Spark---并行度和分区
Posted 快跑呀长颈鹿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark---并行度和分区相关的知识,希望对你有一定的参考价值。
Spark之并行度和分区
文章目录
并行度和分区
默认情况下,Spark 可以将一个作业切分多个任务后,发送给 Executor 节点并行计算,而能
够并行计算的任务数量我们称之为并行度。这个数量可以在构建 RDD 时指定。记住,这里
的并行执行的任务数量(Task),并不是指的切分任务的数量。
集合数据源分区
def main(args: Array[String]): Unit =
//准备环境
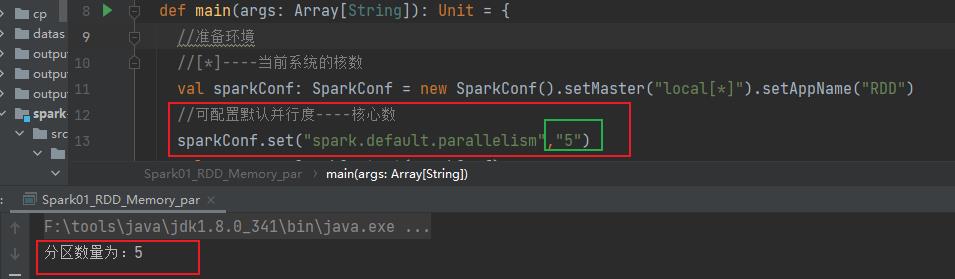
//[*]----当前系统的核数
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
/**
* RDD的并行度&分区
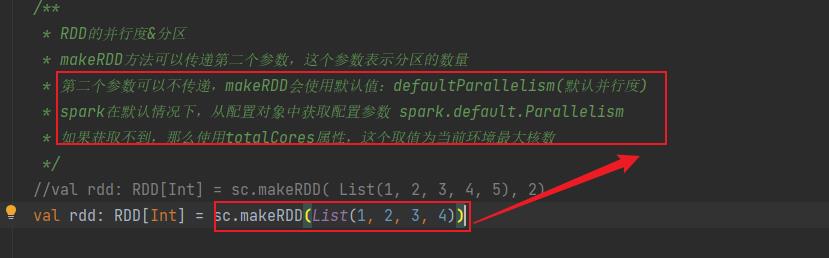
* makeRDD方法可以传递第二个参数,这个参数表示分区的数量
* 第二个参数可以不传递,makeRDD会使用默认值:defaultParallelism(默认并行度)
* spark在默认情况下,从配置对象中获取配置参数 spark.default.Parallelism
* 如果获取不到,那么使用totalCores属性,这个取值为当前环境最大核数
*/
val rdd: RDD[Int] = sc.makeRDD( List(1, 2, 3, 4, 5), 2)
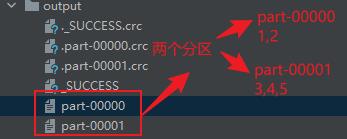
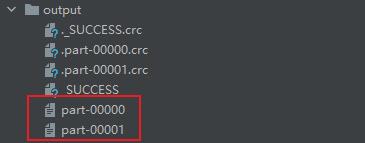
//将处理的数据保存成分区文件
rdd.saveAsTextFile("output")
//关闭环境
sc.stop()

第二个参数可以不传递,makeRDD会使用默认值:defaultParallelism(默认并行度)
在不传参数的情况下
spark在默认情况下,从配置对象中获取配置参数 spark.default.Parallelism
如果获取不到,那么使用totalCores属性,这个取值为当前环境最大核数
就是开头配置的环境
val sparkConf: SparkConf = new SparkConf().setMaster(“local[*]”).setAppName(“RDD”)
先获取sparkConf.set(“spark.default.parallelism”,“5”)
//[*]----当前系统的核数
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
//可配置默认并行度----核心数
sparkConf.set("spark.default.parallelism","5")
val sc = new SparkContext(sparkConf)
//创建RDD
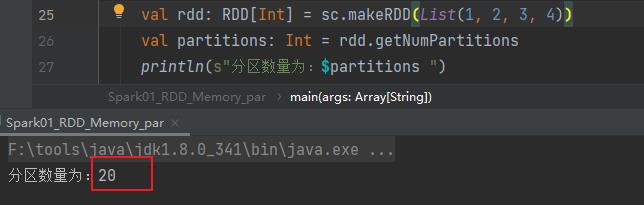
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val partitions: Int = rdd.getNumPartitions
println(s"分区数量为:$partitions ")
//关闭环境
sc.stop()
没有设置时,取值为当前环境最大核数
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
val partitions: Int = rdd.getNumPartitions
println(s"分区数量为:$partitions ")
//将处理的数据保存成分区文件
//rdd.saveAsTextFile("output")
文件数据源分区
读取文件数据时,数据是按照 Hadoop 文件读取的规则进行切片分区,而切片规则和数据读取的规则有些差异。
默认分区数
def main(args: Array[String]): Unit =
//准备环境
//[*]----当前系统的核数
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
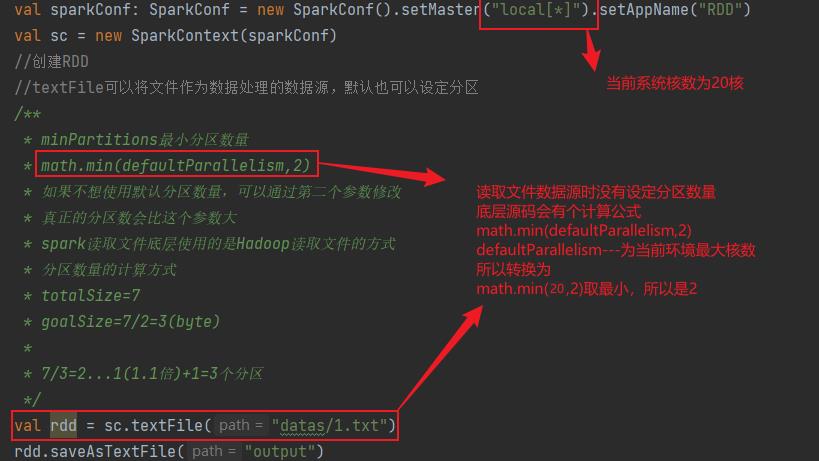
//textFile可以将文件作为数据处理的数据源,默认也可以设定分区
/**
* minPartitions最小分区数量
* math.min(defaultParallelism,2)
* 如果不想使用默认分区数量,可以通过第二个参数修改
* 真正的分区数会比这个参数大
* spark读取文件底层使用的是Hadoop读取文件的方式
* 分区数量的计算方式
* totalSize=7
* goalSize=7/2=3(byte)
*
* 7/3=2...1(1.1倍)+1=3个分区
*/
val rdd = sc.textFile("datas/1.txt")
rdd.saveAsTextFile("output")
//关闭环境
sc.stop()
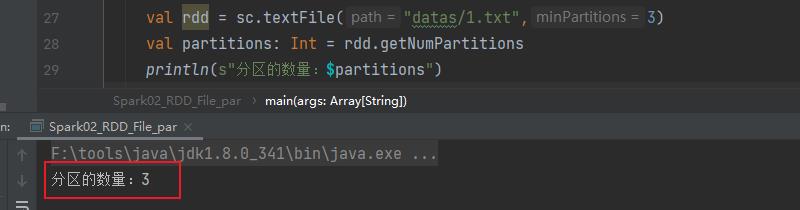
指定分区数
文件分区数量的计算方式
文件为

如果指定分区数量设置为2,但实际分区数量为3

文件大小有7个字节,但文件内只有1 2 3
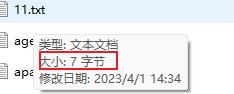
其实是包含了回车换行,也就是7个字节

计算公式
- totalSize=7
- goalSize=7/2=3(byte)—表示每个分区有3个字节
- 7/3=2…1(1.1倍)+1=3个分区----两个分区不够,剩余的数占每个分区的字节数大于10%等同于产生新的分区,如果小于10%不会产生新的分区
所以就会产生三个分区。
Spark 并行化和按键分区
【中文标题】Spark 并行化和按键分区【英文标题】:Spark parallelize and partition by key 【发布时间】:2016-05-30 09:35:13 【问题描述】:在 Spark 中,我可以做到
sc.parallelize([(0, 0), (1, 1), (0, 2), (1, 3), (0, 4), (1, 5)], 2).partitionBy(2)
但是,这首先将数据分布在集群的节点上,然后才再次对其进行混洗。有没有办法在从驱动程序输入数据的时候立即进行key分区?
【问题讨论】:
可以通过首先组织本地数据来避免数据移动,但这看起来像是一个人为的问题。你永远不应该使用parallelize 来传递足够大的数据,以至于后续的洗牌成为问题。
【参考方案1】:
在您提供的示例中,Spark 不知道数据的分区,直到您通过 partitionByKey() 明确提及这一点。
但如果数据已经以适当的方式组织,Spark 可以利用数据的自然分区。例如,
对于 Spark、Parquet 和 HDFS,有一组特定的规则,Spark DataFrames with Parquet and Partitioning 对于 Spark 和 Cassandra,您可以使用来自 Cassandra 连接器的特定 API 来利用分区 https://github.com/datastax/spark-cassandra-connector/blob/master/doc/3_selection.md#grouping-rows-by-partition-key 等。因此,数据、文件系统等的性质会影响 Spark 中的分区。
【讨论】:
以上是关于Spark---并行度和分区的主要内容,如果未能解决你的问题,请参考以下文章