Python代码规范:代码规范整改和编码技巧-pylint扫描问题整改
Posted SteveRocket
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python代码规范:代码规范整改和编码技巧-pylint扫描问题整改相关的知识,希望对你有一定的参考价值。
1. 遵循PEP8规范,确保代码的格式和风格一致性。这可以通过编辑器或工具来自动化。
2. 将代码拆分为小的、易于维护和重用的函数、类和模块。
3. 使用注释来解释代码的目的和功能。
4. 使用有意义的函数和变量名称,这将使代码更易于理解。
5. 避免使用全局变量和魔术数字。
6. 对于大量或复杂的代码块,使用代码注释或文档字符串。
7. 使用异常处理来减少程序崩溃的可能性,并提供有意义的错误消息。
8. 使用工具或库来自动化常见任务,并减少犯错的可能性。
9. 最好结合团队成员的意见和审查来进行整改。
扫描工具的使用参考文章:
 https://blog.csdn.net/zhouruifu2015/article/details/129877179
https://blog.csdn.net/zhouruifu2015/article/details/129877179Line too long (127/120)
行的字符个数127个字符超过了120个的限制数量,进行格式化换行即可。
Variable name "st" doesn't conform to snake_case naming style (invalid-name)

修改成

Missing module docstring (missing-module-docstring)
添加模块的docstring文档说明即可
C0103: Constant name "%s" doesn't conform to snake_case naming style
将常量名更改为snake_case风格
C0115: Missing class docstring (missing-class-docstring)
类中需要添加类docstring文档说明
C0116: Missing function or method docstring (missing-function-docstring)
添加方法docstring文档说明
C0209: Formatting a regular string which could be a f-string (consider-using-f-string)
DB_URI = 'mysql+pymysql://0:1@2/3?charset=utf8'.format(
MYSQL_USERNAME,
MYSQL_PASSWORD,
MYSQL_HOSTNAME,
MYSQL_DATABASE,
)替换成
DB_URI = f'mysql+pymysql://MYSQL_USERNAME:' \\
f'MYSQL_PASSWORD@MYSQL_HOSTNAME/MYSQL_DATABASE?charset=utf8'W0212: Access to a protected member _id of a client class (protected-access)
该错误发生在访问受保护的类成员时。被保护的成员是指只能从该类及其子类中访问的成员。如果在使用时出现此错误,则意味着代码违反了OOP的封装原则,必须更改代码以遵循该原则。
要解决此错误,可以通过以下方法之一:
- 将受保护成员更改为公共成员或添加公共方法以访问该成员。
- 将调用受保护成员的代码移动到类或其子类中。
- 使用单元测试检查代码逻辑,并确保测试涵盖调用受保护成员的所有情况。
可以通过将访问受保护的成员变量_id的代码移至子类中的公共方法或使用getter方法来解决。如果这仍然是必需的,请使用以下语法解决:
# 子类访问保护成员变量
class Child(Parent):
def __init__(self):
Parent.__init__(self)
def print_id(self):
print(self._id)
W0237: Parameter 'o' has been renamed to 'obj' in overridden 'NamespaceEncoder.default' method (arguments-renamed)
该错误表示在重写方法时重命名其参数。这通常是由误操作或不必要的更改引起的。为了避免混淆,建议始终保留参数名称。如果需要更改名称,则应在文档中进行记录以便其他人理解。
可以简单地更改参数名称以匹配重写方法的原始参数名称。这将确保代码的一致性并防止错误的发生。
可以通过在子类中接受与父类接口相同的参数名称来解决。然后,可以使用参数名称传递相同的参数,即使它们被重命名为不同的名称。例如:
# 子类重命名参数
class CustomNamespaceEncoder(json.JSONEncoder):
def default(self, obj, **kwargs):
...
W0221: Variadics removed in overridden
这个错误通常是由于在子类中重写具有可变参数列表的方法时出现的问题。Python 3.x 中已删除了可变参数列表。要解决这个问题,可以使用 `*args` 和 `**kwargs` 代替可变参数列表。下面是一个示例:
class A:
def foo(self, *args, **kwargs):
pass
class B(A):
def foo(self, arg1, arg2, *args, **kwargs): # 这样重写是正确的
pass
还可以在子类方法的参数列表中使用 `*args` 和 `**kwargs` , 以便将参数传递给父类:
class B(A):
def foo(self, *args, **kwargs):
super().foo(*args, **kwargs)这将调用父类的方法,并将所有传递给 `foo()` 的参数传递给它。 无论哪种方法,都可以解决这个问题。
W0613: Unused argument '%s'
删除未使用的参数或者使用它
W0622: Redefining built-in 'id' (redefined-builtin)
在 Python 中出现 W0622 警告时,通常是因为您已在代码中重定义了 Python 内置函数或方法。例如,在代码中重新定义了 `id()` 函数。要解决此问题,请遵循以下步骤:
1. 首先,检查代码并确定哪个函数或方法是重定义的 Python 内置功能。
2. 可以更改函数或方法的名称,以避免与 Python 内置函数或方法名称冲突。例如,更改 `id()` 函数的名称可以避免此警告。将其更改为 `my_id()` 或其他非内置名称。
3. 如果不能更改函数或方法名称,则可以使用以下方法来解决此问题。在函数或方法的开头添加以下代码:
```python
# pylint: disable=W0622
```
此代码将禁用 W0622 警告。但是,请注意,这将禁用该警告的全部实例。
4. 另一种方法是通过使用 `from __future__ import` 语句来解决此问题。
```python
from __future__ import absolute_import, division, print_function
```
此代码导入了 Python 未来的一些功能,可以防止与内置功能名称冲突的问题。
通过以上方法,均可有效地解决警告问题。
W0703: Catching too general exception Exception/BaseException (broad-except)
这个警告消息是说Exception捕获太多的错误类型,捕获的异常过于宽泛,没有针对性,应该使用具体的错误类型,例如通过指定精确的异常类型来解决ValueError, 在顶层函数中使用Exception来捕获异常。
具体的错误类型:
- BaseException: 所有异常的基类
- SystemExit: 解释器请求退出
- KeyboardInterrupt: 用户中断执行(通常是输入^C)
- Exception: 常规错误的基类
- StopIteration: 迭代器没有更多的值
- GeneratorExit: 生成器(generator)发生异常来通知退出
- StandardError: 所有的内建标准异常的基类
- ArithmeticError: 所有数值计算错误的基类
- FloatingPointError: 浮点计算错误
- OverflowError: 数值运算超出最大限制
- ZeroDivisionError: 除(或取模)零 (所有数据类型)
- AssertionError: 断言语句失败
- AttributeError: 对象没有这个属性
- EOFError: 没有内建输入,到达EOF 标记
- EnvironmentError: 操作系统错误的基类
- IOError: 输入/输出操作失败
- OSError: 操作系统错误
- WindowsError: 系统调用失败
- ImportError: 导入模块/对象失败
- LookupError: 无效数据查询的基类
- IndexError: 序列中没有此索引(index)
- KeyError: 映射中没有这个键
- MemoryError: 内存溢出错误(对于Python 解释器不是致命的)
- NameError: 未声明/初始化对象 (没有属性)
- UnboundLocalError: 访问未初始化的本地变量
- ReferenceError: 弱引用(Weak reference)试图访问已经垃圾回收了的对象
- RuntimeError: 一般的运行时错误
- NotImplementedError: 尚未实现的方法
- SyntaxError: Python 语法错误
- IndentationError: 缩进错误
- TabError: Tab 和空格混用
- SystemError: 一般的解释器系统错误
- TypeError: 对类型无效的操作
- ValueError: 传入无效的参数
- UnicodeError: Unicode 相关的错误
- UnicodeDecodeError: Unicode 解码时的错误
- UnicodeEncodeError: Unicode 编码时错误
- UnicodeTranslateError: Unicode 转换时错误
- Warning: 警告的基类
- DeprecationWarning: 关于被弃用的特征的警告
- FutureWarning: 关于构造将来语义会有改变的警告
- OverflowWarning: 旧的关于自动提升为长整型(long)的警告
- PendingDeprecationWarning: 关于特性将会被废弃的警告
- RuntimeWarning: 可疑的运行时行为(runtime behavior)的警告
- SyntaxWarning: 可疑的语法的警告
- UserWarning: 用户代码生成的警告
如果不确定有可能发生的错误,或者是就要使用 Exception 而且还不许 Pylint/PyCharm报提示,那该怎么解决?
1. 关闭编译器中代码检测中有关检测 Exception 的选项
2. 在 try 语句前加入 # noinspection PyBroadException 即可(实际测试针对pylint的检测不起作用)
# noinspection PyBroadException
try:
pass
except Exception as e:
pass
注意:如果想跳过pylint针对此项的检测,使用BaseException 或 标注noqa是无法逃避pylint检测的。

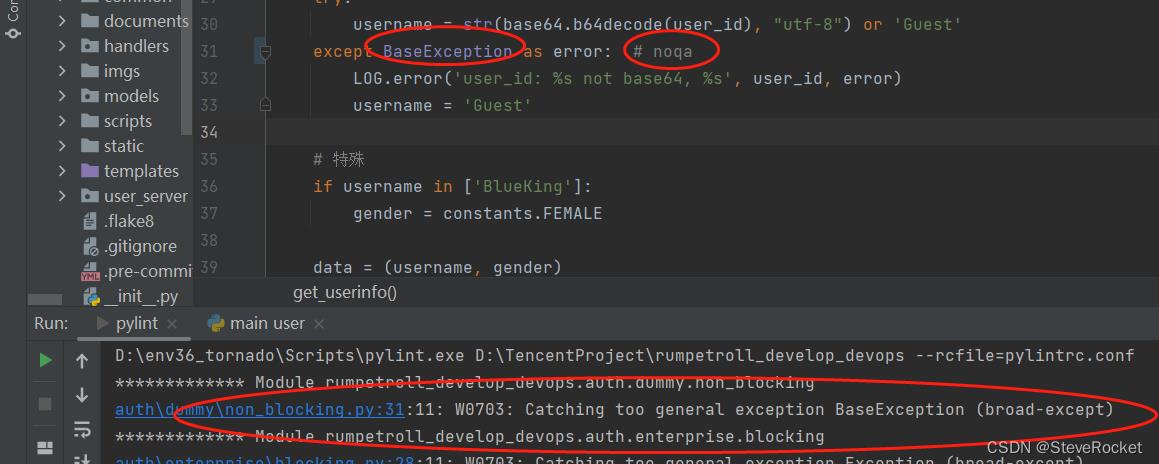
如果想在使用 Pylint 时跳过某个特定的检查(例如上面提到的“Catching too general exception Exception”),可以使用以下方法:
1. 在代码中添加注释来跳过该检查。
例如,在捕获异常时,可以在该行代码上添加以下注释:
```python
try:
# pylint: disable=broad-except
some_code_that_might_raise_an_exception()
except Exception:
handle_exception()
```
在这个例子中,添加了 `pylint: disable=broad-except` 注释,以禁用 `Catching too general exception Exception` 检测。这将告诉 Pylint 忽略此检测。注释中的 `broad-except` 是表示此检测的标识符。如下:
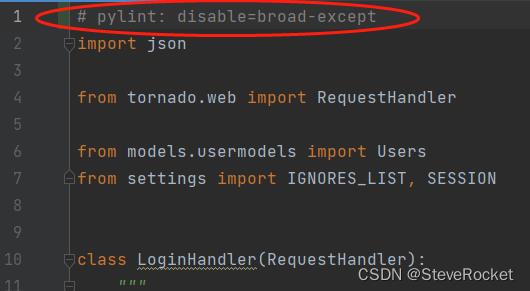
2. 将特定的检测标识符添加到 Pylint 的配置文件中,并将其设置为禁用。
要这样做,需要编辑 Pylint 的配置文件(通常是 `.pylintrc`),并添加以下内容:
```ini
[DISABLED]
C0103 # invalid-name
W0702 # no-else-return
```
在这个例子中,将 `C0103` 和 `W0702` 标识符添加到了 `[DISABLED]` 部分中,这将告诉 Pylint 禁用这两个检测。将特定的检测标识符添加到配置文件中是一种更持久的方法,可以确保在运行 Pylint 时始终禁用它们。
W1201: Use lazy % formatting in logging functions (logging-not-lazy)
由于Python的logging模块中处理字符串格式的方式可能会导致性能问题。它建议使用“惰性”字符串格式来避免这些问题。
应该向日志记录函数传递格式字符串和参数,而不是已经格式化的字符串。否则,格式化操作本身就会冒着在日志记录发生之前引发异常的风险。这些是老式的printf style format strings。出于同样的原因,pylint也会对f字符串报警。
要解决该问题,有以下几种方法:
1. 在logging调用中使用惰性字符串格式。例如,使用f字符串代替百分号格式化字符串,如下所示:
```
logger.debug(f"This is a debug message with argument arg")
```
2. 使用新式字符串格式化,如下所示:
```
logger.debug("This is a debug message with argument ".format(arg))
```
3. 使用延迟格式化日志消息记录器,避免在记录器函数中评估可变参数消息。这种方法可以避免日志格式中的变量被多次计算,从而提高性能:
log = logging.getLogger(__name__)
log.addHandler(logging.StreamHandler())
log.setLevel(logging.DEBUG)
class LazyLogger(object):
def __init__(self, log_func):
self.log_func = log_func
def _get_msg(self, args, kwargs):
return self.log_func(*args, **kwargs)
def __call__(self, *args, **kwargs):
if self.log_func == log.debug:
if log.isEnabledFor(logging.DEBUG):
self.log_func(self._get_msg(args, kwargs))
else:
pass
else: # info, warn, error, critical
self.log_func(self._get_msg(args, kwargs))
LAZY_LOG = LazyLogger(log.debug)
LAZY_LOG('Log message %s', time.time())这样可以确保日志消息只有在必要时才被计算,从而减少不必要的开销。重要的是要注意使用这种方法的影响,因为它可能会导致在某些时候延迟日志的记录。
W1514: Using open without explicitly specifying an encoding (unspecified-encoding)

在Python中,打开文件时应该明确指定编码方式,这有助于确保文件正确地读取和写入。
要解决W1514警告,可以采取以下步骤:
1.在打开文件时明确指定编码格式,例如使用“utf-8”编码方式:
```python
with open("filename.txt", "r", encoding="utf-8") as f:
# 文件操作
```
2. 如果你不确定文件的编码格式,可以使用chardet库来推测文件的编码格式:
import chardet
with open("filename.txt", "rb") as f:
rawdata = f.read()
encoding = chardet.detect(rawdata)['encoding']
with open("filename.txt", "r", encoding=encoding) as f:
# 文件操作使用上述方法可以避免出现“unspecified-encoding”警告,而且会确保文件以正确的编码方式被读取和写入。
Invalid constant name "data"
pylint的常量定义模式为: (([A-Z_][A-Z0-9_]*)|(__.*__))$,常量命名要用大写字母,所以这个就出现警告消息了
no config file found, using default configuration
这个问题是在目录中没有pylintrc文件,可以生成pylintrc文件来解决这个问题
pylint --generate-rcfile > pylintrc
R0205: Class 'Namespace' inherits from object, can be safely removed from bases in python3 (useless-object-inheritance)
这个警告表明类继承自 object,而在 Python 3 中这是一个无用的操作。因为所有类都默认继承自对象,所以没有必要再显式声明。因此,可以在类定义中删掉"object"即可。可以采用以下方法来解决这个问题:
1. 从类定义中删除基类 object;
2. 直接从 object 中继承,而不是在类定义中显式地指定它。
R0902: Too many instance attributes (11/7) (too-many-instance-attributes)
这个警告表明了类中使用了太多的实例属性。可以采用以下的一些方法,以减少实例属性的数量:
1. 使用类属性来替代实例属性;
2. 使用动态属性;
3. 重构代码以将逻辑拆分到更小的组中以降低实例属性的数量。
R0913: Too many arguments (%s/%s)
重构函数,减少参数数量
R1710: Either all return statements in a function should return an expression, or none of them should. (inconsistent-return-statements)
此警告表明函数中的某些 return 语句返回了表达式,而某些则没有。为了解决这个问题,你需要确保你在函数中使用的所有 return 语句都返回一个表达式,或者都没有返回。可以采取以下行动之一:
1. 确保所有的 return 语句都返回一个表达式;
2. 修改函数的结构,确保不需要在某些情况下返回一个表达式。
3. 添加或删除函数的返回语句,使它们的返回值保持一致
R1720: Unnecessary "else" after "raise", remove the "else" and de-indent the code inside it (no-else-raise)
这个警告的意思是,在raise语句后面的else子句是不必要的,因为raise语句将立即停止函数的执行,不会执行else中的任何代码。为了解决这个问题,你可以删除else子句,并把else后面的代码缩进。
例如:
```
if x < 0:
raise ValueError("x 不能是负数")
else:
return math.sqrt(x)
```
可以改成:
```
if x < 0:
raise ValueError("x 不能是负数")
return math.sqrt(x)
```
这样就可以避免警告了。

改成


改成

R1721: Unnecessary use of a comprehension, use list(self.clients) instead. (unnecessary-comprehension)
这个问题是因为在代码中使用了不必要的列表推导式。可以修改代码,使用list()函数代替列表推导式,以消除这个问题。例如:
原代码:
clients = [client for client in self.clients]修改后:
clients = list(self.clients)
这样就可以消除R1721警告信息。
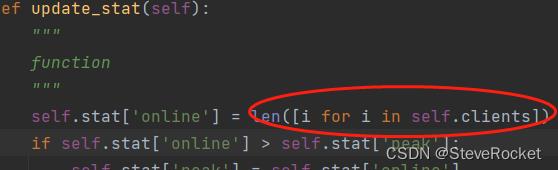
修改后

R1724: Unnecessary "else" after "continue", remove the "else" and de-indent the code inside it (no-else-continue)
解决方法同1720
R1725: Consider using Python 3 style super() without arguments (super-with-arguments)
在 Python 2.x 中,使用 `super()` 必须提供两个参数,即当前类和当前实例。但在 Python 3.x 中,可以省略这两个参数,因为 Python 3.x 中的 `super()` 具有自动检测功能。在使用 `super()` 时不提供参数会导致 R1725 的警告,因为这种方式不符合 Python 3 风格的语法,但总体上并不影响代码的运行。
要解决 R1725 报告的警告,可以采用以下两种方法:
1. 使用 Python 3 风格的 `super()`,即省略参数。例如,将 `super(MyClass, self).__init__()` 改为 `super().__init__()`。
2. 忽略警告,通过在代码中添加以下标记来实现:
# pylint: disable=super-with-arguments或
# pylint: disable=R1725这样可以禁用 pylint 的警告报告机制,但不应长期忽略警告。建议尽可能使用第一种方法来修复 R1725 的警告。
Unused variable 'num_glod'
定义了未使用的变量,删除掉变量,或者使用 _ 占位符进行占位。
Unused import json
导入的内置包未使用,删除掉即可
Unused IGNORES_LIST imported from settings
导入了的内部模块变量未使用,删除掉即可

输入才有输出,吸收才能吐纳。——码字不易
shell脚本--代码风格规范及技巧
shell脚本--代码风格规范及技巧
命名有标准
文件名规范,以.sh结尾,方便识别
编码要统一
在写脚本的时候尽量使用UTF-8编码,能够支持中文等一些奇奇怪怪的字符。不过虽然能写中文,但是在写注释以及打log的时候还是尽量英文,毕竟很多机器还是没有直接支持中文的,打出来可能会有乱码。
这里还尤其需要注意一点,就是当我们是在windows下用utf-8编码来写shell脚本的时候,一定要注意这个utf-8是否是有BOM的。默认情况下windows判断utf-8格式是通过在文件开头加上三个EF BB BF字节来判断的,但是在Linux中默认是无BOM的。因此如果我们是在windows下写脚本的时候,一定要注意将编码改成Utf-8无BOM,一般用notepad++之类的编辑器都能改。否则,在Linux下运行的时候就会识别到开头的三个字符,从而报一些无法识别命令的错。
开头有shebang
所谓shebang其实就是在很多脚本的第一行出现的以”#!”开头的注释,他指明了当我们没有指定解释器的时候默认的解释器,一般可能是下面这样:
#!/bin/bash写出健壮Bash Shell脚本技巧
set -e
set -u
set -o pipeline(1)在"set -e"之后出现的代码,一旦出现了返回值非零,整个脚本就会立即退出。 (2)set -u,当你使用未初始化的变量时,让bash自动退出 (3)set -o pipefail 设置了这个选项以后,包含管道命令的语句的返回值,会变成最后一个返回非零的管道命令的返回值。听起来比较绕,其实也很简单:
例如test.sh
set -o pipefail
ls ./a.txt |echo "hi" >/dev/null
echo $?运行test.sh,因为当前目录并不存在a.txt文件,输出: ls: ./a.txt: No such file or directory 1 # 设置了set -o pipefail,返回从右往左第一个非零返回值,即ls的返回值1
注释掉set -o pipefail 这一行,再次运行,输出: ls: ./a.txt: No such file or directory 0 # 没有set -o pipefail,默认返回最后一个管道命令的返回值
工作路径
我们会先获取当前脚本的路径,然后一这个路径为基准,去找其他的路径。
work_dir=$1
reference=${work_dir}/data/reference/TAIR10_chr_all.fas环境变量PATH
一般情况下我们会将一些重要的环境变量定义在开头,确保脚本中使用的命令能被bash搜索到。
PATH=/bin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin运行脚本
chmod +x ./test.sh #给脚本权限
./test.sh #执行脚本Shell中的变量
“=”前后不能有空格
定义时不用$,使用时需要$,且推荐给所有变量加上花括号{}
脚本的参数
先定义具体含义,后使用
gene_file=$1
${gene_file}
代码有注释
简述某一代码段的功能
各个函数前的说明注释
太长要分行
在调用某些程序的时候,参数可能会很长,这时候为了保证较好的阅读体验,我们可以用反斜杠来分行:
./configure \
–prefix=/usr \
–sbin-path=/usr/sbin/nginx \
–conf-path=/etc/nginx/nginx.conf \日志
例如:
./sub_gtf.shell gene.txt Homo_sapiens.GRCh38.89.chr.gtf >logfile 2>&11 :表示stdout标准输出,系统默认值是1,所以">logfile"等同于"1>logfile" 2 :表示stderr标准错误 & :表示等同于的意思,2>&1,表示2的输出重定向等同于1
回显
例如
if [[ $# != 2 ]];then
echo "Parameter incorrect."
exit 1
fi当执行:
./sub_gtf.shell gene.txt因为参数数目不对,输出Parameter incorrect.至屏幕
当执行:
./sub_gtf.shell gene.txt >logfile 2>&1同样参数数目不对,但输出Parameter incorrect.至日志
函数相关
巧用main函数,使得代码可读性更强
#!/bin/bash
func1(){
#do sth
}
func2(){
#do sth
}
main(){
func1
func2
}
main "$@"考虑作用域
shell中默认的变量作用域都是全局的,比如下面的脚本:
#!/usr/bin/env bash
var=1
func(){
var=2
}
func
echo $var他的输出结果就是2而不是1,这样显然不符合我们的编码习惯,很容易造成一些问题。
因此,相比直接使用全局变量,我们最好使用local, readonly这类的命令,其次我们可以使用declare来声明变量。这些方式都比使用全局方式定义要好。
local一般用于局部变量声明,多在在函数内部使用。
(1)shell脚本中定义的变量是global的,其作用域从被定义的地方开始,到shell结束或被显示删除的地方为止。
(2)shell函数定义的变量默认是global的,其作用域从“函数被调用时执行变量定义的地方”开始,到shell结束或被显示删除处为止。函数定义的变量可以被显示定义成local的,其作用域局限于函数内。但请注意,函数的参数是local的。
(3)如果同名,Shell函数定义的local变量会屏蔽脚本定义的global变量。
使用举例:
#!/bin/bash
function Hello()
{
local text="Hello World!!!" #局部变量
echo $text
}
Hello
只读变量
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
例如:
readonly myUrl
myUrl="http://www.runoob.com"declare
-r 只读 (declare -r var1与readonly var1作用相同)
declare -r var1
-i 整数
declare -i number
-a 数组
declare -a indices
-f 函数
declare -f
函数返回值
在使用函数的时候一定要注意,shell中函数的返回值只能是整数,估计是因为一般情况下一个函数的返回值通常表示这个函数的运行状态,所以一般都是0或者是1就够了,因此就设计成了这样。不过,如果非得想传递字符串,也可以通过下面变通的方法:
func(){
echo "2333"
}
res=$(func)
echo "This is from $res."这样,通过echo或者print之类的就可以做到传一些额外参数的目的。
使用新写法
这里的新写法不是指有多厉害,而是指我们可能更希望使用较新引入的一些语法,更多是偏向代码风格的,比如
尽量使用func(){}来定义函数,而不是func{}
尽量使用[[]]来代替[]
尽量使用$()将命令的结果赋给变量,而不是反引号
在复杂的场 下尽量使用printf代替echo进行回显
事实上,这些新写法很多功能都比旧的写法要强大,用的时候就知道了。
其他小tip
读取文件时不要使用for loop而要使用while read
简单的if尽量使用&& ||,写成单行。比如[[ x > 2]] && echo x
利用/dev/null过滤不友好或者无用的输出信息
例如 if grep 'pattern1' some.file > /dev/null && grep 'pattern2' some.file > dev/null then echo "found 'pattern1' and 'pattern2' in some.file" fi
/dev/null :代表空设备文件
安装shellcheck
ShellCheck, a static analysis tool for shell scripts
使用方式(1)网页版:
http://www.shellcheck.net
github仓库:
https://github.com/koalaman/shellcheck
下载安装: wget -q https://storage.googleapis.com/shellcheck/shellcheck-latest.linux.x86_64.tar.xz xz -d shellcheck-latest.linux.x86_64.tar.xz tar -xvf shellcheck-latest.linux.x86_64.tar echo 'export PATH=/home/wangdong/softwares/shellcheck:$PATH'>>~/.bashrc source ~/.bashrc
使用方式(2)终端:
shellcheck yourscipts
Shell不能做什么
需要精密的运算的时候
需要语言效率很高的时候
需要一些网络操作的时候
总之Shell就是可以快速开发一个脚本简化开发流程,并不可以用来替代高级语言
参考:
(1)https://blog.mythsman.com/2017/07/23/1/
(2)https://github.com/koalaman/shellcheck
以上是关于Python代码规范:代码规范整改和编码技巧-pylint扫描问题整改的主要内容,如果未能解决你的问题,请参考以下文章