Unity优化之Drawcall
Posted 老白游戏开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Unity优化之Drawcall相关的知识,希望对你有一定的参考价值。
一、什么是Drawcalls
在Unity中,每次CPU准备数据并通知GPU的过程就称之为一个DrawCall。这个过程会指定一个Mesh被渲染,绘制材质。
二、Drawcalls有什么影响
为了CPU和GPU可以进行并行工作,需要一个命令缓冲区,由CPU向其中添加命令,然后由GPU从中读取命令,这样就实现了通过CPU准备数据,通知GPU进行渲染。在每次调用DrawCall之前,CPU需要向GPU发送很多内容,主要是包括数据,渲染状态,命令等。所以如果DrawCall数量过多就会导致CPU进行大量计算,进而导致CPU的过载,影响程序运行效率。
三、查看Drawcalls
在unity中查看drawcalls有2个方法,如图1所示查看Game窗口中的State下的Batces,这个数量和drawcalls数量相同。第二种方法是查看Window → Analysis → Profiler 中的Rendering下的Drawcalls,如图2所示。

图1 图2
四、Drawcalls优化
1. 3D场景优化
1.1 静态批处理
静态批处理首先需要到 Project Setting → Player → Other Setting 中将Static Bathing 勾选上,然后把需要静止的物体标记为Static,然后无论大小,相同材质的都会组成Batch。如下图所示,当没有勾选 static 的时候,场景中2个cube的drawcalls为4,勾选了之后drawcalls变成了3。

1.2 动态批处理
动态批处理需要在Project Setting → Player → Other Setting 中将Dynamic Bathing 勾选上,Unity会自动将使用相同材质的物体合并处理。如图所示,场景中虽然有3个cube,但是drawcalls还是只有3。

不过,在使用动态批处理的时候,具有一些局限性。
-
顶点属性最大限制900的可移动物体,
-
使用lightmap的物体不行进行批处理
-
使用多通道的shader也不会进行批处理
-
缩放比不同的物体不会批处理
1.3 勾选 Enable GPU Instancing
在使用大量重复的物体时,需要将该物体的材质的 Enable GPU Instancing 勾选上,这样Unity会将Mesh相同的物体合并处理,常用于树木,植被,粒子等。如图所以虽然我放置了5个cube,但是drawcalls依然只有3。

正在上传…重新上传取消
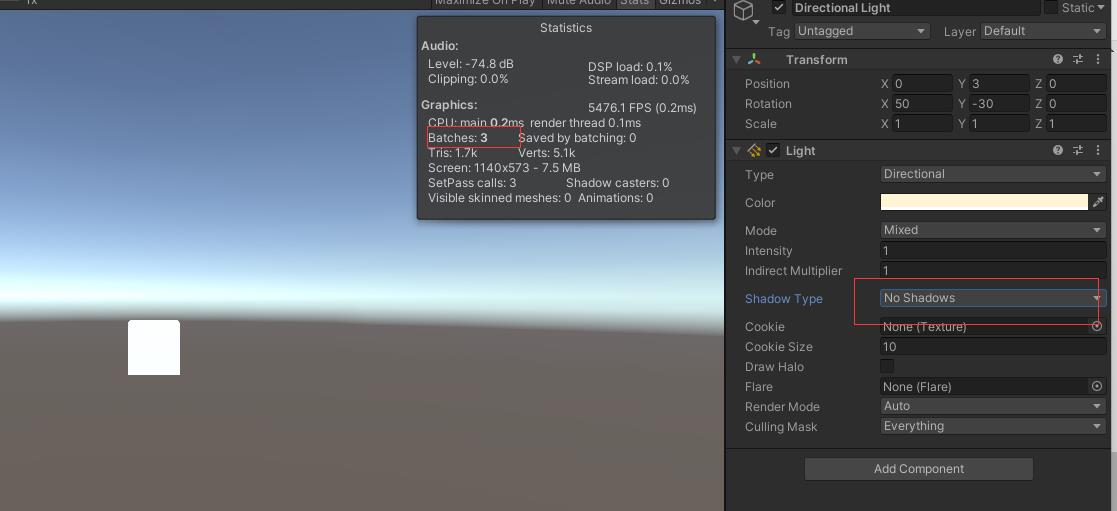
1.4 减少实时光照和阴影效果
当开启灯光,在没有开启阴影的时候drawcalls为3,开启了之后drawcalls变成了7。实时阴影会导致drawcalls大幅上升,建议关闭实时阴影,使用lightmap满足你想要的阴影效果。
1.5 合并Mesh和材质球
如果一个模型有2个或者以上的材质球的时候,drawcalls会直线上升,所以应该劲量将mesh和材质球合并成为一个,以减少drawcalls。如图所示我在一个测试cube中放置了3个material,这个时候drawcalls从3变成了10(和不同的material有关,每个material最低为1)。

1.6 渲染顺序调整
Unity的渲染是有顺序的,这个顺序我们可以自己调整,相机按照深度进行渲染。在图中我使用了3个cube梯次排序,其中第一个和第三个使用相同的材质球。当第二个cube在中间时,drawcalls为5,第二个cube在前或者后时,drawcalls为4。

出现图中情况的原因是在绘制第一个cube时候使用材质球A,绘制第二个cube的时候使用材质球B,绘制第三个cube的时候使用材质球A,这个时候第二个打断了材质球A的渲染使用,使第一个和第三个材质球分开渲染了。
2. 2D UI优化
2.1 图集制作
在制作UI的时候,文件夹中小的图片可以在Unity中制作成图集再给UI使用,这样可以减少drawcalls,具体操作为首先在Project Setting →Editor → Sprite Packer 中选择Mode 为Enable。然后在Assets中右键 Create → Sprite Altas,再将需要打包图集的图片资源拖到Altas中的Objects for Packing中,再点击Pack Preview,图集就制作好了。
如图所示,在没有使用图集的时候,3张图drawcalls为5,当使用的图集时,drawcalls变成了3,3个图使用同一张图集,drawcalls也就变成了3。

2.2 不同图集重叠会打断合批
不同的图集之间重叠会打断合批,在制作UI的时候应该注意不同的UI放置位置,避免出现这种问题,如图,2个图集的UI在分开放的时候drawcalls为4,重叠隔开之后drawcalls变成了5。

2.3 谨慎使用多canvas
每添加一个canvas会添加一个drawcalls,哪怕你下面的资源使用同一个图集也会添加。如图所示当我添加一个canvas,改变了第三个图的层次之后,drawcalls从3变成了4。

2.4 Mask会打断合批,新增drawcalls
当我给使用了图集的一个UI添加一个Mask组件之后,drawcalls从3变成了5。这里可以使用Rect Mask 2D,效果相同但是drawcalls不会增加,回到了3。当我在有Mask组件的UI下添加一个Image,sprite还是使用图集中的图片时,发现drawcalls从5变成了6,说明mask组件还会打断合批,使Mask内外资源分开渲染。这个时候将Mask改为Rect Mask 2D,drawcalls从6变回4,但是也比最初的3多了1,说明使用Rect Mask 2D 也会打断合批,分开渲染。

2.5 图文混排打断合批
新加入两个Text文本(Text Mesh Pro效果相同),drawcalls从3变到4,因为text和image有不同写渲染方式需要分开渲染,移动Text,当2个Text打断了图的连续深度排序时,图片的合批会被,打断,生成多的drawcalls,在图文排版是应特别注意。下图列举了一些错误排版方式和正确方法以及建议排版。
正确:

错误:


建议:

GPU instance 使用一次渲染调用来绘制多个物体,来节省每次绘制物体时CPU→GPU的通信
| 使用限制 | 优点 | |
| 静态合批 | 静止的问题,大内存,大包体 StaticBatchingUtility.Combine | 适用范围较广 |
| 动态合批 | * 顶点属性最大限制900,<br>* 使用lightmap的物体不行进行批处理<br>* 使用MultiplePass的shader也不会进行批处理 | 在一些动的物体上面,内存不会显著增长,不会影响打包的包体 |
| GPUInstance | 一般用于大批生成的物体 | 没有动态合批那样对网格数量的限制,也没有静态网格那样需要这么大的内存 |
| SRP Batcher | 不同mesh,只要使用相同shader且变体一样即可 缺点:constant Buffer显存固定开开销,不支持 | 节省Uniform Buffer的写入操作;按shader分 Batch,预先生存Uniform Buffer,Batch 内部无CPU Write |
[Unity优化] unity性能优化
参考技术A Q:我们图标现在是制作成图集后再使用的,但是当图标数量很多的时候,图集的膨胀就很厉害了。对此我们的做法有两种:1)拆为多个图集;2)不再使用图集转而使用UITexture来使用。请问UWA有什么建议呢?
使用图集的主要缺点在于内存较大,且管理不便;而使用UITexture的主要缺点在于产生的Draw Call较多(每个UITexture都会产生一个Draw Call且无法拼合),影响运行效率。因此,如果同时出现在屏幕上的图标不多,即UITexture所产生的Draw Call数量不大时,可以考虑直接使用;但如果图标数量较多,且目前项目的Draw Call已经较高,那么我们依然建议继续使用图集,按照一定的规则拆分为若干组,从而将 Draw Call控制在较低的范围内。
Q:粒子系统的Prewarm主要用来做什么的,这个怎么优化呢?
ParticleSystem.Prewarm的出现表示当前加载、激活或者首次渲染的粒子系统开启了"Prewarm"选项,而开启该选项的粒子系统在加载后会立即执行一次完整的模拟。以“火焰”为例,Prewarm开启时,加载后第一帧即能看到“大火”,而不是从“火苗”开始逐渐变大。但Prewarm的操作通常都有一定的耗时,建议在可以不用的情况下,将其关闭。
Q:我们为了降低像素填充就限制了最大分辨率,但是发现限制之后NGUI的字体显示就变得模糊了。是否可以避免NGUI字体模糊呢?下图是我们在小米5上测试得到的结果:低分辨率下文字就模糊了。
从开发团队提供的图片上看,小米5上的低分辨率用的是983x552,相当于将原来的画面的四分之一分辨率。此时,降低分辨率的做法可以理解为把983x552的纹理拉伸后贴到1920x1080的屏幕上,而“贴”的过程还会涉及到重新采样,因此造成模糊是正常的,而不仅仅是文本。只是文本的边缘对比度较高,拉伸后变糊的现象会更加明显。
我们建议尝试通过RenderTexture来控制不同内容的分辨率,对于UI部分尽量不要把分辨率降得太低。
Q:打包AssetBundle的时候,我发现切换场景时,即使打同一个场景的AssetBundle,它们的Hash值都是不一样的,可能是什么原因造成的呢?
在不同的场景下打包同一个资源或场景时,如果出现AssetBundle的差异,目前很可能是Shader Stripping造成的,其原理可见文档: https://docs.unity3d.com/Manual/class-GraphicsSettings.html
简单来说就是根据当前场景对Shader进行简化,因此如果打包时包含的场景的Lightmap或Fog设置不同,打出来的AssetBundle包也有可能是不同的。可以尝试通过把Graphics Settings中的Shader Stripping设置进行修改来避免这个问题。
Q:当UI关闭后,Texture图片却还留在内存,是下次垃圾回收或者Resources.UnloadUnusedAssets调用的时候就会清除吗?如果想立即清除,该如何操作?
垃圾回收并不会卸载内存中的资源,而Resources.UnloadUnusedAssets是可以的,但前提是纹理资源已经不再被其他Object引用。如果要立即清除,可以尝试直接调用Resources.UnloadAsset来进行卸载。
Q:我们的游戏中,不透明渲染在总体渲染里占比较高,主要的开销在于 MeshSkinning.Render 部分,这部分的Draw Call过高,共有65个, 请问该如何优化呢?
默认情况下Skinned Mesh是无法合并Draw Call的,从而导致Draw Call过高的问题。 我们建议尝试通过 SkinnedMeshRenderer的BakeMesh接口,将蒙皮动画转为网格序列帧,同时确保顶点属性的数目符合动态拼合的条件,从而降低这部分的Draw Call。另外,这种做法也可以降低MeshSkinning.Update以及Animator.Update的CPU耗时,只是网格序列帧会占用较大的内存,研发团队可以尝试做一个评估。
Q:预设中的变量,拖拽到Inspector面板和Transform.find这两种方法对加载影响是一样的吗?
对加载性能有微小的不同。Transform.Find 是可以灵活控制调用时机的,可以真正要用的时候再进行Transform.Find,这样GameObject被实例化时效率会更高一些 。但如果拖上去,GameObject被实例化时,该变量就需要进行序列化。因此,加载和实例化时两者的性能会存在一些微小的变化。
Q:我发现当把UI挪到屏幕外时,Draw Call不会减少,只有设置Enabled去掉才能减少。UI是没有遮罩剔除这类功能吗? 那是否意味着ScrollRect只能自己做动态加载或者动态设置Enabled之类的优化了?
因为UGUI合并网格时是以Canvas为单位的,所以只把一部分UI元素移除屏幕并不能降低Draw Call,在Unity 5.2版本以前需要满足两点:
1. 使用Screen Space – Camera 的 Render Mode;
2. 需要将移出的UI元素放在独立的Canvas中,然后整体移出屏幕。
但在Unity 5.2版本之后,上述方法也已经失效。
因此我们建议,在移出后,通过将Canvas的Layer修改为相机Culling Mask中未选中的Layer来去除这部分多余的Draw Call,> 但这种方法同样需要将移出的UI元素放在独立的Canvas中。这种方法,相比Enabled的设置,可以减少一定的CPU开销。而对于ScrollRect,如果包含的UI元素较多,确实需要自己做动态加载和动态设置Enabled来进行优化。
Q:UI展示动画时,使用Mask做和使用UI本身做 ,哪个效率会更高些?
一般来说建议尽可能少用Mask组件,该组件的使用对于Draw Call会有较大的影响,也可尝试用 Rect2D Mask来代替。而如果直接通过改变UI元素本身来做动画,当涉及的UI元素数量较大时,容易引起较高的网格重建开销。
Q:GameObject.Instantiate()每实例化一个GameObject到场景中,会造成卡顿,有什么办法可以优化吗?就算我采用了异步加载,仍然会有稍许的卡顿感。除了缓存池,是否还有别的方法?
建议研发团队先通过Unity Profiler来确定该性能卡顿的位置。如果只是一个空的GameObject,Instantiate实例化是很快的。一般来说,Instantiate实例化时间较长,主要由以下三个原因:
(1)与资源的加载有关:对于这种情况,研发团度需要精简资源,或者预加载资源来降低实例化的开销;
(2)序列化信息比较多:当GameObject上的Component比较多时,其Instantiate实例化性能会受到影响,比如说粒子系统,这种情况就只能通过分帧实例化,或者通过缓存池来避免;
(3)自定义组件的Awake:在Instantiate实例化时,其GameObject上挂载脚本的Awake函数也会被触发,其中产生的CPU占用,也会被计算在Instantiate实例化内。
以上是关于Unity优化之Drawcall的主要内容,如果未能解决你的问题,请参考以下文章