抓取网页时html元素找不到
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了抓取网页时html元素找不到相关的知识,希望对你有一定的参考价值。
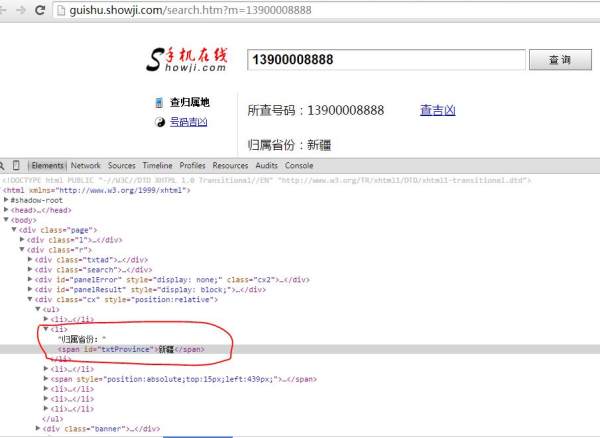
我想抓取网页中的信息。查询号码归属地的一个页面如下所示:
http://guishu.showji.com/search.htm?m=13900008888
我在Chrome中查看该网页的源代码,却看到对应“归属省份:新疆”的地方为:
<li>归属省份:<span id="txtProvince"></span></li>
那么我该如何抓取“新疆”这个信息呢?为什么它没有直接显示在html文件中呢?
非常感谢!
亲,这个标签里面的省份是动态获取的,也就是不是固定的,你查看源代码的方式只能看到网页原来的样子,而没有看到网页动态加载后的样子,你要右键点击省份那里选择审查元素就看见动态加载的内容,直接获取消息还是用
document.getElementById("txtProvince"),但是要等到页面加载完后才能获取到
要抓取的地址应该是这个
$str = 'http://v.showji.com/locating/showji.com.aspx?m=13900008888&output=json&callback=querycallback×tamp=1413972643837';//号码后面的参数要不要都能行,数据格式不同而已本回答被提问者采纳 参考技术B 要抓取的地址应该是这个
1
2
$str = 'http://v.showji.com/locating/showji.com.aspx?m=13900008888&output=json&callback=querycallback×tamp=1413972643837';
//号码后面的参数要不要都能行,数据格式不同而已 参考技术C 那些信息估计是通过js异步加载进来的,因此你看源码是看不到的。你可以分析一下请求和返回的数据来获取
BeautifulSoup 和 lxml 找不到 div 元素
【中文标题】BeautifulSoup 和 lxml 找不到 div 元素【英文标题】:BeautifulSoup and lxml cannot find div element 【发布时间】:2018-03-03 01:11:03 【问题描述】:刚开始用 python 抓取网页,我遇到了一些问题。
我开始使用 Selenium 下载网页的源代码并保存:
from selenium import webdriver
driver= webdriver.Firefox()
driver.get("https://www.website.com")
f=open('output.txt','w')
f.write(driver.page_source.encode('utf-8'))
f.close()
driver.quit()
一切正常,但是 Selenium 太费时间了,所以我首先转向机械化,以获取页面源:
import mechanize
browser = mechanize.Browser()
browser.set_handle_robots(False)
cookies = mechanize.CookieJar()
browser.set_cookiejar(cookies)
browser.addheaders = [('User-agent', 'Mozilla/5.0')]
browser.set_handle_refresh(False)
browser.open("https://www.website.com")
问题来了:如果我尝试通过它的 id 查找特定的 div,它不会返回任何内容:
from bs4 import BeautifulSoup as BS
soup= BS(browser.response().read(),'lxml')
print(soup.find(id="div_id"))
虽然如果我使用常规文本编辑器检查使用 mechanize 获得的源代码,我可以找到它。是这样的:
<div id="div_id" data referrer="div_id">
这个 div 有许多其他子元素,它位于代码的 1/5 左右,完整的源代码大约 500kb。如果我尝试寻找附近的其他 div,也没有运气。然而,如果我在源代码开头附近寻找一些 div,它会找到它。更有趣的是,如果我尝试在使用 Selenium 获得的源代码中寻找相同的 div(使用 BS),而不是获得的那个使用 Mechanize,它能够找到它,尽管使用文本编辑器检查 div 看起来完全一样。
我尝试了所有支持 BS 的解析器,但没有成功。所以我认为这可能与BS有关,我尝试对lxml做同样的事情:
from lxml import etree
parser= etree.HTMLParser()
tree= etree.parse(open('source.txt'),parser)
results= tree.xpath('//div[@id="div_id"]')
print(etree.tostring(results[0]))
与 BS 一样,它能够在使用 Selenium 获得的源代码中找到 div,但无法使用 Mechanize。所以我觉得可能跟 Mechanize 有关系,转而使用 Requests:
import requests
from fake_useragent import UserAgent
ua=UserAgent()
url= 'https://www.website.com'
headers= 'User-agent': str(ua.chrome)
page = requests.get(url, headers=headers)
当使用 BS 或 lxml 查看 div 的 page.content 时,再次失败。无论我是直接分析响应还是将其保存到文件中然后分析文件,都会发生这种情况。
我认为就是这样......我还尝试对 Mechanize 和 Requests 响应进行编码,因为我看到我已经使用 Selenium 完成了它,但没有任何变化。我也试过用其他BS版本(3.x),没有变化。
总结一下: - 如果我在通过 Selenium 获得的源代码中查找带有 BS 或 lxml 的 div,它会找到它。与其他的,没有。 - 如果我在源代码开头寻找其他div,BS和lxml找到它,与用于获取代码的方法无关。 - 经检查,div 在任何情况下都存在。
使用的版本: -蟒蛇:2.7.9 -BeautifulSoup:4.6.0 -机械化:0.3.5 -请求:2.18.4 -硒:3.5.0 -lxml:4.0.0 -操作系统:linux debian
谢谢。
【问题讨论】:
如果你给我们实际的 URL 会有所帮助。 url: facebook.com/groups/1584160618524185 div id: pagelet_forsale_island 谢谢 【参考方案1】:您要查找的 div 隐藏在可能通过 Javascript 处理的 HTML 注释中。您仍然可以使用requests 首先提取隐藏的 HTML,如下所示:
from bs4 import BeautifulSoup, Comment
import requests
id = "pagelet_forsale_island"
r = requests.get("https://www.facebook.com/groups/1584160618524185/")
soup = BeautifulSoup(r.content, "html.parser")
for comment in soup.find_all(string=lambda text:isinstance(text, Comment)):
if id in comment:
hidden_soup = BeautifulSoup(comment, "html.parser")
for div in hidden_soup.find_all('div', id=id):
print div
这会让 BeautifulSoup 找到 HTML 中的所有评论,然后确定其中是否包含您的 id。如果找到匹配项,则注释本身会再次传递给 BeautifulSoup 进行进一步处理。这会将您的<div> 显示为:
<div data-referrer="pagelet_forsale_island" id="pagelet_forsale_island"></div>
【讨论】:
就是这样!你介意解释一下“for comment in soup.find_all(string=lambda text:isinstance(text, Comment)):”是如何工作的吗?我不太确定。你认为 BS 最适合这项任务,还是其他工具更适合我?谢谢!comments 只是特殊类型的文本。这是一个让它返回文档中找到的所有评论的技巧。还有其他工具,不过我倾向于使用 BS。以上是关于抓取网页时html元素找不到的主要内容,如果未能解决你的问题,请参考以下文章