如何进行手机APP的数据爬取?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何进行手机APP的数据爬取?相关的知识,希望对你有一定的参考价值。
参考技术APython爬虫手机的步骤:
1. 下载fiddler抓包工具
2. 设置fiddler
这里有两点需要说明一下。
设置允许抓取HTTPS信息包
操作很简单,打开下载好的fiddler,找到 Tools -> Options,然后再HTTPS的工具栏下勾选Decrpt HTTPS traffic,在新弹出的选项栏下勾选Ignore server certificate errors。
设置允许外部设备发送HTTP/HTTPS到fiddler
相同的,在Connections选项栏下勾选Allow remote computers to connect,并记住上面的端口号8888,后面会使用到。
好了,需要的fiddler设置就配置完成了。
3. 设置手机端
设置手机端之前,我们需要记住一点:电脑和手机需要在同一个网络下进行操作。
可以使用wifi或者手机热点等来完成。
假如你已经让电脑和手机处于同一个网络下了,这时候我们需要知道此网络的ip地址,可以在命令行输入ipconfig简单的获得,如图。
好了,下面我们开始手机端的设置。
手机APP的抓取操作对于android和Apple系统都可用,博主使用的苹果系统,在此以苹果系统为例。
进入到手机wifi的设置界面,选择当前连接网络的更多信息,在苹果中是一个叹号。然后在最下面你会看到HTTP代理的选项,点击进入。
进入后,填写上面记住的ip地址和端口号,确定保存。
4. 下载fiddler安全证书
在手机上打开浏览器输入一个上面ip地址和端口号组成的url:http://192.168.43.38:8888,然后点击FiddlerRoot certificate下载fiddler证书。
以上就简单完成了所有的操作,最后我们测试一下是否好用。
5. 手机端测试
就以知乎APP为例,在手机上打开 知乎APP。下面是电脑上fiddler的抓包结果。
结果没有问题,抓到信息包。然后就可以使用我们分析网页的方法来进行后续的操作了。
Python爬虫:详解Appium如何爬取手机App数据以及模拟用户操作手势

Appium
在前文的讲解中,我们学会了如何安装Appium,以及一些基础获取App元素内容的方式。但认真看过前文的读者,肯定在博主获取元素的时候观察到了一个现象。
那就是手机App的内容并不是一次性加载出来的,比如大多数Android手机列表ListView,都是异步加载,也就是你滑动到那个位置,它才会显示出它的内容。
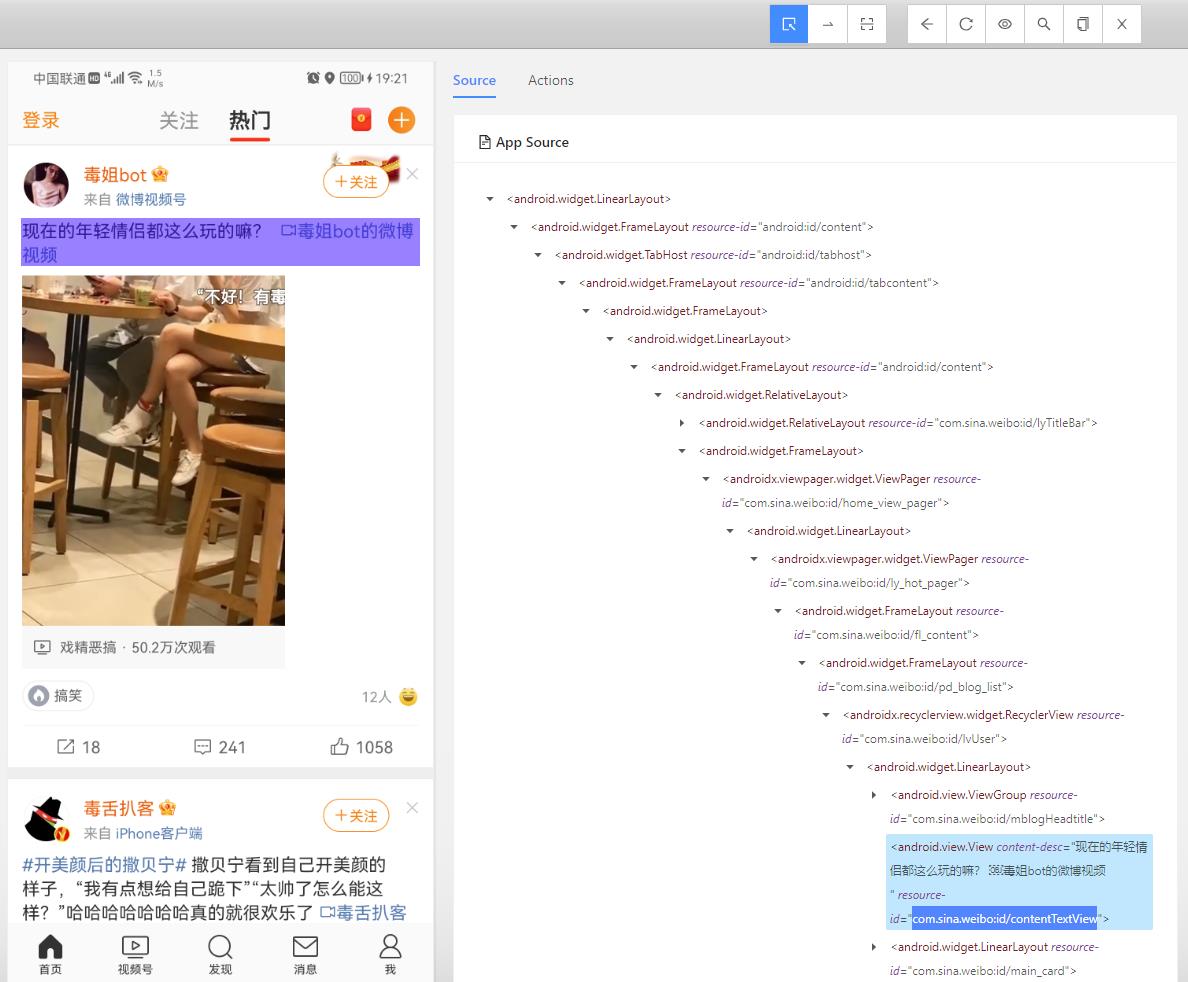
也就是说,我们前面爬取微博首页全部信息的时候,如果你不滑动先加载一定的微博内容,也就如上图所示,只能获取2个微博内容。
模拟操作
所以,我们要实战获取微博内容的话,首先你需要学会如何模拟滑动屏幕操作。下面,我们来一一介绍屏幕的互动操作。
屏幕滑动
在Python的Appium-Python-Client包中,我们通过swipe()函数模拟用户手势从A滑动到B点,其具体的方法定义如下所示:
def swipe(self: T, start_x: int, start_y: int, end_x: int, end_y: int, duration: int = 0) -> T
start_x:开始位置的横坐标
start_y:开始位置的纵坐标
end_x:结束位置的横坐标
end_y:结束位置的纵坐标
duration:持续时间,也就是处于距离后生成滑动速度
当然,滑动的方法还有一个:flick(),它只有4个参数,缺少duration参数,也就是快速从某个位置滑动到指定的位置。
示例代码:
from appium import webdriver
import time
server = "http://localhost:4723/wd/hub"
desired_caps = {
"platformName": "Android",
"deviceName": "liyuanjing",
"appPackage": "com.sina.weibo",
"appActivity": "com.sina.weibo.MainTabActivity",
}
driver = webdriver.Remote(server, desired_caps)
time.sleep(5)
el1 = driver.find_element_by_id("com.android.permissioncontroller:id/permission_allow_button")
el1.click()
time.sleep(5)
driver.swipe(500,500,500,2000,3000)
上面代码实现的下拉屏幕刷新功能,下拉刷新其实也是一个滑动的操作,是先滑动一段距离然后松开。
当然,如果你要实现上滑加载更多的微博,可以直接将坐标颠倒过来即可,这里我们将方法替换成flick(),也就是只需要替换最后一行代码。
driver.flick(487, 2085, 513, 257)
不过,这里有一个非常显著的问题,手机的坐标到底宽高都是多少呢?虽然说,我们程序员什么都通过代码先解决不要一上来就用工具。
但博主想说,这种坐标每个手机的像素分辨率都不同,比如上面swipe就是博主猜测的坐标。而flick()博主试了半天,没弄出来,最后还是借助Appium生成坐标给我。
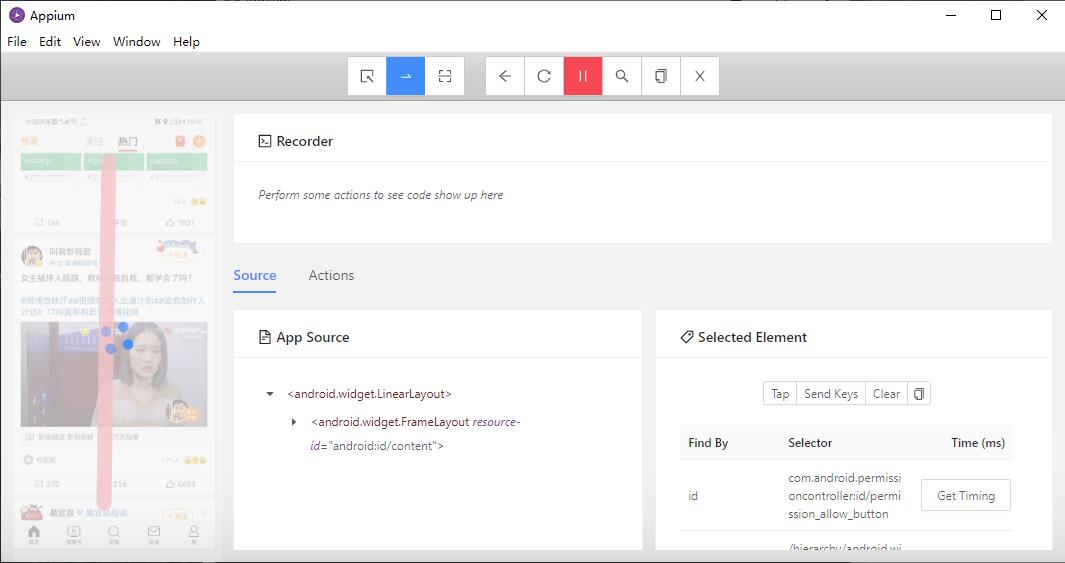
如上图所示,我们先点击蓝色选框中像“一横”的图标,然后记得点录制“眼睛”按钮。接着,在App上拉两个点,这2个点就是滑动的间距,最后生成如下图所示的代码。

这里就有2个坐标,当然上面的代码是动作链的知识后面我们会讲解。这里我们需要copy这2个坐标到flick()方法中,然后就可以下滑微博加载数据。
至于加载微博的动图与下滑微博的动图,大家都玩过微博,这里不需要演示。
屏幕点击
以前的微博都是限制为140字,你不需要打开微博详情,也能看到微博的所有数据。但是自从长微博出现之后,有些微博还必须点击进去才能看完整。
同样,我们爬取这些数据,有时候也要点击进去才能完全获取长微博的数据。所以,我们需要掌握如何点击某个微博。
在Appium包中,我们点击微博使用的是:tap()方法。该方法不仅支持单指点击,而且最多可以支持5个手指,同时也可以设置点击的时长。具体定义如下:
def tap(self: T, positions: List[Tuple[int, int]], duration: Optional[int] = None) -> T
positions:点击的位置组成的列表,比如五个手指,那就是5个坐标值的列表
duration:点击持续的时间,时间短就是点击操作,时间长就是长按操作
示例代码如下:
el2 = driver.tap([(500,500)])
el2.click()
不过,这里有读者肯定会问,每条微博的我难道用坐标取定位?那是怎么区分你点的是哪条微博,毕竟一个页面最少也有2条微博。这里,我们先来看张图:

这里,博主点击的是第2条微博数据,可以看到其id就是微博的内容。所以,后面我们想要获取微博的详细内容,可以直接通过获取内容后在点击。
屏幕拖动
看到这个小标题,博主都有写困惑。拖动与滑动是不是差不多的?
还别说,博主觉得还真差不多,不过这2个在Appium包中的方法却不一样,前文的滑动时通过坐标进行定位的,这里的拖动是通过元素定位的。
比如,你需要你滑动的距离是一个按钮到另一个按钮的位置,我们可以直接获取到这2个按钮,然后使用scroll()方法实现滑动操作。其定义如下:
def scroll(self: T, origin_el: WebElement, destination_el: WebElement, duration: Optional[int] = None) -> T
origin_el:被操作的元素
destination_el:目标元素
duration:持续时间
这里就不演示了,就是获取元素位置然后拖动到指定元素的位置。与前文实现的效果差不多,只是将坐标变成了2个元素的位置。
屏幕拖拽
同样的,微博不好演示的还有拖拽操作。它的方法为drag_and_drop(),其定义如下:
def drag_and_drop(self: T, origin_el: WebElement, destination_el: WebElement) -> T
origin_el:被拖拽的元素
destination_el:目标元素
这里的拖拽你可以理解为将一个按钮元素拖动到另一个按钮的位置,这里拖拽的是元素本身,不是位置的滑动。微博中暂时也没有演示的操作,感兴趣的可以测试其他App。
文本输入
在模拟登录或者说这里发微博的时候,用户肯定需要模拟输入文本。而且,在需要登录的爬虫场景之下,登录都是必备步骤。比如微信朋友圈内容的爬取,你不登陆看得到朋友圈吗?
所以,我们需要掌握Appium的文本输入操作。而它提供了2个方法进行文本的输入,一个是set_text();一个是send_keys()。
现在我们模拟微博输入账号,示例代码如下:
from appium import webdriver
import time
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as ec
server = "http://localhost:4723/wd/hub"
desired_caps = {
"platformName": "Android",
"deviceName": "liyuanjing",
"appPackage": "com.sina.weibo",
"appActivity": "com.sina.weibo.MainTabActivity",
}
driver = webdriver.Remote(server, desired_caps)
wait = WebDriverWait(driver, 20)
time.sleep(5)
el1 = driver.find_element_by_id("com.android.permissioncontroller:id/permission_allow_button")
el1.click()
el2 = wait.until(ec.presence_of_element_located((By.ID, 'com.sina.weibo:id/titleBack')))
el2.click()
el3 = wait.until(ec.presence_of_element_located((By.ID, 'com.sina.weibo:id/et_login_view_phone')))
el3.send_keys("liyuanjinglyj@163.com")
这里,我们只是模拟输入文本,当然登录用户名是手机,但手机属于隐私。博主这里替换成邮箱。感兴趣的可以自己替换手机试试。同时也可以替换为send_text()方法。
动作链
动作链顾名思义就是一系列操作动作的组合。在Selenium中,动作链是ActionChains,而Appium中,动作链是TouchAction。
比如,我们执行的下拉刷新其实就是一个动作链。这里,我们会执行2个动作,一个是按压,一个是从指定位置滑动到另一个位置。这里,我们将2个动作组合实现:
TouchAction(driver).press(x=380, y=2101).move_to(x=390, y=519).release()
实战:爬取微博首页信息
其实,Appium开始推出的时候,是为了自动化测试准备的工具,并不专用于爬虫数据。而且Appium有一个缺陷,目前没有直接的办法获取图片。
如果你想下载App界面中的图片,可以模拟用户长按的操作进行图片的下载。也可以直接截图。话不多说,我们来实现获取微博的文字信息并保存到目录。示例如下:
from appium import webdriver
import time
from selenium.webdriver.support.ui import WebDriverWait
import os
def mkdir(path):
path = path.strip()
path = path.rstrip("\\\\")
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
server = "http://localhost:4723/wd/hub"
desired_caps = {
"platformName": "Android",
"deviceName": "liyuanjing",
"appPackage": "com.sina.weibo",
"appActivity": "com.sina.weibo.MainTabActivity",
}
driver = webdriver.Remote(server, desired_caps)
wait = WebDriverWait(driver, 20)
time.sleep(5)
el1 = driver.find_element_by_id("com.android.permissioncontroller:id/permission_allow_button")
el1.click()
time.sleep(5)
mkdir("weiboFile")
for i in range(10):
items = driver.find_elements_by_id("com.sina.weibo:id/contentTextView")
for item in items:
txt_text = item.get_attribute("content-desc")
folder_output = 'weiboFile/%s.txt' % str(int(time.time()))
with open(folder_output, "w", encoding='utf-8') as f:
f.write(txt_text)
f.close()
print(txt_text)
driver.swipe(487, 2085, 513, 257, 3000)
上面代码主要的功能在for-in循环之中。这里,我们通过先获取文本数据保存之后,在滑动屏幕获取其他的微博数据。
如果你想获取更多的数据,可以把循环的次数设置的更大一些。因为App的数据都是在滑动之中进行加载的。运行之后,效果如下所示:


以上是关于如何进行手机APP的数据爬取?的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫:详解Appium如何爬取手机App数据以及模拟用户操作手势
Python爬虫:详解Appium如何爬取手机App数据以及模拟用户操作手势