操作系统-用户进程
Posted living_frontier
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了操作系统-用户进程相关的知识,希望对你有一定的参考价值。
一、Makefile
这个 Makefile 要比之前的文件夹中的 Makefile 更加复杂,是因为之前的文件夹都是对操作系统特定部分的一个编译指导,所以基本上是实现的功能就是“对应的 C 文件和汇编文件编译成目标文件”这一个功能,最后合成一个整体。但是 user 的 Makefile 指导的是多个用户程序的编译,最后生成的是多个用户目标文件,同时还需要给每个用户文件装备上库目标文件。
首先先补充一下 makefile 的一些知识
自动化变量
$@表示目标(target)文件,就是冒号前面的那个文件$^表示所有的依赖文件,就是冒号后面的那一堆文件$<表示第一个依赖文件,就是紧挨着冒号后面的一个文件$*这个变量表示目标模式中%及其之前的部分。如果目标是dir/a.foo.b,并且目标的模式是a.%.b,那么,$*的值就是dir/a.foo。
静态模式
就是带有 % 的那种 target 和 prereq。主要用于同时匹配多个,之前似乎介绍过了。这里只是强调,对于匹配,是用 target 里面的集合元素去匹配 prereq 中的元素,换句话说,是一个从上到下的结构,比如说
all: a.x b.x
%.x: %.o #这里
a.o: a.c
gcc -o $@ $<
b.o: b.c
gcc -o $@ $<
c.o: c.c
gcc -o $@ $<
对于用注释标注出来的地方,虽然看上去,有 a.o, b.o, c.o 三个文件符合 %.o 的匹配条件,但是请注意,真正匹配到的只有 a.o, b.o 这是因为 all 作为总目标,指定了只要 a.x, b.x ,那么 %.x 就是 a.x, b.x 。所以就只会匹配到 a.o, b.o 。
中间文件
似乎 make 有一种特性是不保存中间文件,正是因为这种特性,我们在 user 下才会找不到 .b.c 文件,也找不到很多 .o 文件。
然后就可以来看文件了(考虑到理解问题,我们从下往上看):
%.o: lib.h
这个只是在保证 user 下有 lib.h 这个文件,不然编译就会报错。
%.o: %.c
$(CC) $(CFLAGS) $(INCLUDES) -c -o $@ $<
%.o: %.S
$(CC) $(CFLAGS) $(INCLUDES) -c -o $@ $<
这两句比较正常,就是把“对应的 C 文件和汇编文件编译成目标文件”。
接下来需要先从上往下看,这是因为本质上 makefile 是一个“需求决定工作”,而不是“工作决定需求”的东西,所以本源方法是从上往下看。
USERLIB := printf.o \\
print.o \\
libos.o \\
fork.o \\
pgfault.o \\
syscall_lib.o \\
ipc.o \\
string.o
all: tltest.x tltest.b fktest.x fktest.b pingpong.x pingpong.b idle.x \\
$(USERLIB) entry.o syscall_wrap.o
这里我们可以看到,我们的目标文件有很多,但是我们可以将其分成三类,一类是库目标文件,也就是前面变量定义的
USERLIB := printf.o \\
print.o \\
libos.o \\
fork.o \\
pgfault.o \\
syscall_lib.o \\
ipc.o \\
string.o
一类是普通包装文件(瞎起的名字),他们是每个程序链接必须用到的(库文件则不一定,虽然这里是一定的)
entry.o syscall_wrap.o
最后是我们真的需要编译成成果的东西,即下面这个三个
tltest.x tltest.b fktest.x fktest.b pingpong.x pingpong.b idle.x
到最后我们用到的东西(也就是链接到整体的项目中的)是 .x 文件,它是一个二进制文件,.b 同样是一个二进制文件。只不过 .b 文件更接近我们通常的理解,而 .x 文件只是一个字符数组的二进制化。
然后我们来看 .x 文件是怎样来的
%.x: %.b.c
$(CC) $(CFLAGS) -c -o $@ $<
可以看出,他是由一个名字相对应的 .b.c 的 C 文件编译而来的,但是这个 C 文件又是从何而?
%.b.c: %.b
chmod +x ./bintoc
./bintoc $* $< > $@~ && mv -f $@~ $@
我们可以看到,是由 .b 文件经过一个叫做 bintoc 的工具转换而来,首先是第一句
chmod +x ./bintoc
这是在赋予 bintoc 一个可执行的权限,这个工具的功能就是把一个二进制文件(这里是 .b )转换为一个字符数组,我们可以在 user 文件夹下输入如下命令
make tltest.b.c
就会显式的得到 tltest.b.c 文件(如果是直接 make ,.b.c 会被判定为中间文件,不会保留),其内容如下
unsigned char binary_user_tltest_start[] =
0x7f, 0x45, 0x4c, 0x46, 0x1, 0x2, 0x1, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0,
0x0, 0x2, 0x0, 0x8, 0x0, 0x0, 0x0, 0x1, 0x0, 0x40, 0x0, 0x0, 0x0, 0x0, 0x0, 0x34,
0x0, 0x0, 0x68, 0x44, 0x0, 0x0, 0x10, 0x1, 0x0, 0x34, 0x0, 0x20, 0x0, 0x2, 0x0, 0x28,
0x0, 0xa, 0x0, 0x7, 0x70, 0x0, 0x0, 0x0, 0x0, 0x0, 0x25, 0xa0, 0x0, 0x40, 0x15, 0xa0,
0x0, 0x40, 0x15, 0xa0, 0x0, 0x0, 0x0, 0x18, 0x0, 0x0, 0x0, 0x18, 0x0, 0x0, 0x0, 0x4,
0x0, 0x0, 0x0, 0x4, 0x0, 0x0, 0x0, 0x1, 0x0, 0x0, 0x10, 0x0, 0x0, 0x40, 0x0, 0x0,
0x0, 0x40, 0x0, 0x0, 0x0, 0x0, 0x53, 0x1a, 0x0, 0x0, 0x53, 0x24, 0x0, 0x0, 0x0, 0x7,
0x0, 0x0, 0x10, ...
0x73, 0x79, 0x73, 0x63, 0x61, 0x6c, 0x6c, 0x5f, 0x69, 0x70, 0x63, 0x5f, 0x63, 0x61, 0x6e, 0x5f,
0x73, 0x65, 0x6e, 0x64, 0x0, 0x70, 0x61, 0x67, 0x65, 0x73, 0x0, 0x0
;
unsigned int binary_user_tltest_size = 29051;
这就与宏契合上了
#define ENV_CREATE(x) \\
\\
extern u_char binary_##x##_start[]; \\
extern u_int binary_##x##_size; \\
env_create(binary_##x##_start, \\
(u_int)binary_##x##_size); \\
然后我们就利用这个工具进行如下操作
./bintoc $* $< > $@~ && mv -f $@~ $@
我们会把这个内容输入到一个以 .b.c~ 结尾的临时文件中,然后再用 mv 指令将其存入正式的 .b.c 文件中,我不知道其深意。
那么 .b 文件又是如何来的呢?
%.b: entry.o syscall_wrap.o %.o $(USERLIB)
echo ld $@
$(LD) -o $@ $(LDFLAGS) -G 0 -static -n -nostdlib -T ./user.lds $^
这里强调一下,无论是 .b, .b.c, .x 那个文件,其实没有 entry.o, fork.o 之类的事情,所有的文件名,都是围绕这四个名字展开的
tltest fktest pingpong idle
然后看代码
%.b: entry.o syscall_wrap.o %.o $(USERLIB)
$(LD) -o $@ $(LDFLAGS) -G 0 -static -n -nostdlib -T ./user.lds $^
这里做的其实是把上面编译好的东西链接起来,也就是给每个 tltest fktest pingpong idle 的东西链接上 entry.o syscall_wrap.o 和库目标文件。
至此,我们可以有一个大致的思路,我们首先编译出很多个目标文件,这其中有真正我们的程序目标文件,有的则是库文件,我们的目的是将库文件链接到每一个写好的程序上。这个时候会生成 .b 文件,这是可执行文件。但是因为此时我们没有文件系统,所以读不了它,所以我们需要将其转换成字符数组的形式,我们用这个工具bintoc 生成了 .b.c 的 C 文件,这个时候我们只需要将其重新编译成二进文件即可,即 .x 文件。
二、user.lds
这个链接脚本就很普通
OUTPUT_ARCH(mips)
ENTRY(_start)
SECTIONS
. = 0x00400000;
_text = .; /* Text and read-only data */
.text :
*(.text)
*(.fixup)
*(.gnu.warning)
_etext = .; /* End of text section */
.data : /* Data */
*(.data)
*(.rodata)
*(.rodata.*)
*(.eh_frame)
CONSTRUCTORS
_edata = .; /* End of data section */
. = ALIGN(0x1000);
__bss_start = .; /* BSS */
.bss :
*(.bss)
/DISCARD/ :
*(.comment)
*(.debug_*)
end = . ;
只是指定了入口函数是 _start (注意是用户进程的 _start ,在 entry.S中)。
然后将所有的代码从低地址区开始链接
. = 0x00400000;
三、启动流程
这个 _start 还是很简单的,其简单的最主要原因就是很多事情都是由内核完成的,所以才会使这里这么简单,其中在 env_alloc 中有
e->env_tf.cp0_status = 0x1000100c;
e->env_tf.regs[29] = USTACKTOP;
可以看到这里设置了栈指针和 CP0_STATUS。于是当调度的时候,sp 已经是用户栈指针了。所以对于 _start 。做的事情就是从用户栈上给 libmain 传入两个参数,就是大名鼎鼎的 argc, argv 。
.text
.globl _start
_start:
lw a0, 0(sp)
lw a1, 4(sp)
nop
jal libmain
nop
对于libmain
void exit(void)
syscall_env_destroy(0);
struct Env *env;
void libmain(int argc, char **argv)
env = 0;
int envid;
envid = syscall_getenvid();
envid = ENVX(envid);
env = &envs[envid];
umain(argc, argv);
exit();
首先是先定义了一个 env 全局指针,这个指针指向了这个进程对应的进程控制块。还是挺有意思的。
struct Env *env;
envid = ENVX(envid);
env = &envs[envid];
可以看到 libmain 主要还是起一个包装的作用,在正式开始前获得进程控制块,然后进行了一个参数传参。在正式结束后把进程控制块在操作系统中注销。
void exit(void)
syscall_env_destroy(0);
最后举一个 umain 的例子
#include "lib.h"
void umain()
while (1)
writef("IDLE!");
可以看到在这里的时候,就很像我们平时写的程序了。到了这里,我们可以说,我们终于对于用户完成了封装。用户只需要引用用户可知的头文件,就可以实现相应的功能,而不需要了解操作系统的实现细节。
四、库函数
这里说明,这里的库函数包括我在 makefile 这一节中提出的库函数和普通包装函数,放在这里一并记录了。
4.1 entry.S
__asm_pgfault_handler
.globl __pgfault_handler
__pgfault_handler:
.word 0
.set noreorder
.text
.globl __asm_pgfault_handler
__asm_pgfault_handler:
nop
lw a0, TF_BADVADDR(sp)
lw t1, __pgfault_handler
jalr t1
nop
lw v1,TF_LO(sp)
mtlo v1
lw v0,TF_HI(sp)
lw v1,TF_EPC(sp)
mthi v0
mtc0 v1,CP0_EPC
lw $31,TF_REG31(sp)
lw $30,TF_REG30(sp)
lw $28,TF_REG28(sp)
lw $25,TF_REG25(sp)
lw $24,TF_REG24(sp)
lw $23,TF_REG23(sp)
lw $22,TF_REG22(sp)
lw $21,TF_REG21(sp)
lw $20,TF_REG20(sp)
lw $19,TF_REG19(sp)
lw $18,TF_REG18(sp)
lw $17,TF_REG17(sp)
lw $16,TF_REG16(sp)
lw $15,TF_REG15(sp)
lw $14,TF_REG14(sp)
lw $13,TF_REG13(sp)
lw $12,TF_REG12(sp)
lw $11,TF_REG11(sp)
lw $10,TF_REG10(sp)
lw $9,TF_REG9(sp)
lw $8,TF_REG8(sp)
lw $7,TF_REG7(sp)
lw $6,TF_REG6(sp)
lw $5,TF_REG5(sp)
lw $4,TF_REG4(sp)
lw $3,TF_REG3(sp)
lw $2,TF_REG2(sp)
lw $1,TF_REG1(sp)
lw k0,TF_EPC(sp)
jr k0
lw sp,TF_REG29(sp)
这个函数在“异常处理流”中讲过了,主要是跳转到函数指针 __pgfault_handler 指向的异常处理函数主体(pgfault),然后进行现场的恢复。
在这个文件中还有与自映射有关的两个变量
.globl vpt
vpt:
.word UVPT
.globl vpd
vpd:
.word (UVPT+(UVPT>>12)*4)
其实就类似与
unsigned int vpt = UVPT;
unsigned int vpd = (UVPT+(UVPT>>12)*4);
关于为啥不直接使用原来定义好的宏,我觉得是因为原来的宏是属于操作系统的,而在库函数的实现的时候尽量少的接触操作系统的细节,是很有必要的,因为这样可以提高可移植性。
4.2 fork.c
首先先吐槽一下,这个函数分类真的是烂透了,为什么 fork.c 中要有 user_bcopy() ,真的理解不了啊。
user_bcopy
实现就类似与 bcopy
void user_bcopy(const void *src, void *dst, size_t len)
void *max;
max = dst + len;
// copy machine words while possible
if (((int)src % 4 == 0) && ((int)dst % 4 == 0))
while (dst + 3 < max)
*(int *)dst = *(int *)src;
dst += 4;
src += 4;
// finish remaining 0-3 bytes
while (dst < max)
*(char *)dst = *(char *)src;
dst += 1;
src += 1;
user_bzero
与 user_bcopy 类似
void user_bzero(void *v, u_int n)
char *p;
int m;
p = v;
m = n;
while (--m >= 0)
*p++ = 0;
pgfault
这个函数实现的是根据虚拟地址 va 为其分配一个物理页面,而且这个新的物理页面要有一些内容。
最有意思的是,这个 va 之前是对应了一个物理页面的(这是一个子进程函数,所以之前是和父进程共享这个页面)。那么我们要实现的,似乎是让一个 va 对应两个物理页面。显然是不合理的。所以严谨地阐述这个函数的功能,是将 va 对应到新的物理页面,并将原来的物理页面映射关系去掉。这个新的物理页面的内容跟原来的物理页面内容一致。
static void pgfault(u_int va)
u_int *tmp = USTACKTOP;
// writef("fork.c:pgfault():\\t va:%x\\n",va);
u_long perm = ((Pte *)(*vpt))[VPN(va)] & 0xfff;
if ((perm & PTE_COW) == 0)
user_panic("pgfault err: COW not found");
perm -= PTE_COW;
// map the new page at a temporary place
syscall_mem_alloc(0, tmp, perm);
// copy the content
user_bcopy(ROUNDDOWN(va, BY2PG), tmp, BY2PG);
// map the page on the appropriate place
syscall_mem_map(0, tmp, 0, va, perm);
// unmap the temporary place
syscall_mem_unmap(0, tmp);
duppage
这个函数用于根据父进程的映射关系,去复制子进程的映射关系,pn 是虚拟页面号的意思。复制最困难的是对于权限位的考量,其实就是对于 COW 的设置。如果一个页面,他不是只读的(说明有写的可能),而且也没有明确说是可以共享的(只共享写),那么就是应该增设 PTE_COW 位,这种增设是对于父子进程都要设置的。所以尽管这里有两个map,但是第一个 map 是用于子进程建立页面映射,而第二个是用于修改父进程的映射权限。
static void duppage(u_int envid, u_int pn)
// addr is the va we need to process
u_int addr = pn << PGSHIFT;
// *vpt + pn is the adress of page_table_entry which is corresponded to the va
u_int perm = ((Pte *)(*vpt))[pn] & 0xfff;
// if the page can be write and is not shared, so the page need to be COW and map twice
int flag = 0;
if ((perm & PTE_R) && !(perm & PTE_LIBRARY))
perm |= PTE_COW;
flag = 1;
syscall_mem_map(0, addr, envid, addr, perm);
if (flag)
syscall_mem_map(0, addr, 0, addr, perm);
// user_panic("duppage not implemented");
fork
这个函数用于产生一个子进程,并且设置其状态和各种配置。这里需要强调的一个有趣的点是,fork 本身并不是系统调用函数,他是由一系列系统调用函数组成的一个用户函数。
int fork(void)
u_int newenvid;
extern struct Env *envs;
extern struct Env *env;
u_int i;
// The parent installs pgfault using set_pgfault_handler
set_pgfault_handler(pgfault);
// alloc a new alloc
newenvid = syscall_env_alloc();
if (newenvid == 0)
env = envs + ENVX(syscall_getenvid());
return 0;
for (i = 0; i < VPN(USTACKTOP); ++i)
if (((*vpd)[i >> 10] & PTE_V) && ((*vpt)[i] & PTE_V))
duppage(newenvid, i);
syscall_mem_alloc(newenvid, UXSTACKTOP - BY2PG, PTE_V | PTE_R);
syscall_set_pgfault_handler(newenvid, __asm_pgfault_handler, UXSTACKTOP);
syscall_set_env_status(newenvid, ENV_RUNNABLE);
return newenvid;
首先我们先进行了一个父进程的配置,我们用这个函数为父进程分配了处理 COW 的时候的栈,还指定了处理 pgfault 异常的函数。至于为啥不一早就分配好了呢?我觉得是因为不是每个进程都需要用到这个栈,所以为了避免页面的浪费,就没有改成了用函数手动配置,而不是默认配置。
set_pgfault_handler(pgfault);
然后我们利用系统调用创造一个进程
newenvid = syscall_env_alloc();
我们先看子进程,它会被时钟中断调度(先别管咋调度的),那么就会从内存控制块里恢复现场,那么此时被恢复的 v0 就是 0,返回的 PC 就是 syscall_env_alloc 所导致的 syscall 的下一条,也就是 msyscall 中的这条
LEAF(msyscall)
syscall
nop // 这条
jr ra
nop
END(msyscall)
那么再次返回的时候 syscall_env_alloc 的返回值就变成了 0。然后就会进入下面这个分支判断
if (newenvid == 0)
env = envs + ENVX(syscall_getenvid());
return 0;
env 是对于用户进程的一个全局变量,他表示正在运行的进程块,一般会在 start 到 main 之间设置,但是以为 fork 出的子进程没有设置这个,所以需要在这里设置,然后就可以结束 fork 了,返回值是 0。
但是对于父进程来说,对于子进程的修改还没有结束,他还需要将虚拟环境完全的复制给子进程,也就是下面的语句。这里的 i 是虚页号,我们可以用 (*vpd)[i >> 10] 的找出这个虚页号对应的一级页表项,用 (*vpt)[i] 找出二级页表项,为什么可以这样呢?
for (i = 0; i < VPN(USTACKTOP); ++i)
if (((*vpd)[i >> 10] & PTE_V) && ((*vpt)[i] & PTE_V))
duppage(newenvid, i);
首先我们需要弄清 extern 的用法,这似乎是理解的最难点,对于一个在 file1 中定义的全局变量 a
int a = 1; // 假设地址 &a = 0x8000_5000
那么在文件 file2 的时候需要引入这个变量,那么可以有两种写法(虽然正常人只会用第一种)
extern int a;
extern int a[];
但是两者的结果是不同的,如果我们打印第一个变量 a,那么会出现 1,如果打印第二个变量(我都感觉这是个指针常量了),那么就会出现 a = 0x80005000 。我不知道为啥是这样的,但是确实是这样的。
然后我们来看一下 vpt 和 vpd 的定义,在 user 文件夹下的 entry.S 下
.globl vpt
vpt:
.word UVPT
.globl vpd
vpd:
.word (UVPT+(UVPT>>12)*4)
可以看到是一个自映射的标准写法,相关的宏就是我们在 mmu.h 中定义的,而且我们在进程创建之初,就完成了这个设置,
e->env_pgdir[PDX(UVPT)] = e->env_cr3 | PTE_V;
但是最让人困惑的莫过于教程中“指针的指针”这一说法,我个人觉得直接认为他是错误的就好了。因为在引入的时候,我们用的是这种方法
extern volatile Pte *vpt[];
extern volatile Pde *vpd[];
按照 c 的语法,vpt 应该是一个指针数组,但是这个操作 (*vpt)[i] 如果需要先按照数组方式理解,然后再按照指针方式理解,那么就会变成这样 *(vpt[0] + i) 或者直观一些 vpt[0][i] 。这都是无厘头的,因为类似于我们声明了一个指针数组,但是只用它的第一个元素当指针,为啥我们不直接声明一个指针 Pte* vpt。这是个未解之谜,我与叶哥哥讨论,叶哥哥也认为如果写成
u_int *vpt = (u_int*) UVPT;
// use vpt[i]
会很好看,鬼知道他为啥写成这样。
但是既然写了,就要从语法上解释通,对于 (*vpt) 操作,结合上面介绍的 extern 知识,可以知道,vpt 的值不再是 0x7fc0 0000 了,而是 vpt 的地址(恶心)。然后 (*vpt) 的值才是 0x7fc0 0000 。所以再结合 (*vpt) + VPN ,知道这是在计算二级页表项的虚拟地址,然后取地址,就可以得到二级页表项 *((*vpt) + VPN) = (*vpt)[VPN] 。
在有了这些知识打底的基础上,我们就可以看到底要干啥了,我们遍历了所有的二级页表项和一级页表项,如果他是有效的,那么就要给子进程复制他,人物交给了 duppage。
for (i = 0; i < VPN(USTACKTOP); ++i)
if (((*vpd)[i >> 10] & PTE_V) && ((*vpt)[i] & PTE_V))
duppage(newenvid, i);
然后我们需要设置一些子进程的对于 COW 的设置
syscall_mem_alloc进程的定义
1、进程是具有一定独立功能的程序在某个数据集合上的一次运行活动,是系统进行资源分配和调度的一个独立单位。
2、从操作系统看:进程分为系统进程和用户进程。系统进程执行操作系统的程序,完成操作系统的某些功能。用户进程运行用户程序,直接为用户服务。系统进程的优先级通常优于一般用户的进程。
3、进程是由程序、数据块和进程控制块(PCB)构成。进程(动态)是程序(静态)的一个执行过程,一个进程可以包括若干程序的执行,而一个程序也可以产生多个进程。
进程的状态与转换
进程从创建到终止的全过程一直处于不断变化的过程。为了表达进程的变化过程,所有的操作系统都把进程分为若干状态,约定各种状态间的转换条件。
1、三状态模型
进行中的进程处于三种状态之一:
运行状态:指进程已获得处理器,并且在处理器上执行的状态。在单处理器系统中,最多只有一个进程处于运行态。
就绪状态:指进程已经具备运行条件,但由于没有获得处理器而不能运行所处的状态。一旦处理其分配给它,该进程就可运行。处于就绪状态的进程可以是多个。
等待状态:也称阻塞或封锁状态,指进程因等待某种事件发生而暂时不能运行的状态。处于等待状态的进程可以是多个。
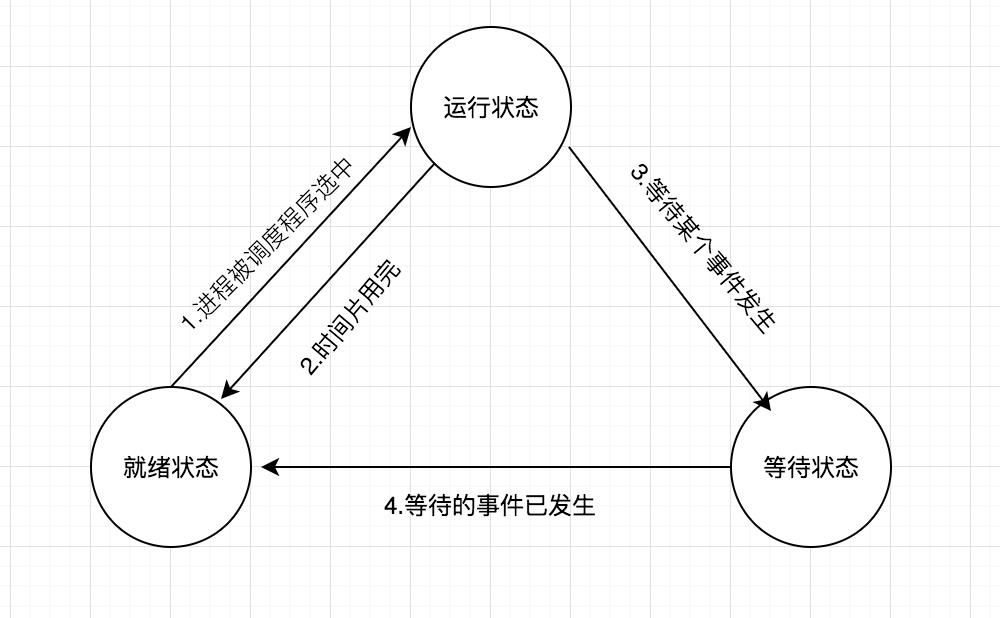
2、五状态模型
在五状态进程模型中,进程状态被分为五种状态.。进程在运行过程中主要是在就绪、运行和阻塞三种状态间进行转换。创建状态和退出状态描述进程创建的过程和进程退出的过程。
创建状态:进程正在创建中,还不能运行。操作系统在创建状态要进行的工作包括分配和建立进程控制块表项、建立资源表格,并分配资源,加载程序并建立地址空间等。
结束状态:进程已结束运行,回收除进程控制块之外的其他资源,并让其他进程从进程控制块中收集有关信息。