Java分布式事务
Posted 造次阿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java分布式事务相关的知识,希望对你有一定的参考价值。
文章目录
-
[Java复习] 分布式事务 Part 2
分布式事务了解吗?如果解决分布式事务问题的?
面试官心里:
只要聊到你做了分布式系统,必问分布式事务,起码得知道有哪些方案,一般怎么来做,每个方案的优缺点是什么。
为什么要有分布式事务?
分布式事务实现的几种方案:
1. 两阶段提交方案/XA方案
这种分布式事务方案,比较适合单块应用里。跨多个库的分布式事务,由于因为严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发的场景。
如果要玩儿,那么基于 Spring + JTA 就可以搞定。
这个方案,很少用,一般来说某个系统内部如果出现跨多个库的这么一个操作,是不合规的。
如果你要操作别人的服务的库,你必须是通过调用别的服务的接口来实现,绝对不允许交叉访问别人的数据库。
2. TCC(Try, Confirm, Cancel)方案
使用补偿机制。分三个阶段:
- Try 阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行锁定或者预留。
- Confirm 阶段:这个阶段说的是在各个服务中执行实际的操作。
- Cancel 阶段:如果任何一个服务的业务方法执行出错,那么这里就需要进行补偿,就是执行已经执行成功的业务逻辑的回滚操作。(把那些执行成功的回滚)
缺点:与业务耦合太紧,事务回滚严重依赖自己的写的代码来回滚和补偿。
适用场景:与钱打交道的场景,支付,交易。需要TCC,严格保证分布式事务要么全部成功,要么全部自动回滚,严格保证资金的正确性。
3. 本地消息表
大概流程:
1. A系统在处理本地事务的同时插入一条数据到消费表。
2. 然后A系统将这个消息发送到MQ。
3. B系统接收到消息后,在一个事务里,先往自己本地消息表插入一条记录,然后执行业务处理;
如果这个消息已经被处理过,则消息表插入失败,事务回滚,保证不会重复处理消息。
4. 如果B系统处理成功,则更新自己本地消费表状态和A系统消费表状态。
5. 如果B系统处理失败,则不会更新消息表状态,A系统会定期扫描自己的消息表,如果有未处理的消息,会再次发送到MQ中,让B系统再次处理。
6. 这个方案保证最终一致性,哪怕B系统事务失败,但A会不断重发消息,直到B成功为止。

缺点:严重依赖数据库的消息表来管理事务。高并发场景怎么办,访问消息表瓶颈,不容易扩展。
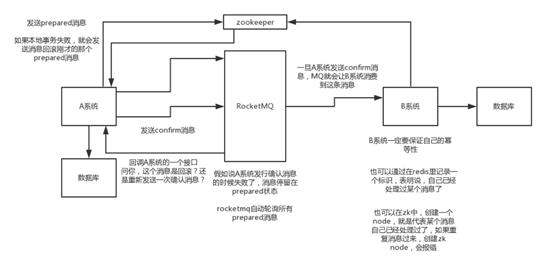
4. 可靠消息最终一致性方案(国内互联网流行)
不用本地消费表,直接基于MQ来实现事务。比如阿里的RocketMQ就支持消息事务。
大概流程:
1. A系统发一个prepared消息到MQ,如果这个消息失败则直接取消操作。
2. 如果这个prepared消息发送成功,则执行本地事务,如果事务执行成功就发送confirm消息到MQ,如果失败就告诉MQ回滚消息。
3. 如果发送了confirm消息,则MQ让B系统消费这条confirm消息,然后执行本地事务。
4. MQ会定时轮询所有prepared消息,然后回调A系统接口,查看这个消息是回滚还是要重发一次confirm消息。
一般情况A系统查看本地事务是否执行成功,如果回滚了,则消息也回滚。避免本地事务执行成功,而confirm消息发送失败。
5. 如果B系统事务失败,则不断重试直到成功。如果实在不行,则想办法通知A系统回滚,或发送报警由人工来手动回滚或补偿。
你们公司怎么处理分布式事务?
如果是严格资金场景,用的TCC方案;
如果是订单插入之后要调用库存服务更新库存,可以用可靠消息最终一致性方案。
一般情况不应该使用分布式事务,代码复杂,性能太差。普通的A调用B,C,D,根本不用做分布式事务。
一般就是监控(发邮件,发短信报警),记录日志(一旦出错,完整的日志),事后快速的定位,排查和解决方案,临时修复数据。
比做分布式事务的成本要低很多。
参考资料:
《互联网Java进阶面试训练营》的笔记 -- 中华石杉
以上是关于Java分布式事务的主要内容,如果未能解决你的问题,请参考以下文章