大数据开发报错汇总
Posted 岱宗夫如何、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据开发报错汇总相关的知识,希望对你有一定的参考价值。
目录
Attempting to operate on hdfs namenode as root
Hadoop
Attempting to operate on hdfs namenode as root
HDfs客户端报错
(31条消息) 两种解决ERROR: Attempting to operate on hdfs namenode as root的方法_世幻水的博客-CSDN博客
报错:
jps后没有namenode
解决
删除data logs 重新初始化namenode
Hive
报错
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
原因
hive和hadoop里的 guava.jar版本不一样
解决
cd /opt/module/hive-3.1.1/lib
ll |gerp guavacd /opt/module/hadoop-3.1.3/share/hadoop/common/lib
ll |grep guava比较两个guava-*-jre.jar的版本
rm guava-低版本的.jar
cp 高版本的 低版本的文件目录加guava-高版本的.jar报错
Caused by:org.apache.hadoop.ipc. RemoteException (org.apache.hadoop.hdfs.server.namenode.SafeModeExcepti
on):Cannot create directory /tmp/hive. Name node is in safe mode
原因
NameNode 处于安全模式 ,对于客户端是only-read。
NameNode启动时,将镜像文件fsimage载入内存,并执行编辑日志edits log中的所有操作,从而建立完整的元数据metadata。
满足最小副本条件(配置项minimal replication condition决定),NameNode 将会在随后(默认30s,配置项dfs.namenode.safemode.extension)自动退出safemode。
NameNode 处于安全模式有两种情况:
1. NameNode启动前30s.
2. 不满足最小副本条件。
参数:
| 属性名称 | 数据类型 | 默认值 | 说明 |
| dfs.namenode.replication.min | int | 1 | 成功执行写操作所需要创建的最小副本数目(也称为最小副本级别) |
| dfs.namenode.safemode.threshold-pct | float | 0.999 | 在namenode退出安全模式之前,系统中满足最小副本级别(dfs.namenode.replication.min定义)的块的比例。将这项值设为0或更小会令namenode无法启动安全模式;设为高于1则永远不会退出安全模式 |
| dfs.namenode.safemode.extension | int | 30000 | 在满足最小副本条件(由dfs.namenode.safemode.threshold-pct定义)之后,namenode还需要处于安全模式的时间(以毫秒为单位)。对于小型集群(几十个节点)来说,这项值可以设为0 |
解决
等待30s后,再启动Hive;
如果不行可以强制退出
# hdfs:可执行命令
# dfsadmin:运行一个dfs admin client
# -safemode:参数,安全模式
# get:参数,是否安全模式(on表示是,off表示否)
# enter:参数,进入安全模式
# leave:参数,离开安全模式
hdfs dfsadmin -safemode get # NameNode是否出于安全模式
hdfs dfsadmin -safemode enter # 进入安全模式
hdfs dfsadmin -safemode leave # 离开安全模式来源:
Hadoop二次开发项目案例方案汇总
大数据Hadoop应用开发技术正可谓如火如荼推进中,以为大数据已经不仅仅是局限在互联网领域,而是已经被上升到了国家战略的高度层面。大数据正在深刻影响和改变我们的日常生活和工作方式。
Hadoop应用开发太过偏底层,难度之大真不是我们一般人所能够理解的。有的人会说,不都是倒腾代码吗?有什么难的!如果真是这样想,那就真的完蛋了。做hadoop底层的开发,真不是一般人和一般的企业就能够去做的。问个超级简单的问题,你知道的网络公司多,还是做大数据hadoop开发的公司多?估计没几个人知道做大数据hadoop开发的公司有哪些吧?
Hadoop起源于国外,所以说国内的Hadoop应用开发起步是落后国外很多的。这也就导致了Hadoop开发中的很多游戏规则我们也只能遵从别人已经制定好的玩了。虽然说国内的Hadoop开发起步晚,但总算是有一些企业在做的。比如国产手机界扛把子的华为,还一直默默的在做底层开发的大快搜索!华为的大数据解决方案主要是满足自主产品的需求,好像目前不对外的吧!
当然,国内做Hadoop开发的不是只有这两家了。国内做Hadoop开发的公司以二次包装为主,做Hadoop原生态开发的至少我知道的也就是上面刚才说的大快搜索是在做的。感兴趣的可以搜索找一下大快搜索推出的国产发行版dkhadoop,应该还是可以申请拿一个玩一下的!
Hadoop二次开发的应用案例比较多,简单的介绍几个Hadoop二次开发的应用方案案例:
1、首先是在政务方面的应用:政务大数据平台解决方案——推行电子政务、建设智慧城市等为抓手,以数据集中和共享为途径,推动技术融合、业务融合、数据融合,打通信息壁垒,形成覆盖全国、统筹利用、统一接入的数据共享大平台,构建全国信息资源共享体系,实现跨层级、跨地域、跨系统、跨部门、跨业务的协同管理和服务。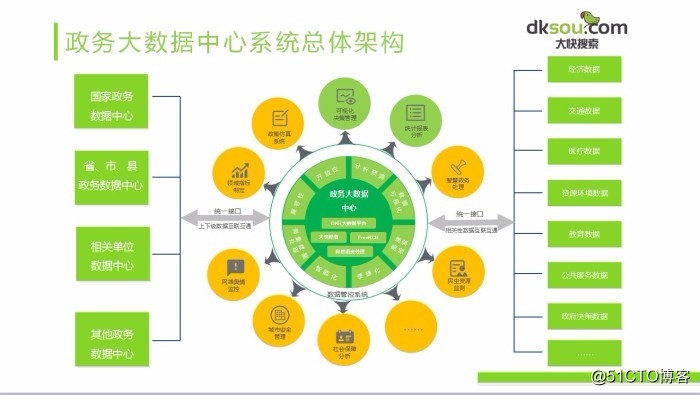
2、企业级大数据处理平台——这是针对大型企业或者行业,如果是一般的小企业就没有必要了。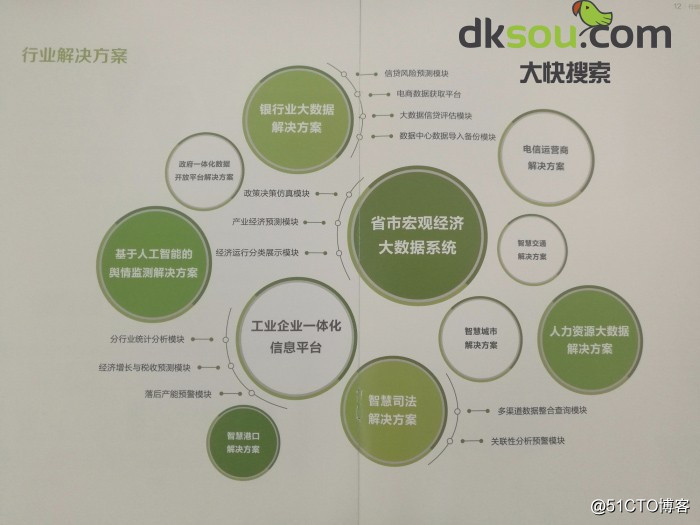
3、城市智慧停车解决方案——智慧城市建设的重要组成部分,前些时候分享过一个大快搜索的城市智慧停车云平台解决方案,感兴趣的可以看一下!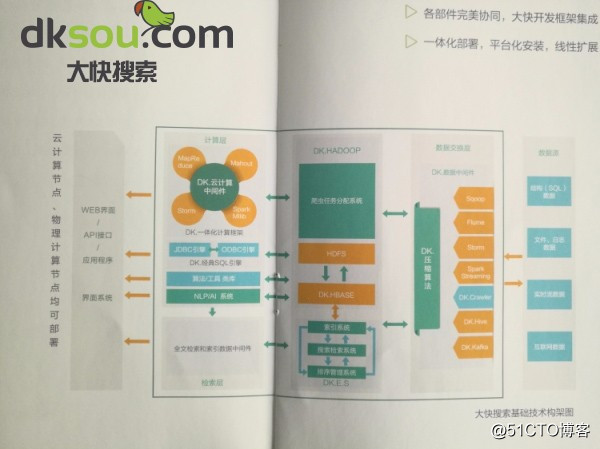
上述这个三个Hadoop二次开发的应用案例可以说是目前比较典型的三种了。码字就码到这里吧,感兴趣的可以自己去查一下这方面的。大快搜索的网站上这三个案例的方案有详细的介绍,还有一些其他的方面的案例介绍,不妨可以看看!
以上是关于大数据开发报错汇总的主要内容,如果未能解决你的问题,请参考以下文章