牛顿法梯度下降法与拟牛顿法
Posted 小何才露尖尖角
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了牛顿法梯度下降法与拟牛顿法相关的知识,希望对你有一定的参考价值。
牛顿法、梯度下降法与拟牛顿法
0 引言
机器学习中在求解非线性优化问题时,常用的是梯度下降法和拟牛顿法,梯度下降法和拟牛顿法都是牛顿法的一种简化
牛顿法是在一个初始极小值点做二阶泰勒展开,然后对二阶泰勒展开式求极值点,通过迭代的方式逼近原函数极值点
在牛顿法迭代公式中,需要求二阶导数,而梯度下降法将二阶导数简化为一个固定正数方便求解
拟牛顿法也是在求解过程中做了一些简化,不用直接求二阶导数矩阵和它的逆
1 关于泰勒展开式
1.1 原理
如果我们有一个复杂函数
f
(
x
)
f(x)
f(x), 对这个复杂函数我们想使用 n 次多项式(多项式具有好计算,易求导,且好积分等一系列的优良性质)去拟合这个函数,这时就可以对
f
(
x
)
f(x)
f(x)进行泰勒展开,求某一点
x
0
x_0
x0附近的 n 次多项式:

注意:
n 次多项式只是在
x
0
x_0
x0 较小的邻域内能较好拟合
f
(
x
)
f(x)
f(x),也就是说,泰勒展开式其实是一种局部近似的方法,只近似
x
=
x
0
x=x_0
x=x0那一点的函数性
1.2 例子
现在要求 f ( x ) = c o s ( x ) f(x)=cos(x) f(x)=cos(x) 在 x 0 = 0 x_0=0 x0=0 处的二阶泰勒展开,因为我们去掉了高阶项,所以只是近似
直接套用公式
f
(
x
0
)
=
f
(
0
)
=
c
o
s
(
0
)
=
1
f(x_0)=f(0)=cos(0)=1
f(x0)=f(0)=cos(0)=1
f
′
(
x
0
)
=
f
′
(
0
)
=
−
s
i
n
(
0
)
=
0
f'(x_0)=f'(0)=-sin(0)=0
f′(x0)=f′(0)=−sin(0)=0
f
′
′
(
x
0
)
=
f
′
′
(
0
)
=
−
c
o
s
(
0
)
=
−
1
f''(x_0)=f''(0)=-cos(0)=-1
f′′(x0)=f′′(0)=−cos(0)=−1
所以展开后的公式为
f
(
x
)
≈
f
(
x
0
)
+
f
′
(
x
0
)
∗
x
+
f
′
′
(
x
0
)
∗
x
2
/
2
=
1
−
0.5
∗
x
2
f(x)≈f(x_0)+f'(x_0)*x+f''(x_0)*x^2/2=1-0.5*x^2
f(x)≈f(x0)+f′(x0)∗x+f′′(x0)∗x2/2=1−0.5∗x2
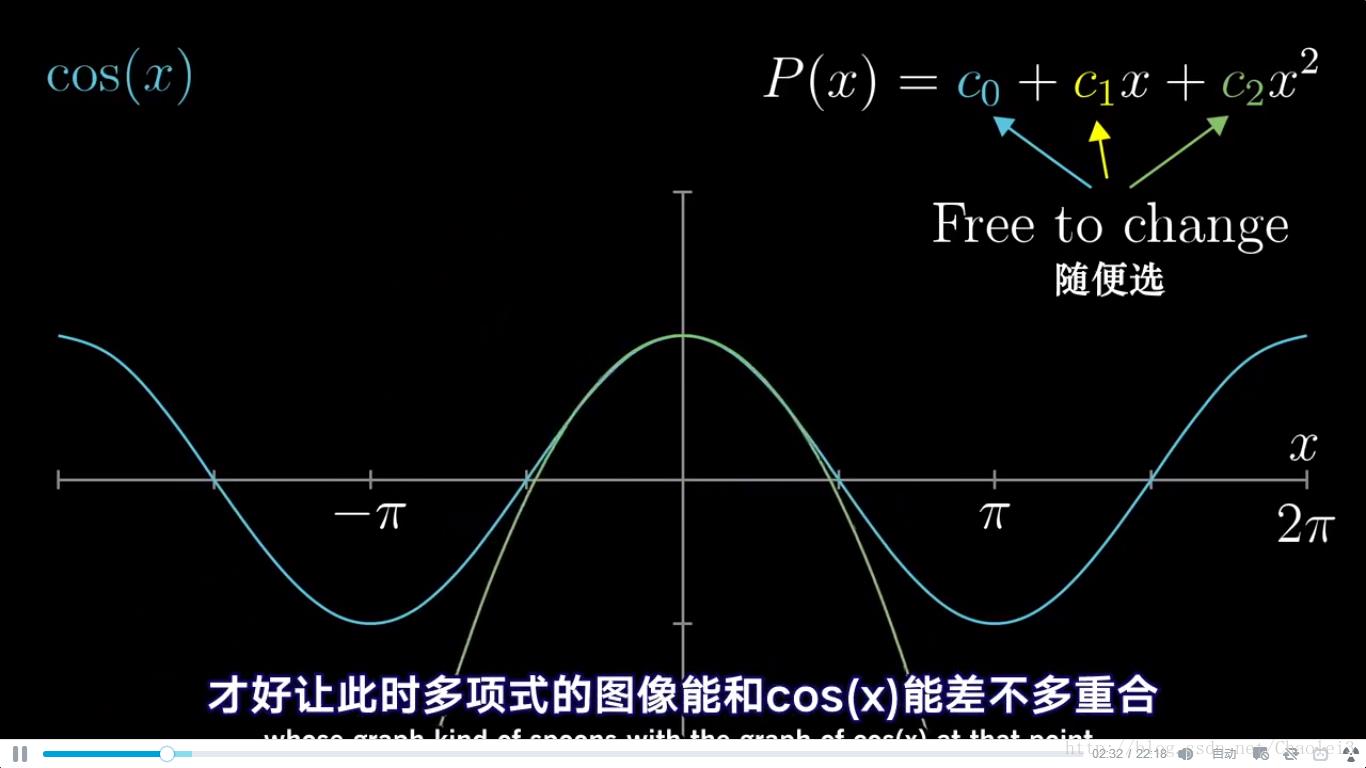
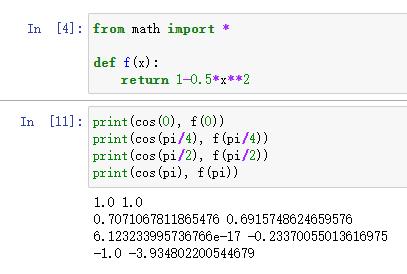
从下方运行程序可以看出,离展开点越近的点,拟合程度越高,越远的点,越离谱
2 牛顿法
2.1 x 为一维
现在假设我们有目标函数
f
(
x
)
f(x)
f(x),我们希望求此函数的极小值,牛顿法的基本思想是:随机找到一个点设为当前极值点
x
k
x_k
xk,在这个点对
f
(
x
)
f(x)
f(x) 做二次泰勒展开,进而找到极小点的下一个估计值。在
x
k
x_k
xk 附近的二阶泰勒展开为:
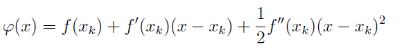
现在想求
φ
(
x
)
\\varphi(x)
φ(x) 的极值点,由极值的必要条件可知,
φ
(
x
)
\\varphi(x)
φ(x) 应满足导数为 0,即:
φ
′
(
x
)
=
0
\\varphi'(x)=0
φ′(x)=0
即
φ
′
(
x
)
=
f
′
(
x
k
)
+
f
′
′
(
x
k
)
(
x
−
x
k
)
=
0
\\varphi'(x)=f'(x_k)+f''(x_k)(x-x_k)=0
φ′(x)=f′(xk)+f′′(xk)(x−xk)=0
这样就可以求得 x 的值
x
=
x
k
−
f
′
(
x
k
)
f
′
′
(
x
k
)
x=x_k-\\fracf'(x_k)f''(x_k)
x=xk−f′′(xk)f′(xk)
于是给定初始值
x
0
x_0
x0,就可以通过迭代的方式逼近
f
(
x
)
f(x)
f(x)的极值点:
x
k
+
1
=
x
k
−
f
′
(
x
k
)
f
′
′
(
x
k
)
x_k+1=x_k-\\fracf'(x_k)f''(x_k)
xk+1=xk−f′′(xk)f′(xk)
如下图,首先在 x n x_n xn 处泰勒展开,得到 f ( x ) f(x) f(x) 的近似函数 g n ( x ) g_n(x) gn(x) ,求得 g n ( x ) g_n(x) gn(x) 的极值点 x n + 1 x_n+1 xn+1
随后在 x n + 1 x_n+1 xn+1 出泰勒展开,得到 g n + 1 ( x ) g_n+1(x) gn+1(x) 函数,继续求 g n + 1 ( x ) g_n+1(x) gn+1(x) 的极值点
一直迭代最后就会逼近
f
(
x
)
f(x)
f(x) 的极值点

2.2 x 为多维
上面讨论的是参数 x 为一维的情况,当 x 有多维时,二阶泰勒展开式可以做推广,此时:
φ
(
x
)
=
f
(
x
k
)
+
∇
f
(
x
k
)
∗
(
x
−
x
k
)
+
1
2
∗
(
x
−
x
k
)
T
∗
∇
2
f
(
x
k
)
∗
(
x
−
x
k
)
\\varphi(x)=f(x_k)+\\nablaf(x_k)*(x-x_k)+ \\frac12*(x-x_k)^T*\\nabla^2f(x_k)*(x-x_k)
φ(x)&#无约束优化问题中牛顿法与拟牛顿法四种迭代方法的matlab实现
文章目录
1. 无约束优化问题的解法
在无约束优化问题中,有四种经典的迭代优化方法:Newton’s method(牛顿法)、Levenberg-Marquardt’s method(非线性最小二乘法,LM)、Broyden-Fletcher-Goldfarb-Shanno’s method(BFGS)、Davidon-Fletcher-Powell’s method(DFP)。
2. Matlab实现
假设有如下无约束优化问题: f ( x 1 , x 2 ) = ( x 1 − 3 ) 4 + ( x 1 − 3 x 2 ) 2 f(x_1,x_2)=(x_1-3)^4+(x_1-3x_2)^2 f(x1,x2)=(x1−3)4+(x1−3x2)2为了方便四种算法的比较,我们统一设置初始迭代点为 x 0 = [ 0 , 0 ] T x_0=[0,0]^T x0=[0,0]T ,则初始海森矩阵为: H 0 = ( 110 − 6 − 6 18 ) H_0=\\beginpmatrix 110 & -6 &\\\\ -6 & 18 &\\\\ \\endpmatrix H0=(110−6−618)
上述优化问题用matlab代码表示为:
syms x1; % 变量x1
syms x2; % 变量x2
f = (x1 - 3).^4 + (x1 - 3*x2).^2; $ 函数表达
x0=[0 0]'; % 初始迭代点
H0=[110 -6;-6 18]; % 初始海森矩阵
m=2; % 变量个数
k=30; % 迭代次数
该函数的最优 X = ( x 1 , x 2 ) X=(x_1,x_2) X=(x1,x2)以及 f ( x 1 , x 2 ) f(x_1,x_2) f(x1,x2)应该为: x 1 = 3 , x 2 = 1 x_1=3, x_2=1 x1=3,x2=1 f ( x 1 , x 2 ) = 0 f(x_1,x_2)=0 f(x1,x2)=0
下面展示一下如何用Matlab实现对函数的优化:
2.1. Newton’s method(牛顿法)
牛顿法的迭代公式为: x k + 1 = x k − H − 1 ( x k ) ∇ f ( x k ) x_k+1=x_k-H^-1(x_k)\\nabla f(x_k) xk+1=xk−H−1(xk)∇f(xk)matlab实现函数实现为:
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%文件名:Newton.m
%
%f表示函数表达式
%H0表示初始的海森矩阵
%x0表示初始的迭代点 为列向量
%m表示变量的个数
%k表示迭代次数
%X存储每次迭代的x,F为函数值,G为每次的梯度,H为海森阵,HN为海森矩阵的逆
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function[X, H, F, G,HN] = Newton(f,H0,x0,m,k)
x1 = sym('x',[1,m]); % [x1, x2]
%f = (x1(1) - 3)^4 + (x1(1) - 3*x1(2))^2;
c = num2cell(x1); % c=变量[x1, x2]
g = sym('x',[m,1]); % [x1, x2]^T
X = zeros(m, k+1); % x1、x2的迭代值
H = zeros( m, m, k+1); % hessian的迭代值
F = zeros(1, k+1); % function的迭代值
G = zeros(m, k+1); % function‘的迭代值
HN = zeros( m, m, k+1); % hessian的逆阵的迭代值
H(:,:,1) = H0; % hessian初始化
HN(:,:,1) = inv(H0); % hessian逆初始化
X(:,1) = x0; % X(x1, x2)初始化
F(1,1) = subs(f, c, X(:,1)'); % 初始X值赋予F
h = hessian(f,x1);%求海森矩阵
for n = 1:m % f对x1、x2分别求偏导
g(n) = diff(f,x1(n));
end
G(:,1) = subs(g,c,X(:,1)'); % 初始X导赋予G
% 迭代
for n = 1:k
X(:,n+1) = X(:,n) - (H(:,:,n))\\G(:,n);
F(1,n+1) = subs(f,c,X(:,n+1)');
G(:,n+1) = subs(g,c,X(:,n+1)');
H(:,:,n+1) = subs(h,c,X(:,n+1)');
HN(:,:,n+1) = inv(H(:,:,n+1));
end
end
执行matlab代码:
[X, H, F, G, HN] = Newton(f,H0,x0,m,k);
即可得到优化结果,下表是迭代次数 k 分别为:0、1、2、3时的输出值:
| k k k | x k x_k xk | f ( x k ) f(x_k) f(xk) | ∇ f ( x k ) \\nabla f(x_k) ∇f(xk) | H ( x k ) H(x_k) H(xk) |
|---|---|---|---|---|
| 0 | ( 0 , 0 ) (0,0) (0,0) | 81 | ( − 108 , 0 ) (-108, 0) (−108,0) | ( 110 − 6 − 6 18 ) \\beginpmatrix110 & -6 &\\\\-6 & 18 &\\\\\\endpmatrix (110−6−618) |
| 1 | ( 1 , 0.3333 ) (1, 0.3333) (1,0.3333) | 16 | ( − 32 , 0 ) (-32, 0) (−32,0) |
(
50
−
6
−
6
18
)
\\beginpmatrix50 & -6 &\\\\-6 & 18 &\\\\\\endpmatrix
(50以上是关于牛顿法梯度下降法与拟牛顿法的主要内容,如果未能解决你的问题,请参考以下文章
梯度下降之模拟退火梯度下降之学习计划牛顿法拟牛顿法共轭梯度法 |