高并发内存池
Posted 世_生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高并发内存池相关的知识,希望对你有一定的参考价值。
从零实现一个高并发内存池
高并发内存池整体框架设计
现在很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。malloc本身就已经很优秀了,那么我们的项目原型tcmalloc就是在多线程高并发的场景下更胜一筹,所以这次我们实现的内存池要考虑几个方面。
- 性能问题
- 在多线程下,锁竞争问题
- 内存碎片问题
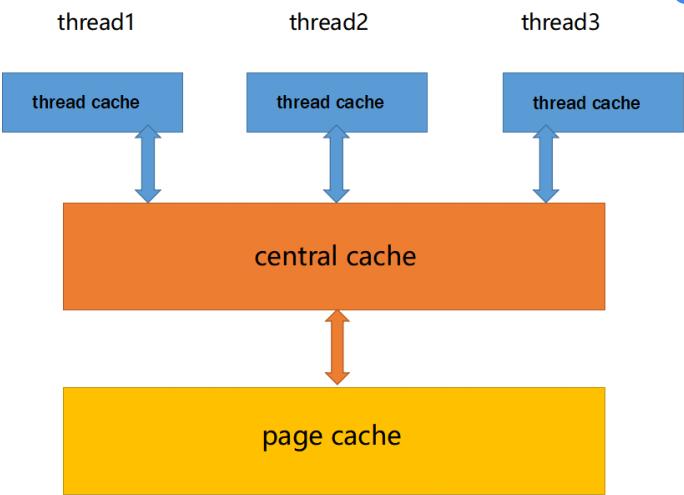
concurrent memory pool主要由下面3个部分组成:
- Thread Cahce:每个线程都要自己独立的线程缓存,用于小于256KB的内存分配在这里申请内存不需要加锁。
- Central Cache:程序中只要一个中心缓存,多个线程共享。thread cache是从这里按需获取对象。central cache具有回收机制,当一个线程中thread cache占用太多内存时,central cache会回收内存,避免其他线程对内存吃紧,达到了内存在分配多个线程时更均衡的按需调度的目的。central cache是多个线程共享的,所以需要锁竞争。但central cache是用的桶锁,所以竞争不是很激烈。
- Paga Cache:存储的内存是以页为单位存储及分配给central cache,当central cache没有对象是,就从paga cache按需拿一定数量的paga,并切割成固定大小的小内存块给central cache。pagan cache也有回收机制,paga cache会回收已经满足条件的central cache中的span对象,并且合并相邻的页,合成一个大页,缓解了内存碎片的问题。
申请内存部分
高并发内存池-Thread Cache
thread cache是哈希桶结构,每个桶的位置映射的是内存块对象的自由链表。每个线程都会有一个thread cache对象,在这个对象中获取和释放都是无锁的。
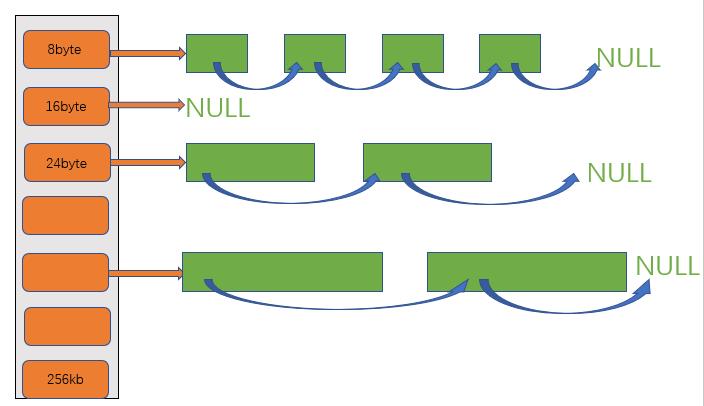
申请内存:
- 当内存申请size<=256KB,先获取到线程本地的thread cache对象,计算size映射的哈希桶自由链表的下标。
- 如果自由链表中有对象,则直接获取一个内存对象返回
- 如果自由链表在没有对象,则去central cache中获取一定数量的对象,插入到自由链表中
框架:
管理小对象的自由链表
static const NFREE_LIST=208;
static const MAX_SIZE=256*1024;
static const PAGE_SHIFT=13;
static const PAGA_LIST=129;
#ifdef _WIN64
typedef size_t PageID;
#elif _WIN32
typedef unsigned long long PageID;
#endif
inline static void* SystemAlloc(size_t kpage)
#ifdef _WIN32
void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
// linux下brk mmap等
#endif
if (ptr == nullptr)
throw std::bad_alloc();
return ptr;
class FreeList
public:
FreeList():_freelist(nullptr),_count(0),_size(1)
~FreeList()
//插入
void Push(void* obj)
assert(obj);
(*(void**))obj=_freelist;
_freelist=obj;
//每次还回来一个要++
_count++;
//插入一段内存块
void PushRange(void* start,void* end,size_t sum)
assert(start&&end);
*((void**)end)=_freelist;
_freelist=start;
_count+=sum;
//删除一段内存块
void PopRange(void*& start,void*& end,size_t sum)
start=_freelist;
end=start;
for(size_t i=0;i<sum-1;i++)
end=*(void**)end;
_freelist=*(void**)end;
*(void**)end=nullptr;
_count-=sum;
//删除
void* Pop()
assert(_freelist);
void*obj=_freelist;
_freelist=(*(void**))_freelist;
(*(void**))obj=nullptr;
//每次拿走都要--
_count--;
return obj;
//判空
bool Empty()
return _freelist==nullptr;
size_t Count()
return _count;
size_t& MaxSize()
return _size;
private:
void* _freelist;//指向自由链表的表头
size_t _count;//该自由链表中节点的数量
size_t _size;//用于慢增长(后面会讲)
;
对齐规则
我们最小都要用8字节对齐,因为我们要用链表把这些小内存块连接起来。当字节<=256KB时,就向thread cache申请。
如果我们都用8字节对齐,那么桶的个数就是32768个桶,太多了,没有必要。
所以、我们采用
整体控制在最多10%左右的内碎片浪费
[1,128] 8byte对齐 freelist[0,16) 16个桶
[128+1,1024] 16byte对齐 freelist[16,72) 56个桶
[1024+1,8*1024] 128byte对齐 freelist[72,128) 56个桶
[8*1024+1,64*1024] 1024byte对齐 freelist[128,184) 56个桶
[64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208) 24个桶
总共 208个桶
例如:当我们需要9字节的内存时,thread cache给我们16字节
当我们需要129字节的内存时,threadcache给我们144字节
造成的内碎片控制在10%左右,且内碎片可以被下次申请时利用。
class SizeClass
public:
普通人写法
static inline size_t _RoundUp(size_t size,size_t alignNum)
size_t align;
if(size%alignNum!=0)
align=(size/alignNum+1)*alignNum;
return align;
else
align=size;
return align;
大佬写法
static inline size_t _RoundUp(size_t size, size_t alignNum)
return ((size+ alignNum - 1) & ~(alignNum - 1));
多次调用的函数使用静态,该函数使用内联
static inline size_t RoundUp(size_t size)
if(size<=128)
return _RoundUp(size,8);
else if(size>128 && size<=1024)
return _RoundUp(size,16);
else if(size>1024 && size<=8*1024)
return _RoundUp(size,128);
else if(size>8*1024 && size<=64*1024)
return _RoundUp(size,1024);
else if(size>64*1024 && size<=256*1024)
return _RoundUp(size,8*1024);
//大于256KB,也按8*1024对齐
else if(size>256*1024)
return _RoundUp(size,8*1024);
else
assert(false);
return -1;
普通人写法
static inline size_t _Index(size_t size,size_t alignNum)
if(size % alignNum==0)
return size/alignNum-1;
else
return size/alignNum;
大佬写法
static inline size_t _Index(size_t size, size_t alignNum)
return ((size + (1 << alignNum) - 1) >> alignNum) - 1;
映射的桶号
static inline size_t Index(size_t size)
assert(size<=MAX_SIZE);
static int group_array[4]=16,56,56,56;
if (size <= 128)
return _Index(size, 3);
else if (size <= 1024)
return _Index(size - 128, 4) + group_array[0];
else if (size <= 8 * 1024)
return _Index(size - 1024, 7) + group_array[1] + group_array[0];
else if (size <= 64 * 1024)
return _Index(size - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];
else if (size <= 256 * 1024)
return _Index(size - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];
else
assert(false);
return -1;
static size_t NumMoveSize(size_t size)
assert(size > 0);
// [2, 512],一次批量移动多少个对象的(慢启动)上限值
// 小对象一次批量上限高
// 小对象一次批量上限低
int num = MAX_BYTES / size;
if (num < 2)
num = 2;
if (num > 512)
num = 512;
return num;
//计算要申请的页的多少
static size_t NumMovePaga(size_t size)
size_t num = NumMoveSize(size);
size_t npage = num*size;
npage >>= PAGE_SHIFT;
if (npage == 0)
npage = 1;
return npage;
;
class ThreadCache
public:
//申请
void* Allocate(size_t size);
//thread cache中不够去central cache中去申请
void* FetchFromCentralCache(size_t index, size_t alignsize);
private:
FreeList freelist[NFREE_LIST];
;
每个线程获取自己独立的Thead Cache
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
Allocate:
void* Allocate(size_t size)
assert(size<=MAX_SIZE);
//计算对齐数,和桶号
size_t alignsize=RoundUp(size);
size_t index=Index(size);
if(freelist[index].Empty())
void* obj;
obj=freelist[index].Pop();
return obj;
else
return FetchFromCentralCache(index,alignsize);
FetchFromCentralCache:
在central cache中获取内存块
在这里我们使用慢增长的方式,每一次去central cache中获取内存时,size++。
好处:当我们大量使用这个桶中的内存时,我们不是每次都在central cache中获取1个,而是每次+1,这样就减少了去central cache中的次数,最大限度是512
FetchFromCentralCache(size_t index,size_t alignsize)
assert(index<NFREE_LIST);
size_t batchsum = min(freelist[index].MaxSize(),SizeClass::NumMoveSize(size));
if(batchsum==freelist[index].MaxSize())
freelist[index].MaxSize()+=1:
//输出型参数
void* start=nullptr;
void* end=nullptr;
//从central cache中获取
size_t sum=GetNumCache(start,end,batchsum,alignsize);
assert(sum>0);
if(sum==1)
assert(start==end);
return start;
else
//拿到了sum块大小为alignsize的内存块,连接起来,我们只需要一块
freelist[index].PushRange(*(void**)start, end,sum-1);
return start;
高并发内存池-Central Cache
central cache也是哈希桶的结构,和thread cache的映射关系一样,都是208个桶。不同的是central cache的每个哈希桶的位置都是SpanList链表结构,每个映射桶下面的Span中的大块内存都被切分成了小块内存通过自由链表连接起来。
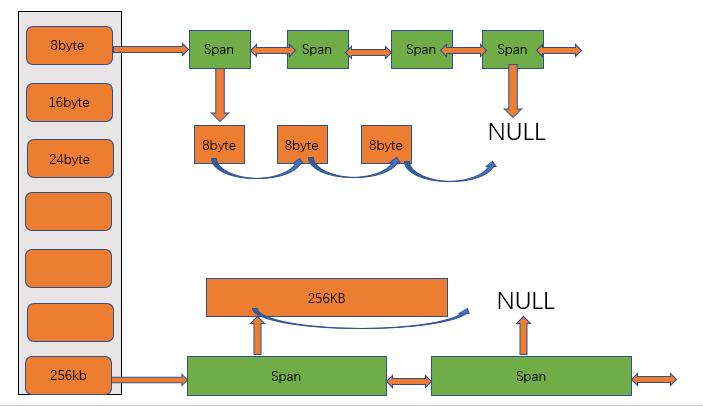
框架:
描述Span
class Span
Span* next=nullptr;
Span* prev=nullptr;
//页号
size_t spanId=0;
//页的数量
size_t pagaSum=0;
void* _freelist=nullptr;
//对象使用页块的个数
size_t _usecount=0;
//该Span的状态
bool state=false;
//对象的大小
size_t objSize=0;
;
class SpanList
public:
SpanList()
_head=new Span();
_head->next=_head;
_head->prev=_head;
Span* Begin()
return _head->next;
Span* End()
return _head;
bool Empty()
return _head->nex==_heaed;
void Insert(Span* pos,Span* obj)
assert(obj&&pos);
Span* cur = pos->prev;
cur->next = obj;
pos->prev = obj;
void Etase(Span* obj)
assert(obj);
assert(obj != _head);
Span* cur = obj->prev;
Span* pos = obj->next;
cur->next = pos;
pos->prev = cur;
void PushFront(Span* obj)
Insert(Begin(),obj);
void* PopFront()
Span* front=_head->next;
assert(front!=_head);
Etase(front);
return front;
private:
Span* _head;
public:
std::mutex mtx;//桶锁
;
多个线程共享,则只能有一个对象,采用单例模式-饿汉模式
class CentralCache
public:
static CentralCache* GetObjCen()
return &_Inst;
//获取一个非空的Span
Span* GetOneSpan(SpanList& list,size_t size);
//从central中获取一段数量的内存
size_t GetNumCache(void*&start,void*&end,size_t batchsum,size_t size);
private:
CentralCache();
CentralCache(const CentralCache& c)=delete;
public:
SpanList _spanlist[NFREE_LIST];
private:
static CentralCache _Inst;
;
初始化
CentralCache CentralCache::_inst;
GetNumCache:
size_t GetNumCache(void*以上是关于高并发内存池的主要内容,如果未能解决你的问题,请参考以下文章