R语言数据的导入输出及调整
Posted 科研小白 新人上路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言数据的导入输出及调整相关的知识,希望对你有一定的参考价值。
数据的导入
在应用R进行数据分析之前,首先要做的一步工作就是将数据导入R工作环境。
原文链接:R语言数据的导入、输出及调整
R所识别的数据通常为“X·Y”型的多变量数据,格式为txt或csv格式,不同数据间以制表符(Tab)或“,”间隔。
输入数据可以使用excel进行录入和基本格式的修改,之后另存为,选择制表符分隔的文本(.txt)或CSV UTF-8(逗号分隔)(.csv)。

R中最常使用read.table()和read.csv()命令对数据进行导入。
read.table
read.table(file, header = FALSE, sep = "",
quote = ""'",dec = ".", row.names, col.names,
as.is = !stringsAsFactors, na.strings = "NA",
colClasses = NA, nrows = -1,skip = 0,
check.names = TRUE, fill = !blank.lines.skip,
strip.white = FALSE, blank.lines.skip = TRUE,
comment.char = "#",allowEscapes = FALSE, flush = FALSE,
stringsAsFactors = default.stringsAsFactors(),
fileEncoding = "", encoding = "unknown")参数解读:
- file,导入文件的名称,要用绝对路径;
- header,逻辑参数,指定是否文件第一行定义为列名;
- sep:
指定数据分割字符,制表符为”\\t”,逗号为”,”; - na.strings:指定缺失文字
- skip:指定读数据跳过的行数
- nrows:指定数据读入最大的行数
- dec:
指定小数点记号 - row.names与col.names,赋予数据行名和列名
- colClasses,数据中每列的类型
- comment.char 注释字符,即忽略携带此字符的行
- stringsAsFactors字符变量是否变为因子
如导入的文件与运行的R脚本位于同一文件夹中,则无需输入绝对路径,只需输入文件名即可。
通常数据的第一行为列名,第一列为行名,此时可以将参数设置为“header = TRUE, row.names = 1”。
data <- read.table(file = "tem.txt", header = TRUE, row.names = 1, sep = "\\t"其余参数一般默认即可。
read.csv
read.table()命令可以解决绝大多数数据导入的问题,但是在个别情况下,会导致数据导入失败或格式错乱,本人之前曾经遇到过,发生次数极少,原因未知,此时可以试试read.csv()命令。
read.csv()命令的使用方法和参与基本上与read.table()一致。
data <- read.csv(file = "tem.txt", header = TRUE, row.names = 1, sep = "\\t", as.is = TRUE)read.csv()命令导入数据时会自动的将非数值类型的数据是为因子(factor),但有时我们可能就是需要字符形式的数据,此时只需把as.is参数设置为TRUE即可。
报错解决
在做数据分析时,经常会碰到一些元素是以0开头的数字,在使用函数read.table或者read.csv等读取文件时,会自动的将开头的0去掉。
可以通过设定read.table或者read.csv的参数colClasses=”character”来解决这一问题。
在导入数据时,会出现这样的错误:scan(file, what, nmax, sep, dec, quote, skip, nlines, na.strings,:15行没有5元素。
这是由于在提示的位置,数据的格式不规则导致无法识别,可以手动进行修改或者设定read.table的参数fill=TRUE来解决。
数据的导出
在进行一系列数据整理或统计学分析之后,可能需要导出结果数据,此时需要用到write.table()命令。
write.table(x, file = "", append = FALSE,
quote = TRUE, sep = " ", eol = "\\n", na = "NA",
dec = ".", row.names = TRUE, col.names = TRUE,
qmethod = c("escape", "double"))参数解读:
- x为需要写入的文件,一般为一个数据框;
- file为输入文件的路径和名字;
- append如为FALSE,则任何同名的文件均会被替换;
- quote规定输出的文件中的数字或字符是否被双引号括在内;
- sep规定每一行中不同的值之间的间隔符;
- eol规定在每一行最后的字符,“\\n”代表换行;
- na规定代表缺失数据的字符;
- dec规定小数点的表示符号;
- row.names和col.names规定输出的文件中是否包含行名或列名;
- qmethod规定如何处置双引号字符,默认为escape,此时忽略双引号,当设置为double时,则把双引号当做字符输出。
#将data导出为result.txt文件
write.table(data, file = "result.txt", sep = "\\t", quote = FALSE)数据框的基本调整
通过read.table或read.csv导入的数据一般为数据框格式(data frame),有时需要将数据框变为矩阵或着将矩阵变为数据框。
data <- as.matrix(data)
data <- as.data.frame(data)有些分析可能需要对数据进行转置。
data <- t(data)提取部分数据
使用[,]进行数据框中特定数据的选择,逗号前代表行,逗号后代表列,数字代表行或列的排序。
#提取第一行第二列的数据
data <- data[1,2]
#提取前5行或前5列
data <- data[1:5,]
data <- data[,1:5]
#提取第1、3、5行
data <- data[c(1,3,5),]
#删除第一列
data <- data[,-1]apply()函数
apply()函数可以按照行或列对数据框进行计算和统计。
apply(X, MARGIN, FUN, ...)- X为需要进行计算的数据框
- MARGIN指定计算方式
- 1代表按照行计算
- 2代表按照列计算
- c(1,2)代表同时进行行和列计算
- FUN为计算公式
- sum代表求和
- mean代表求平均数
- max代表返回最大值
- min代表返回最小值
- ……
相关的FUN函数非常多样,根据自己的需要自行搜索即可。
#求data中每一行的总和
a <- apply(data,1,sum)
#返回的向量a中会按照行的顺序给出每一行的总和
#求data中每一列的平均值
b <- apply(data,2,mean)数据格式转换
通常意义上的“X·Y”型数据被称作“宽格式”,数据所属的分组由其在矩阵中的位置决定,例如数据a位于A行a列,则其分组信息即为“A”和“a”。
在部分R语言的函数中,其识别的数据类型并不是常规的“宽格式”而是“长格式”,在长格式的数据中,每一行代表一个条目,而其所属分组是在其它单独的列中指定。
在进行数据分析和可视化时,有时需要将“宽格式”的数据转化为“长格式”,此时就需要用到reshape2包中的melt()命令。
melt(data, id.vars, measure.vars,
variable.name = "variable", na.rm = FALSE,
value.name = "value", ...)参数解释:
- id.vars是被当做维度的列变量,每个变量在结果中占一列
- measure.vars是被当成观测值的列变量,它们的列变量名称和值分别组成variable和value两列
- 列变量名称用variable.name和value.name来指定
#首先要安装并载入reshape2包
install.packages("reshape2")
library(reshape2)
data <- data.frame(A=c(1:5),
B=c("a","b","c","d","e"),
C=c("Day","Day","Month","Month","Year"))
data
A B C
1 1 a Day
2 2 b Day
3 3 c Month
4 4 d Month
5 5 e Year
data1 <- melt(data, id.vars = "A")
data1
A variable value
1 1 B a
2 2 B b
3 3 B c
4 4 B d
5 5 B e
6 1 C Day
7 2 C Day
8 3 C Month
9 4 C Month
10 5 C Year
相关推荐:
R语言回归及混合效应(多水平/层次/嵌套)模型及贝叶斯实现实践技术
软件R语言数据导入与导出
“R语言导入文本和xlsx文件数据的方法,以及数据与图片的输出”
许多数据往往保存在TXT文件或Excel文件中,该如何将这些文件导入R语言进行分析呢?另外,使用R语言处理完数据之后,我们希望导出一些有用的信息,那么如何将R语言的数据处理结果输出为文档呢?本文将就这些问题展开介绍。
01
—
数据导入
R语言变量编辑
使用x<-edit(x)命令可以像操作Excel表格一样可以修改x,fix(x)命令具有相同的效果
x<-c(1:10)y<-rep(c("a","b","c","d","e"),time=2)z<-seq(from=1,to=20,length=10)u<-c(rep(c(0),5),rep(c(1),5))tp<-data.frame(x,y,z,u)tpx y z u1 1 a 1.000000 02 2 b 3.111111 03 3 c 5.222222 04 4 d 7.333333 05 5 e 9.444444 06 6 a 11.555556 17 7 b 13.666667 18 8 c 15.777778 19 9 d 17.888889 110 10 e 20.000000 1tp<-edit(tp)tpx y z u1 1212 a 1.000000 02 2 b 3.111111 03 3 c 100.000000 04 4 d 7.333333 05 5 e 9.444444 06 6 a 11.555556 17 7 b 13.666667 18 8 c 15.777778 19 9 d 17.888889 110 10 e 20.000000 1
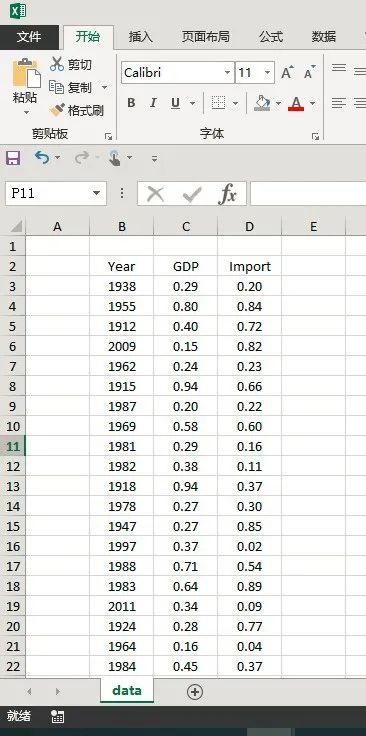
数据框是经常被使用的数据类型,确定一些名称有助于更清晰地使用数据框来描述问题。从统计学的角度来看,数据框的names属性(列名)可与随机变量对应,称为变量;每一行数据表示一个观测。比如下面这个数据框是某个国家年份、GDP和进口总额的虚拟数据,那么年份、GDP和进口总额可以看成随机变量,某一年的年份、GDP和进口总额的具体数值是变量的一个观测。
> tyear GDP Import1 1938 0.2915333 0.197032932 1955 0.7966871 0.838777353 1912 0.3986460 0.720027364 2009 0.1496753 0.819794995 1962 0.2403113 0.234739266 1915 0.9429419 0.664063477 1987 0.2029664 0.216788478 1969 0.5775884 0.599148999 1981 0.2875719 0.1600697310 1982 0.3809945 0.1137205911 1918 0.9387558 0.3700419612 1978 0.2744623 0.3008766813 1947 0.2658890 0.8451930514 1997 0.3698511 0.0171419415 1988 0.7091464 0.5371240416 1983 0.6364550 0.8894114817 2011 0.3433975 0.0930350718 1924 0.2795570 0.7673857419 1964 0.1630461 0.0449098320 1984 0.4498338 0.3731178021 1959 0.9201049 0.24790287
read.table()导入文本文档数据
read.table()函数是R语言导入文件最重要的方法之一,它有一个很长的参数表,可以实现各种自定义的文件导入方式。下面我们将要讨论的是最常用的一些参数的设置方法,若想了解更详尽的参数设置方法可查看帮助文档。
1)只有路径
对于如下TXT文档,使用read.table(“路径”)命令,可将整个TXT文档中的数据导入R语言的数据框变量中。生成的数据框的变量名是默认的v1、v2、v3,TXT文档中第一行数据Year、GDP和Import被认为是一个观测。
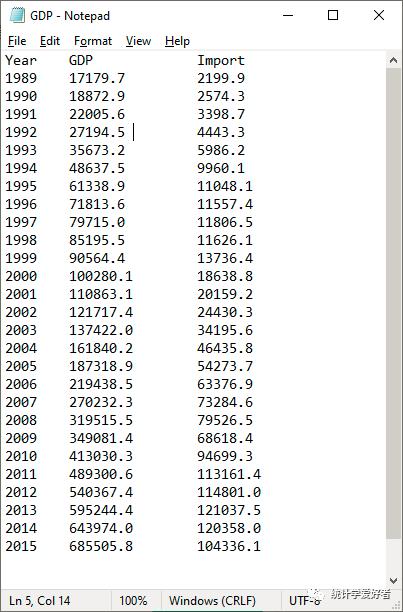
> t<-read.table("G:/Rcode/project1/GDP.txt")tV1 V2 V31 Year GDP Import2 1989 17179.7 2199.93 1990 18872.9 2574.34 1991 22005.6 3398.75 1992 27194.5 4443.36 1993 35673.2 5986.27 1994 48637.5 9960.18 1995 61338.9 11048.19 1996 71813.6 11557.410 1997 79715.0 11806.511 1998 85195.5 11626.112 1999 90564.4 13736.413 2000 100280.1 18638.814 2001 110863.1 20159.215 2002 121717.4 24430.316 2003 137422.0 34195.617 2004 161840.2 46435.818 2005 187318.9 54273.719 2006 219438.5 63376.920 2007 270232.3 73284.621 2008 319515.5 79526.522 2009 349081.4 68618.423 2010 413030.3 94699.324 2011 489300.6 113161.425 2012 540367.4 114801.026 2013 595244.4 121037.527 2014 643974.0 120358.028 2015 685505.8 104336.1class(t)"data.frame"
2)路径+header
设置header参数为TRUE值,将会把第一行看成变量而不是一个观测。
t<-read.table("G:/Rcode/project1/GDP.txt",header=TRUE)tYear GDP Import1 1989 17179.7 2199.92 1990 18872.9 2574.33 1991 22005.6 3398.74 1992 27194.5 4443.35 1993 35673.2 5986.26 1994 48637.5 9960.17 1995 61338.9 11048.18 1996 71813.6 11557.49 1997 79715.0 11806.510 1998 85195.5 11626.111 1999 90564.4 13736.412 2000 100280.1 18638.813 2001 110863.1 20159.214 2002 121717.4 24430.315 2003 137422.0 34195.616 2004 161840.2 46435.817 2005 187318.9 54273.718 2006 219438.5 63376.919 2007 270232.3 73284.620 2008 319515.5 79526.521 2009 349081.4 68618.422 2010 413030.3 94699.323 2011 489300.6 113161.424 2012 540367.4 114801.025 2013 595244.4 121037.526 2014 643974.0 120358.027 2015 685505.8 104336.1
3) 路径+header+skip
当TXT文档开头包含一些无用的信息的时候,设置skip参数可以跳过这些信息。参数skip=num,num表示希望跳过的行数。
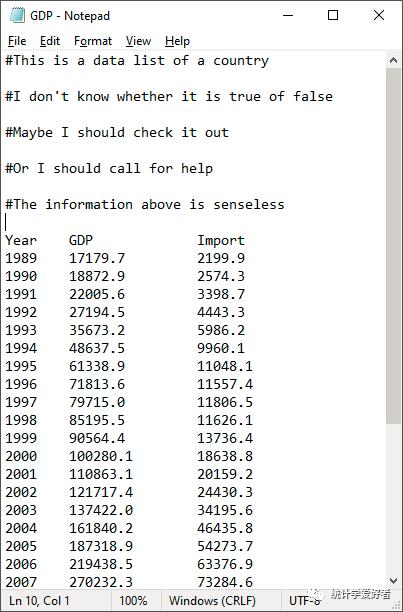
t<-read.table("G:/Rcode/project1/GDP.txt",header=TRUE,skip=10)tYear GDP Import1 1989 17179.7 2199.92 1990 18872.9 2574.33 1991 22005.6 3398.74 1992 27194.5 4443.35 1993 35673.2 5986.26 1994 48637.5 9960.17 1995 61338.9 11048.18 1996 71813.6 11557.49 1997 79715.0 11806.510 1998 85195.5 11626.111 1999 90564.4 13736.412 2000 100280.1 18638.813 2001 110863.1 20159.214 2002 121717.4 24430.315 2003 137422.0 34195.616 2004 161840.2 46435.817 2005 187318.9 54273.718 2006 219438.5 63376.919 2007 270232.3 73284.620 2008 319515.5 79526.521 2009 349081.4 68618.422 2010 413030.3 94699.323 2011 489300.6 113161.424 2012 540367.4 114801.025 2013 595244.4 121037.526 2014 643974.0 120358.027 2015 685505.8 104336.1
4) 路径+header+skip+nrows
设置nrows参数可以控制导入数据的行数,参数nrows=num表示要导入num行数据。
> t<-read.table("G:/Rcode/project1/GDP.txt",header=TRUE,skip=10,nrows=3)> tYear GDP Import1 1989 17179.7 2199.92 1990 18872.9 2574.33 1991 22005.6 3398.7
openxlsx包导入xlsx文档
首先使用install.packages("openxlsx")命令安装openxlsx包,然后使用library(openxlsx)命令导入这个包,接着就可以使用read.xlsx()命令来读取Excel文件数据了,返回值也是一个数据框类型。
同样地,read.xlsx()命令也有很长的参数表,下面是两个常用的情形。
1)只有路径
read.xlsx()自动识别第一行作为变量名,另外read.xlsx()还自动跳跃空行,也就是说即使数据从B2单元格开始也能得到同样的结果。
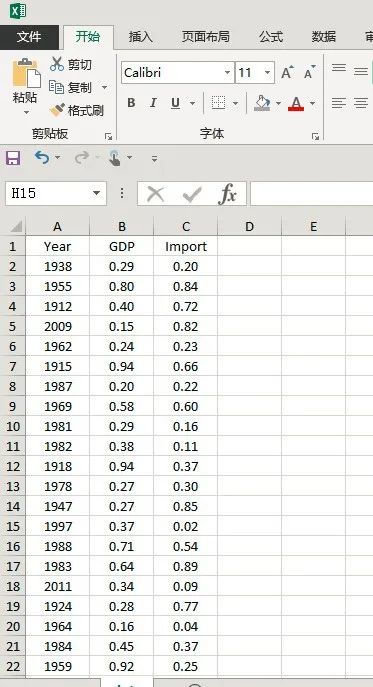
year GDP Import1 1938 0.2915333 0.197032932 1955 0.7966871 0.838777353 1912 0.3986460 0.720027364 2009 0.1496753 0.819794995 1962 0.2403113 0.234739266 1915 0.9429419 0.664063477 1987 0.2029664 0.216788478 1969 0.5775884 0.599148999 1981 0.2875719 0.1600697310 1982 0.3809945 0.1137205911 1918 0.9387558 0.3700419612 1978 0.2744623 0.3008766813 1947 0.2658890 0.8451930514 1997 0.3698511 0.0171419415 1988 0.7091464 0.5371240416 1983 0.6364550 0.8894114817 2011 0.3433975 0.0930350718 1924 0.2795570 0.7673857419 1964 0.1630461 0.0449098320 1984 0.4498338 0.3731178021 1959 0.9201049 0.24790287> class(dataf)[1] "data.frame"
2)路径+rows+cols
rows参数和cols参数是数字向量,可以控制导入哪些行和哪些列。
dataf<-read.xlsx("G:/Rcode/project1/data.xlsx",rows=c(2:4),cols=c(2:3))datafYear GDP1 1938 0.29153332 1955 0.7966871
02
—
数据导出
导出到屏幕
1)文本
①直接输入变量名,执行
datafYear GDP1 1938 0.29153332 1955 0.7966871
②print()函数
print(dataf)Year GDP1 1938 0.29153332 1955 0.7966871
2)图形
①覆盖原来的图形
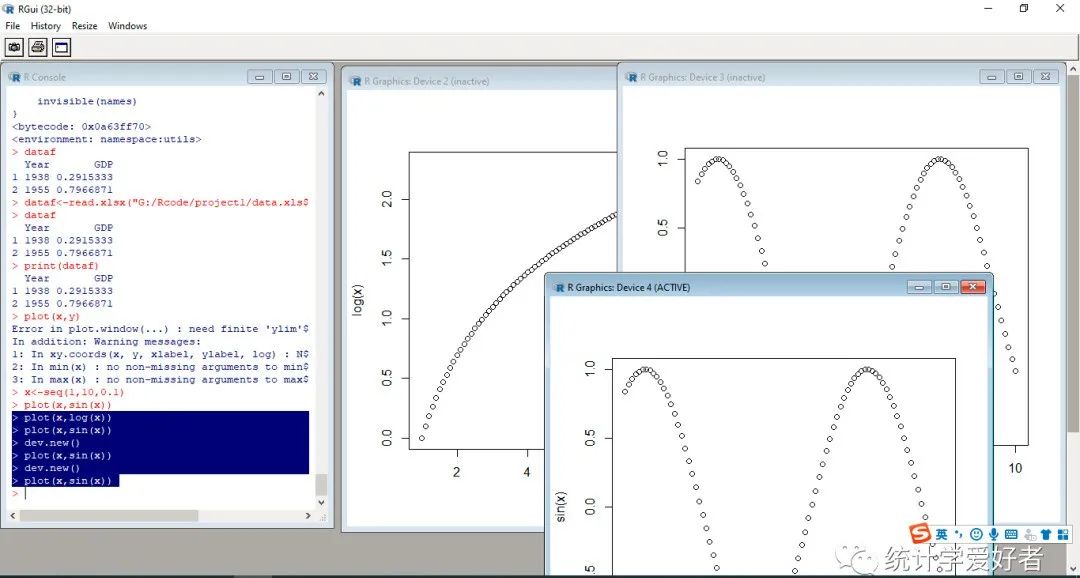
执行两次plot()绘图操作,第二次绘图将会覆盖原来的图形。Rgui中菜单栏的history命令提供查看绘图历史的功能,前提是要开启recording。
> x<-seq(1,10,0.1)> plot(x,sin(x))> plot(x,log(x))
②多个绘图窗口
如果希望每次绘图都新生成一个绘图窗口,而不改变原来的图形,可使用dev.new()命令。
plot(x,log(x))dev.new()plot(x,sin(x))dev.new()plot(x,sin(x))
导出文本到外部文档
1)文本
①写入TXT文档
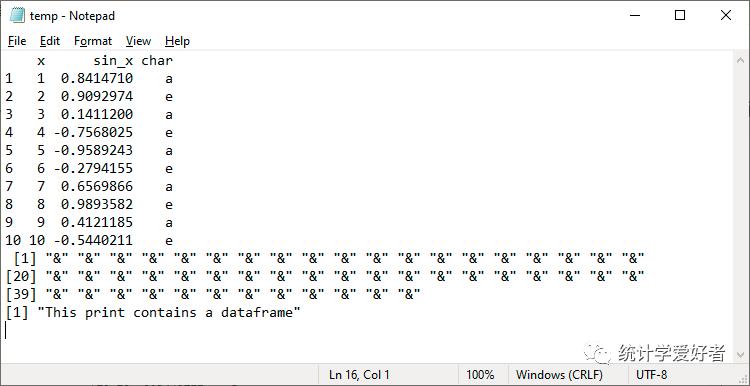
执行sink("TXT路径")命令,能够将原本打印到屏幕文本信息输出到指定的TXT文档,在这种状态下默认不再输出到屏幕上,执行sink()命令可以取消这种写入状态。
x<-c(1:10)y<-sin(x)z<-rep(c("a","e"),5)df<-data.frame(x=x,sin_x=y,char=z)dfx sin_x char1 1 0.8414710 a2 2 0.9092974 e3 3 0.1411200 a4 4 -0.7568025 e5 5 -0.9589243 a6 6 -0.2794155 e7 7 0.6569866 a8 8 0.9893582 e9 9 0.4121185 a10 10 -0.5440211 esink("G:/Rcode/temp.txt")dfprint(rep(c("&"),50))print("This print contains a dataframe")sink()dfx sin_x char1 1 0.8414710 a2 2 0.9092974 e3 3 0.1411200 a4 4 -0.7568025 e5 5 -0.9589243 a6 6 -0.2794155 e7 7 0.6569866 a8 8 0.9893582 e9 9 0.4121185 a10 10 -0.5440211 e
②将变量信息写入xlsx文档
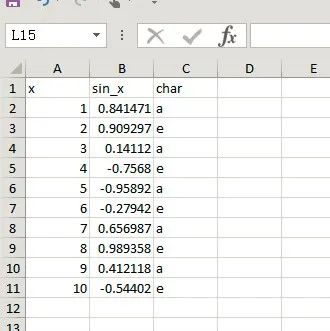
使用openxlsx中的write.xlsx()方法可以将变量输入xlsx文档中,最简单的参数设置方法是write.xlsx(x,“xlsx路径”),执行后可将x变量中的信息导出到指定的xlsx文档中。
dfx sin_x char1 1 0.8414710 a2 2 0.9092974 e3 3 0.1411200 a4 4 -0.7568025 e5 5 -0.9589243 a6 6 -0.2794155 e7 7 0.6569866 a8 8 0.9893582 e9 9 0.4121185 a10 10 -0.5440211 elibrary(openxlsx)write.xlsx(df,"G:/Rcode/temp.xlsx")
2)图形
①导出到pdf文档
pdf(“pdf路径”)命令可以将多个图片导出到指定的pdf文档中,若要停止导出状态,执行dev.off()命令即可。
x<-seq(1,10,0.1)pdf("G:/Rcode/temp.pdf")plot(x,sin(x))plot(x,exp(x))plot(x,log(x))dev.off()2
上述命令将生成一个pdf文档,每页包含一个图形。
②导出到图片
将图形导出到图片的方法可以是png("png路径")、tiff("tiff路径")、bmp("bmp路径")等类似的函数,使用dev.off()命令可中止导出。
png("G:/Rcode/temp.png")plot(x,sin(x))dev.off()null device1tiff("G:/Rcode/temp.tiff")plot(x,exp(x))dev.off()null device1bmp("G:/Rcode/temp.bmp")plot(x,x)dev.off()null device1
以上是关于R语言数据的导入输出及调整的主要内容,如果未能解决你的问题,请参考以下文章