Oracle in 1000 的异常处理方案和思考
Posted supingemail
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Oracle in 1000 的异常处理方案和思考相关的知识,希望对你有一定的参考价值。
好记忆不如烂笔头,能记下点东西,就记下点,有时间拿出来看看,也会发觉不一样的感受.
目录
虽然 oracle 已经在不广泛使用了,但是仍然有部分应用在使用它作为信息存储的介质,所以也肯定会遇到Oracle的各种各样的问题。
一、起因
一个生成上的缺陷问题(因为项目比较老,使用的是hibernate的hql语法),在查询中,使用 in 操作,但是in 后“()”中的value是通过参数传入的,参数的个数已经大于了1000。之前没有报错,是因为之前数量少,现在随着时间推移,值变多了,也就自然而然的超过了oracle 的默认的 1000 的设置了。具体参见如下图:
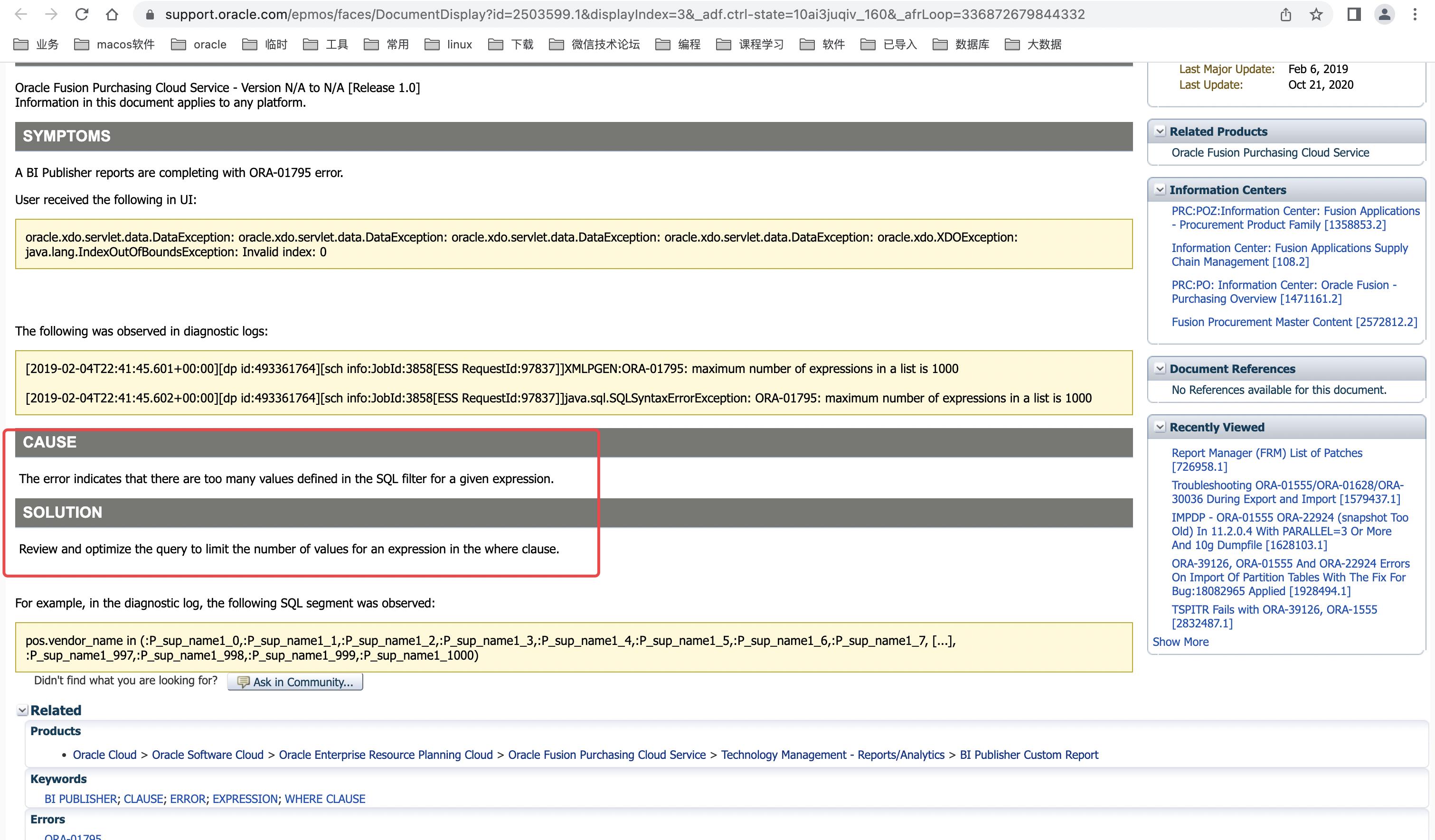
二、 解决方案
1.解决方案一:使用元组
思路:即把in条件,拼接成元组的形式,如 id in (1,2,3), 改为 (1,id) in ((1,1),(1,2),(1,3)) 即可。
总结:这种改法相对代码改动会比较少点,但是在hibernate的低版本和jodbc中,会报错:“无效的标识”,在oracle客户端却是可以执行成功的。主要原因是:hibernate认为 1=1 and id=1 这种是无效的运算符,这也说明hibernate的牛逼设计,因为它封装的深;但是mybatis这种写法是可以执行的,并且得到想要的结果。
(1,id) in ((1,1),(1,2),(1,3)) 在sql解析阶段,会将其解析成为:(1=1 and id=1) or (1=1 and id=2) or (1=1 and id=3)2.解决方案二:or 或union
思路:即把in 大于 1000的范围按照一定条件拆分,如 in 4000 的id ,可以拆解成:
id in(0-800)or id in(801-1600)or id in(1601-2400)... or id in(3201-4000)
总结:本来in的效率就低下,这样的操作虽然可以实现结果,但是效率低,不可取。
3.解决方案三: 子查询
思路:即把in ()中的value,通过sql子查询得到,而不是通过传值传递过来的,这设计程序的取数改造(使用这种方式,即便 SQL子查询中的vlaue值个数大于1000,也丝毫不影响查询,也不会报错,为什么,因为SQL编译器察觉不到in ()中的个数大于了1000 ,只有在SQL执行阶段,它才知道个数大于了1000,这个时候已经晚了)。
总结:如果想比较小的改动,这种方式:可取。
4.解决方案四:建立中间表
思路:建立一个中间的temp表存在查询条件,在数据库内部进行直接查询
总结:操作少许麻烦,不推荐。
5.解决方案五:建立临时表
思路:ORACLE临时表有两种类型:会话级的临时表和事务级的临时表。
1)ON COMMIT DELETE ROWS
它是临时表的默认参数,表示临时表中的数据仅在事务过程(Transaction)中有效,当事务提交(COMMIT)后,临时表的暂时段将被自动截断(TRUNCATE),但是临时表的结构 以及元数据还存储在用户的数据字典中。如果临时表完成它的使命后,最好删除临时表,否则数据库会残留很多临时表的表结构和元数据。
2)ON COMMIT PRESERVE ROWS
它表示临时表的内容可以跨事务而存在,不过,当该会话结束时,临时表的暂时段将随着会话的结束而被丢弃,临时表中的数据自然也就随之丢弃。但是临时表的结构以及元数据还存储在用户的数据字典中。如果临时表完成它的使命后,最好删除临时表,否则数据库会残留很多临时表的表结构和元数据。
总结:操作少许麻烦,不推荐。
三、思考
1.在SQL语句中,in 的操作性能是很低的,非到万不得,尽量少用,就算是用,也能明确知道 in 后的条件的个数不要超过 50 个,再多的话,在数据量大的时候,查询性能就很糟糕。
2. 在程序开发阶段,尽量避免使用in 操作,可以使用inner join 或left join 来实现效果。
3.在非写不可,in 的value 又大于100 的话,可以可考虑使用 exist 来代替,达到最终的目的。
4.写查询语句时候,为了提高查询效率,建议不要超过3 张表的联查。
移步:码出精彩(codingba),查看干货信息。
以上是关于Oracle in 1000 的异常处理方案和思考的主要内容,如果未能解决你的问题,请参考以下文章