工作面试老大难-MySQL中的锁类型
Posted 听到微笑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了工作面试老大难-MySQL中的锁类型相关的知识,希望对你有一定的参考价值。
mysql 是支持ACID特性的数据库。我们都知道”C”代表Consistent,当不同事务操作同一行记录时,为了保证一致性,需要对记录加锁。在MySQL 中,不同的引擎下的锁行为也会不同,本文将重点介绍 MySQL InnoDB引擎中常见的锁。
一. 准备
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(32) DEFAULT NULL,
`age` tinyint(4) DEFAULT '0',
`phone` varchar(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4;
create index test_age_index
on user (age);
#插入基础数据
INSERT INTO `user` (`id`, `name`, `age`, `phone`)
VALUES
(1, '张三', 18, '13800138000'),
(2, '李四', 20, '13800138001'),
(3, '王五', 22, '13800138002'),
(4, '赵六', 26, '13800138003'),
(5, '孙七', 30, '13800138004');
为了方便讲解,创建一张user表,设置age的字段为普通索引,并填充以下数据。本文所有的sql语句均基于这张表。
| id | name | age | phone |
|---|---|---|---|
| 1 | 张三 | 18 | 13800138000 |
| 2 | 李四 | 20 | 13800138001 |
| 3 | 王五 | 22 | 13800138002 |
| 4 | 赵六 | 26 | 13800138003 |
| 5 | 孙七 | 30 | 13800138004 |
二. 快照读和当前读
MySQL在REPEATABLE READ隔离级别下很大程度地避免了幻读现象(很大程度是个啥意思?意思是在某些情况下其实还是可能出现幻读现象的)。
怎么避免脏读、不可重复读、幻读这些现象呢?其实有两种可选的解决方案。
-
方案一:读操作使用多版本并发控制(MVCC),写操作进行加锁。
MVCC 在之前的文章有详细的描述,就是通过生成一个 ReadView,然后通过ReadView找到符合条件的记录版本(历史版本是由undo日志构建的)。其实就像是在生成ReadView的那个时刻,时间静止了(就像用相机拍了一个快照),查询语句只能读到在生成ReadView之前已提交事务所做的更改,在生成ReadView之前未提交的事务或者之后才开启的事务所做的更改则是看不到的。写操作肯定针对的是最新版本的记录,读记录的历史版本和改动记录的最新版本这两者并不冲突,也就是采用MVCC时,读-写操作并不冲突。我们通常把MVCC实现的并发读写称为“快照读”。
MVCC无法完全避免快照读,参考:《什么是MVCC机制》
-
方案二:读、写操作都采用加锁的方式。
如果我们的一些业务场不允许读取记录的旧版本,而是每次都必须去读取记录的最新版本。比如在银行存款的事务中,我们需要先把账户的余额读出来,然后将其加上本次存款的数额,最后再写到数据库中。在将账户余额读取出来后,就不想让别的事务再访问该余额,直到本次存款事务执行完成后,其他事务才可以访问账户的余额。这样在读取记录的时候也就需要对其进行加锁操作,这也就意味着读操作和写操作也得像写写操作 那样排队执行。我们通常将使用加锁的方式实现的并发读写称为“当前读”。后文提到的
select ... for update和select ... lock in share mode就是典型的当前读。
很明显如果采用MVCC方式,读-写操作彼此并不冲突,性能更高;如果采用加锁方式,读-写操作彼此需要排队执行,从而影响性能。一般情况下,我们当然愿意采用MVCC来解决读-写操作并发执行的问题,但是在某些特殊业务场景中,要求必须采用加锁的方式执行,那也是没有办法的事情。
三. 锁的分类
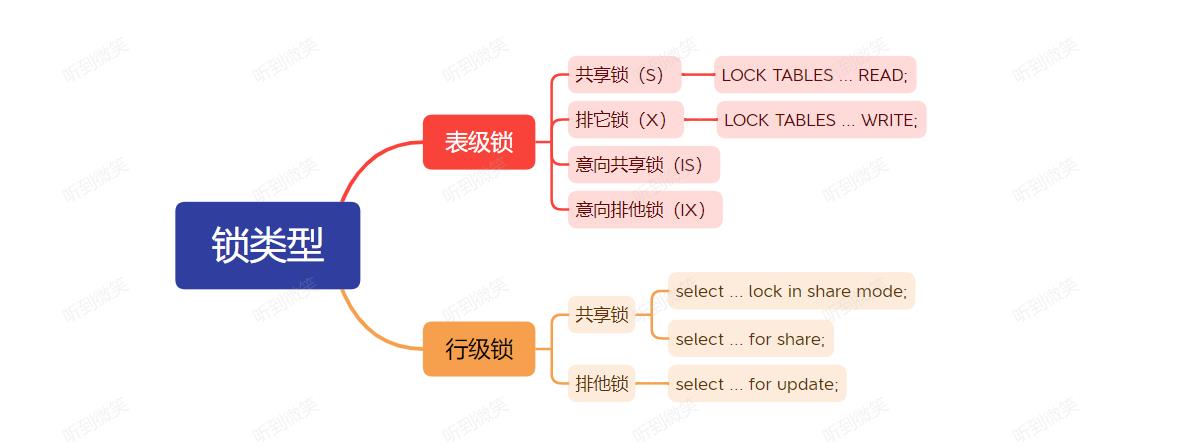
3.1 行级锁和表级锁(Row-level and Table-level Locks)
按照锁的粒度划分,可分为行级锁和表级锁。表级锁作用于数据库表,不同的事务对同一个表加锁,根据实际情况,后加锁的事务可能会发生block,直到表锁被释放。表级锁的优点是资源占用低,可防止死锁等。缺点是锁的粒度太高,不利于高并发的场景。
行级锁行级锁作用于数据库行,它允许多个事务同时访问同一个数据库表。当多个事务操作同一行记录时,没获得锁的事务必须等持有锁的事务释放才能操作行数据。行级锁的优点能支持较高的并发。缺点是资源占用较高,且会出现死锁。
4.2 共享锁排它锁(Shared and Exclusive Locks)
InnoDB引擎的锁分为两类,分别是共享锁和排他锁。这些概念在很多领域都出现过,比如Java中的ReadWriteLock。
-
共享锁(shared lock) 允许多个事务同时持有同一个资源的共享锁,常用
S表示。#mysql 8.0之前的版本通过 lock in share mode给数据行添加share lock select * from user where id = 1 lock in share mode; #mysql 8.0以后的版本通过for share给数据行添加share lock select * from user where id = 1 for share;在普通的 SELECT 语句后边加
LOCK IN SHARE MODE,如果当前事务执行了该语句,那么它会为读取到的记录加 S 锁 这样允许别的事务继续获取这些记录的 S 锁(比方说别的事务也使用SELECT ... LOCK IN SHARE MODE语句来读取这些记录),但是不能获取这些记录的 X 锁(比方说使用SELECT ... FOR UPDATE语句来读取这些记录,或者直接修改这些记录)。如果别的事务想要获取这些记录的 X 锁,那么它们会阻塞,直到当前事务提交之后将这些记录上的 S 锁释放掉。select默认情况下都是快照读,除非显式加锁,实现当前读。
-
排他锁(exclusive lock)只允许一个事务持有某个资源的锁,常用
X表示。# 通过for update可以给数据行加exclusive lock select * from user where id = 1 for update; # 通过update或delete同样也可以 update user set age = 16 where id = 1;也就是在普通的 SELECT 语句后面加上
FOR UPDATE。如果当前事务执行了该语句,那么它会为读取到的记录加X锁,这样既不允许别的事务获取这些记录的S锁(比如别的事务| 使用SELECT .. LOCK IN SHARE MODE语句来读取这些记录时),也不允许获取这些记录的x锁(比如说使用SELECT … FOR UPDATE语句来读取这些记录,或者直接改动这些记录时)如果别的事务想要获取这些记录的s锁或者X锁,那么它们会被阻塞,直到当物事务提交之后将这些记录上的X锁释放掉为止。update、delete语句默认会加排他行锁
举个例子,假如事务T1持有了某一行®的共享锁(S)。当事务T2也想获得该行的锁,分为如下两种情况:
- 如果T2申请的是行r的共享锁(S),会被立即允许,此时T1和T2同时持有行r的共享锁。
- 如果T2申请的是排他锁(X),那么必须等T1释放才能成功获取。
反过来说,假如T1持有行r的排他锁,那不管T2申请的是共享锁还是排他锁,都必须等待T1释放才能成功。
总的来说,MySQL中的锁有很多种,不过我们需要重点关注的就上面两点,即锁的作用域和锁的类型。如上所述,锁可以作用于行,也能作用于表,但不管他们的作用域是什么,锁的类型只有两种,即“共享”和“排他”。
不管是行级还是表级锁,都遵循下列互斥关系:
| 排他锁(X) | 共享锁(S) | |
|---|---|---|
| 排他锁(X) | 互斥 | 互斥 |
| 共享锁(S) | 互斥 | 兼容 |
四. 数据库锁信息查看
如果我们需要查看MySQL目前的锁持有状态,我们可以使用下列语句查询:
# 获取 InnoDB 事务锁的情况,MySQL 8.0 之前
select * from information_schema.INNODB_LOCKS
# MySQL 8.0 之后使用:
select * from performance_schema.data_locks;
例如下列SQL,
| Transaction 1 | Transaction 2 | Transaction 3 |
|---|---|---|
| select * from user where id=2 update; | ||
| update user set name=‘张三’ where id=2; | ||
| select * from performance_schema.data_locks; |
执行结果如下:
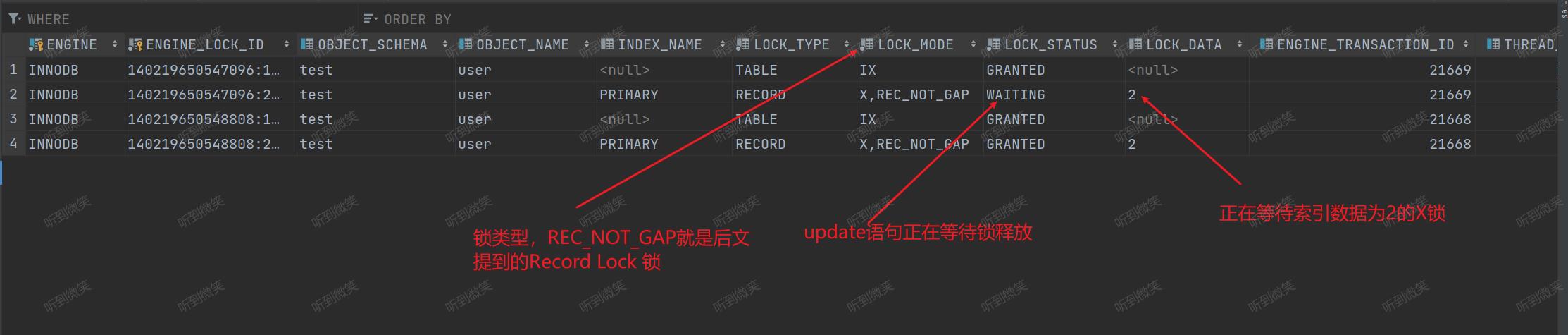
通过 performance_schema.data_locks 表的信息,我们可以轻松了解到系统目前的加锁情况。
五. 意向锁(Intention Locks)
5.1 意向锁分类
InnoDB 支持多粒度锁,允许行锁和表锁并存。例如, LOCK TABLES ... WRITE 之类的语句在指定的表上获取排它锁(X 锁)。为了使多粒度级别的锁定变得可行,InnoDB 使用了意向锁。
意向锁是一种特殊的表级锁,指示事务稍后对表中的行需要哪种类型的锁(共享或独占)。意向锁有两种类型:
- 意向共享锁(intention share lock):简称
IS。事务在给一个数据行加共享锁(S)前必须先取得该表的IS锁,用于标记当前表有行级共享锁存在,代表有事务准备读取数据。 - 意向排他锁(intention exclusive lock):简称
IX。事务在给一个数据行加排他锁(X)前必须先取得该表的IX锁,用于标记当前表有行级排他锁的存在,代表有事务准备写入数据。
需要注意的是,意向锁不会阻塞除全表请求(例如 LOCK TABLES ... WRITE )之外的任何内容。意向锁的主要目的是表明有人正在锁定一行,或者将要锁定表中的一行。IS 和 IX两者之间并不互斥:
| 意向排他锁(IX) | 意向共享锁(IS) | |
|---|---|---|
| 意向排他锁(IX) | 兼容 | 兼容 |
| 意向共享锁(IS) | 兼容 | 兼容 |
也就是说,当 IX 被 T1事务获取,并不影响其他事务获取 IX 和 IS;同理当 IS 被 T1获取时,其他事务也能获取到 IX 和 IS。
只有当一个事务需要获得表级X或S锁时:
# 给user表加表级 S 锁
lock tables user read;
# 给user表加表级 X 锁
lock tables user write;
才会去判断当前表是否有人占用 IX 和 IS 锁,具体有两种情况:
- 尝试获取表级S锁时,如果 IX 被占用,这表明当前表有行级X锁存在,会有事务写入新数据,则获取表级S锁事务被阻塞;如果 IX 未被占用,这表明现在没有行级X锁存在,没有事务写入新数据,则成功获取表级S锁,。
- 尝试获取表级X锁时,如果 IX 或 IS 被占用,这表明当前表有事务准备写入或读取某行数据,则获取表级X锁事务被阻塞。
表级锁和意向锁的互斥关系如下表:
| 意向共享锁(IS) | 意向排他锁(IX) | |
|---|---|---|
| 共享锁(S) | 兼容 | 互斥 |
| 排他锁(X) | 互斥 | 互斥 |
5.2 意向锁存在的意义
有人可能会有疑问,MySQL为什么需要设计意向锁呢?
那我们就需要来看看没有意向锁,MySQL该如何处理表级锁和行级锁共存。
假如事务 A 获取了某一行的排他锁,并未提交:
SELECT * FROM `user` WHERE id = 1 FOR UPDATE;
事务 B 想要获取 users 表的表锁:
LOCK TABLES `user` READ;
因为共享锁与排他锁互斥,所以事务 B 在试图对 user 表加共享锁的时候,必须保证:
- 当前没有其他事务持有 user 表的表级排他锁。
- 当前没有其他事务持有 user 表中任意一行的行级排他锁。
为了检测是否满足第二个条件,事务 B 必须在确保 user 表不存在任何排他锁的前提下,去检测表中的每一行是否存在排他锁。很明显这是一个效率很差的做法,但是有了意向锁之后,情况就不一样了:
因为行级锁加锁前,都会先获取意向锁,所以如果当前意向锁没有被占用,就代表当前表没有行锁占用,就不需要扫描整张表是否存在行级锁占用,大大提高了表级锁加锁效率。
六. 行锁算法
InnoDB引擎是MySQL非常重要的一部分,MySQL团队为它开发了很多种类型的锁,下面将逐一介绍。
6.1 记录锁(Record Locks)
Record Locks是作用于记录的索引,可以锁定单条或多条记录,比如下面SQL语句:
# 锁定id=1这条记录,阻止任何其他事务插入、更新或删除 user.id 值为 1 的行。
SELECT * FROM user WHERE id = 1 FOR UPDATE;
上面的sql给id为1的行加了X锁。其他事务要对这行数据进行修改(update、insert、delete)都必须等待当前事务释放X锁(提交或回滚事务)。
记录锁总是锁定索引记录,即使表没有定义索引。对于这种情况, InnoDB 创建一个隐藏的聚簇索引并使用该索引进行记录锁定。
6.2 间隙锁(Gap Locks)
间隙锁(Gap Lock)是InnoDB为了解决在“可重复读”隔离级别下**“当前读”的幻读问题**引入的锁机制。
6.2.1 什么是间隙锁
间隙就是是指索引两两之间的一个左开右开区间。
在user表中,由于age字段加了普通索引,age字段存在以下的间隙:
(-∞,18), (18,20), (20,22), (22,26), (26,30), (30,+∞]
6.2.2 间隙锁的行为
Record lock是作用于索引,而Gap locks 是作用于索引之间的间隙。比如下面的sql语句就会给(22,26)之间的索引间隙加锁。
select * from user where age between 22 and 26 for update;
上面的语句执行过后,其他事务就无法往[22,26]之间的间隙插入数据。这样做的目的是为了防止出现幻读。假如没有 Gap locks,下面sql会发生不同的行为:
| Transaction 1 | Transaction 2 |
|---|---|
| select * from user where age between 22 and 26 for update; | |
| Insert into user (name,age) values (‘bigbyto’,23); | |
| select * from user where age between 22 and 26; |
上面的sql可能会出现两种情况
- 有Gap locks:T1的第二次查询依然是查询出两个结果,即王五和赵六。 T2将会Block,直到T1事务结束。通过下面sql可以看到Gap lock阻止了T2插入内容。
- 没有Gap locks:由于没有 Gap locks,就只会给 id=3 和 id=4 加锁,而不会给没有的数据加锁,这样T2将会插入成功,数据库多了一条bigbyto,age为25的数据; T1第二次查询将会出现3条数据(幻读)。
Gap locks的目的就是为了防止其他事务往索引的间隙插入数据,以此来避免出现幻读。虽然gap锁有共享gap锁和排他gap锁这样的说法,但是他们起的作用都是相同的。而且如果对一条记录加了gap锁(无论是共享gap锁还是排他gap锁),并不会限制其它事务对这条记录加 Record Lock 或继续加 gap 锁。再强调一遍,gap锁的作用仅仅是为了防止插入幻影记录而已。
在 MySQL 的REPEATABLE-READ隔离级别下,Gap locks默认启用。禁用方式很简单,把隔离级别设置为READ_COMMITTED即可。
需要注意的是,如果age列上没有索引,SQL会走聚簇索引的全表扫描进行过滤,由于过滤是在MySQL Server层面进行的。因此每条记录(无论是否满足条件)都会被加上X锁。
也就是说如果 user 表没有 age 字段索引,T1 执行
select * from user where age between 22 and 26 for update;后,T2是无法插入任何数据。
6.2.3 锁降级
在REPEATABLE-READ隔离级别下,当查询一条记录时,根据实际情况,mysql会对记录加不同的锁。比如下面的sql:
select * from user where id = 3 for update;
上面sql中,会给id=3的行加Record lock。
当where字段满足唯一索引,主键其中之一时,mysql会使用Record lock给记录加锁。因为数据库约束数据唯一,不会出现幻读。如果字段是普通索引,情况会发生变化
select * from user where age = 22 for update;
上面的sql会使用Gap lock,(20,22)之间的间隙会被锁定,其他事务无法往这个区间插入数据。
6.3 Next-Key Locks
Next-Key Locks实际上就是Gap lock和Record Lock的组合。Gap lock中的索引间隙是一个左开右开的区间,在next-key lock中,变成左开右闭,比如:
(-∞,18], (18,20], (20,22], (22,26], (26,30], (30,+∞)
Next-Key Locks同时给索引和索引之间的间隙加锁(即组合Record lock和Gap lock),例如:
select * from user where age = 22 for update;
对于这条sql,锁定的范围变成了(18,22], (22,26),即Next-Key lock会锁定索引前后的区间以及索引本身。同时,因为用到了Gap lock,这种锁自然而然也是只有在 REPEATABLE-READ 的隔离级别下才能用。
6.4 Insert Intention Locks
Insert Intention Lock是MySQL中一种锁类型,用于在多个事务同时向同一个表中插入新行时,保护对于同一索引键的插入操作。Insert Intention Lock的作用是在表级别上创建一个锁定,以指示其他事务正在尝试向表中插入新行。
当一个事务想要向表中插入新行时,它会先获得一个Insert Intention Lock。然后,如果该事务需要向表中插入新行,它会在需要插入的索引键上获得一个排他锁(Exclusive Lock)。如果该事务需要向表中插入新行但没有指定索引键,则会在表上获得一个排他锁。
Insert Intention Lock的作用是防止多个事务同时向同一索引键插入新行,从而保证数据的一致性和完整性。它只会在需要插入新行时才会被创建,不会对已经存在的行造成影响。需要注意的是,Insert Intention Lock只保护对于同一索引键的插入操作,对于不同索引键的插入操作没有任何保护作用。
参考文章:
《MySQL是怎样运行的-小孩子4919著》
MySQL :: MySQL 5.7 Reference Manual :: 14.7.1 InnoDB Locking
MySQL详解--锁.md (xuzhongcn.github.io)
面试中的老大难-mysql事务和锁,一次性讲清楚!
众所周知,事务和锁是mysql中非常重要功能,同时也是面试的重点和难点。本文会详细介绍事务和锁的相关概念及其实现原理,相信大家看完之后,一定会对事务和锁有更加深入的理解。
什么是事务
在维基百科中,对事务的定义是:事务是数据库管理系统(DBMS)执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
事务的四大特性
事务包含四大特性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)(ACID)。
- 原子性(Atomicity) 原子性是指对数据库的一系列操作,要么全部成功,要么全部失败,不可能出现部分成功的情况。以转账场景为例,一个账户的余额减少,另一个账户的余额增加,这两个操作一定是同时成功或者同时失败的。
- 一致性(Consistency) 一致性是指数据库的完整性约束没有被破坏,在事务执行前后都是合法的数据状态。这里的一致可以表示数据库自身的约束没有被破坏,比如某些字段的唯一性约束、字段长度约束等等;还可以表示各种实际场景下的业务约束,比如上面转账操作,一个账户减少的金额和另一个账户增加的金额一定是一样的。
- 隔离性(Isolation) 隔离性指的是多个事务彼此之间是完全隔离、互不干扰的。隔离性的最终目的也是为了保证一致性。
- 持久性(Durability) 持久性是指只要事务提交成功,那么对数据库做的修改就被永久保存下来了,不可能因为任何原因再回到原来的状态。
事务的状态
根据事务所处的不同阶段,事务大致可以分为以下5个状态:
- 活动的(active) 当事务对应的数据库操作正在执行过程中,则该事务处于
活动状态。 - 部分提交的(partially committed) 当事务中的最后一个操作执行完成,但还未将变更刷新到磁盘时,则该事务处于
部分提交状态。 - 失败的(failed) 当事务处于
活动或者部分提交状态时,由于某些错误导致事务无法继续执行,则事务处于失败状态。 - 中止的(aborted) 当事务处于
失败状态,且回滚操作执行完毕,数据恢复到事务执行之前的状态时,则该事务处于中止状态。 - 提交的(committed) 当事务处于
部分提交状态,并且将修改过的数据都同步到磁盘之后,此时该事务处于提交状态。

事务隔离级别
前面提到过,事务必须具有隔离性。实现隔离性最简单的方式就是不允许事务并发,每个事务都排队执行,但是这种方式性能实在太差了。为了兼顾事务的隔离性和性能,事务支持不同的隔离级别。
为了方便表述后续的内容,我们先建一张示例表hero。
CREATE TABLE hero (
number INT,
name VARCHAR(100),
country varchar(100),
PRIMARY KEY (number)
) Engine=InnoDB CHARSET=utf8;事务并发执行遇到的问题
在事务并发执行时,如果不进行任何控制,可能会出现以下4类问题:
- 脏写(Dirty Write) 脏写是指一个事务修改了其它事务未提交的数据。

如上图,Session A和Session B各开启了一个事务,Session B中的事务先将number列为1的记录的name列更新为\'关羽\',然后Session A中的事务接着又把这条number列为1的记录的name列更新为张飞。如果之后Session B中的事务进行了回滚,那么Session A中的更新也将不复存在,这种现象就称之为脏写。
- 脏读(Dirty Read) 脏读是指一个事务读到了其它事务未提交的数据。

如上图,Session A和Session B各开启了一个事务,Session B中的事务先将number列为1的记录的name列更新为\'关羽\',然后Session A中的事务再去查询这条number为1的记录,如果读到列name的值为\'关羽\',而Session B中的事务稍后进行了回滚,那么Session A中的事务相当于读到了一个不存在的数据,这种现象就称之为脏读。
- 不可重复读(Non-Repeatable Read) 不可重复读指的是在一个事务执行过程中,读取到其它事务已提交的数据,导致两次读取的结果不一致。

如上图,我们在Session B中提交了几个隐式事务(mysql会自动为增删改语句加事务),这些事务都修改了number列为1的记录的列name的值,每次事务提交之后,如果Session A中的事务都可以查看到最新的值,这种现象也被称之为不可重复读。
- 幻读(Phantom) 幻读是指的是在一个事务执行过程中,读取到了其他事务新插入数据,导致两次读取的结果不一致。

如上图,Session A中的事务先根据条件number > 0这个条件查询表hero,得到了name列值为\'刘备\'的记录;之后Session B中提交了一个隐式事务,该事务向表hero中插入了一条新记录;之后Session A中的事务再根据相同的条件number > 0查询表hero,得到的结果集中包含Session B中的事务新插入的那条记录,这种现象也被称之为幻读。
脏写的问题太严重了,任何隔离级别都必须避免。其它无论是脏读,不可重复读,还是幻读,它们都属于数据库的读一致性的问题,都是在一个事务里面前后两次读取出现了不一致的情况。
四种隔离级别
在SQL标准中设立了4种隔离级别,用来解决上面的读一致性问题。不同的隔离级别可以解决不同的读一致性问题。
-
READ UNCOMMITTED:未提交读。 -
READ COMMITTED:已提交读。 -
REPEATABLE READ:可重复读。 SERIALIZABLE:串行化。
各个隔离级别下可能出现的读一致性问题如下:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读(READ UNCOMMITTED) | 可能 | 可能 | 可能 |
| 已提交读(READ COMMITTED) | 不可能 | 可能 | 可能 |
| 可重复读(REPEATABLE READ) | 不可能 | 不可能 | 可能(对InnoDB不可能) |
| 串行化(SERIALIZABLE) | 不可能 | 不可能 | 不可能 |
InnoDB支持四个隔离级别(和SQL标准定义的基本一致)。隔离级别越高,事务的并发度就越低。唯一的区别就在于,InnoDB 在可重复读(REPEATABLE READ)的级别就解决了幻读的问题。这也是InnoDB使用可重复读 作为事务默认隔离级别的原因。
MVCC
MVCC(Multi Version Concurrency Control),中文名是多版本并发控制,简单来说就是通过维护数据历史版本,从而解决并发访问情况下的读一致性问题。
版本链
在InnoDB中,每行记录实际上都包含了两个隐藏字段:事务id(trx_id)和回滚指针(roll_pointer)。
trx_id:事务id。每次修改某行记录时,都会把该事务的事务id赋值给trx_id隐藏列。roll_pointer:回滚指针。每次修改某行记录时,都会把undo日志地址赋值给roll_pointer隐藏列。
假设hero表中只有一行记录,当时插入的事务id为80。此时,该条记录的示例图如下:

假设之后两个事务id分别为100、200的事务对这条记录进行UPDATE操作,操作流程如下:

由于每次变动都会先把undo日志记录下来,并用roll_pointer指向undo日志地址。因此可以认为,对该条记录的修改日志串联起来就形成了一个版本链,版本链的头节点就是当前记录最新的值。如下:

ReadView
如果数据库隔离级别是未提交读(READ UNCOMMITTED),那么读取版本链中最新版本的记录即可。如果是是串行化(SERIALIZABLE),事务之间是加锁执行的,不存在读不一致的问题。但是如果是已提交读(READ COMMITTED)或者可重复读(REPEATABLE READ),就需要遍历版本链中的每一条记录,判断该条记录是否对当前事务可见,直到找到为止(遍历完还没找到就说明记录不存在)。InnoDB通过ReadView实现了这个功能。ReadView中主要包含以下4个内容:
m_ids:表示在生成ReadView时当前系统中活跃的读写事务的事务id列表。min_trx_id:表示在生成ReadView时当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值。max_trx_id:表示生成ReadView时系统中应该分配给下一个事务的id值。creator_trx_id:表示生成该ReadView事务的事务id。
有了ReadView之后,我们可以基于以下步骤判断某个版本的记录是否对当前事务可见。
- 如果被访问版本的
trx_id属性值与ReadView中的creator_trx_id值相同,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。 - 如果被访问版本的
trx_id属性值小于ReadView中的min_trx_id值,表明生成该版本的事务在当前事务生成ReadView前已经提交,所以该版本可以被当前事务访问。 - 如果被访问版本的
trx_id属性值大于或等于ReadView中的max_trx_id值,表明生成该版本的事务在当前事务生成ReadView后才开启,所以该版本不可以被当前事务访问。 - 如果被访问版本的
trx_id属性值在ReadView的min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中,如果在,说明创建ReadView时生成该版本的事务还是活跃的,该版本不可以被访问;如果不在,说明创建ReadView时生成该版本的事务已经被提交,该版本可以被访问。
在MySQL中,READ COMMITTED和REPEATABLE READ隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同。READ COMMITTED在每次读取数据前都会生成一个ReadView,这样就能保证每次都能读到其它事务已提交的数据。REPEATABLE READ 只在第一次读取数据时生成一个ReadView,这样就能保证后续读取的结果完全一致。
锁
事务并发访问同一数据资源的情况主要就分为读-读、写-写和读-写三种。
读-读即并发事务同时访问同一行数据记录。由于两个事务都进行只读操作,不会对记录造成任何影响,因此并发读完全允许。写-写即并发事务同时修改同一行数据记录。这种情况下可能导致脏写问题,这是任何情况下都不允许发生的,因此只能通过加锁实现,也就是当一个事务需要对某行记录进行修改时,首先会先给这条记录加锁,如果加锁成功则继续执行,否则就排队等待,事务执行完成或回滚会自动释放锁。读-写即一个事务进行读取操作,另一个进行写入操作。这种情况下可能会产生脏读、不可重复读、幻读。最好的方案是读操作利用多版本并发控制(MVCC),写操作进行加锁。
锁的粒度
按锁作用的数据范围进行分类的话,锁可以分为行级锁和表级锁。
行级锁:作用在数据行上,锁的粒度比较小。表级锁:作用在整张数据表上,锁的粒度比较大。
锁的分类
为了实现读-读之间不受影响,并且写-写、读-写之间能够相互阻塞,Mysql使用了读写锁的思路进行实现,具体来说就是分为了共享锁和排它锁:
共享锁(Shared Locks):简称S锁,在事务要读取一条记录时,需要先获取该记录的S锁。S锁可以在同一时刻被多个事务同时持有。我们可以用select ...... lock in share mode;的方式手工加上一把S锁。排他锁(Exclusive Locks):简称X锁,在事务要改动一条记录时,需要先获取该记录的X锁。X锁在同一时刻最多只能被一个事务持有。X锁的加锁方式有两种,第一种是自动加锁,在对数据进行增删改的时候,都会默认加上一个X锁。还有一种是手工加锁,我们用一个FOR UPDATE给一行数据加上一个X锁。
还需要注意的一点是,如果一个事务已经持有了某行记录的S锁,另一个事务是无法为这行记录加上X锁的,反之亦然。
除了共享锁(Shared Locks)和排他锁(Exclusive Locks),Mysql还有意向锁(Intention Locks)。意向锁是由数据库自己维护的,一般来说,当我们给一行数据加上共享锁之前,数据库会自动在这张表上面加一个意向共享锁(IS锁);当我们给一行数据加上排他锁之前,数据库会自动在这张表上面加一个意向排他锁(IX锁)。意向锁可以认为是S锁和X锁在数据表上的标识,通过意向锁可以快速判断表中是否有记录被上锁,从而避免通过遍历的方式来查看表中有没有记录被上锁,提升加锁效率。例如,我们要加表级别的X锁,这时候数据表里面如果存在行级别的X锁或者S锁的,加锁就会失败,此时直接根据意向锁就能知道这张表是否有行级别的X锁或者S锁。
InnoDB中的表级锁
InnoDB中的表级锁主要包括表级别的意向共享锁(IS锁)和意向排他锁(IX锁)以及自增锁(AUTO-INC锁)。其中IS锁和IX锁在前面已经介绍过了,这里不再赘述,我们接下来重点了解一下AUTO-INC锁。
大家都知道,如果我们给某列字段加了AUTO_INCREMENT自增属性,插入的时候不需要为该字段指定值,系统会自动保证递增。系统实现这种自动给AUTO_INCREMENT修饰的列递增赋值的原理主要是两个:
AUTO-INC锁:在执行插入语句的时先加上表级别的AUTO-INC锁,插入执行完成后立即释放锁。如果我们的插入语句在执行前无法确定具体要插入多少条记录,比如INSERT ... SELECT这种插入语句,一般采用AUTO-INC锁的方式。轻量级锁:在插入语句生成AUTO_INCREMENT值时先才获取这个轻量级锁,然后在AUTO_INCREMENT值生成之后就释放轻量级锁。如果我们的插入语句在执行前就可以确定具体要插入多少条记录,那么一般采用轻量级锁的方式对AUTO_INCREMENT修饰的列进行赋值。这种方式可以避免锁定表,可以提升插入性能。
InnoDB中的行级锁
前面说过,通过MVCC可以解决脏读、不可重复读、幻读这些读一致性问题,但实际上这只是解决了普通select语句的数据读取问题。事务利用MVCC进行的读取操作称之为快照读,所有普通的SELECT语句在READ COMMITTED、REPEATABLE READ隔离级别下都算是快照读。除了快照读之外,还有一种是锁定读,即在读取的时候给记录加锁,在锁定读的情况下依然要解决脏读、不可重复读、幻读的问题。由于都是在记录上加锁,这些锁都属于行级锁。
InnoDB的行锁,是通过锁住索引来实现的,如果加锁查询的时候没有使用过索引,会将整个聚簇索引都锁住,相当于锁表了。根据锁定范围的不同,行锁可以使用记录锁(Record Locks)、间隙锁(Gap Locks)和临键锁(Next-Key Locks)的方式实现。假设现在有一张表t,主键是id。我们插入了4行数据,主键值分别是 1、4、7、10。接下来我们就以聚簇索引为例,具体介绍三种形式的行锁。
- 记录锁(Record Locks) 所谓记录,就是指聚簇索引中真实存放的数据,比如上面的1、4、7、10都是记录。

显然,记录锁就是直接锁定某行记录。当我们使用唯一性的索引(包括唯一索引和聚簇索引)进行等值查询且精准匹配到一条记录时,此时就会直接将这条记录锁定。例如select * from t where id =4 for update;就会将id=4的记录锁定。
- 间隙锁(Gap Locks) 间隙指的是两个记录之间逻辑上尚未填入数据的部分,比如上述的(1,4)、(4,7)等。

同理,间隙锁就是锁定某些间隙区间的。当我们使用用等值查询或者范围查询,并且没有命中任何一个record,此时就会将对应的间隙区间锁定。例如select * from t where id =3 for update;或者select * from t where id > 1 and id < 4 for update;就会将(1,4)区间锁定。
- 临键锁(Next-Key Locks) 临键指的是间隙加上它右边的记录组成的左开右闭区间。比如上述的(1,4]、(4,7]等。

临键锁就是记录锁(Record Locks)和间隙锁(Gap Locks)的结合,即除了锁住记录本身,还要再锁住索引之间的间隙。当我们使用范围查询,并且命中了部分record记录,此时锁住的就是临键区间。注意,临键锁锁住的区间会包含最后一个record的右边的临键区间。例如select * from t where id > 5 and id <= 7 for update;会锁住(4,7]、(7,+∞)。mysql默认行锁类型就是临键锁(Next-Key Locks)。当使用唯一性索引,等值查询匹配到一条记录的时候,临键锁(Next-Key Locks)会退化成记录锁;没有匹配到任何记录的时候,退化成间隙锁。
间隙锁(Gap Locks)和临键锁(Next-Key Locks)都是用来解决幻读问题的,在已提交读(READ COMMITTED)隔离级别下,间隙锁(Gap Locks)和临键锁(Next-Key Locks)都会失效!
以上是关于工作面试老大难-MySQL中的锁类型的主要内容,如果未能解决你的问题,请参考以下文章