AD-NeRF 由音频和人脸图像合成人脸视频并表现出自然的说话风格
Posted 西西弗Sisyphus
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AD-NeRF 由音频和人脸图像合成人脸视频并表现出自然的说话风格相关的知识,希望对你有一定的参考价值。
AD-NeRF 由音频和人脸图像合成人脸视频并表现出自然的说话风格
flyfish
合成高保真音频驱动的面部视频序列在数字人类、聊天机器人和虚拟视频会议等许多应用中是一个重要而具有挑战性的问题。
将语音头部的生成过程视为从音频到视觉人脸的跨模态映射,期望合成的人脸图像表现出自然的说话风格,同时同步与原始视频相同的照片真实感的流媒体结果。
环境:
Ubuntu 18.04
NVIDIA Driver Version: 440.33.01
CUDA Version: 10.2 cuda-repo-ubuntu1804-10-2-local-10.2.89-440.33.01_1.0-1_amd64
libcudnn8_8.0.3.33-1+cuda10.2_amd64
Python: 3.7
PyTorch: torch-1.8.2+cu102-cp37-cp37m-linux_x86_64
PyTorch3D: pytorch3d-0.6.0-py37_cu102_pyt181
代码在以上环境能够正确处理数据和训练模型
本文的运行方案与官网有稍微不同
论文:https://arxiv.org/abs/2103.11078
代码:https://github.com/YudongGuo/AD-NeRF
论文题目《AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis》
本文AD-NeRF运行环境,模型和代码下载地址
链接:https://pan.baidu.com/s/1tvZOwFM8XAnJONPXNvkGYg
提取码:1l53
本文执行方案如下
先下载已经提供的AD-NeRF运行环境 包括cuda,cudnn,pytorch,pytorch3d,全部是匹配的版本,本地化安装不容易出现问题
内容包括
cuda-repo-ubuntu1804-10-2-local-10.2.89-440.33.01_1.0-1_amd64.deb
libcudnn8_8.0.3.33-1+cuda10.2_amd64.deb
libcudnn8-dev_8.0.3.33-1+cuda10.2_amd64.deb
pytorch3d-0.6.0-py37_cu102_pyt181.tar.bz2
torch-1.8.2+cu102-cp37-cp37m-linux_x86_64.whl
执行步骤
1 cuda和cudnn的安装
在 NVIDIA驱动是440版本的环境下安装上面已经下载的cuda和cudnn,其他驱动版本未测试
如果下载其他版本看这里
2 创建 anaconda虚拟环境,名字叫adnerf
conda env create -f environment.yml
conda activate adnerf
3 本地安装GPU版的PyTorch
pip install torch-1.8.2+cu102-cp37-cp37m-linux_x86_64.whl
4 本地安装PyTorch3D
conda install --use-local pytorch3d-0.6.0-py37_cu102_pyt181.tar.bz2
5 第三方模型位置
将"01_MorphableModel.mat" 放到 data_util/face_tracking/3DMM/
运行
cd data_util/face_tracking
python convert_BFM.py
文本已提供该模型
6 制作数据集
bash process_data.sh Obama
该数据集是通过 dataset/vids/Obama.mp4生成的数据集,网盘已包含生成的数据集
7 剩下的事情就可以按照官网提供的命令进行训练了
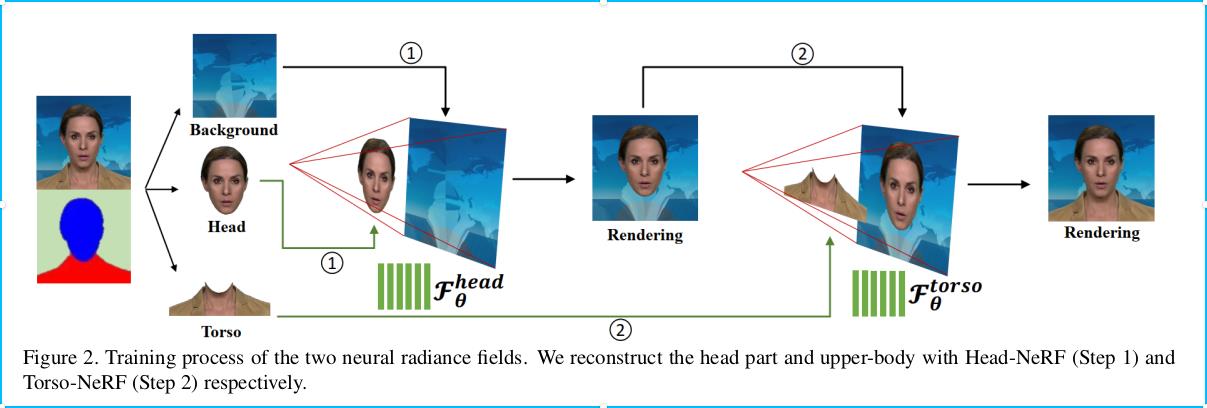
训练分两部
(1)训练Head-NeRF
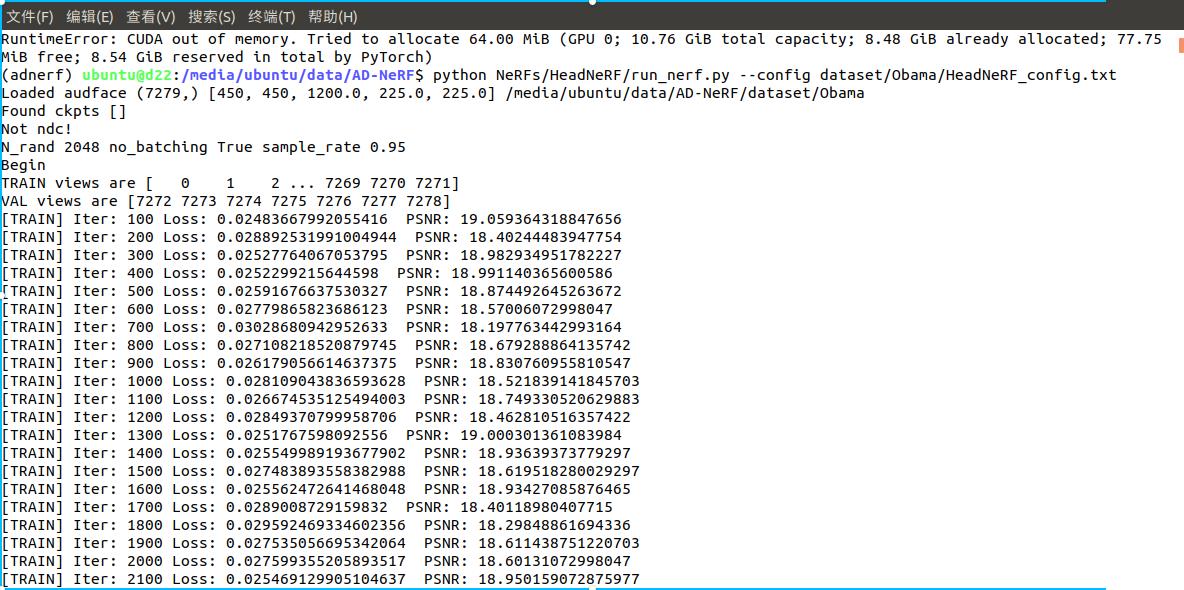
如果遇到与我相同的显存不足的问题,可以跳到8
python NeRFs/HeadNeRF/run_nerf.py --config dataset/Obama/HeadNeRF_config.txt
(2)训练TorsoNeRF
从AD-NeRF/dataset/Obama/logs/Obama_head找到最新的模型, 例如030000_head.tar重命名为head.tar
将head.tar放到AD-NeRF/dataset/Obama/logs/Obama_com中
执行名
python NeRFs/TorsoNeRF/run_nerf.py --config dataset/Obama/TorsoNeRF_config.txt
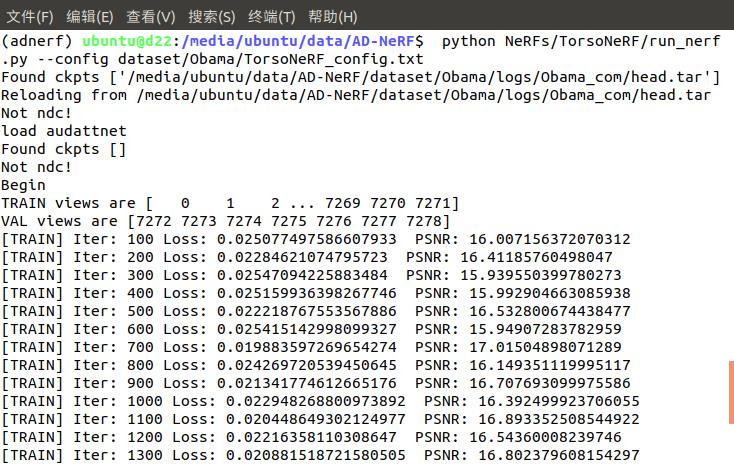
训练过程
8 显存不够的解决
(1)训练源码在12G显存下不够,所以改了下样本大小由64改到了32可以运行
AD-NeRF/NeRFs/HeadNeRF/run_nerf.py
AD-NeRF/NeRFs/TorsoNeRF/run_nerf.py
parser.add_argument("--N_samples", type=int, default=32,
...
(2)制作数据集时显存不够
AD-NeRF/data_util/face_tracking/face_tracker.py
搜索代码 batch_size
原来是50,这里改成10
batch_size = 10
人脸识别 介绍
人脸识别
人脸识别技术是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,
并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部的一系列相关技术,通常也叫做人像识别、面部识别
人脸识别流程
人脸识别技术流程主要包括四个组成部分,分别为:人脸图像采集及检测、人脸图像预处理、人脸图像特征提取以及匹配与识别
1.人脸图像采集
人脸图像采集方式分为两种,分别为批量人脸图像导入及现场视频人脸采集。
批量导入是指系统在用户指定的目录下面自动寻找图像文件进行人脸图像批量导入。现场视频人脸图像采集是指客户端的采集功能被打开后,会调用本地的摄像头并打开。当客户在采集设备的拍摄有效范围内,采集设备会自动搜索客户的人脸图像,当采集域上出现红色矩形时,采集设备已经搜索到客户的人脸图像,然后客户端进行自动采集图像。
2人脸图像质量择优
为了获得质量更高的人脸图片,提高比对精确性,我司的客户端组件带有人脸采集图片质量择优处理,可自动对当前图片质量进行检测,确保抓拍的照片符合人脸识别质量要求和人脸图像质量的判断方法,例如:通过两眼间像素数判断图像清晰度、判断人脸姿态角度等进行判断,在自动检测抓拍到清晰可辨人脸图片的同时,可大大提升用户体验。
3人脸检测
人脸检测在实际中主要用于人脸识别的预处理,即在图像中准确标定出人脸的位置和大小。人脸图像中包含的模式特征十分丰富,如直方图特征、颜色特征、模板特征、结构特征及Haar特征等。人脸检测就是把这其中有用的信息挑出来,并利用这些特征实现人脸检测。
主流的人脸检测方法基于以上特征采用Adaboost学习算法,Adaboost算法是一种用来分类的方法,它把一些比较弱的分类方法合在一起,组合出新的很强的分类方法。
人脸检测过程中使用Adaboost算法挑选出一些最能代表人脸的矩形特征(弱分类器),按照加权投票的方式将弱分类器构造为一个强分类器,再将训练得到的若干强分类器串联组成一个级联结构的层叠分类器,有效地提高分类器的检测速度。
2.人脸图像预处理
人脸图像预处理是对系统所采集到的人脸图像进行光线处理、切割、旋转、降噪、过滤、放大或缩小等一系列的复杂处理,通过这些处理使人脸图像无论是光线还是角度、距离、大小等达到人脸图像特征提取的标准要求,尽可能消除因光照和角度等因素造成的影响,为进行人脸图像特征提取做好准备。
3.人脸图像特征提取
人脸识别系统可使用的特征通常分为视觉特征、像素统计特征、人脸图像变换系数特征、人脸图像代数特征等。人脸特征提取就是针对人脸的某些特征进行的。人脸特征提取,也称人脸表征,它是对人脸进行特征建模的过程。人脸特征提取的方法归纳起来分为两大类:一种是基于知识的表征方法;另外一种是基于代数特征或统计学习的表征方法。
基于知识的表征方法主要是根据人脸器官的形状描述以及他们之间的距离特性来获得有助于人脸分类的特征数据,其特征分量通常包括特征点间的欧氏距离、曲率和角度等。人脸由眼睛、鼻子、嘴、下巴等局部构成,对这些局部和它们之间结构关系的几何描述,可作为识别人脸的重要特征,这些特征被称为几何特征。基于知识的人脸表征主要包括基于几何特征的方法和模板匹配法。
基于代数特征的方法的基本思想是将人脸在空域内的高维描述转化为频域或者其他空间内的低维描述。基于代数特征的表征方法分为线性投影表征方法和非线性投影表征方法。基于线性投影的方法主要有主成分分析法或称K-L变换,独立成分分析法和Fisher线性判别分析法。非线性特征提取方法有两个重要的分支:基于核的特征提取技术和以流形学习为主导的特征提取技术。
4.匹配与识别
4.1人脸识别1:1比对
人脸识别系统通过人脸识别算法实现上送两张图像进行比对,根据不同渠道的识别率返回比对结果,并将比对通过的图像按照设定规则入库保存。
1) 图片支持联网核查图片、证件身份芯片、现场抓拍图片。
2) 能够最大限度的提高识别率,智能的解决像素较低(如芯片图)、逆光、侧光、昏暗、带眼镜、一定角度侧脸等不利条件。
4.2人脸识别1:N比对
天诚盛业人脸识别系统通过上送客户图像,在客户特征库中识别出该将客户身份,并返回该客户的相关信息,如客户信息号、姓名等。系统具有人脸识别 1:N功能,对外提供 1:N比对接口,可根据各系统传送的照片提取特征值,并跟库中模板比对,返回相似度最高的N个人(返回人数可自定义)。
1)支持现场拍摄客户影响或短视频,并从中提取人脸影响功能。
2)支持根据影像从人脸数据库中检索出客户信息。
3)根据检索出的信息,发送到相应操作终端进行后续操作。
5. 应用领域:
- 金融行业:联网核查、刷脸支付、VIP客户识别等;
- 社保行业:离退休人员信息采集及身份信息核查;
- 教育行业:考生信息采集和身份识别;
- 公安行业:公安人脸照片比对、罪犯抓捕;
- 企事业单位:工作人员考勤、出入控制;
转自天诚盛业对人脸识别的分析。在人脸识别中我门要关注如下技术点:
1。基本流程
1.图像获取(从图片,摄像头,视频录像)
2.人脸识别比对(人脸预处理,特征提取,特征对比匹配与识别调用特征模型,结果输出)
3.模型训练(人脸大数据,DL深度学习)
2。如何进行 图像进行比对,最大限度的提高识别率,
智能的解决像素较低(如芯片图)、逆光、侧光、昏暗、带眼镜、一定角度侧脸等不利条件)
以上是关于AD-NeRF 由音频和人脸图像合成人脸视频并表现出自然的说话风格的主要内容,如果未能解决你的问题,请参考以下文章
人脸识别0视频分解图片与图片合成视频
人脸识别怎么用
人脸识别(face recognition)
人脸识别 介绍
图像人脸检测(框出人脸笑脸眼睛)
描述人脸识别的过程