ClickHouse 大数据量的迁移方式
Posted inthirties
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse 大数据量的迁移方式相关的知识,希望对你有一定的参考价值。
关于Clickhouse 备份方式,其官方网站上就提供了多种备份方式可以参考,不同的业务需求有不同的使用场景,需要使用不同的备份方式,不存在一个通用的解决方案可以应对各种情况下的ClickHouse备份和恢复。今天这个文字,我们介绍的是各种不同的Clickhouse的迁移方式,具体使用场景还需要根据要求进行选择。
一、 文本文件导入导出
数据库里的数据导出成特定的格式,再导入,这种方式很直接,也很简单容易理解,但是只能使用在数据量小的情况下,如果数据量一旦大,这种方式就是灾难。
导出:
clickhouse-client --password 12345678 --query="select * from inuser.t_record FORMAT CSV" > record.csv导入: 注意FORMAT后面大写
cat inuser.record.csv | clickhouse-client --port 9008 --password 12345678 --query="INSERT INTO inuser.record FORMAT CSV"二、 拷贝数据目录
冷数据恢复,直接拷贝走clickhouse 的数据到另一台机器上,修改下相关配置就可以直接启动了,仔细的观察一下 ClickHouse 在文件系统上的目录结构(配置文件
/ect/clickhouse-server/config.xml 里面配置的 <path>),为了便于查看,只保留了 data 和 metadata 目录。

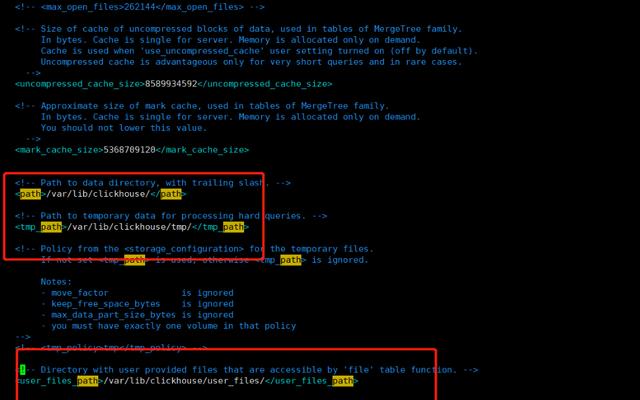

基于这个信息,直接把data和metadata目录(要排除 system 库)复制到新集群,即可实现数据迁移
步骤:
1、停止原先的clickhouse数据库,并打包好 对应数据库或表的 data 和 metadata 数据
2、拷贝到目标clickhouse数据库对应的目录,比如/var/lib/clickhouse 目录下
3、给clickhouse 赋予权限, chown -Rf clickhouse:clickhouse /var/lib/clickhouse/*
chown -Rf clickhouse:clickhouse /var/lib/clickhouse
4、重启目标clickhouse数据库
5、验证数据
select count(1) form inuser.t_record;三、 使用第三方工具,clickhouse-backup
clickhouse-backup 是社区开源的一个 ClickHouse 备份工具,可用于实现数据迁移。其原理是先创建一个备份,然后从备份导入数据,类似 mysql 的 mysqldump + SOURCE。这个工具可以作为常规的异地冷备方案
# 使用限制:
- 支持1.1.54390以上的ClickHouse
- 仅MergeTree系列表引擎
- 不支持备份Tiered storage或storage_policy
- 云存储上的最大备份大小为5TB
- AWS S3上的parts数最大为10,000
(1)、下载clickhouse-backup 软件包
官方提供了二进制版本和rpm包的方式
github地址: https://github.com/AlexAkulov/clickhouse-backup
下载地址: https://github.com/AlexAkulov/clickhouse-backup/releases/download/v1.0.0/clickhouse-backup.tar.gz

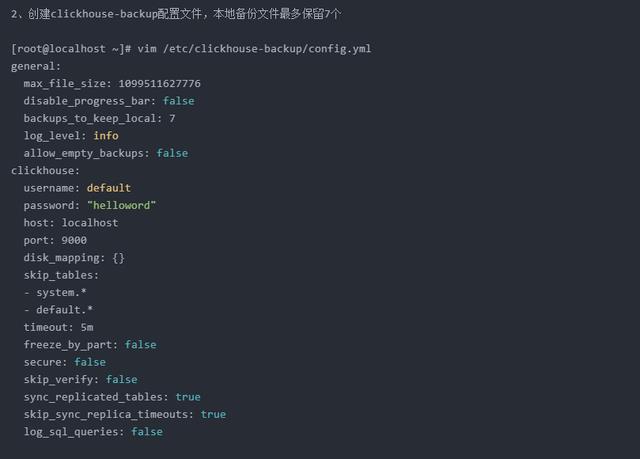
(2)、修改clickhouse-backup 配置文件config.yml
# 根据clickhouse自身的配置来修改 此配置文件,比如 clickhouse的数据目录,数据库密码,监控地址及端口
官方的配置说明:
clickhouse-backup 除了备份到本机,此外还支持远程备份的方式,备份到s3 上【对象存储】,ftp,sftp 上,还支持 使用 api 接口 访问


(3)、查看clickhouse-backup 相关命令
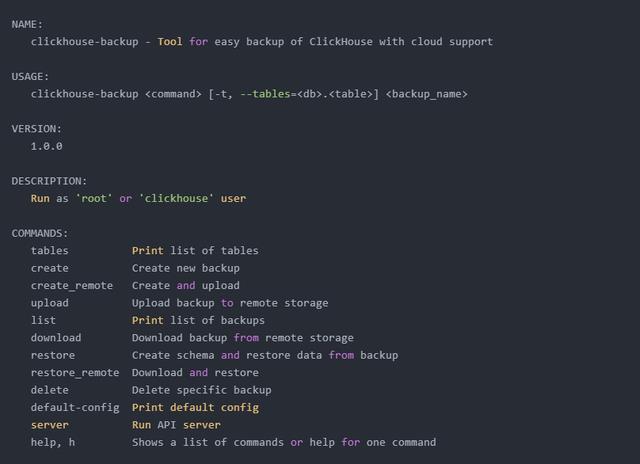
1、 查看全部默认的配置项
clickhouse-backup default-config2、 查看可备份的表【已在配置文件中过滤掉system和default 库下面的所有表】
[root@localhost clickhouse-backup]# clickhouse-backup tablesbrdatasets.hits_v1 1.50GiB default 3、 创建备份
#全库备份
clickhouse-backup create备份存储在中 $data_path/backup 下,备份名称默认为时间戳,可手动指定备份名称
clickhouse-backup create 备份包含两个目录:
- metadata目录: 包含重新创建所需的DDL SQL
- shadow目录: 包含作为ALTER TABLE ... FREEZE操作结果的数据
单表备份
clickhouse-backup create [-t, --tables=<db>.<table>] <backup_name>备份表datasets.hits_v1
clickhouse-backup create -t datasets.hits_v1备份多个表datasets.hits_v1, datasets.hits_v2
clickhouse-backup create -t datasets.hits_v1,datasets.hits_v24、查看备份记录
[root@localhost datasets]# clickhouse-backup list5、删除备份文件
[root@localhost datasets]# clickhouse-backup delete local 2021-09-06T14-03-23(4)、数据恢复
语法:
clickhouse-backup restore 备份名

四、使用clickhouse-backup备份与恢复数据
4.1 、本机备份与恢复


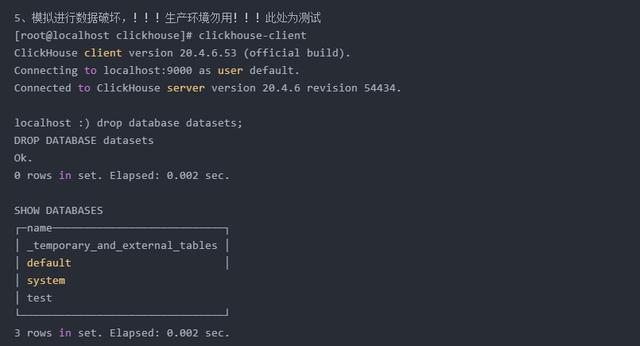

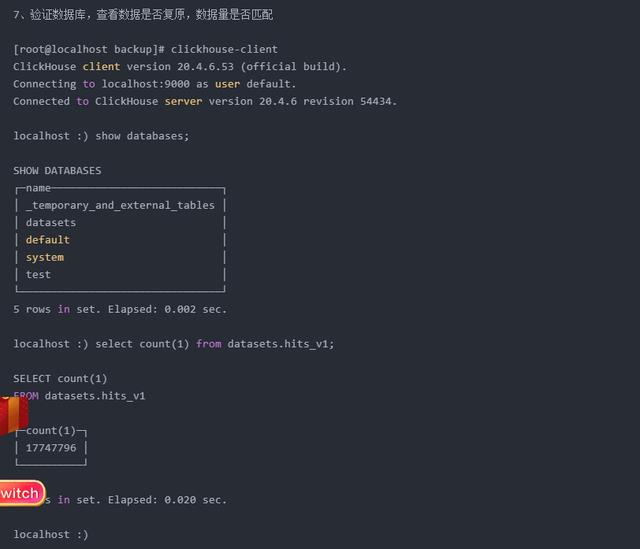
4.2、异机远程备份与恢复

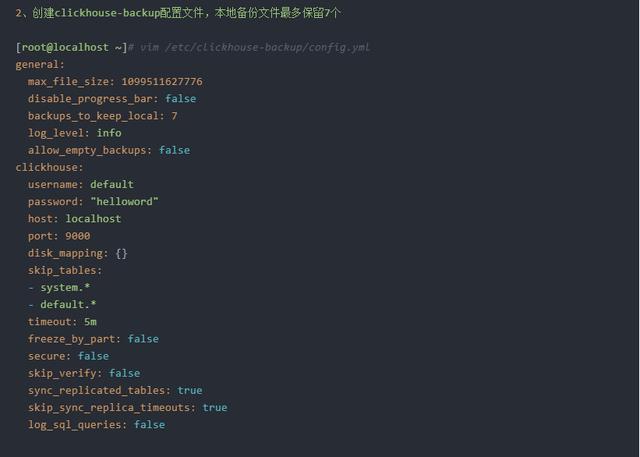

五、使用脚本定期异机远程备份

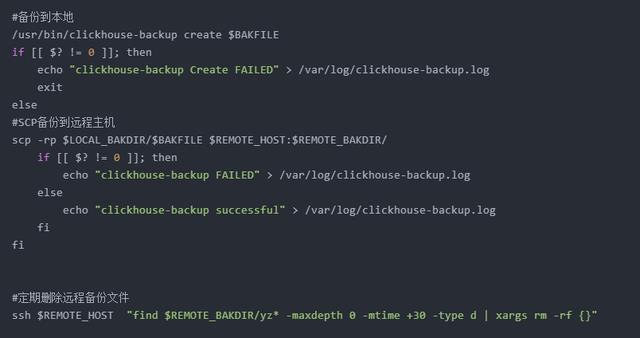
六、常见问题
1、问题现象:使用clickhouse-backup 恢复数据时,提示UUID 问题


服务器数据迁移需要多长时间
服务器数据迁移所需要的时间主要跟数据量的大小以及迁移方式有关系。一般的迁移方式有线下迁移和线上迁移两种方式。线下迁移就是拿着另外一个存储介质(移动硬盘等)将服务器数据拷贝后再上传至新服务器内,这种方式主速度的快慢主要受数据量大小的影响。在线上传就是远程将服务器数据拷贝出来,然后在线上传至另外一台服务器内。这种迁移方式速度受数据量大小以及服务器带宽大小影响。如果数据量很大,迁移速度肯定就会慢一些,反之,数据量小,数据迁移速度就会快一点。另外在线迁移如果带宽大,下载和上传数据的时间就短一些,如果服务器带宽小,下载和上传速度就会慢一些,迁移时间也就要长一些。 参考技术A 服务器的环境搭建这个过程,不同情况,复杂度不一致。有可能一两个小时。复杂的业务系统,为了稳妥,各项参数的调试环节用一周或者更长内也可以理解。
数据库和代码迁移速度很快,一两个小时就弄过去了。
图片、附件、视频、音频,如果站点内容比较多的话,拷贝速度很慢,几天到几周都有可能。还要结合新旧服务器的网络连通速度来和文件大小来评估大致的时间。
以上是关于ClickHouse 大数据量的迁移方式的主要内容,如果未能解决你的问题,请参考以下文章