前言:
hashmap是一种很常用的数据结构,其使用方便快捷,接下来笔者将给大家深入解析这个数据结构,让大家能在用的时候知其然,也知其所以然。
一.Map
首先,从最基本的讲起,我们先来认识一下map是个什么东西。在我们写程序的时候经常会遇到数据检索等操作,对于几百个数据的小程序而言,数据的存储方式或是检索策略没有太大影响,但对于大数据,效率就会差很远。我们来讨论一下这个问题。
1.线性检索:
线性检索是最为直白的方法,把所有数据都遍历一遍,然后找到你所需要的数据。其对应的数据结构就是数组,链表等线性结构,这种方式对于大数据而言效率极低,其时间复杂度为O(n)。
2.二分搜索:
二分搜索算是对线性搜索的一个改进,比如说对于【1,2,3,4,5,6,7,8】,我要搜索一个数(假设是2),我先将这个数与4(这个数一般选中位数比较好)比较,小于4则在4的左边【1,2,3】中查找,再与2比较,相等,就成功找到了,这种检索方式好处在于可以省去很多不必要的检索,每次只用查找集合中一半的元素。其时间复杂度为O(logn)。但其也有限制,他的数排列本身就需要是有序的。
3.Hash表中的查找:
好了,重点来了,Hash表闪亮登场,这是一种时间复杂度为O(1)的检索,就是说不管你数据有多少只需要查一次就可以找到目标数据。是不是很神奇??好吧其实很弱智。大家请看下图。

大家可以看到这个数组中的值就等于其下标,比如说我要存11,我就把它存在a[11]里面,这样我要找某个数字的时候就直接对应其下标就可以了。这其实是一种牺牲空间换时间的方法,这样会对内存占用比较大,但检索速度极快,只需要搜索一次就能查到目标数据。
4.Hash表的改变
看了上面的Hash表你肯定想问,如果我只存一个数10000,那我不是要存在a[10000],这样其他空间不是白白浪废了吗,好吧,不存在的。Hash表已经有了其应对方法,那就是Hash函数。Hash表的本质在于可以通过value本身的特征定位到查找集合的元素下标,从而快速查找。一般的Hash函数为:要存入的数 mod(求余) Hash数组长度。比如说对于上面那个长度为9的数组,12的位置为12 mod 9=3,即存在a3,通过这种方式就可以安放比较大的数据了。
5.Hash冲突解决策略
看了上面的讲解,机智的你们肯定已经发现了一个问题,通过求余数得到的地址可能是一样的。这种我们称为Hash冲突,如果数据量比较大而Hash桶比较小,这种冲突就很严重。我们采取如下方式解决冲突问题。
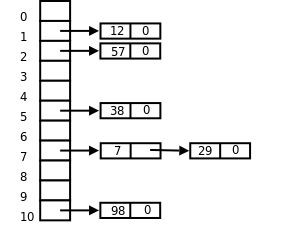
我们可以看到12和0的位置冲突了,然后我们把该数组的每一个元素变成了一个链表头,冲突的元素放在了链表中,这样在找到对应的链表头之后会顺着链表找下去,至于为什么采用链表,是为了节省空间,链表在内存中并不是连续存储,所以我们可以更充分地使用内存。
Java之HashMap
上面讲了那么多,那跟我们今天的主题HashMap有什么关系呢??好了盆友们不要方,进入正题。我们知道HashMap中的值都是key,value对吧,其实这里的存储与上面的很像,key会被映射成数据所在的地址,而value就在以这个地址为头的链表中,这种数据结构在获取的时候就很快。但这里存在的问题就是如果hash桶较小,数据量较大,就会导致链表非常的长。比如说上面的长为11的空间我要放1000个数,无论Hash函数如何精妙,后面跟的链表都会非常的长,这样Hash表的优势就不复存在了,反而倾向于线性检索。好了,红黑树闪亮登场。
红黑树
在jdk1.8版本后,java对HashMap做了改进,在链表长度大于8的时候,将后面的数据存在红黑树中,以加快检索速度,我们接下来讲一下红黑树。
avl树
要了解红黑树,先要知道avl树,要知道avl树,首先要知道二叉树,其实很简单,二叉树就是每个父节点下面有零个一个或两个子节点,大致如下图。
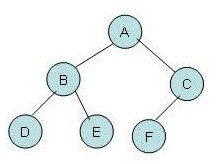
我们在向二叉树中存放数据的时候将比父节点大的数放在右节点,将比父节点小的数放在左节点,这样之后我们在查找某个数的时候只需要将其与父节点比较,大则进入右边并递归调用,小则进入左边递归。但其存在不足,如果运气很不好我的数据本身就是有序的,比如【1,2,3,4,5,6,7】,这样就会导致树的不平衡,二叉树就会退化成为链表。所以我们推出了avl树。
avl树即平衡树,他对二叉树做了改进,在我们每插入一个节点的时候,必须保证每个节点对应的左子树和右子树的树高度差不超过1。如果超过了就对其进行调平衡,具体的调平衡操作就不在这里讲了,无非就是四个操作——左旋,左旋再右旋,右旋再左旋。最终可以是二叉树左右两边的树高相近,这样我们在查找的时候就可以按照二分查找来检索,也不会出现退化成链表的情况。
二三树
网上有很多讲解红黑树的文章,有各种各样的讲解方式,但博主喜欢把红黑树与二三树放在一起。先来看一下什么是二三树。
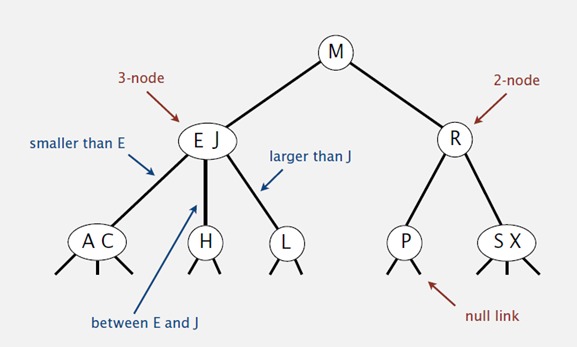
注:该图来自百度
其实很好理解,二三树与普通二叉树的不同点在于他有二节点和三节点。二节点下面有两个子节点,二节点里面可以容纳一个值,而三节点下面有三个子节点,三节点里面可以容纳两个值。下面来说一下二三数的构建。
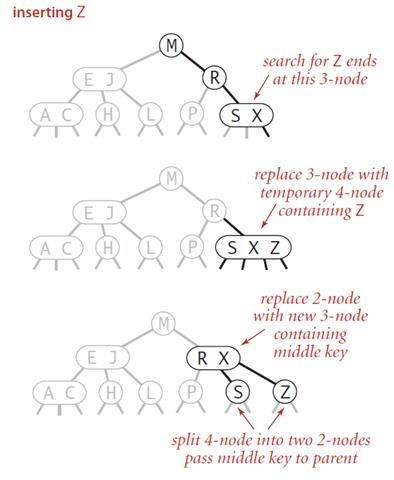
注:图片依然来自百度,博主画图比较垃圾。
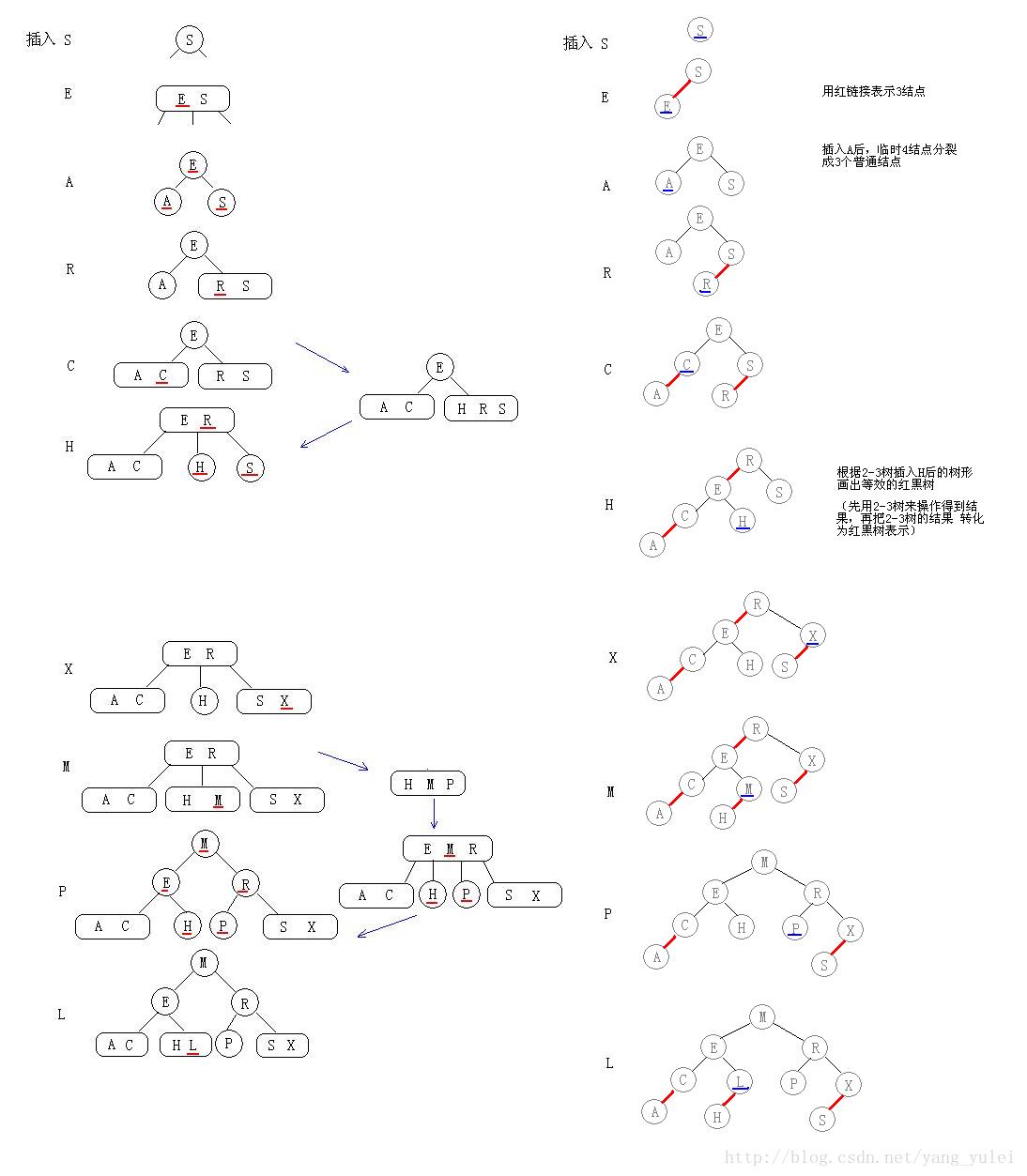
其实二三树的构建很简单,如图所示,图中M结点就是一个二节点,M左边的EJ节点是一个三节点。依然是大的数据放右边,小的数据放左边。此时我们向该树重如果该数可以直接放入二节点中,就直接进去,但如果正好需要放在三节点中,就像图中一样,Z正好要放在SX中。那么我们需要将该节点分裂成两个节点,并将中间的数提到父节点中去,就像图中将X放在了R旁边。当然如果将子节点提到父节点的时候导致了父节点里的数超过了两个,就继续向上提,直到满足了为止。
红黑树
红黑树和二三树很相像,基本上就是二三树的一个变形。
红黑树比较传统的定义是需要满足以下五个特征:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
其特点在于给数的每一个节点加上了颜色属性,在插入的过程中通过颜色变换和节点旋转调平衡。其实博主不是很喜欢上面的定义,还有一种视角就是将它与二三树比较。
当然上面这张图也是搜来的。
红黑树还可以描述成:
⑴红链接均为左链接。
⑵没有任何一个结点同时和两条红链接相连。
⑶该树是完美黑色平衡的,即任意空链接到根结点的路径上的黑链接数量相同。
这里节点之间的连接分为红连接和黑连接,取代了红节点和黑节点的定义(本质是一样的),将之前的黑高度相等定义为了黑连接数相等。更为直观。
而如图所示,其实红黑树的每一步操作都对应了二三树的操作,如果是二节点就是黑连接,三节点的话里面的两个数之间就是红连接。
红黑树的优势
红黑树相比avl树,在检索的时候效率其实差不多,都是通过平衡来二分查找。但对于插入删除等操作效率提高很多。红黑树不像avl树一样追求绝对的平衡,他允许局部很少的不完全平衡,这样对于效率影响不大,但省去了很多没有必要的调平衡操作,avl树调平衡有时候代价较大,所以效率不如红黑树,在现在很多地方都是底层都是红黑树的天下啦~
总结
HashMap在里面就是链表加上红黑树的一种结构,这样利用了链表对内存的使用率以及红黑树的高效检索,是一种很happy的数据结构。
文末小福利
笔者以前用C++手写过avl树的实现,大二数据结构课程设计有点迷的朋友可以参考。