什么是hashMap,初始长度,高并发死锁,java8 hashMap做的性能提升
Posted jiguojing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是hashMap,初始长度,高并发死锁,java8 hashMap做的性能提升相关的知识,希望对你有一定的参考价值。
众所周知,HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry。这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。
HashMap数组每一个元素的初始值都是Null。

对于HashMap,我们最常使用的是两个方法:Get 和 Put。
1.put方法的原理
比如调用 hashMap.put("apple", 0) ,插入一个Key为“apple"的元素。这时候我们需要利用一个哈希函数来确定Entry的插入位置(index): length表示 初始化时候,HashMap的容量
hash = Hash(“apple”)
index = hash & (length - 1)
假定最后计算出的index是2,那么结果如下:

但是,因为HashMap的长度是有限的,当插入的Entry越来越多时,再完美的Hash 函数也难免会出现index冲突的情况,比如:
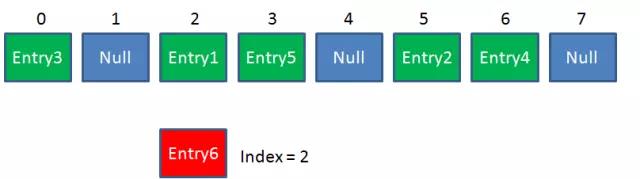
这个时候该怎么办呢,我们可以利用链表来解决。
HashMap数组的每一个元素不止是一个Entry对象,也是一个链表的头节点。每一个Entry对象通过Next指针指向它的下一个Entry节点。当新来的Entry映射到冲突的数组位置时,只需要插入到对应的链表即可:

需要注意的是,新来的Entry节点插入链表时,使用的是“头插法”。至于为什么不插入链表尾部,是因为HashMap的发明者认为,后插入的Entry被查找的可能性更大。且插入到最后的话,那时间复杂度也会上升。
2.get方法的原理
首先会把输入的Key做一次Hash映射,得到对应的index:
hash = Hash("apple")
index = hash & (length-1)
由于刚才所说的Hash冲突,同一个位置有可能匹配到多个Entry,这时候就需要顺着对应链表的头节点,一个一个向下来查找。假设我们要查找的Key是“apple”:
第一步,我们查看的是头节点Entry6,Entry6的Key是banana,显然不是我们要找的结果。
第二步,我们查看的是Next节点Entry1,Entry1的Key是apple,正是我们要找的结果。
问题:
问题1:HashMap的初始长度,为什么?HashMap的最大容量?
问题2:高并发下 HashMap 可能会出现死锁?
问题3:java8中,HashMap的结构有什么样的优化?
解答:
问题1:HashM安排的初始长度,为什么?
初始长度是 16,每次扩展或者是手动初始化,长度必须是 2的幂。
因为: index = HashCode(Key) & (length - 1), 如果 length是 2的 幂的话,则 length - 1就是 全是 1的二进制数,比如 16 - 1 = 1111,这样相当于是 坐落在长度为 length的hashMap上的位置只和 HashCode的后四位有关,这只要给出的HashCode算法本身分布均匀,算出的index就是分布均匀的。
因为HashMap的key是int类型,所以最大值是2^31次方,但是查看源码,当到达 2^30次方,即
MAXIMUM_CAPACITY,之后,便不再进行扩容。
问题2:高并发情况下,为什么HashMap出现死锁?
我们看到默认HashMap的初始长度是16,比较小,每一次push的时候,都会检查当前容量是否超过 预定的 threshold,如果超过,扩大HashMap容量一倍,整个表里的所有元素都需要按照新的hash算法被算一遍,这个代价较大。提到死锁,对于HashMap来说,貌似只能和链表操作有关。
正常ReHash过程,可以看到,每个元素重新算hash值,将链表翻转(目的遍历每个bucket上的链表还是用的是头插法,时间复杂度最低),放到对应的bucket上的链表中
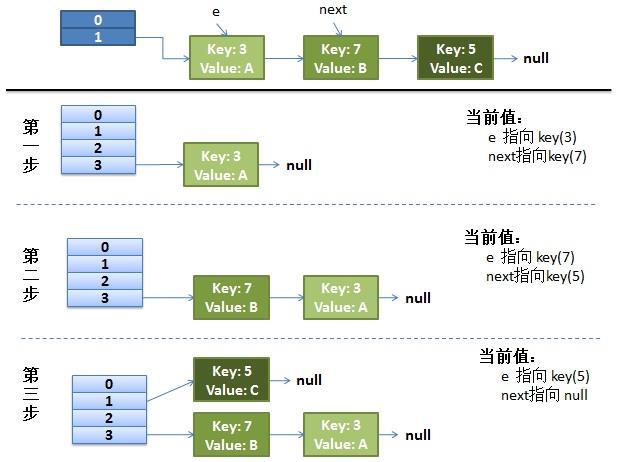
并发时候的reHash过程
while(null != e) { Entry<K,V> next = e.next; //线程1还没有执行这句 中断了 if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; }
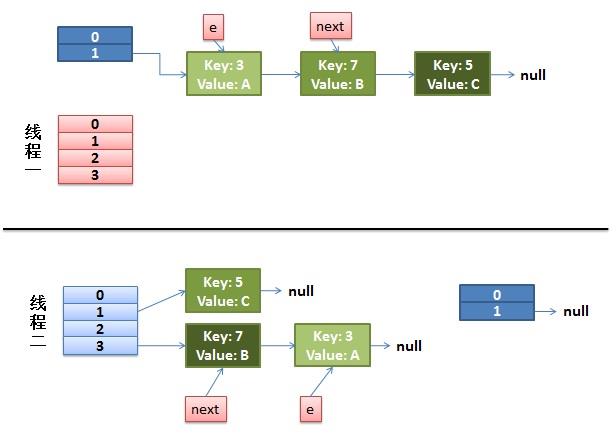
过程:
(1)线程1,先被中断,线程2执行reHash过程
(2)线程2将原表 bucket 1 处的链表分发到 新表 bucket 1 和 bucket 3 上(hash值的后2位,第一位不同,则不是01就是11),分散到 bucket 3上的值有两个, key(3), key(7),遍历原表Bucket 1 上的 链表,采用头插法,结果就是 链表反转且还属于新表此bucket的元素放到 此bucket上。此时 key(7) -> key(3) -> null
(3)此时线程 2 被中断,线程 1调度。 此时线程 1 中 e 是 key(3)-> null
执行 next = e.next , 得到 next = null
e.next = newTable[i], e.next = key(7)->key(3)->null,所以 e是 key(3)->key(7)->key(3)
newTable[i] = e; 此时newTable[i] 就是一个 循环链表。
e = next, e是null,跳出循环
这样等到get方法到对应的链表上取数据时,就会发生 死循环。
问题3:java8对hashMap做了什么优化?
简单说: java7中 hashMap每个桶中放置的是链表,这样当hash碰撞严重时,会导致个别位置链表长度过长,从而影响性能。
java8中,HashMap 每个桶中当链表长度超过8之后,会将链表转换成红黑树,从而提升增删改查的速度。
以上是关于什么是hashMap,初始长度,高并发死锁,java8 hashMap做的性能提升的主要内容,如果未能解决你的问题,请参考以下文章