new bing的chatGPT如何解析英文论文pdf
Posted 育种数据分析之放飞自我
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了new bing的chatGPT如何解析英文论文pdf相关的知识,希望对你有一定的参考价值。
昨天我的new bing申请下来了,有了聊天的界面:

但是解析pdf的英文文献,还是不行,没有对话窗口。就问了一下chatGPT,方案如下:
要使用New Bing解析PDF文献,你需要以下几个步骤:
1,申请加入new bing的等待名单,等待邮箱通知
2,收到new bing的邀请通知
3,安装Edge 开发者12版本:Edge DEV
4,用Edge DEV打开pdf,打开对话窗口,就可以沟通了。
下面结合我的经验,介绍一下相关步骤。
1. 申请new bing的waitlist名单
详见我的文章:

注意:
- 不要用126,163,qq邮箱,可以用outlook和gmail邮箱
- 注册后,会收到一封邮件
- 要12~15天左右才能收到确认邮件
2. 收到new bing的邀请通知
详见我的文章:
用了12天收到的确认邮件:
3. 安装Edge Dev版本才能解析pdf文献
下载地址:https://www.microsoftedgeinsider.com/en-us/download/dev

安装一下,打开界面如下,右上角有个图标:

4. 用Edge Dev打开英文pdf文献
比如,这里打开一篇水产的英文文献pdf
选择浏览器右上角的图标,进入对话框:
5. 开始询问
5.1 这篇文章主要内容介绍
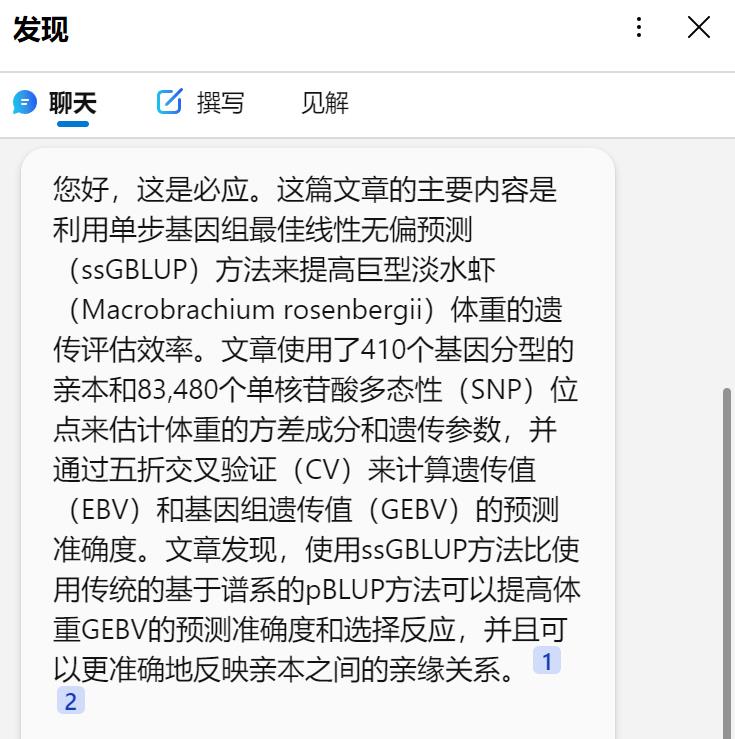
您好,这是必应。这篇文章的主要内容是利用单步基因组最佳线性无偏预测(ssGBLUP)方法来提高巨型淡水虾(Macrobrachium rosenbergii)体重的遗传评估效率。文章使用了410个基因分型的亲本和83,480个单核苷酸多态性(SNP)位点来估计体重的方差成分和遗传参数,并通过五折交叉验证(CV)来计算遗传值(EBV)和基因组遗传值(GEBV)的预测准确度。文章发现,使用ssGBLUP方法比使用传统的基于谱系的pBLUP方法可以提高体重GEBV的预测准确度和选择反应,并且可以更准确地反映亲本之间的亲缘关系。
5.2 这篇文章用的是什么方法
这篇文章用的是单步基因组最佳线性无偏预测(ssGBLUP)方法。这是一种结合了基于谱系的pBLUP方法和基于分子标记的GBLUP方法的遗传评估方法。它可以利用少量的基因分型数据和大量的表型数据来构建一个更准确的亲缘关系矩阵H,从而提高遗传值和基因组遗传值的预测准确度和选择反应。
您想了解更多关于ssGBLUP方法的原理或步骤吗?
5.3 请问ssGBLUP方法有什么优势或局限性
ssGBLUP是一种基于基因组和谱系信息的单步最佳线性无偏预测方法,用于动物育种中的遗传评估和选择。ssGBLUP方法有以下优势和局限性:
优势:ssGBLUP可以利用高密度SNP标记来构建更准确的亲缘关系矩阵,从而提高遗传参数的估计精度和育种值的预测准确度1234。ssGBLUP还可以利用不同权重的SNP标记来进行基因组广泛关联分析(GWAS),从而发现与目标性状相关的SNP位点。ssGBLUP还可以适用于任何类型的群体,包括有或无谱系信息、有或无基因组信息、有或无近交等。
局限性: ssGBLUP需要大量的计算资源和时间来处理大规模的数据集,尤其是当亲缘关系矩阵非常稠密时3。ssGBLUP还需要对SNP标记进行质量控制和过滤,以避免引入噪声和偏差。ssGBLUP还可能受到群体结构、选择历史、遗传漂变等因素的影响,从而降低预测效果。
希望这些信息对您有所帮助。
会给出一个参考文献:

5.4 文章主要是使用什么软件,什么参数实现的
文章中使用了单步基因组最佳线性无偏预测(ssGBLUP)方法来估计遗传参数和预测遗传增益。ssGBLUP方法是一种利用高密度基因型数据进行遗传评估的流行方法1。文章中使用了动物模型,结合SNP标记和家系数据构建的关系矩阵H或者只用家系数据构建的关系矩阵A来估计方差组分。文章中没有提到具体使用的软件和参数,但根据其他文献23,可能使用的软件有BLUPF90、ASReml、WOMBAT等,可能使用的参数有SNP标记数目、交叉验证次数、选择强度等。
ASReml是一种用于拟合线性混合模型的软件,可以处理大规模的数据和复杂的方差协方差结构1。ASReml的实现方法主要是基于平均信息算法(AI),利用似然函数和其一阶和二阶导数来估计参数2。ASReml有两种参数化方式,一种是基于比例(gamma)的,另一种是基于分量(sigma)的,具体取决于残差模型的设定2。ASReml还有一个R语言接口(ASReml-R),可以在R环境中进行数据处理、分析和输出管理
5.5 文章中遗传进展是如何计算的
遗传进展是指在一定的选择压力下,一个群体的遗传水平随着世代的变化而发生的改变1。文章中遗传进展是用选育值或基因选育值(EBV或GEBV)的差异来计算的。选育值或基因选育值是指一个个体对后代表现的预期贡献,它可以用线性混合模型来估计2。文章中使用了五折交叉验证法(CV)来评估选育值或基因选育值的准确性,然后根据不同世代之间的平均选育值或基因选育值的差异来计算遗传进展。
6. 结论
- new bing可以翻译论文中的内容或者段落,准确性较高
- 可以针对某个方法或者内容进行交流
- new bing会给出相关的参考文献
- 可以对某个概念或者方法进行拓展
对于阅读文献,可以加快速度,加深理解,加强关联。
利器!!!
从ChatGPT与New Bing看程序员为什么要学习算法?
文章目录
为什么要学习数据结构和算法?
“算法难道不是脱离实际工作的知识?可能除了面试,这辈子也用不着吧?”
你是不是和我想的一样?
尽管计算机相关专业的同学在大学都学过这门课程,甚至很多培训机构也会培训这方面的知识,但是,很多程序员对数据结构和算法依旧一窍不通。还有一些人也只听说过数组、链表、快排这些最最基本的数据结构和算法,稍微复杂一点的就完全没概念。
当然,也有很多人说,自己实际工作中根本用不到数据结构和算法。所以,就算不懂这块知识,只要Java API、开发框架用得熟练,照样可以把代码写得“飞”起来。事实真的是这样吗?

我们先来听听ChatGPT与NEW Bing怎么回答“程序员为什么要学习数据结构和算法”。
ChatGPT与NEW Bing 的回答
NEW Bing
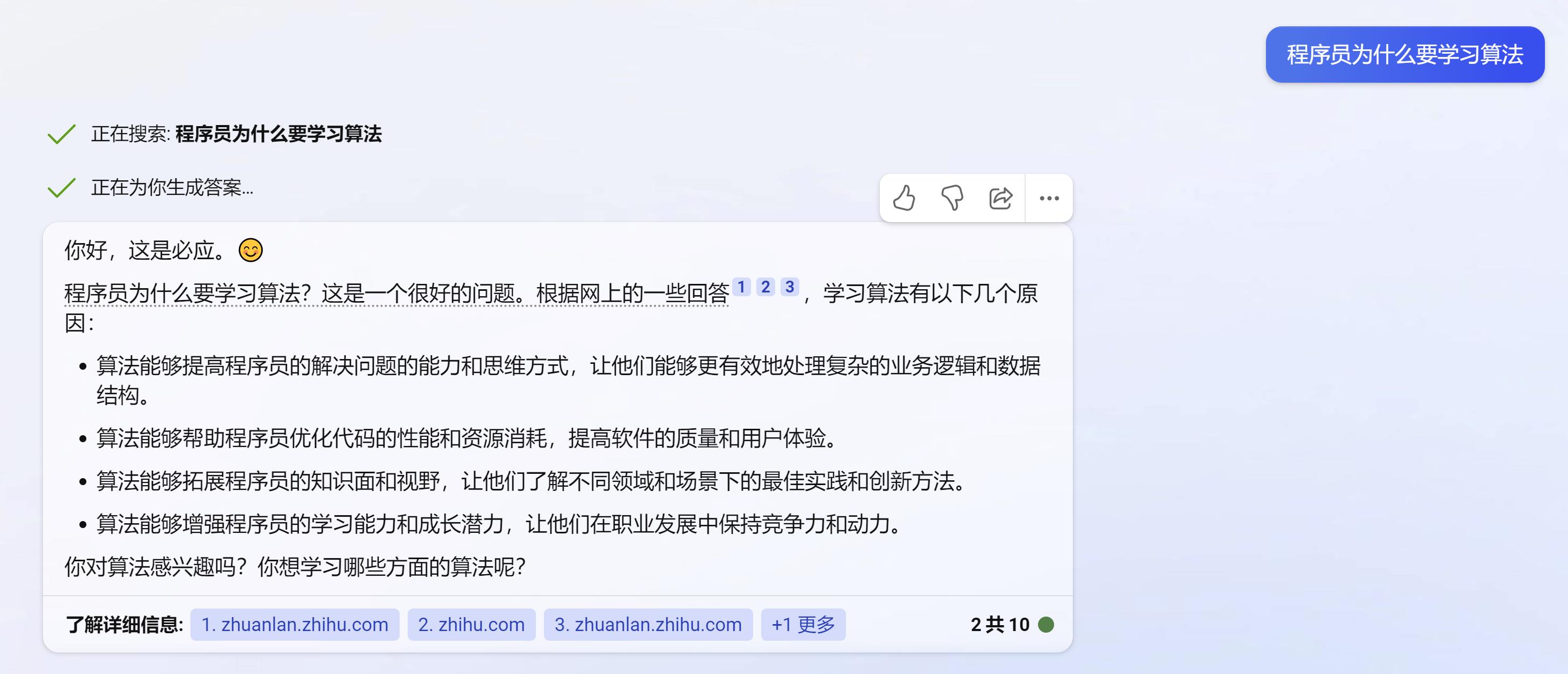
ChatGPT
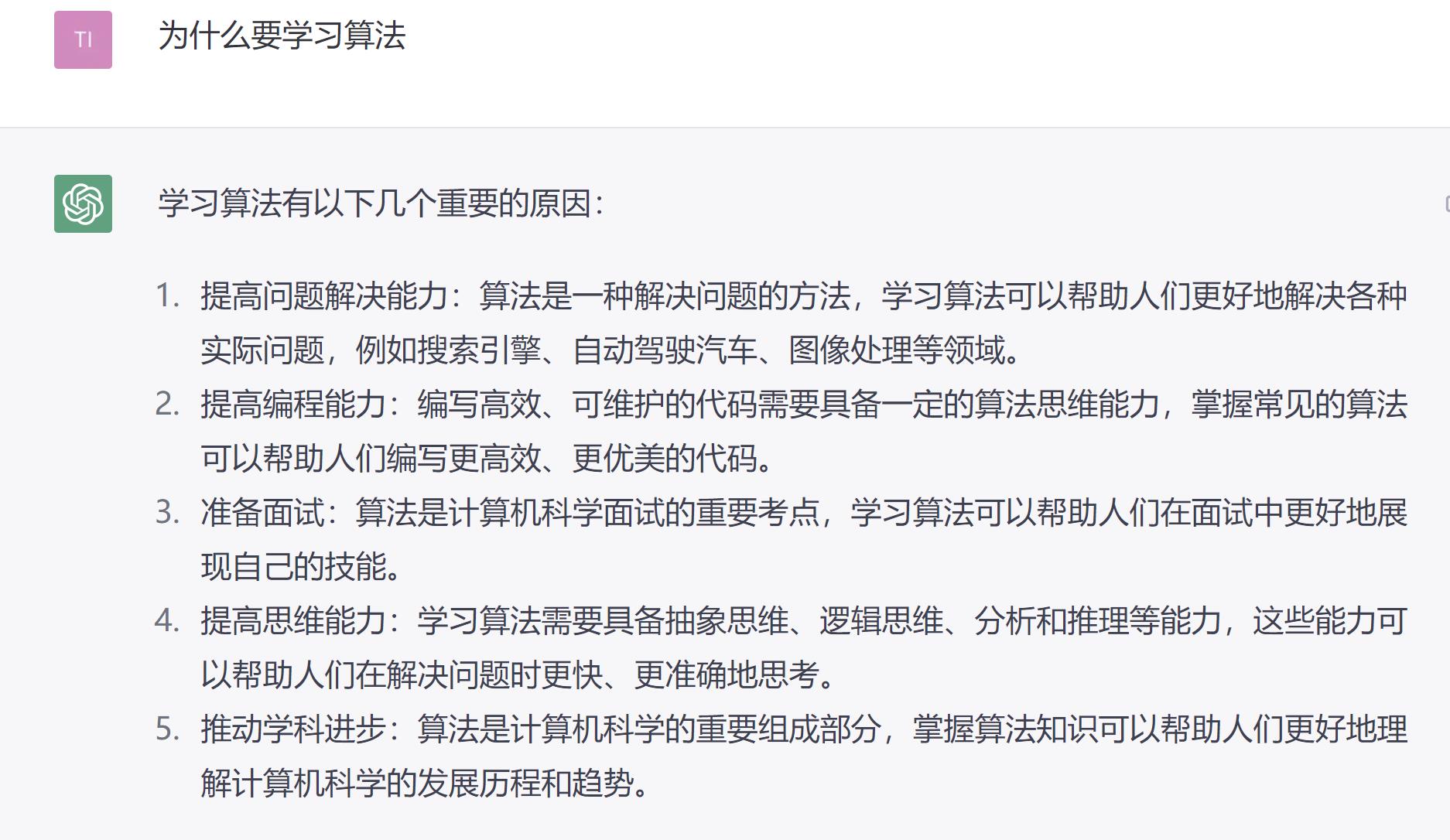
想要通关大厂面试,就不能让数据结构和算法拖了后腿
很多大公司,比如BAT、Google、Facebook,面试的时候都喜欢考算法、让人现场写代码。有些人虽然技术不错,但每次去面试都会“跪”在算法上,很是可惜。那你有没有想过,为什么这些大公司都喜欢考算法呢?
校招的时候,参加面试的学生通常没有实际项目经验,公司只能考察他们的基础知识是否牢固。社招就更不用说了,越是厉害的公司,越是注重考察数据结构与算法这类基础知识。相比短期能力,他们更看中你的长期潜力。
你可能要说了,我不懂数据结构与算法,照样找到了好工作啊。那我是不是就不用学数据结构和算法呢?当然不是,你别忘了, 我们学任何知识都是为了“用”的,是为了解决实际工作问题的,学习数据结构和算法自然也不例外。

业务开发工程师,你真的愿意做一辈子CRUD boy吗?
如果你是一名业务开发工程师,你可能要说,我整天就是做数据库CRUD(增删改查),哪里用得到数据结构和算法啊?
是的,对于大部分业务开发来说,我们平时可能更多的是利用已经封装好的现成的接口、类库来堆砌、翻译业务逻辑,很少需要自己实现数据结构和算法。但是, 不需要自己实现,并不代表什么都不需要了解。
如果不知道这些类库背后的原理,不懂得时间、空间复杂度分析,你如何能用好、用对它们?存储某个业务数据的时候,你如何知道应该用ArrayList,还是Linked List呢?调用了某个函数之后,你又该如何评估代码的性能和资源的消耗呢?
作为业务开发,我们会用到各种框架、中间件和底层系统,比如Spring、RPC框架、消息中间件、Redis等等。 在这些基础框架中,一般都揉和了很多基础数据结构和算法的设计思想。
比如,我们常用的Key-Value数据库Redis中,里面的有序集合是用什么数据结构来实现的呢?为什么要用跳表来实现呢?为什么不用二叉树呢?
如果你能弄明白这些底层原理,你就能更好地使用它们。即便出现问题,也很容易就能定位。因此, 掌握数据结构和算法,不管对于阅读框架源码,还是理解其背后的设计思想,都是非常有用的。
在平时的工作中,数据结构和算法的应用到处可见。我来举一个你非常熟悉的例子:如何实时地统计业务接口的99%响应时间?
你可能最先想到,每次查询时,从小到大排序所有的响应时间,如果总共有1200个数据,那第1188个数据就是99%的响应时间。很显然,每次用这个方法查询的话都要排序,效率是非常低的。但是,如果你知道“堆”这个数据结构,用两个堆可以非常高效地解决这个问题。

对编程还有追求?不想被行业淘汰?那就不要只会写凑合能用的代码!
何为编程能力强?是代码的可读性好、健壮?还是扩展性好?我觉得没法列,也列不全。但是,在我看来, 性能好坏起码是其中一个非常重要的评判标准。但是,如果你连代码的时间复杂度、空间复杂度都不知道怎么分析,怎么写出高性能的代码呢?
你可能会说,我在小公司工作,用户量很少,需要处理的数据量也很少,开发中不需要考虑那么多性能的问题,完成功能就可以,用什么数据结构和算法,差别根本不大。但是你真的想“十年如一日”地做一样的工作吗?
经常有人说,程序员35岁之后很容易陷入瓶颈,被行业淘汰,我觉得原因其实就在此。有的人写代码的时候,从来都不考虑非功能性的需求,只是完成功能,凑合能用就好;做事情的时候,也从来没有长远规划,只把眼前事情做好就满足了。
可是如果你在一家成熟的公司,面对的是千万级甚至亿级的用户,开发的是TB、PB级别数据的处理系统。性能几乎是开发过程中时刻都要考虑的问题。一个简单的ArrayList、Linked List的选择问题,就可能会产生成千上万倍的性能差别。这个时候,数据结构和算法的意义就完全凸显出来了。
其实,我觉得,数据结构和算法这个东西,如果你不去学,可能真的这辈子都用不到,也感受不到它的好。但是一旦掌握,之前你可能需要费很大劲儿来优化的代码,需要花很多心思来设计的架构,用了数据结构和算法之后,很容易就可以解决了。

学习计划
还记得你刚学算法时手写出冒泡排序时的喜悦,以及被其精妙的想法折服时的心情吗?
public class BubbleSort
public static void main(String[] args)
int[] array = 5, 3, 8, 4, 2;
bubbleSort(array);
for (int i : array)
System.out.print(i + " ");
public static void bubbleSort(int[] array)
int n = array.length;
for (int i = 0; i < n - 1; i++)
for (int j = 0; j < n - i - 1; j++)
if (array[j] > array[j + 1])
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
让我们重拾这片心情,继续朝着算法这条路出发吧!
出于对算法的探索以及为了备战四月的蓝桥杯,我报名了这次新星计划中的算法赛道,在接下来的两周里我会持续分享我学习算法的过程与总结。学习任何东西都需要有一个计划,而且这个计划要根据自己的实际情况来制定。比如:
- 我们应该先从哪些基础知识开始入门?
- 我们应该按照什么样的顺序和难度来逐渐深入?
- 我们应该花多少时间来练习编码和调试?
- 我们应该如何评估自己的进度和效果?
就让我带着大家一起领略算法的神秘与五彩缤纷的世家吧!

以上是关于new bing的chatGPT如何解析英文论文pdf的主要内容,如果未能解决你的问题,请参考以下文章