hive的jdbc使用
Posted 求知cvip
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive的jdbc使用相关的知识,希望对你有一定的参考价值。
①新建maven项目,加载依赖包
在pom.xml中添加
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.1</version>
</dependency>
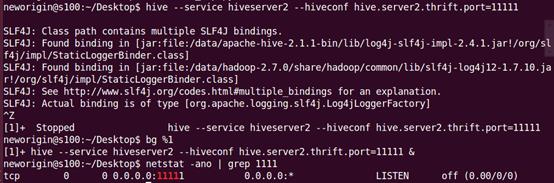
②启动hive的service,启动集群
(hive1.2.1版本以后需要使用hiveserver2启动)
hive –-service hiveserver2 –-hiveconf hive.server2.thrift.port=11111(开启服务并设置端口号)
③配置core-xite.xml
<property>
<name>hadoop.proxyuser.neworigin.groups</name>
<value>*</value>
<description>Allow the superuser oozie to impersonate any members of the group group1 and group2</description>
</property>
<property>
<name>hadoop.proxyuser.neworigin.hosts</name>
<value>*</value>
<description>The superuser can connect only from host1 and host2 to impersonate a user</description>
</property>
④编写java代码
package com.neworigin.HiveTest1; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.sql.Statement; public class JDBCUtil { static String DriverName="org.apache.hive.jdbc.HiveDriver"; static String url="jdbc:hive2://s100:11111/myhive"; static String user="neworigin"; static String pass="123"; //创建连接 public static Connection getConn() throws Exception{ Class.forName(DriverName); Connection conn = DriverManager.getConnection(url,user,pass); return conn; } //创建命令 public static Statement getStmt(Connection conn) throws SQLException{ return conn.createStatement(); } public void closeFunc(Connection conn,Statement stmt) throws SQLException { stmt.close(); conn.close(); } } package com.neworigin.HiveTest1; import java.sql.Connection; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import java.sql.Statement; public class JDBCTest { public static void main(String[] args) throws Exception { Connection conn = JDBCUtil.getConn();//创建连接 Statement stmt=JDBCUtil.getStmt(conn);//创建执行对象 String sql="select * from myhive.employee";//执行sql语句 String sql2="create table jdbctest(id int,name string)"; ResultSet set = stmt.executeQuery(sql);//返回执行的结果集 ResultSetMetaData meta = set.getMetaData();//获取字段 while(set.next()) { for(int i=1;i<=meta.getColumnCount();i++) { System.out.print(set.getString(i)+" "); } System.out.println(); } System.out.println("第一条sql语句执行完毕"); boolean b = stmt.execute(sql2); if(b) { System.out.println("成功"); } } }
以上是关于hive的jdbc使用的主要内容,如果未能解决你的问题,请参考以下文章