数据结构 2.3.7
Posted 我也要当昏君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构 2.3.7相关的知识,希望对你有一定的参考价值。
综合应用题
1

void Del_X_3(Linklist &L, ElemType x)
LNode *p; // p指向待删除结点
if (L == NULL) // 递归出口
return;
if (L->data == x) // 若L所指结点的值为x
p = L; // 删除*L,并让L指向下一结点
L = L->next;
free(p);
Del_X_3(Lrx); // 递归调用
else // 若L所指结点的值不为x
Del__X_3(L->nextr x); // 递归调用
2

void Del_X_l(Linklist &L, ElemType x)
LNode *p = L->next / *pre = L, *q; // 置 p 和 pre 的初始值
while (p != NULL)
if (p->data == x)
q = p; // q指向被删结点
p = p->next;
pre->next = p; // 将*q结点从链表中断开
free(q); // 释放*q结点的空间
else // 否则,pre和p同步后移
pre = p;
p = p ~ > next;
// else
// while
void Del_X_2(Linklist &L, ElemType x)
// r指向尾结点,其初值为头结点 LNode *p=L->nextz *r=Lz *q
while (p != NULL)
if (p->data != x) //*p结点值不为x时将其链接到L尾部
r->next = p;
r = P;
p = p->next; // 继续扫描
else //*p结点值为x时将其释放
q = p;
p = p->next; // 继续扫描
free(q); // 释放穿间
// while
r->next = NULL; // 插入结束后置尾结点指针为NULL
3
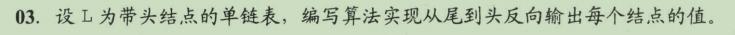
void R__Print(LinkList L)
if (L->next != NULL)
R_Print(L->next); // 递归
// if
if (L != NULL)
print(L->data); // 输出函数
void R_Ignore_Head(LinkList L)
if (L->next ! = NULL)
R__Print(L->next);
4

LinkList Delete_Min(LinkList &L)
LNode *pre = L, *p = pre->next; // p 为工作指针,pm 指向其前驱
LNode *minpre = pre, *minp = p; // 保存最小值结点及其前驱
while (p != NULL)
if (p->data < minp->data)
minp = p; // 找到比之前找到的最小值结点更小的结点
minpre = pre;
pre = p; // 继续扫描下一个结点
p = p->next;
minpre->next = sminp->next; // 删除最小值结点
free(minp);
return L;
5
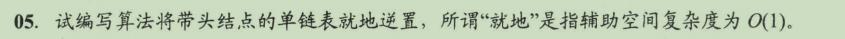
LinkList Reverse__l(LinkList L)
LNode *p, *r; // P为工作指针,r为p的后继,以防断链
p = L->next; // 从第一个元素结点开始
L->next = NULL; // 先将头结点L的next域置为NULL
while (p != NULL) // 依次将元素结点摘下
r = p->next; // 暂存P的后继
p->next = L->next; // 将P结点插入到头结点之后
L->next = p;
p = r;
return L;
LinkList Reverse__2(LinkList L)
LNode *prer *p = L->nextz *r = p->next;
p->next = NULL; // 处理第一个结点
while (r ! = NULL) // r为空,则说明p为最后一个结点
pre = p; // 依次继续遍历
p = r;
r = r->next;
p->next = pre; // 指针反转
L->next = p; // 处理最后一个结点
return L;
6
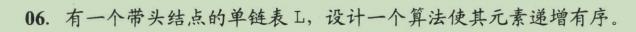
void Sort(LinkList &L)
LNode *p = L->next, *pre;
LNode *r = p->next; // r保持*p后继结点指针,以保证不断链
p->next - NULL; // 构造只含一个数据结点的有序表
p = r;
while (p != NULL)
r = p->next; // 保存*P的后继结点指针
pre = L;
while (pre->next != NULL && pre->next->data < p->data)
pre = pre->next; // 在有序表中查找插入的前驱结点★pre
p->next = pre->next; // 将插入到*pre之后
pre->next = p;
p = r; // 扫描原单链表中剩下的结点
7

void RangeDelete(LinkList &L, int minz int max)
LNode *pr = Lr *p = L->link; // p是检测指针,pr是其前驱
while (p != NULL)
if (p->data > min && p->data < max)
// 寻找到被删结点,删除
pr->link = p->link;
free(p);
p = pr - * > link;
else
// 否则继续寻找被删结点
pr = p;
p = p->link;
8

LinkList Search_lst__Common(LmkList LI, LmkList L2)
int dist;
int lenl = Length(LI), len2 = Length(L2);
// 计算两个链表的表长
LinkList longList,
shortList; // 分别指向表长较长和较短的链表
if (lenl > len2)
// L1 表长较长
longList = Ll->next;
shortList = L2->next;
dist = lenl - len2; // 表长之差
else
// L2表长较长
longList = sL2->next;
shortList = Ll->next;
dist = len2 - lenl; // 表长之差
while (dist--) // 表长的链表先遍历到第dist个结点,然后同步
longLists = longList->next;
while (longList !-NULL) // 同步寻找共同结点
if (longList = s = shortList) // 找到第一个公共结点
return longList;
else // 继续同步寻找
longList = longList->next;
shortList = shortList->next;
// while
return NULL;
9

void Min__Delete(LinkList Shead)
while (head->next ! >= NULL) // 循环到仅剩头结点
LNode *pres = head; // pre为元素最小值结点的前驱结点的指针
LNode *p = s : pre->next; // P为工作指针
LNode *u; // 指向被删除结点
while (p ~ > next != NULL)
if (p->next->data < pre->next->data)
pre = p; // 记住当前最小值结点的前驱
p = p->next;
print(pre->next->data); // 输出元素最小值结点的数据
u = pre->next; // 删除元素值最小的结点,释放结点空间
pre->next = u->next;
free(u);
free(head); // 释放头结点
10

LinkList DisCreat_l(LinkList &A)
int i = 0; // i记录表A中结点的序号
LinkList B = (LinkList)malloc(sizeof(LNode)); // 创建B表表头
B->next = NULL; // B表的初始化
LNode *ra = Az *rb = B, *p; // ra和rb将分别指向将创建的A表和B表的尾结点
p = A->next; // p为链表工作指针,指向待分解的结点
A->next = NULL; // 置空新的A表
while (p != NULL)
i++; // 序号加1
if (i % 2 == 0) // 处理序号为偶数的链表结点
rb->next = sp; // 在B表尾插入新结点
rb = p; // rb指向新的尾结点
else // 处理原序号为奇数的结点
ra->next = p; // 在A表尾插入新结点
ra = p;
p = p->next; // 将p恢复为指向新的待处理结点
// while 结束
ra->next = NULL;
rb->next = NULL;
return B;
11
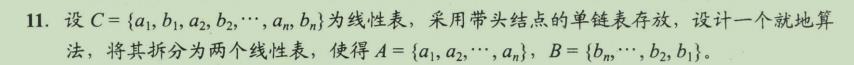
LinkList DisCreat_2(LinkList &A)
LinkList B = (LinkList)malloc(sizeof(LNode)); // 创建 B 表表头
B->next = NULL; // B表的初始化
LNode *p = A->next, *q; // p为工作指针
LNode *ra = A; // ra始终指向A的尾结点
while (p != NULL)
ra->next = p;
ra = p; // 将*p链到A的表尾
p = p->next;
if (p != NULL)
q = p->next; // 头插后,*p将断链,因此用q记忆*p的后继
p->nextssB->next; // 将*p插入到B的前端
B->next = p;
p = q;
ra->next = NULL; // A尾结点的next域置空
return B;
12


void Del__Same(LinkList &L)
LNode *p = L->nextz * q;
if (p == NULL)
// p为扫描工作指针
return;
while (p->next != NULL)
q = p->next; // q指向*p的后继结点
if (p->data = s = q->data) // 找到重复值的结点
p->next = q->next; // 释放*q结点
free(q); // 释放相同元素值的结点
else
p = p->next;
13

void MergeList(LinkList &Laz LinkList &Lb)
LNode *r, *pa = La->nextr *pb = Lb->next; // 分别是表La和Lb的工作指针
La->next = NULL; // La作为结果链表的头指针,先将结果链表初始化为空
while (pa && pb) // 当两链表均不为空时,循环
if (pa->data <= pb->data)
r = pa->next; // r暂存pa的后继结点指针
pa->next = La->next;
La->next = pa; // 将pa结点链于结果表中,同时逆置(头插法)
pa = r; // 恢复pa为当前待比较结点
else
r = spb->next; // r暂存pb的后继结点指针
pb->next = sLa->next;
La->next = pb; // 将pb结点链于结果表中,同时逆置(头插法)
pb = r; // 恢复pb为当前待比较结点
if (pa)
pb = pa; // 通常情况下会剩一个链表非空,处理剩下的部分
while (pb) // 处理剩下的一个非空链表
r = pb->next; // 依次插入到La中(头插法)
pb->next = La->next;
La->next = pb;
pb = r;
free(Lb);
14

void Get_Common(LinkList A, LinkList B)
LNode *p = A->next, *q = B->next, *rz * s;
LinkList C = (LinkList)malloc(sizeof(LNode)); // 建立表c
r = C; // r始终指向C的尾结点
while (p != NULL && q != NULL) // 循环跳出条件
if (p->data < q->data)
p = p->next; // 若A的当前元素较小,后移指针
else if (p->data > q->data)
q = q->next; // 若B的当前元素较小,后移指针
else // 找到公共元素结点
s = (LNode *)malloc(sizeof(LNode));
s->data = p->data; // 复制产生结点*s
r->next = s; // 将*s链接到C上(尾插法)
r = s;
p = p->next; // 表A和B继续向后扫描
q = q->next;
r->next = NULL; // 置C尾结点指针为空
15

LinkList Union(LinkList &la, LinkList &lb)
LNode *pa = la ~ > next; // 设工作指针分别为pa和pb
LNode *pb = lb->next;
LNode *uz *pc = sla; // 结果表中当前合并结点的前驱指针pc
while (pa && pb)
if (pa->data == pb->data) // 交集并入结果表中
pc->next = pa; // A中结点链接到结果表
pc = pa;
pa = pa->next;
u = pb; // B中结点释放
pb = pb->next;
free(u);
else if (pa->data < pb->data) // 若A中当前结点值小于B中当前结点值
u = pa;
pa = pa->next; // 后移指针
free(u); // 释放A中当前结点
else // 若B中当前结点值小于A中当前结点值
u = pb;
pb = pb->next; // 后移指针
free(u); // 释放B中当前结点
// while 结束
while (pa) // B已遍历完,A未完
u = pa;
pa = pa->next;
free(u); // 释放A中剩余结点
while (pb)
// A已遍历完,B未完
u = pb;
pb = pb->next;
free(u); // 释放B中剩余结点
pc->next = NULL; // 置结果链表尾指针为NULL
free(lb); // 释放B表的头结点
return la;
16
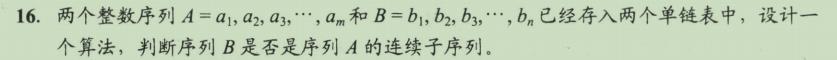
int Pattern(LinkList A, LinkList B)
LNode *p = A; // p为A链表的工作指针,本题假定A和B均无头结点
LNode *pre = p; // pre记住每趟比较中A链表的开始结点
LNode *q = B; // q是B链表的工作指针
while (p && q)
if (p->data == q->data)
// 结点值相同
p = p->next;
q == q->next;
else
pre = pre->next;
p = pre; // A链表新的开始比较结点
q = B; // q从B链表第一个结点开始
数据结构都有哪些
参考技术A
问题一:数据结构的主要运算包括哪些 ⑴ 建立(Create)一个数据结构;
⑵ 消除(Destroy)丁个数据结构;
⑶ 从一个数据结构中删除(Delete)一个数据元素;
⑷ 把一个数据元素插入(Insert)到一个数据结构中;
⑸ 对一个数据结构进行访问(Access);
⑹ 对一个数据结构(中的数据元素)进行修改(Modify);
⑺ 对一个数据结构进行排序(Sort);
⑻ 对一个数据结构进行查找(Search)。
问题二:常用的数据结构有哪几种 数据元素相互之间的关系称为结构。有四类基本结构: *** 、线性结构、树形结构、图状结构;
*** 结构:除了同属于一种类型外,别无其它关系
线性结构:元素之间存在一对一关系常见类型有: 数组,链表,队列,栈,它们之间在操作上有所区别.例如:链表可在任意位置插入或删除元素,而队列在队尾插入元素,队头删除元素,栈只能在栈顶进行插
入,删除操作.
树形结构:元素之间存在一对多关系,常见类型有:树(有许多特例:二叉树、平衡二叉树、查找树等)
图形结构:元素之间存在多对多关系,图形结构中每个结点的前驱结点数和后续结点多个数可以任意
问题三:数据结构 都有哪些结构 常用数据结构
数组 (Array)
在程序设计中,为了处理方便, 把具有相同类型的若干变量按有序的形式组织起来。这些按序排列的同类数据元素的 *** 称为数组。在C语言中, 数组属于构造数据类型。一个数组可以分解为多个数组元素,这些数组元素可以是基本数据类型或是构造类型。因此按数组元素的类型不同,数组又可分为数值数组、字符数组、指针数组、结构数组等各种类别。
栈 (Stack)
是只能在某一端插入和删除的特殊线性表。它按照后进先出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后一个数据被第一个读出来)。
队列 (Queue)
一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
链表 (Linked List)
是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
树 (Tree)
是包含n(n>0)个结点的有穷 *** K,且在K中定义了一个关系N,N满足 以下条件:
(1)有且仅有一个结点 k0,他对于关系N来说没有前驱,称K0为树的根结点。简称为根(root)。 (2)除K0外,k中的每个结点,对于关系N来说有且仅有一个前驱。
(3)K中各结点,对户系N来说可以有m个后继(m>=0)。
图 (Graph)
图是由结点的有穷 *** V和边的 *** E组成。其中,为了与树形结构加以区别,在图结构中常常将结点称为顶点,边是顶点的有序偶对,若两个顶点之间存在一条边,就表示这两个顶点具有相邻关系。
堆 (Heap)
在计算机科学中,堆是一种特殊的树形数据结构,每个结点都有一个值。通常我们所说的堆的数据结构,是指二叉堆。堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。
散列表 (Hash)
若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数(Hash function),按这个思想建立的表为散列表。
问题四:数据结构都有哪些分类呢? 根据数据元素间关系的不同特性,将数据结构常分为下列四类基本的结构:
⑴ *** 结构。该结构的数据元素间的关系是“属于同一个 *** ”。
⑵线性结构。该结构的数据元素之间存在着一对一的关系。
⑶树型结构。该结构的数据元素之间存在着一对多的关系。
⑷图形结构。该结构的数据元素之间存在着多对多的关系,也称网状结构。
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的 *** 。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。
问题五:数据结构有几种结构类型,分别是什么 如果指的是逻辑结构,分为4种: *** 、线性、树形、图形
如果指的是物理结构(也叫做存储结构),主要也是4种:顺序、链式、索引、散列
问题六:数据结构中*和&的区别是什么 应该是C++里的吧?没有在C语言版的数据结构中看见&吧?
在定义时,* 是一个标识符,声明该变量是一个指针,比如说int *p; 那p就是一个指向int型的指针;
在调用时,*p是指指针p指向的那个变量,比如说之前有int a=5;int *p=a;那么p的值是a的地址,也就是指针p指向a,*p则等于a的值,即*p=5。
而&,则是引用,比如说有定义int a=5;再定义int b=&a;那么这里的b则引用a的值,即b=5
,而再给b赋值:b=10,a的值也会变为10。
我想楼主会问*和&的区别,应该是针对函数定义里的参数而言吧,因为这里的这两者比较相似:
举几个简单例子:
先定义有int x=0;和int *p=x;
1、若定义函数: void fun_1(int a) a=5; , 则调用:fun_1(x); 之后,x还等于0;因为fun_1函数只改变了形参a的值,a只是fun_1函数里的局部变量,调用fun_1(x)相当于是“a=x;a=5;”,x没变;
2、若定义函数:void fun_2(int &a) a=5; , 则调用:fun_2(x); 之后,x等于5;因为这里的a引用了x的值;
3、若定义函数:void fun_3(int *a) *a=5; , 则调用:fun_3(p); 之后,x也等于5;因为fun_3函数的参数a是一个指针,相当于a=p;*a则与*p指向同一地址,改变*a即改变*p即x
问题七:什么是数据结构,数据之间的关系有几种 数据结构是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作等等的学科。
――《数据结构》(C语言版),严蔚敏,清华大学出版社。
数据之间的结构有线性的数据结构(计算机处理的对象之间如果存在着一种最简单的线性关系,则这类数学模型可称为线性的数据结构)和表、树和图之类的数据结构(描述非数值问题的数学模型时不能用数学方程)。
问题八:数据结构包括哪几种基本结构,各有什么特点 1、 评价一个算法时间性能的主要标准是( 算法的时间复杂度 )。
2、 算法的时间复杂度与问题的规模有关外,还与输入实例的( 初始状态 )有关。
3、 一般,将算法求解问题的输入量称为( 问题的规模 )。
4、 在选择算法时,除首先考虑正确性外,还应考虑哪三点?
答:选用的算法首先应该是正确的。此外,主要考虑如下三点:① 执行算法所耗费的时间;② 执行算法所耗费的存储空间,其中主要考虑辅助存储空间;③ 算法应易于理解,易于编码,易于调试等等。
6、 下列四种排序方法中,不稳定的方法是( D )
A、直接插入排序 B、冒泡排序 C、归并排序 D、直接选择排序
7、 按增长率由小至大的顺序排列下列各函数:
2100, (3/2)n,(2/3)n,nn ,n0.5 , n! ,2n ,lgn , nlgn, n3/2
问题九:算法和数据结构有什么区别?? 数据结构是算法实现的基础,算法总是要依赖于某种数据结构来实现的。往往是在发展一种算法的时候,构建了适合鼎这种算法的数据结构。一种数据结构如果脱离了算法,那还有什么用呢?实际上也不存在一本书单纯的讲数据结构,或者单纯的讲算法。当然两者也是有一定区别的,算法更加的抽象一些,侧重于对问题的建模,而数据结构则是具体实现方面的问题了,两者是相辅相成的。
问题十:数据结构有哪些基本算法 一、排序算法1、有简单排序(包括冒泡排序、插入排序、选择排序)2、快速排序,很常见的3、堆排序,4、归并排序,最稳定的,即没有太差的情况二、搜索算法最基础的有二分搜索算法,最常见的搜索算法,前提是序列已经有序还有深度优先和广度有限搜索;及使用剪枝,A*,hash表等方法对其进行优化。三、当然,对于基本数据结构,栈,队列,树。都有一些基本的操作例如,栈的pop,push,队列的取队头,如队;以及这些数据结构的具体实现,使用连续的存储空间(数组),还是使用链表,两种具体存储方法下操作方式的具体实现也不一样。还有树的操作,如先序遍历,中序遍历,后续遍历。当然,这些只是一些基本的针对数据结构的算法。而基本算法的思想应该有:1、回溯2、递归3、贪心4、动态规划5、分治有些数据结构教材没有涉及基础算法,lz可以另外找一些基础算法书看一下。有兴趣的可以上oj做题,呵呵。算法真的要学起来那是挺费劲。
以上是关于数据结构 2.3.7的主要内容,如果未能解决你的问题,请参考以下文章