我这样减少了26.5M Java内存!
Posted 腾讯WeTest
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我这样减少了26.5M Java内存!相关的知识,希望对你有一定的参考价值。
WeTest 导读
历时五天的内存优化已经结束,这里总结一下这几天都做了什么,有哪些收获。优化了,或可以优化的地方都有哪些。(因为很多事还没做,有些结论需要一定样本量才能断定,所以叫一期)一期优化减少JavaHeap内存占用约26.5M。
在任何性能优化之前,要做的第一件事就是找到性能瓶颈!而找到性能瓶颈通常需要强大的debug工具辅助。内存方面android有 AndroidStudio 的 Android Profiler、Allocation Tracker,以及Eclipse的MAT用于分析java的内存占用,相当强大。而偏向native层面的内存占用则找不到太好的工具,因此这里在做优化前,先造了几个工具。
一、造轮子
1. 线程创建分析工具
该工具使用native hook的方式,直接hook了pthread_create调用,并记录每一个线程创建时的堆栈,并打印日志。同时维护一个running thread的集合,必要时 dump下来所有running thread的创建堆栈,用于分析野蛮线程创建的场景。以及对应的日志分析工具。
2. Linux /proc/<pid>/smaps 文件分析脚本
主要用于跟踪进程的 Code 部分内存(见下文)占用,分析出占用内存较多的dex,so文件。排查第三方SDK占用过多内存场景。网上只能找到一个perl脚本,功能不是很强大,鉴于笔者不熟悉perl的语法规范,改起来会比较困难,因此直接用python重写了一个。
代码在这里:https://gist.github.com/LanderlYoung/aedd0e1fe09214545a7f20c40c01776c
3. 快速Dump Android java heap脚本
因为分析内存需要很多dump操作,所以干脆写了个Bash脚本。
Bash脚本链接:https://gist.github.com/LanderlYoung/9cd0f49e49e42746622cc8e7b4bbcc8a
(顺便提一下,android提供的 hprof-conv 工具有个参数 -z 用于排除zygote的内存,十分便利。)
二、Android 进程 内存分类
通常我们在系统的内存管理页面看到的内存占用是进程的PSS,也就是整个进程的内存占用,因此我们做优化的要考虑到所有的内存,不仅仅是Java Heap。
使用Android Studio(3.0 beta)的 Android Profiler工具。

我们可以很清晰的看到
1)进程总内存占用: 180M
2)JavaHeap: 48M
3)NativeHeap:native层的 so 中调用malloc或new创建的内存 —— 28M
4)Graphics:OpenGL和SurfaceFlinger相关内存 ——58M
5)Stack:线程栈——1.89M
6)Code:dex+so相关代码占用内存——37.75M
7)Other:蜜汁存在
上述6中内存占用除了两种不需要考虑,其他5中通通需要优化。不需要考虑的是:
1)Other:暂时无从分析
2)Graphics:若应用没有直接调用OpenGL,则可以确定这部分内存是由Android Framework操控的,可以忽略。(当然对于游戏类应用,这里肯定是优化重点。)
下面按照内存分类分开逐一介绍分析方法,和结论:
JavaHeap
这里必然是内存优化的重点,无需多言。但是企鹅FM的业务,UI,代码已经比较庞大,分析起来会显得力不从心。因此这里主要从两个方面入手,希望能总结出一套分析方法。
1. 分析应用 静息态 内存占用。
所谓静息态,是笔者自行定义的概念:
应用在退后台之后,不保留活动的场景下的内存占用。
为什么要考察这个维度?因为这个是一个应用内存占用最低点的时候,后续打开任何Activity内存只会更多,不会更少!
2. 分析方法
1)开发者选项开启“不保留活动”
2)进入MainActivity,滑动页面,操作一下
3)退后台,Android Studio中强制执行GC
4)dump java heap (注意上面提到的 hprof-conf 加上 -z 参数排除zygote的干扰)
5)MAT 分析 dump 下来的JavaHeap
重点介绍一下MAT:
这里可以直接打开domanitor_tree看占用内存最多的实例。

从这里按照RetainedHeap倒序排列,一点一点的排查内存占用。很容易发现不正常的内存情况。
在企鹅FM中发现:
1)图片的内存级缓存退后台没清空(此处属于onTrimMemory回调的处理有误),占用10M内存
2)ImageMisc — 280k
①

② 是一个buffer,可以在不用的时候释放内存
③ 优化目标,彻底干掉
3)播放页应用动画的关系,UI是单例。其中相关View占用数百K内存,而button的icon直接引用住了5-6M的bitmap资源。
4)播放列表存储了103个ShowInfo,每个ShowInfo 22k,总计内存约2.24M,ShowInfo冗余信息很多,可以考虑优化数据结构

5) DanmuManager — 510k
● mDanmuItemManager 内含众多弹幕
● 每条弹幕6k
● UI相关数据,离开播放页后应该清理弹幕(因为无需展示了)
● 优化目标,彻底干掉。
6) FileCacheService — 362k
①
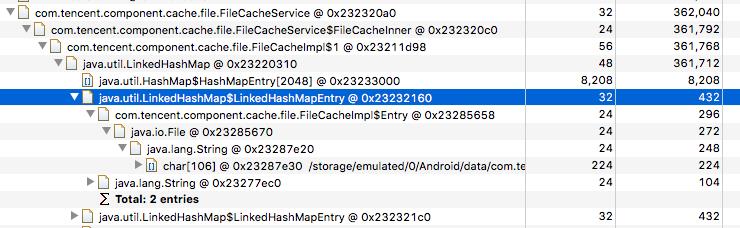
② 其中缓存了每一个cache entry,其中图片缓存较多
③ 每一个entry记录完整文件路径其比较长,因此路径的字符串占用了很多内存
④ 优化方案:
● 文件Parent可以共用同一个File对象。
● entry = new File(parent, “entry_name”)
⑤ 优化目标 到100k
7)LiveRoomShowListManager -- 287k
①

② 优化目标:UI相关数据,离开界面应该彻底干掉
8) DB InsertHelper, Sql Statement clearBinding
① 700K到2M
② InsetHelper中会引用住最后一次执行DB insert调用的 数据(占位符)
③ InsertHelper的占位数据可以在insert完成之后清掉
针对上面提到的ShowInfo的数据结构优化

拟定优化方案:
1)ShowList存储的ShowInfo数量过多,30个足矣。
2)ShowInfo中Album字段占用10k内存,其实同一个ShowList中大多数album是完全一致的(比如专辑类型的ShowList,主播类型的,自选集类型的,本地专辑的,etc...)。
预计内存占用 2M -> 30*12K = 360K
3)静息态内存优化总结:
上述几点加起来预期可以减少内存占用:
10M + 280K + 5M + 2M + 510K + 260k + 287k + 1M = 约20M
3. MainActivity 操作一段时间之后内存增量
上面分析的是静息态内存,下面看一下MainActivity操作一点时间之后,内存有怎样的变化。
这里采用的方式是:
1)dump静息态内存
2)进入MainActivity,立即dump内存
3)操作一段时间之后再dump内存
一共有三次dump,可以利用MAT对比heap的功能对比内存增量。
打开MAT的historgram视图

工具栏最右边有个双箭头的icon,点击可对比dump:如下图

增量最多的还是Bitmap(底层用byte[]存储),借助MAT的 Finer 工具可以直接看到Bitmap的图片。
这里发现的几个问题是(时间关系,应该多次测试的,会发现更多问题):
① Banner的大图没有 Clip 导致 分辨率 很高
② 分类页的 配置区域 没有Clip
③ onRecycle没有清除掉已经引用的Bitmap,导致引用住不能gc
主要说一下第3点,是Banner每一个Item有一个大图做背景,当item的view被回收的时候,相应的ImageView仍然持有着大图,导致其不能回收。这里发现了4张1M+的大图,其实理论上应该只有1张。
这个问题可以推广到所有的ListView场景,建议方式是:
替换为RecyclerView,在view回收的时候,ScarpView释放图片引用。
此外,MainActivity有5个tab,各个tab之间其实会用到相同的View(listview 的item),如果使用RecyclerView可以做到5个tab的RecyclerView共同复用同一个RecyclerPool,在节省内存的同时还能显著提高性能。
这里不方便直接测试内存占用,预估可以节省内存5-10M。
4. 正常操作应用,观察内存占用图表是否有突起
这里主要用来测试异常内存分配的场景。
这里仍然需要很大人力,过很多页面。
目前发现问题有:
1)service进程,发送wns请求的时候,内存异常增长2-3M。

这时可以使用AllocationTracker工具(点击下图工具栏的红点),记录峰值那一段内存的分配,如图:
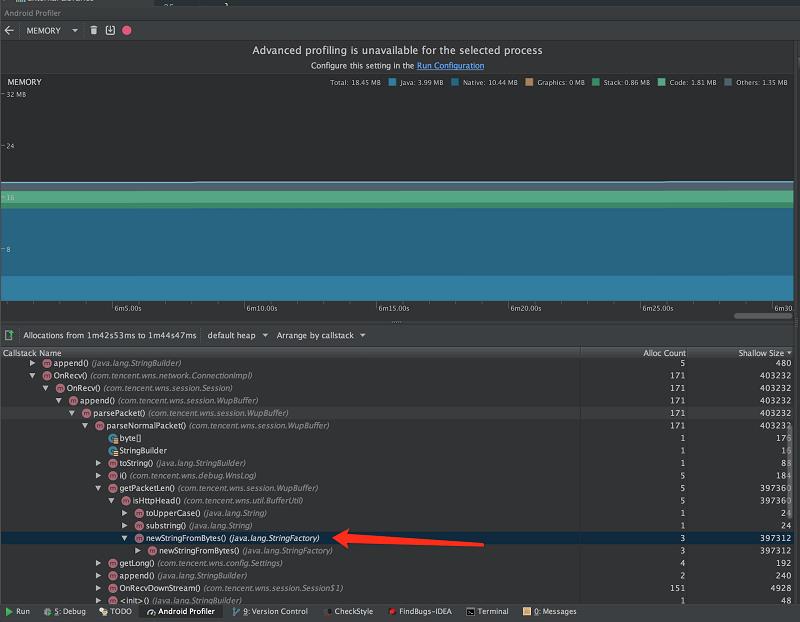
这里可以直接看到分配的栈,定位过去看,发现是这样的代码,因为head是一个65536长的数组(在 com.tencent.wns.session.Session 的构造函数写死的长度),这里创建string就浪费了超大量的内存。建议可以改成下图弹窗里的样子

2)另外一个问题是播放进程,在切换节目的时候内存会突然增长2-3M,简单跟进去看是exo创建buffer。似乎有问题,需要再多分析一下~
Native Heap
目前能看到的NativeHeap大小是
应用启动:26M 此时已经初始化了 X5内核和IM SDK
UGC录音:26M->34M 退出之后时32M,还有部分没释放,疑似内存泄漏
发起直播:32M->72M 退出之后42M,同样没有完全释放
具体内部占用情况还没测。。。(都说了是一期)。
官方文档:
https://source.android.com/devices/tech/debug/native-memory
Code
这一段明显看到占用了很多内存。各个场景下的使用情况是:
1)刚进入应用:38M
2)再使用UGC录音:38.28M
3)再使用视频直播(发起直播):46M
4)打开应用内WebView(X5内核):56M
以上是主进程的内存,占用相当多。需要注意的是code内存占用一般是通过read-only方式mmap映射到内存中的的dex、odex、so等文件,因此在内存紧张的情况下,系统会回收这些内存,只是在oom-killer中仍然会计算在内。
另外播放进程2.27M,service进程1.1M还属于比较正常的水平。
显然主进程的Code内存占用太多了,需要分析。这里通过解析Linux标准的 /proc/<pid>/smaps文件,这个文件记录了进程内每一段虚拟内存的文件映射情况,这个文件只有进程自己有读权限,所以要么用root的机器,要么就自己写段代码copy出来。结合上面提到的工具。分析结果如下:
● 应用so占用 app so map Rss = 3984 kB (其中IM SDK 2576k)
● 应用的dex占用 app dex map Rss = 15101 kB
● X5内核的so+dex内存占用 tbs mem map Rss = 29048 kB
● 直播so相关 avlive mem map Rss = 3092 kB
● 其中X5内核的代码没有打进apk,因此可以比较独立的统计出来,占用有29M之多,让人惊讶!
● 其次直播的java代码打进了apk不方便单独统计内存用量,但是so是独立加载的,内存占用3M也是不少的。
● 最后是应用自身的dex占用有15M之多,因为自身代码量很大,似乎可以理解,但是仍然很多啊!
这里需要考虑的是 X5 内核能否延时加载?因为没打开WebView的时候就已经占用了数M了。另外WebView关闭之后是否可以销毁。
直播相关SO,可以考虑直播退出之后从内存中卸载掉。(java规范是加载so的classloader被GC,相关so即可卸载)。
应用自身dex占用。android 8.0 对art优化一个叫做DexLayout 的能力,应为mmap映射的文件不会被立即加载进内存,在用到的时候是按照页大小(4k)加载的,当用到的类在dex中分布很分散的时候,就会导致盲目加载很多页,DexLayout就是把热点类集中放到一起。这里FaceBook推出了ReDex工具,可以参考一下。
PS:关于DexLayout

三、线程创建
在AndroidStudio的Memory Profiler中没有线程数这个维度。但是运行中,主进程的线程数量通常会在100个左右,这是个惊人的数字,要知道Mac版的AndroidStudio也不过77个线程。。。。请自行体会一下。
关于线程的创建和内存占用,请参考笔者的另一篇文章:《Android 创建线程源码与OOM分析》 。
这里分析用的自制工具,dump下载所有running的线程,和他们创建时的堆栈。
结果是:
● X5:25个线程(简直。。。)
● IMSDK:17个线程
● StackBlur:8个线程
● WNS:7个线程
● ImageLoader:6个线程
● magnifiersdk:5个线程
需要注意,这里的栈和线程名,是创建线程的时候的调用栈,以及对应的线程名(而不是子线程名)
事实上,用同样的方法,还可以分析一下进程历史中所有创建过的线程,统计哪里创建线程最多。
通常来说,所有线程应该有应用统一的线程池来管理,sdk内部需要线程池,应该有外部注入一个线程池来提供给sdk使用。
如果有其他情况,如:不是在线程池创建的线程,在sdk自己的线程池里创建的线程,这种都可能导致线程数量的野蛮增长,需要联系sdk的开发人员杜绝这种情况。
四、总结
以上就是这5天的工作结果:
java内存占用基本合理,静息态 内存占用可以优化20M,MainActivity运行时的内存占用可以优化5-10M。
code内存占用太多,其中X5内核占用29M实在太多,需要考虑优化。
应用内的线程数量主要有X5内核,IMSDK和WNS贡献,外网线程创建的OOM crash 系WNS的bug,需要联系相关sdk开发人员。
最后是Native内存占用还没有详细分析,暂时看不到使用情况。但是可以知道目前的结论是:Native内存占用很多,且应该存在内存泄漏。
PS: 实际效果反馈
按照上述分析结果,进行了相关的代码调整。
执行的点包括:
1、IntelliShowList pageSize 50->20
2、IntelliShowList 公用Album结构
3、Afc-db clearBinding after insert, 数据库
4、Afc-FileCacheService cache Entry with fileName not full path, 文件缓存
5、 fix onTrimMemory bug,退后台清空图片内存缓存
6、播放页相关控件,退后台之后清掉icon,释放bitma引用
未执行的点包括:
1、播放页的bottomPannel部分icon因为逻辑较为复杂,暂时未进行处理。预计内存占用1M
2、PlayLogic的historyList逻辑复杂暂时未处理,预计内存占用500K
3、24h直播间LiveRoomShowListManager -- 287k
4、DanmuManager — 510k
5、经过ice提醒,下载节目的record也会全部加载进内存。每个ShowInfo 22k,内存占用取决于用户下载的节目数。
效果对比:
before:39.32M

after:12.88M

优化内存占用 26.44M!
UPA—— 一款针对Unity游戏/产品的深度性能分析工具,由腾讯WeTest和unity官方共同研发打造,可以帮助游戏开发者快速定位性能问题。旨在为游戏开发者提供更完善的手游性能解决方案,同时与开发环节形成闭环,保障游戏品质。
目前,限时内测正在开放中,点击http://wetest.qq.com/cube/ 即可预约。
对UPA感兴趣的开发者,欢迎加入QQ群:633065352
如果对使用当中有任何疑问,欢迎联系腾讯WeTest企业QQ:800024531
以上是关于我这样减少了26.5M Java内存!的主要内容,如果未能解决你的问题,请参考以下文章