Java-HashMap源码分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java-HashMap源码分析相关的知识,希望对你有一定的参考价值。
HashMap
(1)HashMap是基于哈希表Map的实现,允许key和value的值为null,保证不了存入数据的顺序;
(2)HahMap有两个参数影响它的性能:初始容量和负载因子;
(3)默认的负载因子之所以是0.75,是为了时间和空间成本的一种平衡;
(4)HashMap不是线程安全的,没有实现同步;
1. JDK1.8里HashMap的实现是通过:数组 + 链表 + 红黑树 来实现的。
2. HashMap中一些常量和两个重要的数据结构的作用
// 创建 HashMap 时未指定初始容量情况下的默认容量,默认16 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 // hashmap的最大容量,2的30次方 static final int MAXIMUM_CAPACITY = 1 << 30; // hashmap默认的负载因子是0.75 static final float DEFAULT_LOAD_FACTOR = 0.75f; // hashmap中关于红黑树的三个参数 // 1.用来确定何时将链表转换为树 static final int TREEIFY_THRESHOLD = 8; // 2.用来确定何时将树转换为链表 static final int UNTREEIFY_THRESHOLD = 6; // 3.当链表转换为树时,需要判断下数组的容量,当数组的容量大于这个值时,才树形化该链表; // 否则会认为链表太长(即冲突太多)是由于数组的容量太小导致的,则不将链表转换为树,而是对数组进行扩容; static final int MIN_TREEIFY_CAPACITY = 64;
// 用来实现数组中链接的数据结构 static class Node<K,V> implements Map.Entry<K,V> { final int hash; // 每个节点的hash值 final K key; // 每个节点的key值 V value; // 每个节点的value HashMap.Node<K, V> next; // 链表中当前节点的下一个节点 Node(int hash, K key, V value, HashMap.Node<K, V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } } // 用来实现红黑树的数据结构 static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { HashMap.TreeNode<K, V> parent; // 存储当前节点的父节点 HashMap.TreeNode<K, V> left; // 存储当前节点的左孩子 HashMap.TreeNode<K, V> right; // 存储当前节点的右孩子 HashMap.TreeNode<K, V> prev; // 存储当前节点的前一个节点 boolean red; // 存储红黑树当前节点的颜色(红,黑) TreeNode(int hash, K key, V val, HashMap.Node<K, V> next) { super(hash, key, val, next); } }
3. HashMap的put方法的大致实现步骤:
- 对key的hashCode()做hash,然后计算出要保存到数组的index;
- 如果没有发生index冲突,直接放到数组里;
- 如果发生冲突了,以链表的形式保存在数组里,采用头部插入,保存在链表的最上层;
- 如果冲突导致该链表过长(超过了默认的TREEIFY_THRESHOLD),将进行扩容或者将该链表转换为红黑树;
- 保存的时候,如果节点存在,就替换旧的key值;
- 如果数组满了,就扩充为原来的两倍;
源代码如下:
// put方法的主逻辑 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 1. 数组为空则进行创建 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 2.1 根据hash值计算出节点在数组中的插入位置,如果该index处没有元素,则进行插入((n-1) & hash 计算下标) if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { // 2.2 如果该位置已经有元素存在 Node<K,V> e; K k; // 3.1 比较原有元素和待插入元素的hash值和key值,如果都相等,则覆盖掉原来的value if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 3.2 如果原节点是红黑树结构,则调用红黑树的putTreeVal方法进行判断处理 else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 3.3 如果原节点是链表的头节点,从这个节点向后查找插入位置 for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { // 4.1 找到位置,插入数据 p.next = newNode(hash, key, value, null); // 4.2 链表长度好过8,调用树形化方法进行扩容或转换为红黑树 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // 4.3 在该链表中找到已存在元素,替换掉旧的value if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } // 5.1 待插入元素在hashmap中已经存在 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; // 6.1 是否需要扩容,threshold据说该字段叫做阈值(yu zhi) if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
4. HashMap的树形化方法:treeifyBin()
// 链表的树形化方法:如果链表的长度超过了8,则调用该方法 final void treeifyBin(Node<K,V>[] tab, int hash) { int n, index; Node<K,V> e; // 1. 如果数组为空 或这 数组的长度小于 进行树形化的阈值(默认64) 就扩容 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY) resize(); else if ((e = tab[index = (n - 1) & hash]) != null) { // 2. 如果数组中的元素个数超过了阈值,进行树形化,转为红黑树(hd tl 红黑树头尾节点) TreeNode<K,V> hd = null, tl = null; do { // 3. 从链表的第一个节点开始构建树,e是链表的第一个节点 TreeNode<K,V> p = replacementTreeNode(e, null); if (tl == null) hd = p; else { p.prev = tl; tl.next = p; } tl = p; } while ((e = e.next) != null); // 4. 让数组的第一个元素指向红黑树的头节点,以后这个数组里的元素就是红黑树,而不是链表了 if ((tab[index] = hd) != null) hd.treeify(tab); } }
5. HashMap的get方法实现的大致步骤:
- 首先hashMap的数组不为空,否则返回null;
- 直接定位到该节点,比较该节点的第一个元素,如果相等直接返回;
- 如果该节点是红黑树,调用红黑树的getTreeNode方法返回;
- 如果该节点是链表,挨个查询,匹配完成返回;
源码如下:
public V get(Object key) { Node<K,V> e; // 通过key计算出hash,然后通过hash和key 调用getNode方法 return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; // 1. 数组不为空,通过下标定位到节点,如果该节点的第一个元素不为空((n-1)&hash 计算下标) if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // 2. 定位到的节点的第一个元素匹配上,直接返回 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { // 3. 如果该节点是红黑树,则调用红黑树的getTreeNode方法来返回 if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); // 4. 如果该节点是链表,挨个匹配,匹配完成返回; do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }
问题:
1. 存取时如何确定key在数组中的index?
答:对该节点的key获取hashCode值,然后高位运算计算hash,然后取模运算,计算出index;
在get和put的过程中,计算下标时,先对hashCode进行hash操作,然后再通过hash值进一步计算下标,如下图所示:
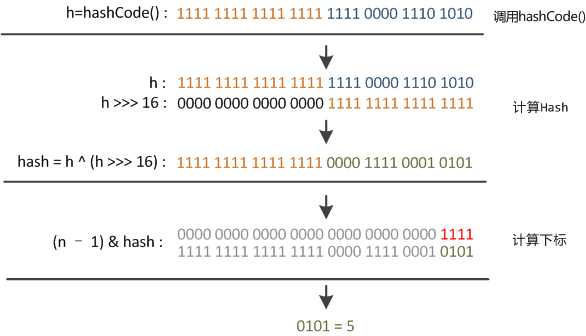
计算hash方法:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
可以看到这个函数大概的作用就是:高16bit不变,低16bit和高16bit做了一个异或。
在设计hash函数时,因为目前的table长度n为2的幂,而计算下标的时候,是这样实现的(使用&位操作,而非%求余):
(n - 1) & hash
设计者认为这方法很容易发生碰撞。为什么这么说呢?不妨思考一下,在n - 1为15(0x1111)时,其实散列真正生效的只是低4bit的有效位,当然容易碰撞了。
因此,设计者想了一个顾全大局的方法(综合考虑了速度、作用、质量),就是把高16bit和低16bit异或了一下。设计者还解释到因为现在大多数的hashCode的分布已经很不错了,就算是发生了碰撞也用O(logn)的tree去做了。仅仅异或一下,既减少了系统的开销,也不会造成的因为高位没有参与下标的计算(table长度比较小时),从而引起的碰撞。
如果还是产生了频繁的碰撞,会发生什么问题呢?作者注释说,他们使用树来处理频繁的碰撞(we use trees to handle large sets of collisions in bins),在JEP-180中,描述了这个问题:
Improve the performance of java.util.HashMap under high hash-collision conditions by using balanced trees rather than linked lists to store map entries. Implement the same improvement in the LinkedHashMap class.
之前已经提过,在获取HashMap的元素时,基本分两步:
- 首先根据hashCode()做hash,然后确定bucket的index;
- 如果bucket的节点的key不是我们需要的,则通过keys.equals()在链中找。
在Java 8之前的实现中是用链表解决冲突的,在产生碰撞的情况下,进行get时,两步的时间复杂度是O(1)+O(n)。因此,当碰撞很厉害的时候n很大,O(n)的速度显然是影响速度的。
因此在Java 8中,利用红黑树替换链表,这样复杂度就变成了O(1)+O(logn)了,这样在n很大的时候,能够比较理想的解决这个问题。
代码参考:
http://yikun.github.io/2015/04/01/Java-HashMap%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E7%8E%B0/
https://tech.meituan.com/java-hashmap.html
http://blog.csdn.net/lianhuazy167/article/details/66967698
以上是关于Java-HashMap源码分析的主要内容,如果未能解决你的问题,请参考以下文章