Redis缓存一致性
Posted Al6n Lee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis缓存一致性相关的知识,希望对你有一定的参考价值。
文章目录
缓存一致性
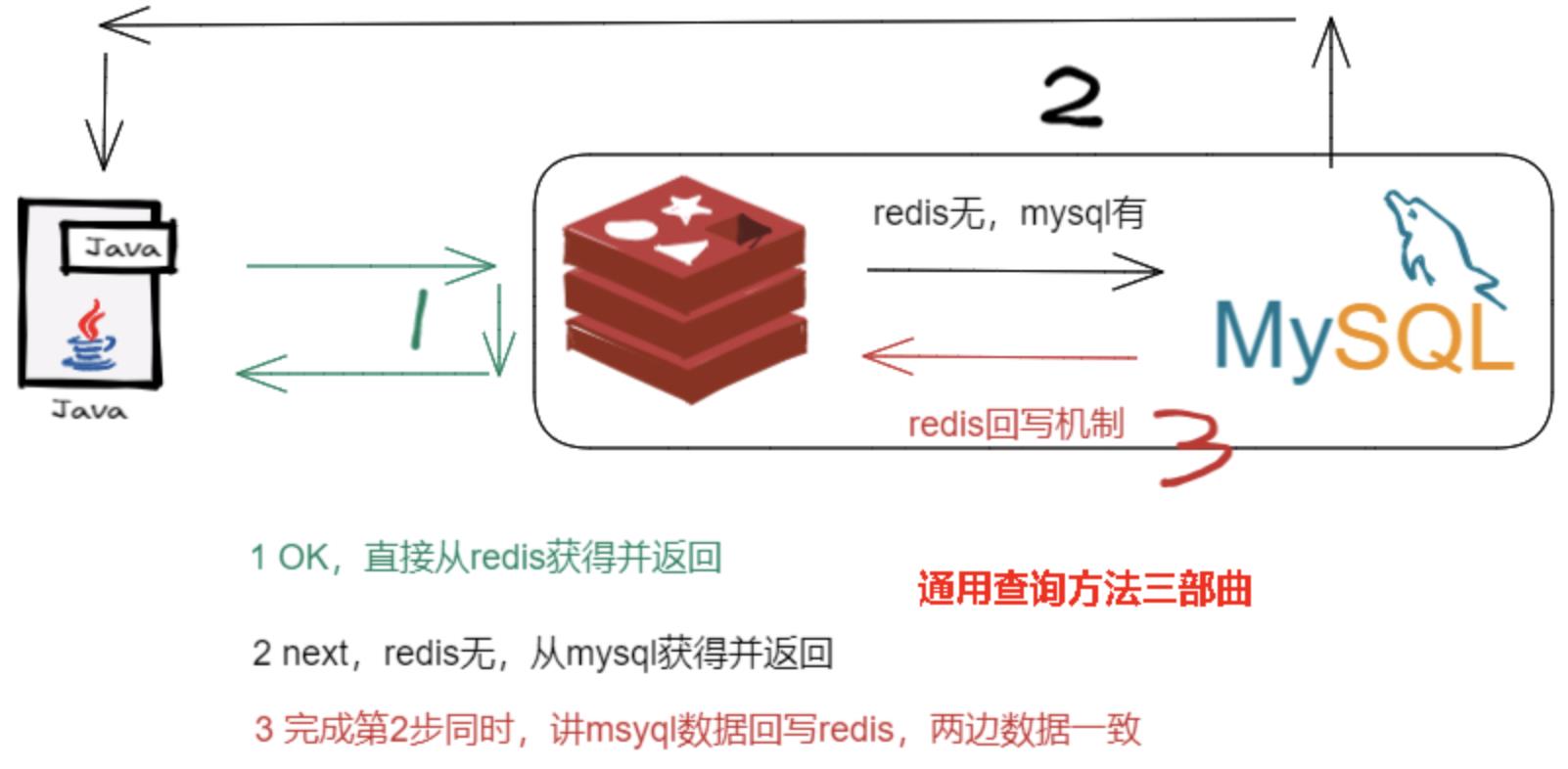
读缓存
双检加锁策略
采用双检加锁策略
- 多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。
- 其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。
- 后面的线程进来发现已经有缓存了,就直接走缓存。
package com.atguigu.redis.service;
import com.atguigu.redis.entities.User;
import com.atguigu.redis.mapper.UserMapper;
import io.swagger.models.auth.In;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.stereotype.Service;
import org.springframework.web.bind.annotation.PathVariable;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
/**
* @auther zzyy
* @create 2021-05-01 14:58
*/
@Service
@Slf4j
public class UserService
public static final String CACHE_KEY_USER = "user:";
@Resource
private UserMapper userMapper;
@Resource
private RedisTemplate redisTemplate;
/**
* 业务逻辑没有写错,对于小厂中厂(QPS《=1000)可以使用,但是大厂不行
* @param id
* @return
*/
public User findUserById(Integer id)
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
//2 redis里面无,继续查询mysql
user = userMapper.selectByPrimaryKey(id);
if(user == null)
//3.1 redis+mysql 都无数据
//你具体细化,防止多次穿透,我们业务规定,记录下导致穿透的这个key回写redis
return user;
else
//3.2 mysql有,需要将数据写回redis,保证下一次的缓存命中率
redisTemplate.opsForValue().set(key,user);
return user;
/**
* 加强补充,避免突然key失效了,打爆mysql,做一下预防,尽量不出现击穿的情况。
* @param id
* @return
*/
public User findUserById2(Integer id)
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql,
// 第1次查询redis,加锁前
user = (User) redisTemplate.opsForValue().get(key);
if(user == null)
//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class)
//第2次查询redis,加锁后
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null)
//4 查询mysql拿数据(mysql默认有数据)
user = userMapper.selectByPrimaryKey(id);
if (user == null)
return null;
else
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
return user;
写缓存
保障最终数据一致性解决方案
- 给缓存设置过期时间
- 定期清理缓存并回写
先更新数据库,再更新缓存
-
案例演示1->更新缓存异常
- 先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。
- 先更新mysql修改为99成功,然后更新redis。
- 此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100 。
- 上述发生,会让数据库里面和缓存redis里面数据不一致,读到redis脏数据
-
案例演示2->并发导致
-
A、B两个线程发起调用;A写,B写
1 A update mysql 100 3 B update mysql 80 4 B update redis 80 2 A update redis 100 -
最终结果:mysql80,redis100->数据不一致
-
先更新缓存,再更新数据库
不推荐,业务上一般把mysql作为底单数据库,保证最后解释
-
案例演示->并发导致
-
A、B两个线程发起调用;A写,B写
A update redis 100 B update redis 80 B update mysql 80 A update mysql 100 -
最终结果:mysql100,redis80->数据不一致
-
先删除缓存,再更新数据库
-
案例演示->并发导致
-
A、B两个线程发起调用;A写,B读
- 请求A进行写操作,删除redis缓存后,工作正在进行中,更新mysql…A还么有彻底更新完mysql,还没commit
- 请求B开工查询,查询redis发现缓存不存在(被A从redis中删除了)
- 请求B继续,去数据库查询得到了mysql中的旧值(A还没有更新完)
- 请求B将旧值写回redis缓存
- 请求A将新值写入mysql数据库
-
总结
时间 线程A 线程B 出现的问题 t1 请求A进行写操作,删除缓存成功后,工作正在mysql进行中… t2 1 缓存中读取不到,立刻读mysql,由于A还没有对mysql更新完,读到的是旧值 2 还把从mysql读取的旧值,写回了redis 1 A还没有更新完mysql,导致B读到了旧值 2 线程B遵守回写机制,把旧值写回redis,导致其它请求读取的还是旧值,A白干了。 t3 A更新完mysql数据库的值,over redis是被B写回的旧值,mysql是被A更新的新值。出现了,数据不一致问题。
-
-
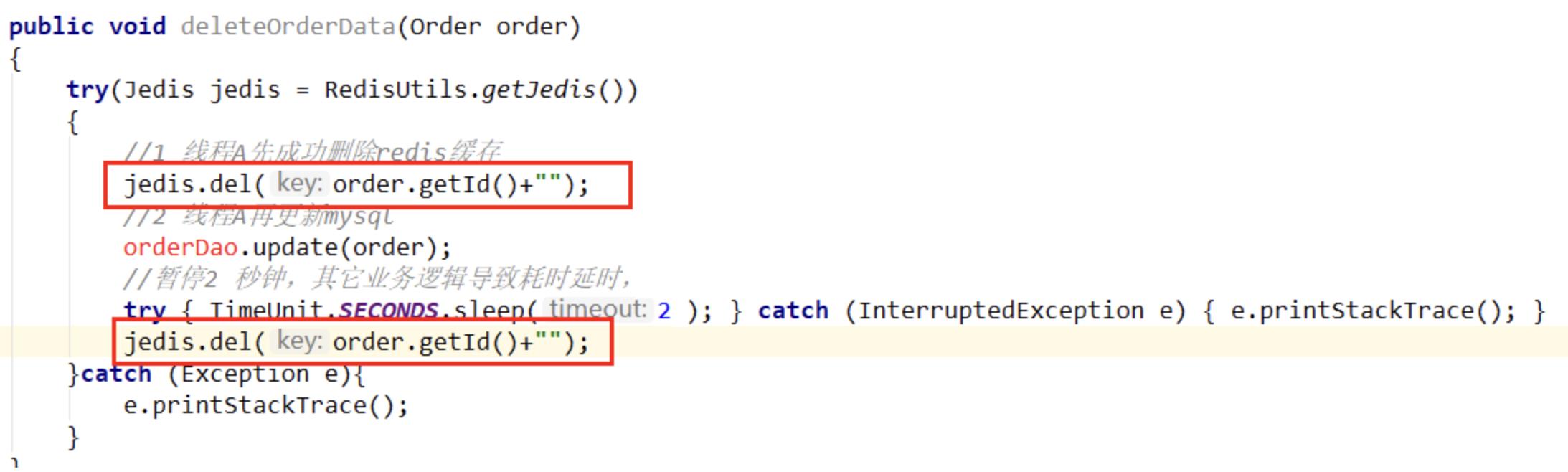
解决策略->延时双删
加上sleep的这段时间,就是为了让线程B能够先从数据库读取数据,再把缺失的数据写入缓存,然后,线程A再进行删除。所以,线程Asleep的时间,就需要大于线程B读取数据再写入缓存的时间。这样一来,其它线程读取数据时,会发现缓存缺失,所以会从数据库中读取最新值。因为这个方案会在第次删除缓存值后,延迟一段时间再次进行删除,所以我们也把它叫做“延迟双删”
-
删除该休眠多久合适?
-
方式一:
在业务程序运行的时候,统计下线程读数据和写缓存的操作时间,自行评估自己的项目的读数据业务逻辑的耗时,
以此为基础来进行估算。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上加百毫秒即可。
-
方式二
新启动一个后台监控程序,比如后面要讲解的WatchDog监控程序,会加时
-
-
先更新数据库,再删除缓存(推荐~~)
-
案例演示1->更新缓存异常
-
A、B两个线程发起调用;A写,B读
t3时间上线程A更新Redis缓存失败,会导致Redis缓存与mysql数据不一致的情况发生
时间 线程A 线程B 出现的问题 t1 更新数据库中的值… t2 缓存中立刻命中,此时B读取的是缓存旧值。 A还没有来得及删除缓存的值,导致B缓存命中读到旧值。 t3 更新缓存的数据,over
-
-
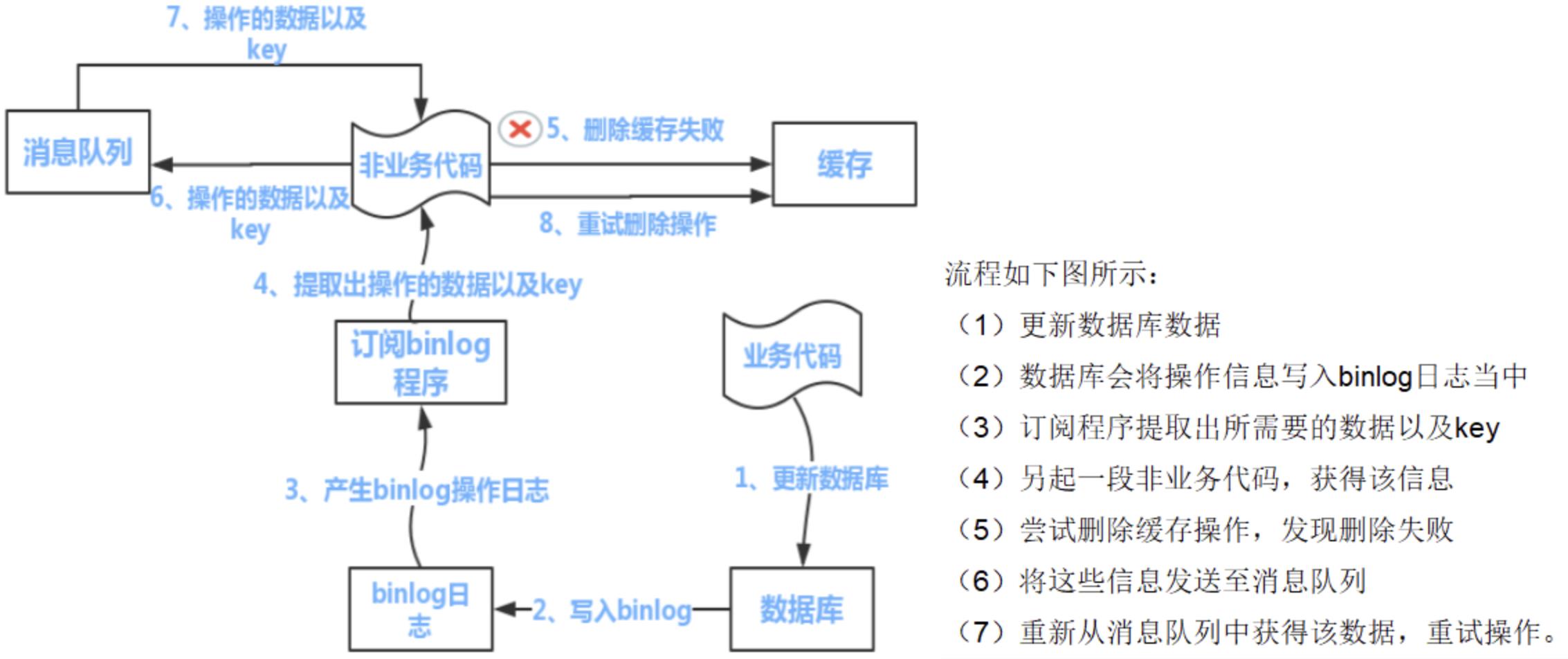
解决策略->消息队列重试写Redis缓存
-
可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka/RabbitMQ等)。
-
当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后再次进行删除或更新。
-
如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存的数据一致了,否则还需要再次进行重试
-
如果重试超过的一定次数后还是没有成功,我们就需要向业务层发送报错信息了,通知运维人员。
-
如何选方案
优先使用先更新数据库,再删除缓存的方案(先更库→后删存)
- 先删除缓存值再更新数据库,有可能导致请求因缓存缺失而访问数据库,给数据库带来压力导致打满mysql。
- 如果业务应用中读取数据库和写缓存的时间不好估算,那么,延迟双删中的等待时间就不好设置。
| 策略 | 高并发多线程条件下 | 问题 | 现象 | 解决方案 |
|---|---|---|---|---|
| 先删除redis缓存,再更新mysql | 无 | 缓存删除成功但数据库更新失败 | Java程序从数据库中读到旧值 | 再次更新数据库,重试 |
| 有 | 缓存删除成功但数据库更新中…有并发读请求 | 并发请求从数据库读到旧值并回写到redis,导致后续都是从redis读取到旧值 | 延迟双删 | |
| 先更新mysql,再删除redis缓存 | 无 | 数据库更新成功,但缓存删除失败 | Java程序从redis中读到旧值 | 再次删除缓存,重试 |
| 有 | 数据库更新成功但缓存删除中…有并发读请求 | 并发请求从缓存读到旧值 | 等待redis删除完成,这段时间有数据不一致,短暂存在。 |
Redis与MySQL数据双写一致性工程落地

阿里巴巴开源的中间件-canal
定义
定义:历史背景是早期阿里巴巴因为杭州和美国双机房部署,存在跨机房数据同步的业务需求,实现方式主要是基于业务 trigger(触发器) 获取增量变更。从2010年开始,阿里巴巴逐步尝试采用解析数据库日志获取增量变更进行同步,由此衍生出了canal项目
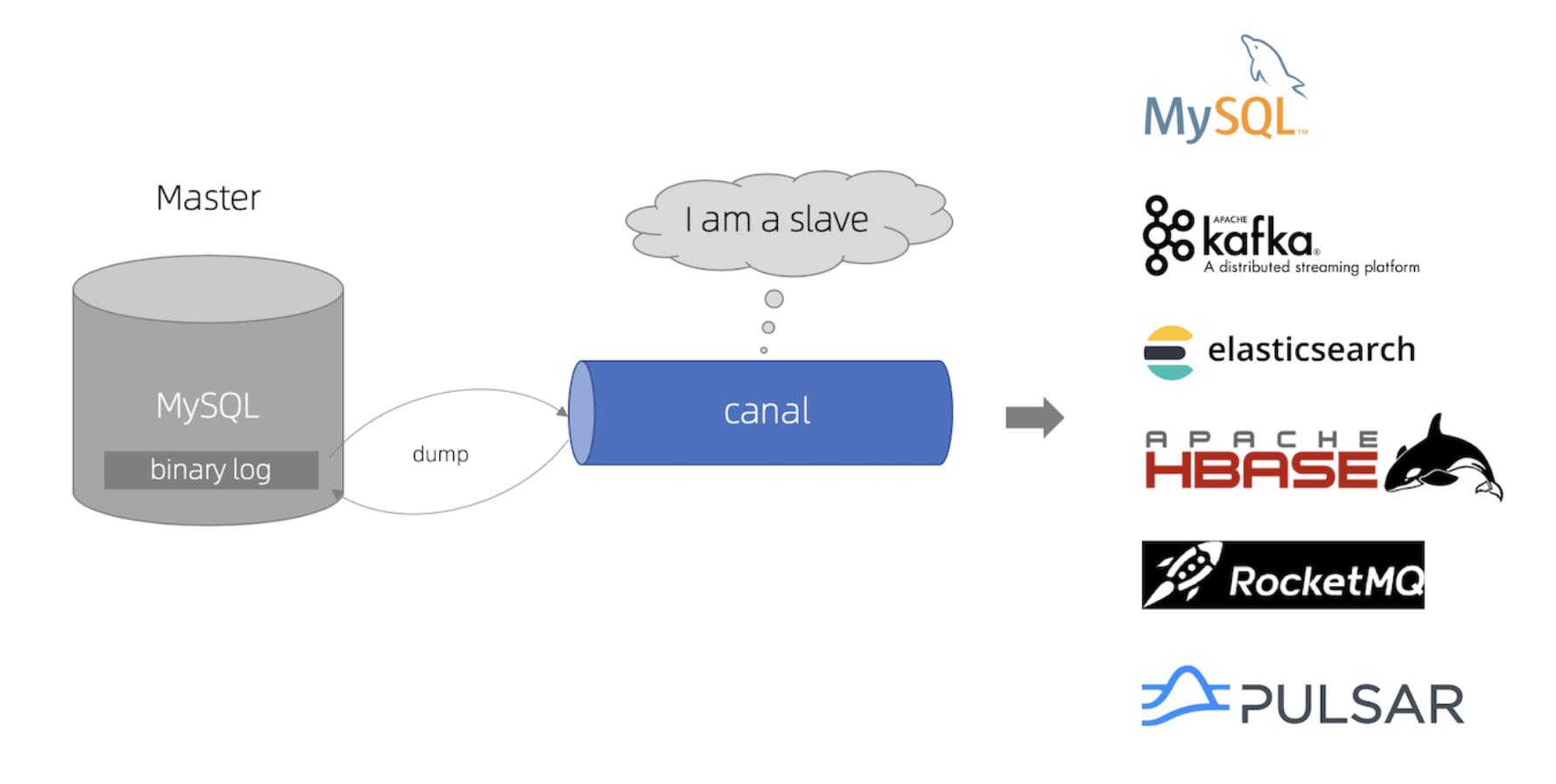
作用
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
下载
工作原理
-
MySQL的主从复制
-
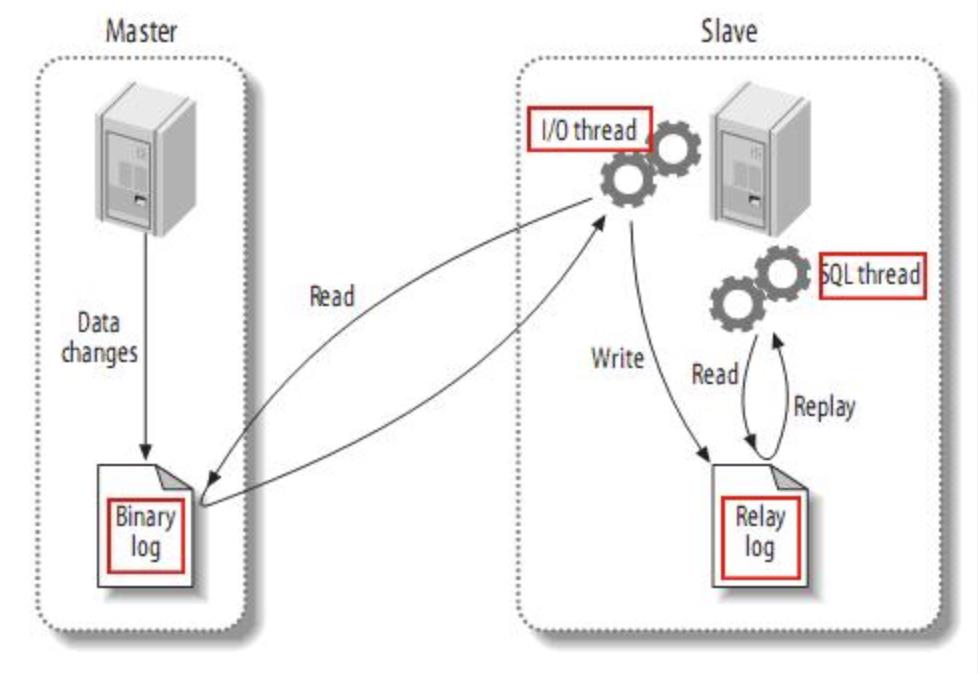
当 master 主服务器上的数据发生改变时,则将其改变写入二进制事件日志文件binlog中;
-
salve 从服务器会在一定时间间隔内对 master 主服务器上的二进制日志进行探测,探测其是否发生过改变,如果探测到 master 主服务器的二进制事件日志发生了改变,则开始一个 I/O Thread 请求 master 二进制事件日志;
-
同时 master 主服务器为每个 I/O Thread 启动一个dump Thread,用于向其发送二进制事件日志
-
slave 从服务器将接收到的二进制事件日志保存至自己本地的中继日志文件中;
-
salve 从服务器将启动 SQL Thread 从中继日志中读取二进制日志,在本地重放,使得其数据和主服务器保持一致;
-
最后 I/O Thread 和 SQL Thread 将进入睡眠状态,等待下一次被唤醒;
-
-
canal工作原理
-
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave,向 MySQL master 发送dump 协议
-
MySQL master 收到 dump 请求,开始推送 binary log 给 slave ( canal )
-
canal解析 binary log 对象(原始为 byte 流)
-
一致性工程案例
MySQL
-
查看当前主机二进制日志
show master status;
-
查看log_bin日志状态
show variables like 'log_bin';
-
开启MySQL的binlog写入功能(Windows下的my.ini配置文件,Linux下的my.cnf配置文件)

log-bin=mysql-bin #开启 binlog binlog-format=ROW #选择 ROW 模式 server_id=1 #配置MySQL replaction需要定义,不要和canal的 slaveId重复 ROW模式 除了记录sql语句之外,还会记录每个字段的变化情况,能够清楚的记录每行数据的变化历史,但会占用较多的空间。 STATEMENT模式只记录了sql语句,但是没有记录上下文信息,在进行数据恢复的时候可能会导致数据的丢失情况; MIX模式比较灵活的记录,理论上说当遇到了表结构变更的时候,就会记录为statement模式。当遇到了数据更新或者删除情况下就会变为row模式; -
重启MySQL
-
验证开启binlog是否成功
show variables like 'log_bin'; -
授权canal连接mysql的账号
-
查看当前目录下的账号
SELECT * FROM mysql.user;
-
创建账号并授权(此次mysql版本为5.7)
[删除canal用户,可忽略] DROP USER IF EXISTS 'canal'@'%'; CREATE USER 'canal'@'%' IDENTIFIED BY 'canal'; GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' IDENTIFIED BY 'canal'; FLUSH PRIVILEGES; [查看是否添加成功] SELECT * FROM mysql.user;
-
canal服务端
-
下载
canal.deployer-1.1.6.tar.gz:https://github.com/alibaba/canal/releases/tag/canal-1.1.6
-
解压
-
配置
修改/mycanal/conf/example路径下instance.properties文件
-
换成自己的mysql主机master的IP地址
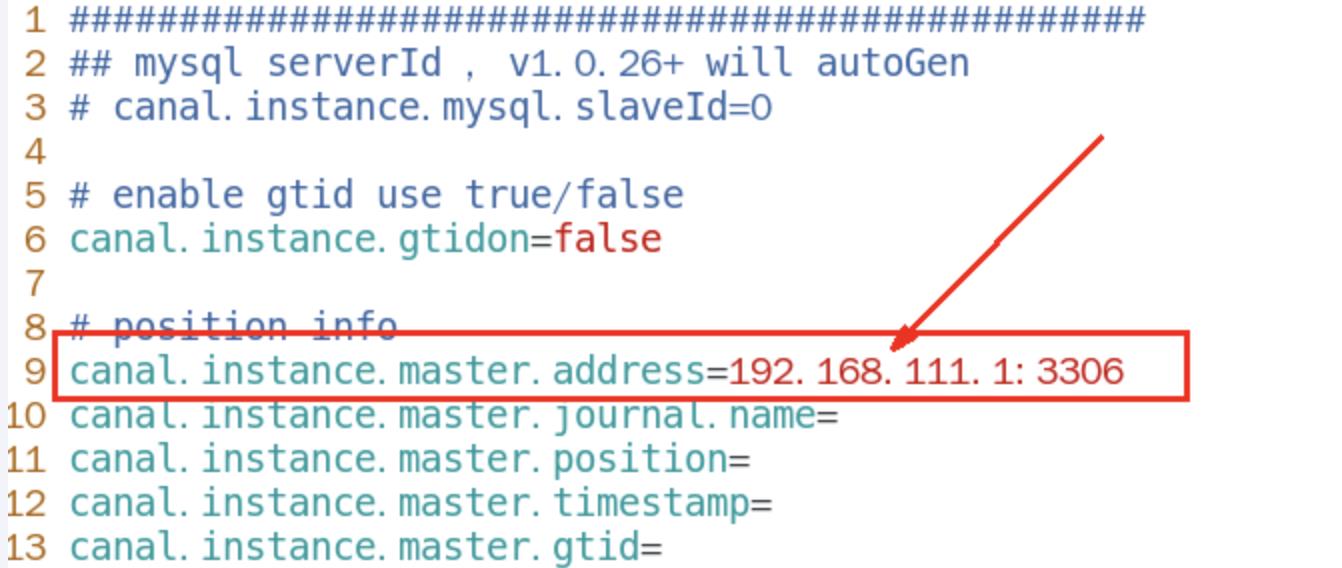
-
换成自己的在mysql新建的canal账户
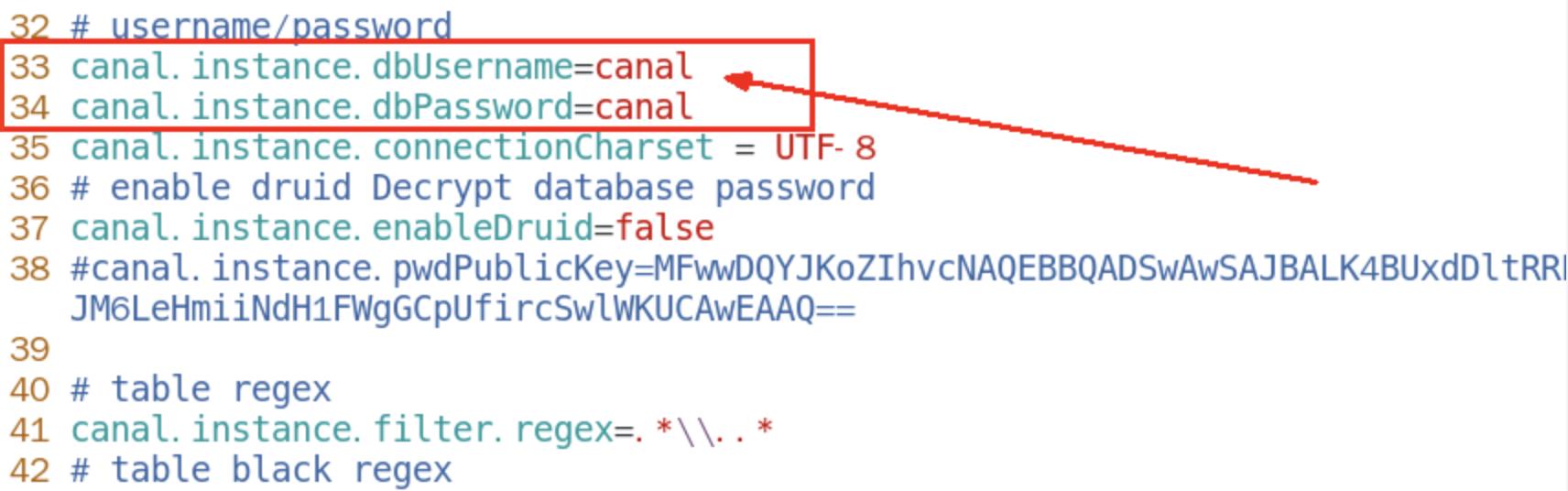
-
-
启动
/opt/mycanal/bin路径下执行
./startup.sh
-
查看验证
-
查看server日志

-
查看样例example的日志
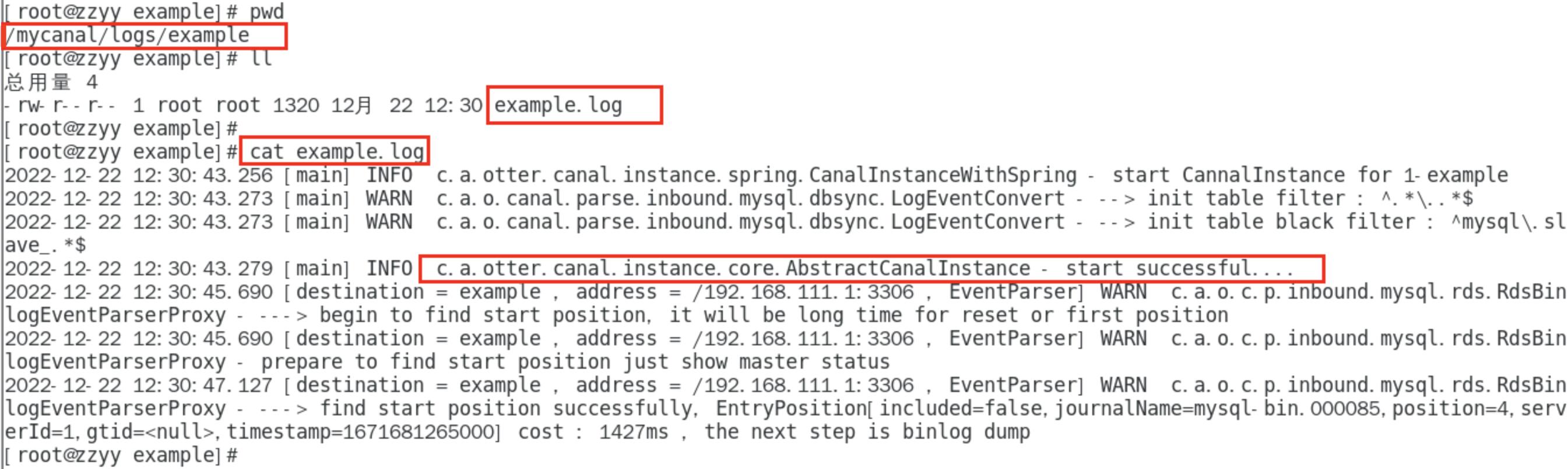
-
canal客户端
redis缓存一致性讨论
总结不易,如果对你有帮助,请点赞关注支持一下
微信搜索程序dunk,关注公众号,获取博客源码、数据结构与算法笔记(超级全)、大厂面试、笔试题
目录
上下文 & QA
最近工作遇到一个场景,需要将数据库中某一张表的所有数据全部捞出来,放在缓存中。
为什么要用缓存?
因为对方接口QPS比较高,对方接口每次执行时,最坏情况会调用我方接口三次,其中每次都需要全量查询db进行过滤,因此为了提高接口的QPS,考虑将db所有数据全量捞出,缓存在redis中。
为什么使用hash?
因为该表中一行数据字段较多,一方面:如果采用string存储,那么这个key将会是一个很大的key,会占用大概几KB-几M的内存,不方便保存,每次都要将全量捞出来,在做处理,增加了通信代价,另一方面:考虑后期存在对该表数据的crud,为了保证缓存一致性,需要更新缓存,如果采用string存储,每次刷缓存的时候都需要需要全量来一遍,在缓存没命中的呢次,接口QPS会很高,如果使用hash,每次只用更新对应的field即可,代价很小。
为什么每次crud的时候要异步刷新缓存?
主要目的是为了不让缓存更新失败而导致整个操作失败,允许短期缓存不一致,同时,增加定时任务、监控告警,补偿缓存。
定时任务怎么补偿?
- 每1h执行一次,先执行补偿更新(刷新近6h有过更新的数据),实质是补偿update 和 create 操作
- 捞db和缓存对应数据量是否一致,不一致找到缓存比db多的数据,删除对应缓存,实质补偿delete操作
如何防止缓存穿透而导致多个线程同时全量扫db?
使用golang自带的singleflight,其实我觉得有点类似于java里面的semaphore多个线程并发访问,我只给一个信号量,其他线程来了等着,执行全量的线程执行完了,其他线程拿结果就行了,后面会讲讲singleflight怎么用的。
tips:
redis不支持设置hash缓存中每个field的过期时间,只支持设置整个key的过期时间;redis也不支持在HSET的时候设置过期时间,所以需要执行Expire为整个key设置过期时间,但是如果访问两次redis,那么这个操作不是原子性的,可能会存在一个成功,一个失败的情况,不利于回滚。所以需要使用lua脚本执行redis的命令,保证操作的原子性。
下面将介绍一下redis的缓存一致性问题和redis执行lua脚本的操作
缓存一致性
使用redis的时候必然会遇到一个问题就是:数据库和缓存的一致性问题,这个问题产生的原因是:更新数据库和更新redis是两个步骤,那就有可能一个更新成功,一个更新失败,这时就是产生缓存一致性问题。
缓存类型
按照Redis缓存是否接受写请求,可以将缓存分为:只读缓存、读写缓存
- 只读缓存:数据库更新后,删掉缓存中的数据,下一次读取缓存时发生缓存缺失,再从数据库读取数据写回缓存。
- 读写缓存:数据库更新后,同步更新缓存中的数据,下一次读取缓存时就会直接命中缓存。
区别
- 只读缓存是删除缓存中的数据,下次访问这个数据时,会重新读取数据库中的值,这样可以保证数据库和缓存完全一致,并且缓存中保留的是经常访问的热点数据。缺点是删除缓存后,之后的访问会先触发一次缓存缺失,然后从数据库读取数据,这个过程访问延迟会变大。
- 读写缓存是同步更新缓存中的值,这样被修改的数据永远都在缓存中,下次访问能够直接命中缓存,不再查询数据库,这个过程性能比较好,比较适合先修改又立即访问的场景。缺点是在高并发场景下,并发更新同一个值时,可能会导致缓存和数据库的不一致;并且对于某些缓存值的计算可能会比较复杂,但是又不常访问,那么缓存的利用率就会降低,更新缓存的代价就比较大。
选择
只读缓存牺牲了一定的性能,优先保证数据库和缓存的一致性,它更适合对于一致性要求比较要高的场景。而如果对于数据库和缓存一致性要求不高,或者不存在并发修改同一个值的情况,那么使用读写缓存就比较合适,它可以保证更好的访问性能,但要考虑到缓存更新的代价。
只读缓存
新增数据
对于新增数据,先将数据写入数据库中,缓存有两种处理方式
- 新增时不做任何处理,下次查询缓存时从数据库查询写回缓存;
- 新增时同步写入缓存
无论哪种方式,缓存最终都是一致的
更新数据
- 先删缓存,再更新数据库,删缓存成功,更新数据库失败:此时缓存没有值,数据库是旧值,下次查询触发缓存缺失,读取数据库的旧值,缓存与数据库是一致的。
- 先更新数据库,再删缓存,更新数据库成功,删缓存失败:删缓存失败时
- 如果能回滚数据库更新,那么缓存和数据库的值是一致的。
- 如果不能回滚数据库更新,那么缓存是旧值,数据库是新值,出现数据不一致。
先删缓存,再更新数据库则没有不一致的问题。所以一般采用
先删缓存,再更新数据库的模式。
并发读写
- 并发
写+读- A线程先删缓存,B线程读缓存,缓存失效,读数据库并写入缓存,A线程更新数据库,数据库时新值,缓存是旧值,数据不一致。
- A线程先更新数据库,B线程读缓存,读到旧值,接着A线程删除缓存,缓存失效后会被下次查询操作更新为新值,只会短暂出现缓存不一致现象,对业务影响较小。
- 并发
写+写都会先删除缓存,再更新数据库,然后会触发缓存失效从而更新缓存,最终数据一致
对于并发写+读的第一种情况,可以使用延迟双双删:就是在 先删缓存,后更新数据库后,sleep 一小段时间,再进行一次缓存删除操作。sleep 的时间就约等于B线程 读取数据+写入缓存的时间,这样就可以在B线程写入旧缓存,A线程更新完数据库后,再次删掉旧缓存。
读写缓存
新增数据
和只读缓存一样,不会出现数据不一致情况
更新删除数据
- 先更新缓存,再更新数据库,更新缓存成功,更新数据库失败:此时缓存中是新值,数据库是旧值,出现数据不一致
- 先更新数据库,再更新缓存,更新数据库成功,更新缓存失败
- 如果更新缓存失败时,可以回滚数据库操作,那么数据库和缓存都是旧值,数据一致
- 如果没有回滚,那么数据库是新值,缓存是旧值,数据不一致
无论先更新缓存还是先更新数据库,只要第二步失败了,就会导致缓存不一致
这里可以增加重试机制,把第二部操作放入MQ中,如果更新没有成功,可以从消息队列中取出消息,执行更新数据库或者缓存的操作,成功后删除消息,否则重试,以此达到数据库和缓存的最终一致。如果多次重试失败,可以发送告警信息。
并发读写
更新缓存和数据库都成功
- 并发
写+读,A线程先更新数据库,B线程读缓存,A线程再更新缓存,此时B线程读到旧值,出现短暂的不一致性,对业务影响比较小。 - 并发
写+读,A线程先更新缓存,B线程读缓存,A线程再更新数据库,此时B线程读到新值,数据是一致的,对业务没有影响。 - 并发
写+写,A、B 线程并发更新同一条数据,先更新缓存,再更新数据库,顺序为 A更新缓存 -> B更新缓存 -> B更新数据库 -> A更新数据库,这时数据库和缓存的数据不一致。 - 并发
写+写,A、B 线程并发更新同一条数据,先更新数据库,再更新缓存,顺序为 A更新数据库 -> B更新数据库 -> B更新缓存 -> A更新缓存,这时数据库和缓存的数据不一致。
可以看到并发
写+写,会出现数据不一致的情况,对业务影响较大,针对这种情况,可以使用分布式锁来保证多个线程操作同一资源的顺序性,同一时间只允许一个线程去更新数据库和缓存,以此保证一致性。但对并发更新的性能会有较大的影响,需要权衡。
总结
对比下读写缓存和只读缓存模式:
- 读写缓存模式下,无论先更新缓存、再更新数据库,还是先更新数据库、再更新缓存,第二步失败都可能导致数据不一致,解决方案是第二步增加
重试机制。存在并发写的情况,可以增加分布式锁保证更新顺序的一致性。 - 只读缓存模式下,采用
先删缓存、再更新数据库的方式,同时在并发读写的情况下,增加延迟双删机制,就能保证数据的一致性。
可以看到,将Redis做为读写缓存,采用更新缓存的方式,会有数据不一致的风险,否则就要增加重试机制、分布式锁机制来保证一致性,这在实现上有一定的复杂度;除此之外,如果缓存计算比较复杂,又不常用到这些缓存,那缓存更新的代价就比较大。这种模式一般用在先修改又立即访问,对性能有较高要求的场景。
一般情况下,将Redis做为只读缓存,采用先删除缓存,再更新数据库,再删缓存的方式更好,实现方式更简单。采用删除缓存而不是更新缓存,其实就是一种懒加载的思想,只有在使用这个缓存的时候再去重新计算。
这其实就是经典的 Cache Aside Pattern:
- 读的时候先读缓存,缓存没有则读数据库,然后计算放入缓存,再返回响应;
- 更新的时候,先删除缓存,再更新数据库(为保证一致性,可再删一次缓存)。
Singleflight
缓存击穿
在高并发系统中,会有大量请求同时请求一个热点key的情况,这时这个key失效了,导致大量的请求直接访问数据库。上述现象就是缓存击穿,其后果就是大量请求同时访问数据库时,导致数据库压力剧增。
解决方案
1、缓存中的热点数据可以设置成永不过期。但是这个方法有两个问题,①不是所有场景都适用,需要区分场景,比如秒杀场景中,热点数据的缓存时间要覆盖整个活动。②数据更新时,需要一个后台线程更新缓存中的数据。
2、使用互斥锁,在第一个请求查询数据库时,加锁,阻塞其他请求,第一个请求会将数据加载到缓存中,结束后,释放锁,其他阻塞的请求直接在缓存中查询数据,这样可以达到保护数据库的目的。但是这个方法也有问题,阻塞其他线程会降低系统吞吐。
3、singleflight。其中原理和方法二类似,但是由于singleflight是go语言支持的,所以他锁住的不是线程,是更加轻量的goroutine。并且后续goroutine不需要在缓存中获取数据,可以直接返回第一个goroutine获取到的数据。
方法介绍
Do方法:singleflight的核心方法,执行给定的函数,并返回结果,一个key返回一次,重复的key会等待第一个返回后,返回相同的结果。
DoCall方法:与Do方法作用一样,区别在于执行函数非阻塞,所有的结果通过chan传给各个请求。
/*
Do 执行给定的函数,并返回结果,一个key返回一次,重复的key会等待第一个返回后,返回相同的结果。
入参:key 请求标识,用于区分是否是相同的请求;fn 要执行的函数
返回值:v 返回结果;err 错误信息;shared 是否是共享的结果,是否将v提供给多个请求
*/
func (g *Group) Do(key string, fn func() (interface, error)) (v interface, err error, shared bool)
// 相当于给map加锁
g.mu.Lock()
// 懒加载,如果g中还没有map,就初始化一个map
if g.m == nil
g.m = make(map[string]*call)
// key有对应的value,说明有相同的key只在执行,当前的请求需要等待。
if c, ok := g.m[key]; ok
c.dups++ // 相同的请求数+1
g.mu.Unlock() // 不需要写入,直接释放锁
c.wg.Wait() // 等待
// 省略一些错误逻辑处理。。。
......
return c.val, c.err, true
// 当前的key没有对应value
c := new(call) // 新建当前key的call实例
c.wg.Add(1) // 只有1个请求执行,只需要Add(1)
g.m[key] = c // 写入map
g.mu.Unlock() // 写入完成释放锁
g.doCall(c, key, fn) // 执行
return c.val, c.err, c.dups > 0 // >0 表示当前值需要共享给其他正在等待的请求。
/*
DoChan 与Do方法作用相同,区别是返回的是chan,可以在有数据时直接填入chan中,避免阻塞。
*/
func (g *Group) DoChan(key string, fn func() (interface, error)) <-chan Result
ch := make(chan Result, 1)
......
if c, ok := g.m[key]; ok
c.dups++
// 等待的请求将自己的ch添加到call实例中的chans列表中,方便有结果时返回
c.chans = append(c.chans, ch)
// 因为结果通过ch传递,所以不需要c.wg.Wait()
......
return ch
c := &callchans: []chan<- Resultch
......
// 因为使用chan传输数据,是非阻塞式的,可以使用其他的goroutine执行处理函数。
go g.doCall(c, key, fn)
return ch
doCall:执行处理函数fn。
/*
doCall 执行处理函数
入参:c key的实例;key 请求的标识;fn 处理函数
返回结果都存在c实例中。
*/
func (g *Group) doCall(c *call, key string, fn func() (interface, error))
......
defer func()
......
// 当前的处理函数运行完成,执行wg done
c.wg.Done()
// 加锁,删除刚执行的key/value
g.mu.Lock()
defer g.mu.Unlock()
// 当前key没有执行Forget,就可以删除key了
if !c.forgotten
delete(g.m, key)
if e, ok := c.err.(*panicError); ok
......
else
// Normal return
// 当执行DoChan方法时,chans存了Result列表,将结果添加到每个需要结果的ch中。
for _, ch := range c.chans
ch <- Resultc.val, c.err, c.dups > 0
()
func()
......
// 执行处理函数。
c.val, c.err = fn()
......
()
......
Forget方法:丢弃当前正在处理的key
// Forget 方法的作用是当前key由于超时等原因被主动丢弃,
// 后续相同key的请求会重新运行,而被丢弃的请求可能还正在执行。
// 作用是防止当前请求故障而导致所有相同key的请求都阻塞住。
func (g *Group) Forget(key string)
g.mu.Lock()
// 如果当前key存在,需要将对应的forgotten标志位改为true,标识当前key又有其他请求执行。
if c, ok := g.m[key]; ok
c.forgotten = true
delete(g.m, key)
g.mu.Unlock()
redis执行lua脚本实现多命令原子性操作
lua脚本
local fieldIdx=3
local valueIdx=4
local key=KEYS[1]
local fieldCount=ARGV[1]
local expired=ARGV[2]
for i=1,fieldCount,1 do
redis.pcall('HSET',key,ARGV[fieldIdx],ARGV[valueIdx])
fieldIdx=fieldIdx+2
valueIdx=valueIdx+2
end
redis.pcall('EXPIRE',key,expired)
执行script load命令
需要将脚本内容单行化,并以分号间隔不同的命令:
SCRIPT LOAD "local fieldIdx=3;local valueIdx=4;local key=KEYS[1];local fieldCount=ARGV[1];local expired=ARGV[2];for i=1,fieldCount,1 do redis.pcall('HSET',key,ARGV[fieldIdx],ARGV[valueIdx]) fieldIdx=fieldIdx+2 valueIdx=valueIdx+2 end;redis.pcall('EXPIRE',key,expired);"
"e03e7868920b7669d1c8c8b16dcee86ebfac650d"

执行脚本
evalsha 76c7302cec4ee92634f253f221a4753e425c8ab8 1 key 2 1000 field1 value1 field2 value2
redis事务
Redis官方文档指出:Redis的命令只会在语法错误或对key使用了错误的数据类型时会执行失败。因此,只要我们保证将正确的写数据和设置时间的命令作为一个整体发送到服务端即可,使用Lua脚本正式基于此原理
以上是关于Redis缓存一致性的主要内容,如果未能解决你的问题,请参考以下文章