ARMv8-A非对齐数据访问支持(Alignment support)
Posted SOC罗三炮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ARMv8-A非对齐数据访问支持(Alignment support)相关的知识,希望对你有一定的参考价值。
目录
2.1 Instruction alignment 指令对齐
2.2 Unaligned data access 非对齐数据访问
2.3 SCTLR.A Alignment check enable
3.1 Instruction alignment 指令对齐
3.2 Alignment of data accesses 对齐数据访问
3.3 普通Load 和Store指令(包括单寄存器和多寄存器)
3.4 Load-Exclusive/ Store-Exclusive 和Atomic 指令
3.7 FEAT_LSE2, Large System Extensions v2
如果非对齐访问出错,可以考虑以下问题:
- 当前架构是否支持非对齐数据访问。
- 系统控制寄存器SCTLR.A是否打开对齐访问检查功能。
- 使用的指令是否支持非对齐访问。
- 操作的对象(SP,PC,Normal memory,Device memory)是否支持非对齐访问。
- 当前系统所使用的是大端还是小端。
1,对齐传输和非对齐传输
参考Cortex-M3与Cortex-M4权威指南 第6.6章:
由于存储器系统为32位的(至少从编程模型的角度来看是这样的),大小为32位(4 byte(字节)字节,或 1 word(字))或16位(2字节,或半字)可以是对齐也可以是不对齐的。
对齐传输的意思是地址值为大小(以字节为单位)的整数倍。例如,字大小的对齐传输可以执行的地址为0x00000000、0x00000004、···、0x00001000、0x00001004等;类似地,半字大小的对齐传输可以执行的地址则为0x00000000、0x00000002、···、0x00001000、0x00001002等。
对齐和非对齐传输的实例下图所示。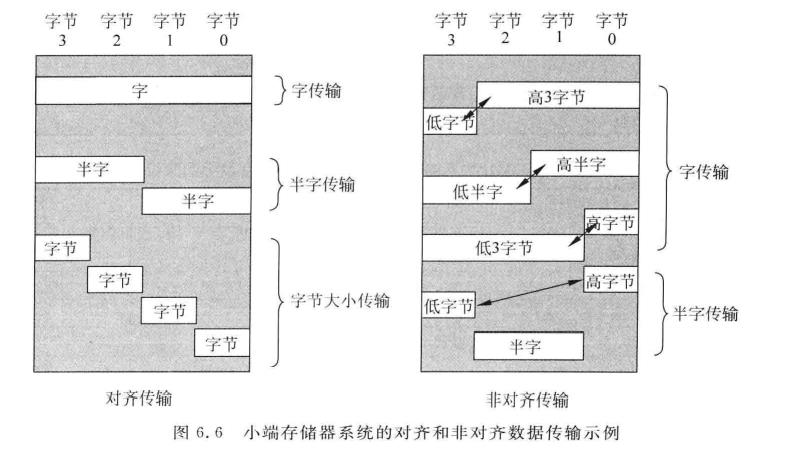
一般来说,多数经典ARM处理器(如ARM7 /ARM9 /ARM10)都只允许对齐传输。这就意味着在访问存储器时,字传输地址的bit[1]和bit[0]为0,而半字传输地址的bit[0]为0。例如,字数据可位于0x1000或0x1004,而不能位于0x1001、0x1002或0x1003,对于半字数据,地址可以为 0x1000 或 0x1002,而不能为 0x1001。所有的字节传输都是对齐的。
Cortex-M3和Cortex-M4处理器都支持普通存储器访问(如LDR、LDRH,STR以及STRH 指令)的非对齐数据传输。
另外还有一些限制:
- 多加载/存储指令不支持非对齐传输。
- 栈操作指令(PUSH/POP)必须是对齐的。
- 排他访问(如 LDREX 或 STREX)必须是对齐的,否则就会触发错误异常(使用错误)。
- 位段操作不支持非对齐传输,因为其结果是不可预测的。
当非对齐传输是由处理器发起时,它们实际上会被处理器的总线接口单元转换为多个对齐传输。这个转换是不可见的,因此应用程序开发人员无须考虑这个问题。
不过,当产生非对齐传输时,它会被拆分为几个对齐传输,因此本次数据访问会花费更多的时钟周期,可能对需要高性能的情形不利。若追求更高的性能,确保数据处于合适的对齐是有必要的。
多数情况下,C编译器不会产生非对齐传输,它只会在以下情况中出现:
- 直接操作指针。
- 包含非对齐数据的数据结构增加“_packed”属性。
- 内联/嵌入式汇编代码。
2,AArch32 Alignment support
2.1 Instruction alignment 指令对齐
A32 指令是 字对齐的(word-aligned)。
T32 指令是 半字对齐的(halfword-aligned)。
2.2 Unaligned data access 非对齐数据访问
在ARM A系列的实现中,通过一些Load/Store 指令是支持对Normal memory进行非对齐数据访问的。关于Normal memory和device memory的细节描述,可以参考博文:ARMv8内存属性与类型(Memory types and attributes)简介_arm 内存属性_SOC罗三炮的博客-CSDN博客
如下图红框中所示,有一部分的 Load/Store指令可以实现非对齐访问,比如最常用的LDR与STR指令。当然前提是,系统控制寄存器SCTLR里的对齐检查位没有被enable,即SCTLR.A = 0:
- 通过设置 SCTLR.A 位,可以控制除了Hyp mode外,其他任何模式下的对齐访问。
- 通过设置HSCTLR.A 位,可以控制Hyp mode下的对齐访问。

任何对Device memory的非对齐访问,都会产生对齐异常。
2.3 SCTLR.A Alignment check enable
SCTLR.A位控制住系统对Normal memory的非对齐访问。在PL0或者PL1下,检查对齐错误:
- SCTLR.A = 0, reset value,disable 对齐错误检查,在PL0或者PL1时,不会检查 Load/Store指令对一个或者多个寄存器进行操作时,访问的数据元素的大小与地址是否对齐。
- SCTLR.A = 1,enable 对齐错误检查,在PL0或者PL1时,不会检查 Load/Store指令对一个或者多个寄存器进行操作时,访问的数据元素的大小与地址是否对齐。如果发现非对齐访问,会产生Data Abort 异常。
此外,Load/store exclusive 和load-acquire/store-release指令自带对齐检查,所以会忽略SCTLR.A的值。
3,AArch64 Alignment support
3.1 Instruction alignment 指令对齐
A64 指令是 字对齐的(word-aligned)。
3.2 Alignment of data accesses 对齐数据访问
同A32一样,任何对Device memory属性的非对齐访问,都会造成对齐错误,产生Data Abort异常。
对于Normal memory的非对齐访问,其行为取决于:
- 内存访问的指令(load、store)
- 被访问的内存的内存属性(Normal 或者Device)
- SCTLR_ELx.A, nAA的值,是否打开对齐访问检查。
- FEAT_LSE2是否实现。
3.3 普通Load 和Store指令(包括单寄存器和多寄存器)
对于 普通的Load 和Store指令,无论是单寄存器操作还是多寄存器操作,如果被访问的地址与被访问的数据元素的大小不一致(非对齐访问),则:
- 如果SCTLR_ELx.A = 1,将会产生一个对齐错误。
- 如果SCTLR_ELx.A = 0,将执行非对齐访问(Normal memory)。
3.4 Load-Exclusive/ Store-Exclusive 和Atomic 指令
对于Load-Exclusive/ Store-Exclusive 和Atomic 指令,如果SCTLR_ELx.A = 1,将会产生一个对齐错误。
如果SCTLR_ELx.A = 0,这取决于FEAT_LSE2,具体分析可以查看文档:DDI0487G_a_armv8_arm.pdf。
3.7 FEAT_LSE2, Large System Extensions v2
FEAT_LSE2为 load和store操作引入 单次拷贝原子性需求(single-copy atomicity requirements)以及对齐访问需求(alignment requirements)。
- This feature is supported in AArch64 state only.
- This feature is OPTIONAL in Armv8.2 implementations.
- This feature is mandatory in Armv8.4 implementations
可通过ID_AA64MMFR2_EL1的AT位来查看是否实现了该属性。
与对齐的访问相比,未对齐的访问通常需要额外的周期(cycles)才能完成。
3.8 对齐访问SP寄存器
64 bit宽的Stack Pointer 寄存器,堆栈指针需要16个byte对齐。
当堆栈指针被用作计算的基址时,不管指令应用了任何偏移量,其中堆栈指针的[3:0]位不是0b0000,这就是非对齐的堆栈指针。处理器可以配置为:如果load/store指令使用了未对齐的堆栈指针,处理器将生成栈指针未对齐异常。
伪代码如下:

通过判断 SCTLR的 SA0或者SA位是否为0,从而决定是否产生栈指针非对齐异常。
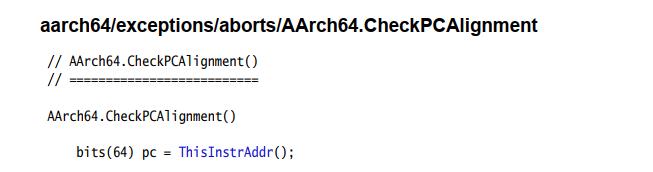
3.9 对齐访问 PC寄存器
64 bit宽的Program Counter 寄存器里保存着当前执行的指令的地址。如果执行A64 指令的时候不是 字对齐(word-aligned),将会产生PC 对齐错误。
PC对齐检查将生成一个与指令获取相关的PC对齐错误异常,在AArch64状态时,试图从架构上执行一条指令,该指令是用未对齐的PC获取的。非对齐的PC是指PC的[1:0]位不是0b00,也就是地址需要以0、4 、 8 、c结尾,比如PC可以为0x1000或0x1004,而不能为0x1001、0x1002或0x1003
一个PC 非对齐异常将会 把Exception Syndrome Register (ESR)寄存器的EC 位写入 0x22,并且会产生一系列的错误。
检查PC非对齐异常的伪代码如下:

参考文章:
非对齐访问和Alignment Fault
什么是对齐异常?
简单来说,当CPU访问内存地址时,如果发现访问的地址是不对齐的,硬件(部分)就会自动触发对齐异常。对齐即要求被访问的地址满足其数据类型的位宽要求,比如要访问一个4字节int型的数据,但是提供的地址不是4字节对齐的,那就是不对齐了。也就是说要访问的数据的位宽长度是多少,那么访问的地址就必须是按这个位宽长度对齐的。如果是char类型的,那就没有没有对齐要求了。
为什么在部分硬件上出现?
部分CPU硬件支持非对齐访问,典型的就是X86,X86硬件会自动处理非对齐访问情况,对软件透明,代价是牺牲效率。硬件处理简单来说就是通过多次访存操作,结合拼接(或拆分)操作实现,比如要读取一个4字节的int型数据,当地址在2字节的边界时,则需要进行两次内存读取操作,将边界前后的两个4字节的数据读取出来,然后取出其中的部分数据进行拼接,才能得到想要的数据,X86中,这些操作虽然都是由硬件自动完成,但是相对于对齐的数据访问来说,其性能损失也是非常明显的。
部分CPU“部分支持”非对齐访问,典型的就是ARM,其“单指令”操作支持非对齐,但“群指令”操作(SIMD)则不支持(必须对齐访问),如LDM、STM、LDRD、STRD。ARMv5指令集的CPU(一般是arm9架构)默认不支持非对齐内存访问,ARMv6及以上的CPU默认支持处理大部分的非对齐内存地址访问。
部分CPU硬件不支持对齐访问,但通过软件支持。典型的就是部分mips架构,其通过内核中对alignment fault异常处理流程中进行处理,比如将非对齐的数据访问,通过多次访存操作和拼接操作来处理,也可以使用类似memcpy的方式来处理,当然代价是更严重的性能损失。ARM架构内核中也有类似的处理分支,可以通过相关的配置来控制其处理方式。
定位方法
内核中的手段
Linux内核中有alignment=启动参数和/proc/cpu/alignment参数,用于控制出现alignment fault时默认的处理行为,具体定义如下:
alignment= [KNL,ARM]
Allow the default userspace alignment fault handler behaviour to be specified. Bit 0 enables warnings, bit 1 enables fixups, and bit 2 sends a segfault.
该参数由3位组成,第一位控制是否打印warning,第二位控制是否通过软件修复,第3位控制是否触发段错误。
通常,在出现alignment fault时,需要分析定位原因,而不能简单的通过内核的fixup或者忽略,由于由此带来的性能损耗是非常大的,当然如果您的环境中不在乎性能,那就另当别论了。
所以,通常在分析定位alignment fault异常时,需要设置bit0和bit2,即:
echo 5 > /proc/cpu/alignment
如此设置后,在出现alignment fault时,就能在messages中有较详细的打印,同时,正常情况下(除非禁用了),如果是出现在用户态,还会有core文件生成,如果是出现在内核态,则会除非die(),最终触发panic和kdump,生成vmcore,便于后续的深入分析。
分析思路
此类问题的具体分析思路为:
- 在搜集到core(或vmcore)文件后,使用gdb(或crash)工具进行分析。
- 确认出现问题的PC指针值
- 确认PC指针处触发问题的指令
- 确认PC指针处对应的具体代码行
- 分析代码逻辑,确认是否有可能导致出现对齐异常的代码编写问题,比如不同的指针类型直接的转换,或者是结构体中padding问题。
为什么出现?
我们了解,计算机中,CPU是通过总线访问内存的,而alignment fault正式总线控制器返回给CPU core的。不同的硬件,总线控制器的实现和配置不同,导致不同硬件上,对于非对齐访问的表现也不同,前面也做了说明。
那为什么部分CPU至今仍坚持不支持非对齐访问呢,最主要的原因肯定是性能问题了。如之前所说,非对齐访问带来的性能损耗是相当明显的,在目前主流的计算机体系下,其是一个明显的性能损失点,这也是性能调优过程中需要重点关注的点,特别是当CPU自身性能不济时,需要尤其关注,这就对程序猿们提出了更高的要求。
由于alignment fault对性能的影响,所以很多CPU中,会将此类问题当做一种异常上报,目的就是告诉用户:这里有性能隐患了,虽然我可能为您修复,但需要您的关注,建议您修正代码,以提升性能。
由什么引起?
出现alignment fault问题,通常是用户编写的代码导致。估计很多程序猿在编写代码(特别是c/c++代码)时,从未考虑过这样的问题,那是因为多数可能都在X86架构下的进行代码开发,而且没有考虑过代码的移植性,如前面所说X86硬件会自动处理非对齐问题,用户感知不到,但这种情况下,由此带来的性能损耗,用户可能也关注不到了。另一方面,部分情况下,编译器也会自动做padding处理(如对结构体的自动填充对齐),这也进一步让程序猿们减少了对alignment fault的关注。
最常见的可能导致alignment fault的代码编写方式如:
-
指针转换:将低位宽类型的指针转换为高位宽类型的指针,如:将char * 转为int *,或将void *转为结构体指针。这类操作是导致alignment fault的最主要的来源,在分析定位问题时,需要特别关注。对于出现异常却又必须这样使用的场景,对这类转换后的指针进行访问时,如果不能确认其对应的地址是对齐的,则应该使用memcpy访问(memcpy方式不存在对齐问题)。另外,建议转换后立即使用,不要将其传递到其他函数和模块,防止扩展,带来潜在的问题。
-
使用packed属性或者编译选项。这样的操作会关闭编译器的自动填充功能,从而使结构体中各个字段紧凑排列,如果排列时未处理好对齐,则可能导致alignment fault。一些场景下(内核中也较常见)确实需要用户自行紧凑排列结构体,可节省空间(在内存资源稀缺的场景下,很有用),此时需要特别关注对齐问题,建议通过填充的方法尽量对齐,如此可能会导致空间浪费,但是会提升访问性能,典型的“以空间换时间”的思路。如果对空间有强烈要求,而可以接受性能损失,也可以不考虑对齐,不做padding,但在访问这些结构体的数据时,需要全部使用memcpy的方式。
解决方案
通常,对于alignment fault有如下几种处理方法,不同的方法对性能影响不同,如下按性能从高到低描述:
程序猿保证对齐
这是最理想的解决方案,没有性能损失(但可能会有一定的空间浪费),对程序猿们的要求也比较高,但确实非常非常有必要。
写代码时需要记住:数据地址应该至少对齐到与访问宽度相同的水平。即:1字节访问无需对齐,2字节访问需要地址能被2整除,4字节访问需要地址能被4整除,8字节访问需要地址能被8整除。
另一方面,主流编译器通常会自动的通过填充pad来辅助处理对齐问题,程序猿们编程代码时,通常只需要关注:尽量将数据宽度大的字段(也即较长的double/longlong型变量)放到结构体的前面即可,如此,数据宽度较小的字段无需编译器补齐,从而可以节约内存。
此外,寄存器宽度也对对齐有影响,通常情况下,寄存器宽度即代表了最高的对齐要求,例如32位的arm,在载入8字节的数据(如longlong型)时,也只需要4字节对齐。另外需要注意一些cpu的拥有SIMD指令,这些指令对应的寄存器宽度往往要远大于cpu自己的核心寄存器,因而也会有更高的对齐要求。
还有,虽然memcpy(或memset)的方式不要求对齐,但对于device类型(linux内核中分配内存时指定)的内存,部分架构下(如ARM64)不能使用memcpy(或memset)的方式访问,否则也会出现alignment fault,具体案例请参考我的另一篇文章。
硬件处理
如前所述,一些CPU硬件自身已经支持非对齐访问,并且在多数情况下能够支持“快速非对齐访问”。这里的“快速”,指的是使用单个不对齐访问指令快于(拆分不对齐访问后产生的)两条对齐访问指令的情况。在这样的硬件下,我们通常无需在软件层面上做出特殊的布置和调整。但是,对于性能有要求的代码,还是需要慎重考虑是否添加pad来消除不对齐,因为到目前为止不对齐访问仍然明显的慢于对齐访问。
编译器或代码拆分
当cpu不能进行快速不对齐访问时,为了提高代码执行效率,应该在软件层面拆分不对齐访问指令。
现代的编译器通常都有对不对齐访问的特殊处理(例如gcc中的munaligned-access等选项)。当编译器检查到不对齐的访问(并且对应的目标硬件不支持快速不对齐访问时),会自动生成拆分访问的代码。但是,需要特别注意,编译器在编译时无法获知所有指针的地址信息,因此不能完全对齐对齐问题。
代码拆分,需要程序猿自行将不对齐的内存访问拆分成对齐的变量访问。例如一个int x指针,当我们知道x只是双字节对齐时,就要将其拆分两个short,如果不知道其地址的对齐情况,可以先对该指针地址进行4或者2的求余再来决定如何拆分,当然,这种情况下,也可以直接调用memcpy进行拷贝。在现代编译器中memcpy等常用函数已经被编译器高度优化了,其实现逻辑和我们前面手写代码是完全一样的。
内核处理
如前面描述,Linux内核(部分架构,如ARM)自身提供了对alignment fault的异常处理机制,对于内核来说alignment fault被当做一种异常来处理,类似于缺页异常,通常,该异常由硬件触发(x86等硬件自动处理的架构不会触发此类异常),内核捕获后进行相应处理,比如进行一些fixup操作,如果修复成功,则万事大吉,用户感知不到(但性能上损耗严重),如果不能修复,则进行后续处理,大致流程为:
- 判断是内核态还是用户态触发
- 如果是用户态,则给用户进程发送Sigbus信号,用户进程收到信号后触发coredump,搜集core文件。
- 如果是内核态,则直接进入die()流程,最终触发panic和kdump,搜集vmcore
以上是关于ARMv8-A非对齐数据访问支持(Alignment support)的主要内容,如果未能解决你的问题,请参考以下文章