Vue学习——第四弹
Posted 沃和莱特
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Vue学习——第四弹相关的知识,希望对你有一定的参考价值。
前言
上一篇文章 Vue学习——【第三弹】 中我们了解了MVVM模型,这篇文章接着学习Vue中的数据代理。
简单介绍
数据代理就是**一个对象(A)来代理对另一个对象(B)的属性操作(A一定要包含B)。**直接看定义大家可能觉得有些抽象,我们可以用代码来实现。
提到数据代理,我们会很容易想到一个重要的API:JavaScript中的Object.defineProperty() 方法:
通过对javascript的学习,我们知道可以用Object.defineProperty() 方法直接在一个对象上定义一个新属性,或者修改一个已经存在的属性,它的语法是这样的:
Object.defineProperty(obj, prop, desc)
obj 需要定义属性的当前对象
prop 当前需要定义的属性名
desc 属性描述符
该方法的工作机制:
给对象添加属性值 value
给对象添加getter和setter
getter和setter用于对属性的读写进行监控
并且该方法还具有一些配置项,比如:
enumerable:true,//enumerable用于控制属性是否可以枚举,默认值时false
writable:true,//该配置项可以控制属性是否可以被修改,默认是false
configurable:true//该配置项可以控制属性是否可以被删除,默认值是false
那么接下来我们就来看看Object.defineProperty() 方法的使用方式:
<!-- 数据代理:通过一个对象代理对另一个对象中的属性进行操作 -->
<script type="text/javascript">
let obj1 = a:100
let obj2 = b:200
// 当访问obj2.a的时候,就调用get函数,然后返回obj1中的属性a;当修改obj2.a时,obj1.a就会被修改
Object.defineProperty(obj2,'a',
get()
console.log('obj1.a被读取')
return obj1.a
,
set(value)
console.log('obj.a被修改')
obj1.a = value
)
</script>
在控制台上操作:
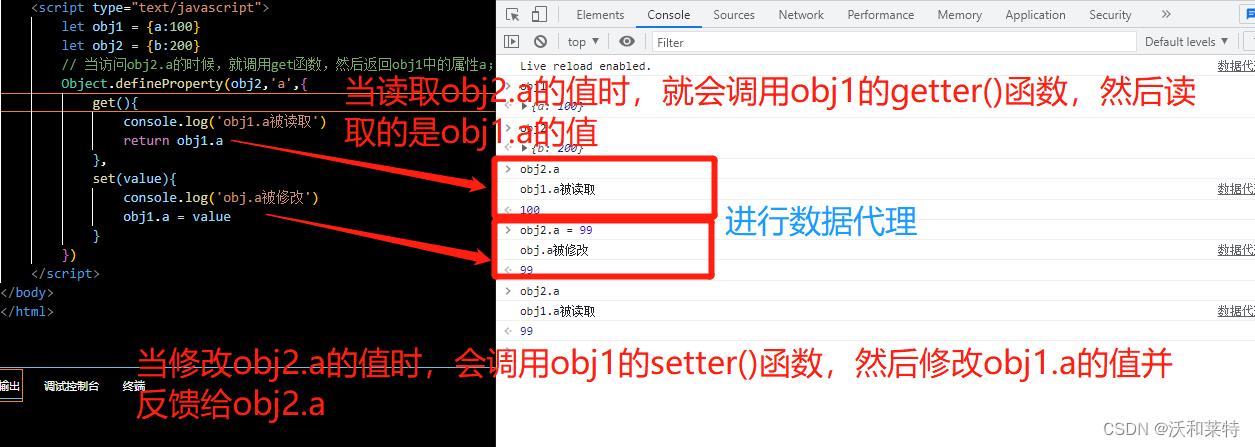
Vue中的数据代理
我们知道Vue是渐进式的JavaScript框架,而Vue中的数据代理所调用的API就是Object.defineProperty() 方法,我们举几个例子,来观察一下Vue中的数据代理的实现:
<div id="demo">
<h1>姓名:name</h1>
<h2>地址:address</h2>
</div>
<script type="text/javascript">
const vm = new Vue(
el:'#demo',
data:
name:'小明',
address:'山东'
)
</script>
控制台上操作:
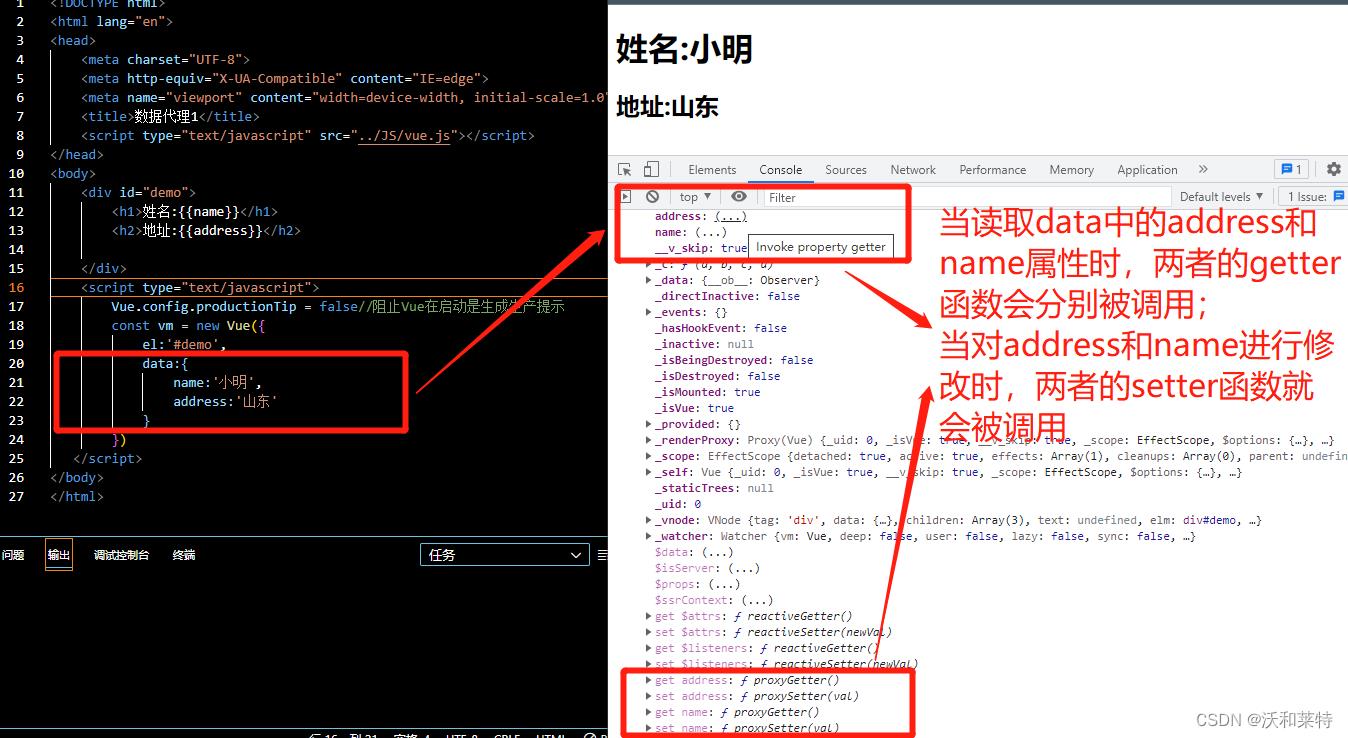
我们在控制台发现了熟悉的两个属性——name和address,并且点开它们我们可以看到它们的值就是我们代码中的值;
前文提到使用Object.defineProperty() 方法时,getter() 和setter() 用于对属性的读写进行监控,我们不妨来验证一下Vue数据代理中的getter()和setter()
捕获data
在验证setter()函数的调用之前,我们先看一下如何去获取data:
当我们直接去获取data时发现控制台返回 undefined
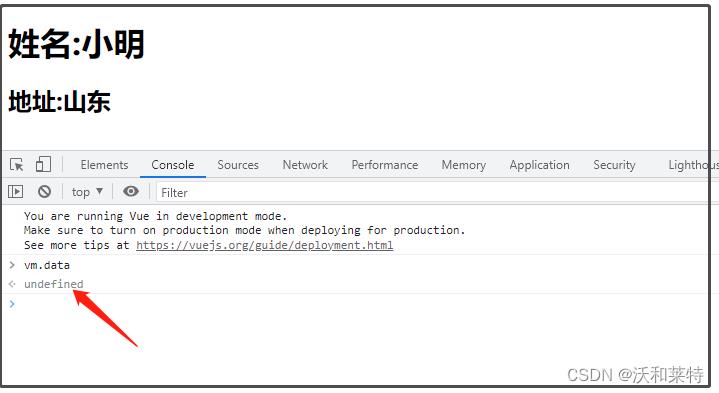
这时候我们看一下我们写的代码:
<div id="demo">
<h1>姓名:name</h1>
<h2>地址:address</h2>
</div>
<script type="text/javascript">
const vm = new Vue(
el:'#demo',
data:
name:'小明',
address:'山东'
)
</script>
我们不难看出,vm中的data其实是vm配置对象中的一个属性,并非全局变量,因此我们无法通过vm.data直接获取data,这时候想要获取data,就需要用到vm._data进行获取:
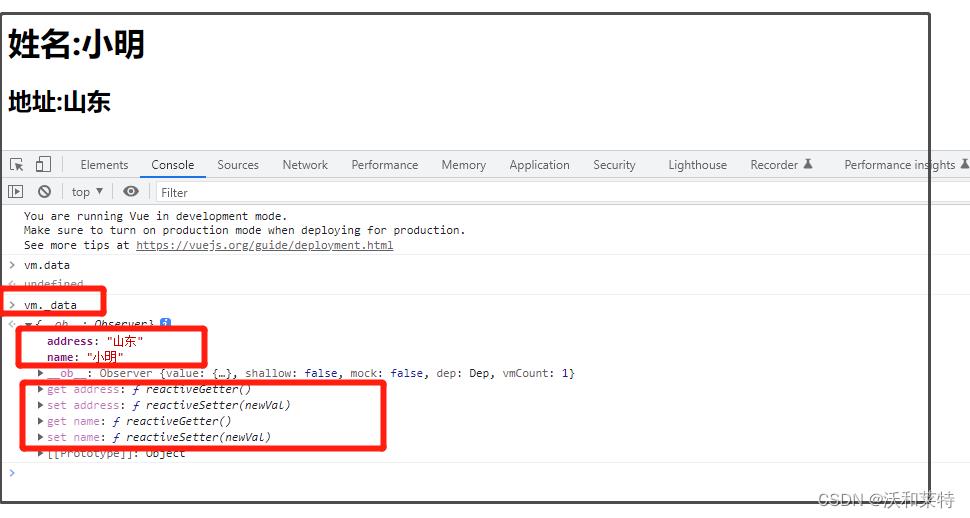
并且我们发现,在vm._data中还出现了data中的name和address属性。
其实,这里的vm._data就是我们想要获取的data,比如我们举个例子来验证一下:
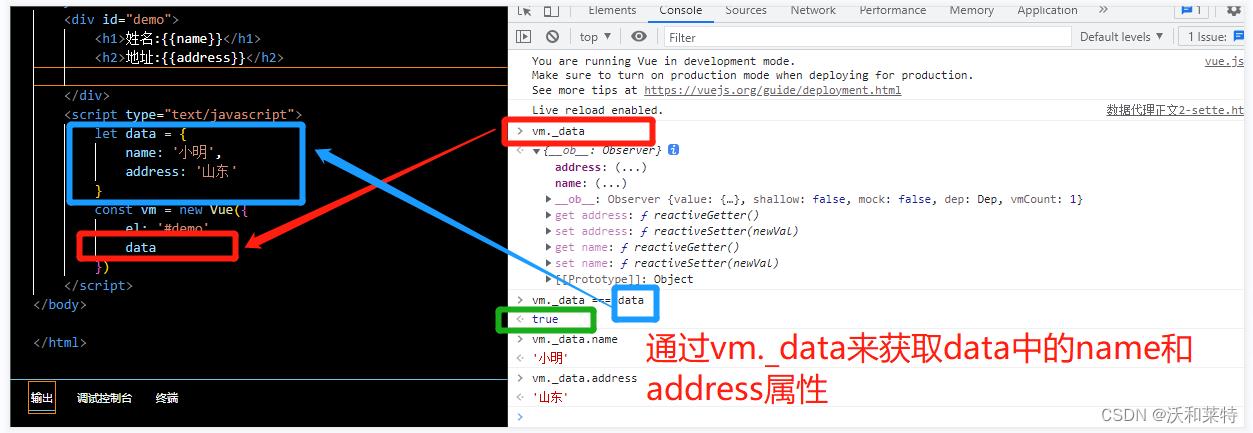
我们将含有name和address属性的data作为一个全局变量写在 vm 的外部,然后在Vue实例中写上一个data;再在控制台比较vm._data是否和data相同,结果是返回true,很明显,两者是相同的。
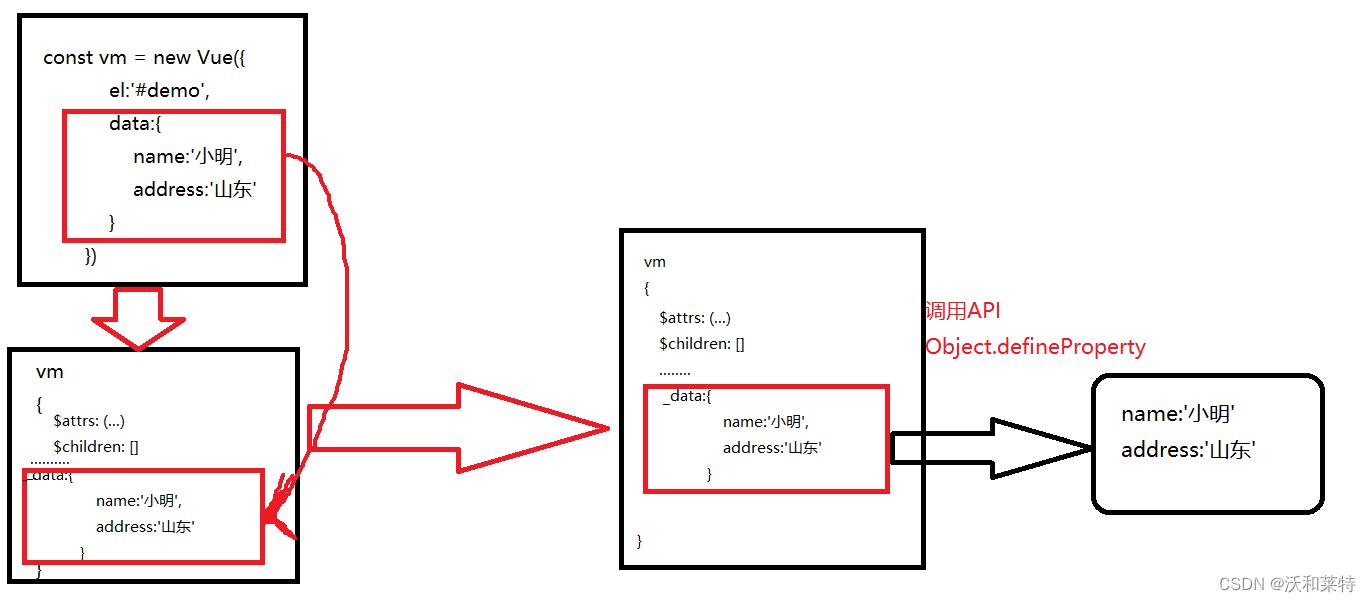
简单描述一下Vue中的数据代理的过程:
vm 拿到data中的数据后,放在了vm里的_data中。vm中的name和address代理了_data中的name和address。读取vm.name时,调用getter()方法,读取了_data中的name。
修改了vm中的name时,就会调用setter()方法去修改_data中的name。
如果不做代理,在“ ”中须要这样写成“_data.xxx”的形式;通过Vue中的数据代理,我们就可以简化缩写内容,只需要些xxx的形式即可。
明白以上原理,我们就可以很容易明白在进行数据代理时对getter()和setter()的调用啦。
getter()
 在我们读取vm中的name属性时,负责对name进行读取的函数getter()就会被调用,然后执行对data中的name属性值进行读取。
在我们读取vm中的name属性时,负责对name进行读取的函数getter()就会被调用,然后执行对data中的name属性值进行读取。
setter()

并且在模板中的花括号里的内容我们都可以写成 _data.xxx 的形式,通过Vue的数据代理,我们就无需如此繁琐的写成_data.xxx的形式。
小结
通过代码的验证,下图可以为我们展现出Vue中的数据代理机制:
参考文献
如有不足,感谢指正!
运维学习第四弹
运维学习之用户和组的管理:
linux是一个多用户多任务的分时操作票系统,所有一个要使用系统资源的用户都必须先向系统管理员申请一个账号,然后以这个账号的身份进入系统。用户的账号一方面能帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也能帮助用户组织文件,并为用户提供安全性保护。每个用户账号都拥有一个惟一的用户名和用户口令。用户在登录时键入正确用户名和口令后,才能进入系统和自己的主目录。
实现用户账号的管理,要完成的工作主要有如下几个方面:
1)用户账户管理
2)组账户管理
3)权限的分配
现在大多数企业采用的Cisco公司开发的AAA认证体系:
Authentication:认证,核实身份是否正确;
Authorization:授权,对已经核实身份的用户进行资源分配;
Accounting:审计,监督资源被使用的情况;
在这个多用户、多任务的系统中,应用程序进程是能够实现资源使用和完成任务的主题。
进程是以其发起者的身份运行的:可以理解为,进程的所有者就是发起者 ;会将发起者的信息标记在进程上;当进程试图访问资源的时候,安全上下文会比对进程的所有者和资源的所有者的关系:
首先查看进程的所有者是不是资源的所有者,如果是,就按照属组的权限使用;
如果不是,则判断进程的所有者是否属于资源所属组,如果是,按照属组的权限使用资源;如果不是,则直接使用资源的其他人访问权限来使用资源;
用户账户:就是计算机操作者在操作系统中的身份映射;是在满足了认证条件之后的身份映射;
其中用户分为2类:
超级用户(管理员):root
普通用户:
1)系统用户:为了保证安全,必须让那些运行在后台的进程或者服务类进程以非管理员的身份运行;这类 用户一般不需要登陆到系统;
2)登录用户:能够正常使用整个系统资源的用户;
用户的标识:
1)用户的登录名称:为操作者准备的简单易记的字符串标识;
2)用户的ID(UID):为计算机系统准备的数字标识;
超级用户ID:0
系统用户ID:
CentOS5、6:1~499
CentOS7:1~999
登录用户:
CentOS5、6:500~60000
CentOS7:1000~60000
60000+的标识符为用户自定义标识:
名称解析:
名字<-->UID
解析库:/etc/passwd(解析库文件)
系统利用解析库完成认证机制:
验证登录用户是否是你声称的那个人
认证库:
用户的认‘证信息库:/etc/shadow
组的认证信息库:/etc/group
采用密码认证的机制:
设置密码的一般性策略:
1.尽量使用随机字串作为密码;
2.密码的长度一般不要少8字符
3.密码中至少包括大写字母、小写字母、数字和标点符号四类字符中的三类;
4.不定期更换,每隔一段不规律的时间更换一个密码;42天之内更改密码。
在linux中,保存到认证库中的密码信息是经过加密保存的:
hash(哈希)单向加密算法:抽取原始数据的特征信息,数据指纹;
单向加密算法的特征:
1.只要数据相同,其加密结果就必然相同;
2.无论数据多大,其加密效果定长输出;
3.雪崩效应:
4.不可逆
单向加密常用的算法:
1.md5:message diges,消息摘要,128bit定长输出
2.sha1:Secuer Hash Alogrithm ,安全的哈希算法,160bit定长输出;
3.sha224
4.sha256
5.sha384
6.sha512
salt:加随机数
抽取随机数:
ls /dev/*random
/etc/random :仅仅只是从熵池中返回随机数,一旦熵池随机数耗尽,则进程被堵塞
/etc/unrandom:先试图从熵池中返回随机数,如果熵池耗尽,它就会利用伪随机数生成器生产伪随机数;
注意: 熵池中的数据有可能被取空。
echo "qhdlink" | md5sum : 为qhdlink这个数据流加密
最终认证字符串:算法+salt+密码
在认证库中存放的信息:$6$salt$crytped_password
用户组:将具有某些相同或相似属性的用户联系在一起以便集中授权的容器:
用户的组类别:
管理员组:
普通用户组:
1)系统组:
2)登陆组:
组的标识方法:
组名:
方便操作者使用的;
组的ID(GID) :
为系统提供组标识;
管理员组:0
系统组:
CentOS5~6:1-499
CentOS7:1-999
登陆组:
CentOS5、6:500-60000
CentOS7:1000-60000
组的解析库:
/etc/group
组也需要认证,组也有认证库:
/etc/grasswd
同样组也需要密码保护,如果组没有设置密码保护的话,则不能随时加入
以用户为核心来对组进行分类:
用户的主要组(基本组):primary group,对于用户来说,这样的组要有而且只能有一个
用户的附加组(附属组,额外组):这样的组对于用户来说可以没有,也可以有多个。
根据组容纳的用户进行分类:
用户的私有组:组名与用户登录名相同,并且组中只有此用户;
用户的公共组:组中可以包含其他多个不同用户;
注意:默认情况下,用户的主要组都是其私有组
下面是我们在进行用户和组的管理时主要使用命令:
组管理相关的命令:
groupadd groupdel groupmod gpasswd
用户管理相关的命令L:
useradd userdel usermod
与认证相关的命令:
passwd 、gpasswd 、chage、
其他的相关的管理命令:
chsh finger su id
用户账号的管理主要涉及到用户账号的添加、删除和修改。
1.创建新用户的命令是useradd,其语法如下:
useradd 选项 用户名
其中各选项含义如下:
-c comment 指定一段注释性描述。
-d 目录 指定用户主目录,如果此目录不存在,则同时使用-m选项,能创建主目录。
-g 用户组 指定用户所属的用户组。
-G 用户组,用户组 指定用户所属的附加组。
-s Shell文件 指定用户的登录Shell。
-u 用户号 指定用户的用户号,如果同时有-o选项,则能重复使用其他用户的标识号。
-p 这个命令是需求提供md5码的加密口令,普通数字是不行的。
2.删除账号的命令是userdel,其语法如下:
userdel 选项 用户名
-r : 把用户的主目录一起删除
3.修改已有账号信息的命令是usermod,其语法如下:
-c 修改用户帐号的备注文字。
-d 修改用户登入时的目录。
-e 修改帐号的有效期限。
-f 修改在密码过期后多少天即关闭该帐号。
-g 修改用户所属的群组。
-G 修改用户所属的附加群组。
-l 修改用户帐号名称。
-L 锁定用户密码,使密码无效。
-<shell> 修改用户登入后所使用的shell。
-u<uid> 修改用户ID。
-U 解除密码锁定。
4.产看账号的属性
id user1 :显示user1的UID和GID
5,指定和修改用户的密码命令是passwd,其用法如下:
passwd 选项 用户名
-l 锁定密码,即禁用账号。
-u 密码解锁。
-d 删除用户的密码。
-f 强迫用户下次登录时修改密码。
用户组的管理:
1.添加用户组的命令是groupadd,其语法如下:
groupadd 选项 用户
-g GID 指定新用户组的组标识号(GID)。
-o 一般和-g选项同时使用,表示新用户组的GID能和系统已有用户组的GID相同。
2.删除已有的用户组用groupdel命令。
groupdel 用户组
3.修改用户组的命令是groupmod命令:
groupmod 选项 用户组
-g GID 为用户组指定新的组标识号。
-o 和-g选项同时使用,用户组的新GID能和系统已有用户组的GID相同。
-n 新用户组 将用户组的名字改为新名字
以上是关于Vue学习——第四弹的主要内容,如果未能解决你的问题,请参考以下文章