java8新特性-Stream
Posted 路迢迢
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java8新特性-Stream相关的知识,希望对你有一定的参考价值。
Java8中的Collection接口被扩展,提供了两个获取流的方法:
default Stream<E> stream() :返回一个顺序流
default Stream<E> parallelStream() :返回一个并行流
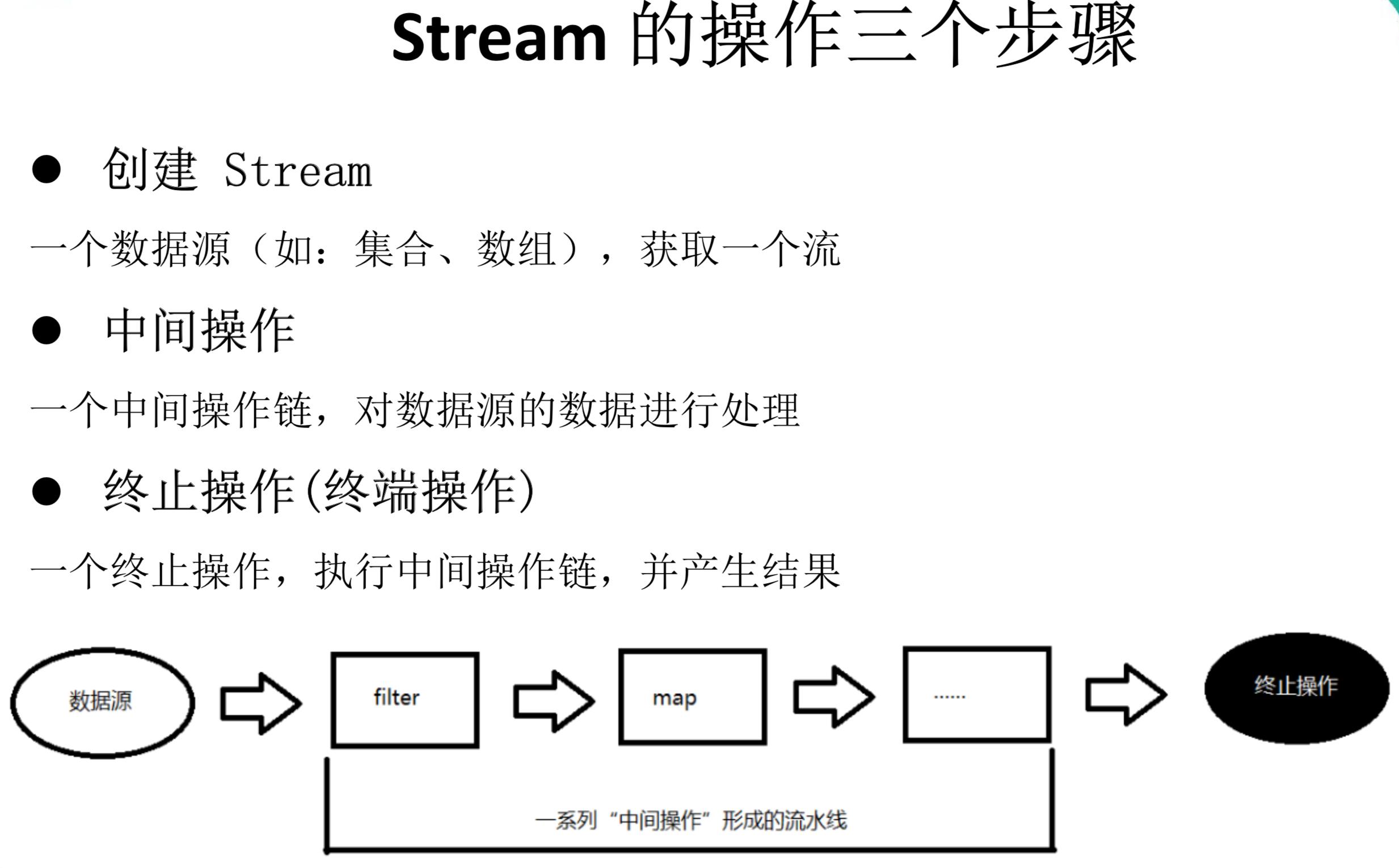
1创建
1. Collection 提供了两个方法 stream() 与 parallelStream()
List<String> list = new ArrayList<>(); Stream<String> stream = list.stream(); //获取一个顺序流 Stream<String> parallelStream = list.parallelStream(); //获取一个并行流
2. 通过 Arrays 中的 stream() 获取一个数组流
Integer[] nums = new Integer[10]; Stream<Integer> stream1 = Arrays.stream(nums);
3通过 Stream 类中静态方法 of()
Stream<Integer> stream2 = Stream.of(1,2,3,4,5,6);
4创建无限流
//迭代 Stream<Integer> stream3 = Stream.iterate(0, (x) -> x + 2).limit(10); stream3.forEach(System.out::println);
5
//生成 Stream<Double> stream4 = Stream.generate(Math::random).limit(2); stream4.forEach(System.out::println);
2中间操作
筛选与切片
filter——接收 Lambda , 从流中排除某些元素。
limit——截断流,使其元素不超过给定数量。
skip(n) —— 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
distinct——筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素
所有的中间操作不会做任何的处理,
只有当做终止操作时,所有的中间操作会一次性的全部执行,称为“惰性求值”
//外部迭代 @Test public void test3(){ Iterator<Employee> it = emps.iterator(); while(it.hasNext()){ System.out.println(it.next()); } }
filter——接收 Lambda , 从流中排除某些元素。
@Test public void test4(){ emps.stream() .filter((e) -> { System.out.println("短路!"); // && || return e.getSalary() >= 5000; }).limit(3) .forEach(System.out::println); }
@Test public void test5(){ emps.parallelStream() .filter((e) -> e.getSalary() >= 5000) .skip(2) .forEach(System.out::println); }
@Test public void test6(){ emps.stream() .distinct() .forEach(System.out::println); }
映射
map——接收 Lambda , 将元素转换成其他形式或提取信息。接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
flatMap——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流
@Test public void test1(){ Stream<String> str = emps.stream() .map((e) -> e.getName()); System.out.println("-------------------------------------------"); List<String> strList = Arrays.asList("aaa", "bbb", "ccc", "ddd", "eee"); Stream<String> stream = strList.stream() .map(String::toUpperCase); stream.forEach(System.out::println); Stream<Stream<Character>> stream2 = strList.stream() .map(TestStreamAPI1::filterCharacter); stream2.forEach((sm) -> { sm.forEach(System.out::println); }); System.out.println("---------------------------------------------"); Stream<Character> stream3 = strList.stream() .flatMap(TestStreamAPI1::filterCharacter); stream3.forEach(System.out::println); } public static Stream<Character> filterCharacter(String str){ List<Character> list = new ArrayList<>(); for (Character ch : str.toCharArray()) { list.add(ch); } return list.stream(); }
sorted()——自然排序(Comparable)
sorted(Comparator com)——定制排序
@Test public void test2(){ emps.stream() .map(Employee::getName) .sorted() .forEach(System.out::println); System.out.println("------------------------------------"); emps.stream() .sorted((x, y) -> { if(x.getAge() == y.getAge()){ return x.getName().compareTo(y.getName()); }else{ return Integer.compare(x.getAge(), y.getAge()); } }).forEach(System.out::println); }
3终止操作(终端操作)
allMatch——检查是否匹配所有元素
anyMatch——检查是否至少匹配一个元素
noneMatch——检查是否没有匹配的元素
findFirst——返回第一个元素
findAny——返回当前流中的任意元素
count——返回流中元素的总个数
max——返回流中最大值
min——返回流中最小值
归约:reduce(T identity, BinaryOperator) / reduce(BinaryOperator) ——可以将流中元素反复结合起来,得到一个值。
收集:collect——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法,转换list,set等
allMatch——检查是否匹配所有元素
boolean bl = emps.stream() .allMatch((e) -> e.getStatus().equals(Status.BUSY)); System.out.println(bl);
anyMatch——检查是否至少匹配一个元素
boolean bl1 = emps.stream() .anyMatch((e) -> e.getStatus().equals(Status.BUSY)); System.out.println(bl1);
noneMatch——检查是否没有匹配的元素
boolean bl2 = emps.stream() .noneMatch((e) -> e.getStatus().equals(Status.BUSY)); System.out.println(bl2);
findAny——返回当前流中的任意元素
Optional<Employee> op2 = emps.parallelStream() .filter((e) -> e.getStatus().equals(Status.FREE)) .findAny(); System.out.println(op2.get());
findFirst——返回第一个元素
Optional<Employee> op = emps.stream() .sorted((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())) .findFirst(); System.out.println(op.get());
count——返回流中元素的总个数
long count = emps.stream() .filter((e) -> e.getStatus().equals(Status.FREE)) .count(); System.out.println(count);
max——返回流中最大值
min——返回流中最小值
Optional<Double> op = emps.stream() .map(Employee::getSalary) .max(Double::compare); System.out.println(op.get()); Optional<Employee> op2 = emps.stream() .min((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())); System.out.println(op2.get());
注意:流进行了终止操作后,不能再次使用
@Test public void test4(){ Stream<Employee> stream = emps.stream() .filter((e) -> e.getStatus().equals(Status.FREE)); long count = stream.count(); stream.map(Employee::getSalary) .max(Double::compare); }
会报错
归约:reduce(T identity, BinaryOperator) / reduce(BinaryOperator) ——可以将流中元素反复结合起来,得到一个值。
@Test public void test1(){ List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10); Integer sum = list.stream() .reduce(0, (x, y) -> x + y); System.out.println(sum); System.out.println("----------------------------------------"); Optional<Double> op = emps.stream() .map(Employee::getSalary) .reduce(Double::sum); System.out.println(op.get()); }
收集:collect——将流转换为其他形式。接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
@Test public void test3(){ List<String> list = emps.stream() .map(Employee::getName) .collect(Collectors.toList()); list.forEach(System.out::println); System.out.println("----------------------------------"); Set<String> set = emps.stream() .map(Employee::getName) .collect(Collectors.toSet()); set.forEach(System.out::println); System.out.println("----------------------------------"); HashSet<String> hs = emps.stream() .map(Employee::getName) .collect(Collectors.toCollection(HashSet::new)); hs.forEach(System.out::println); }
@Test public void test4(){ Optional<Double> max = emps.stream() .map(Employee::getSalary) .collect(Collectors.maxBy(Double::compare)); System.out.println(max.get()); //最小值 Optional<Employee> op = emps.stream() .collect(Collectors.minBy((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary()))); System.out.println(op.get()); //总和 Double sum = emps.stream() .collect(Collectors.summingDouble(Employee::getSalary)); System.out.println(sum); //平均值 Double avg = emps.stream() .collect(Collectors.averagingDouble(Employee::getSalary)); System.out.println(avg); //统计 Long count = emps.stream() .collect(Collectors.counting()); System.out.println(count); System.out.println("--------------------------------------------"); DoubleSummaryStatistics dss = emps.stream() .collect(Collectors.summarizingDouble(Employee::getSalary)); System.out.println(dss.getMax()); }
分组
//分组 @Test public void test5(){ Map<Status, List<Employee>> map = emps.stream() .collect(Collectors.groupingBy(Employee::getStatus)); System.out.println(map); }
多级分组
//多级分组 @Test public void test6(){ Map<Status, Map<String, List<Employee>>> map = emps.stream() .collect(Collectors.groupingBy(Employee::getStatus, Collectors.groupingBy((e) -> { if(e.getAge() >= 60) return "老年"; else if(e.getAge() >= 35) return "中年"; else return "成年"; }))); System.out.println(map); }
分区 :按true/false
//分区 @Test public void test7(){ Map<Boolean, List<Employee>> map = emps.stream() .collect(Collectors.partitioningBy((e) -> e.getSalary() >= 5000)); System.out.println(map); }
拼接
@Test public void test8(){ String str = emps.stream() .map(Employee::getName) .collect(Collectors.joining("," , "----", "----")); System.out.println(str); }
并行流
是对fork/join的优化
参考:fork/join
.parallel(),做数字累加操作,会启用多线程,cpu高负载;
@Test public void test3(){ long start = System.currentTimeMillis(); Long sum = LongStream.rangeClosed(0L, num) .parallel() .sum(); System.out.println(sum); long end = System.currentTimeMillis(); System.out.println("test3耗费的时间为: " + (end - start)); }
以上是关于java8新特性-Stream的主要内容,如果未能解决你的问题,请参考以下文章