数据库开发常见面试题
Posted '接受现实'
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库开发常见面试题相关的知识,希望对你有一定的参考价值。
主要针对于ORACLE和kettle
1、Delete Truncate Drop 区别
2、DML、DDL
3、经常使用到得函数
4、KETTLE内存溢出解决方案
5、kettle中黄色的锁,绿色的对勾,红色的停止代表的意思
6、数仓架构
7、Oracle的五种约束
8、oracle与mysql的区别
9、创建索引
10、对表数据进行分区
11、exists和in区别
12、数据库三大范式
13、Oracle体系架构
14、窗口函数
15、删除重复数据
16、SQL优化
17、索引、怎么建索引?建在哪个地方?
18、存储过程
19、kettle为什么可以连接不同数据库
20、Ltrim、Rtrim与Trim的区别
21、锁表发生在insert update 、delete 中
22、如何加表空间
23、触发器
24、游标
25、oracle命名规则
26、kettle为什么可以跨平台
27、oracle分页
1、Delete Truncate Drop 区别
delete,drop,truncate 都有删除表的作用,区别在于:
1)delete 和 truncate 仅仅删除表数据,drop 连表数据和表结构一起删除
2)delete 是 DML 语句,操作完以后如果没有不想提交事务还可以回滚,truncate 和 drop 是 DDL 语句,操作完马上生效,不能回滚,
3)执行的速度上,drop>truncate>delete
truncate:释放表空间,对外显示
truncate无法通过binlog回滚,会清空所有数据且执行速度很快。
2、DML、DDL
DML 数据操纵语言:select、insert、update、delete
DDL 数据定义语言:create、truncate、drop、alter
DCL 数据控制语言:grant … to … revoke … from
TCL 事务控制语言: commit、rollback
3、经常使用到得函数
trunc(d,fmt):将日期保留到指定的精度,如果第二个参数缺失,相当于是dd,fmt可以是yyyy、mm、dd、hh24、mi、ss、day
decode(条件,值1,返回值1,值2,返回值2,…值n,返回值n,缺省值)
nvl:nvl(string1, replace_with)
mod(m,n): m/n的余数
round(n,p): 四舍五入
length 长度、
lower小写、
upper大写,
to_date转化日期,
to_char转化字符
to_number转变为数字
ltrim/rtrim/trim©: 去左/右/中 空格
substr(c,p,n):截取字符串,从p位开始截,包含p位,截取n位
add_month增加或者减掉月份、
4、KETTLE内存溢出解决方案
在kettle的运行路径中,用文本编辑器打开Spoon.bat
将其中字段为:-Xmx1024m 加大最好是256的整数倍;
修改字段:MaxPermSize 最大值,运行时最大
修改默认缓存条数(默认为1万)
双击Transformation空白地方,会弹出一个界面,修改Nr of rows in rowset值:
5、kettle中黄色的锁,绿色的对勾,红色的停止代表的意思
黄色的锁:表示不论上一步是否执行成功,将会继续向下执行,下一步可以正常执行
绿色的对勾:表示只有当上一步的任务执行成功并且没有任何错误的时候才会执行下一步
红色停止:表示当上一个作业项的执行结果为假或者没有成功执行时,执行下一个作业项
双斜线:并行启动下一个条目,右键菜单launch next entries in parallel可以设置
6、数仓架构
贴源层:ODS (Operation data store) 直接接入源数据的:业务库、埋点日志、消息队列等
数据明细层:DWD(Data Warehouse Detail)业务层和数据仓库层的隔离层,保持和ODS层相同颗粒度,进行数据清洗和规范化操作:去空/脏数据、离群值等
数据中间层:DWM(Data WareHouse Middle)在DWD的基础上进行轻微的聚合操作、算出相应的统计指标、聚合之后会生成中间表
数据服务层:DWS(Data WareHouse Servce)在DWM的基础上,整合汇总成一个主题的数据服务层,汇总结果通常是宽表
数据应用层:ADS (Application data service)供数据分析和挖掘使用
宽表概念: 通常是指业务主题相关的指标、维度、属性关联在一起的一张数据库表。
优点:用户使用方便,通过一张表以及对应标签、维度的筛选就可以得到对应的数据。
缺点:如果遇到废弃字段、新增字段、修改逻辑等需求,数据开发人员维护成本较高。
拉链表概念:记录历史数据的每个状态,记录一个事物从开始,一直到当前状态的所有变化的信息;拉链表通常是对账户信息的历史变动进行处理保留的结果。”
7、Oracle的五种约束
非空(NOT NULL)约束:所定义的列不绝对不能为空;
主键(PRIMARY KEY)约束:唯一的标识表中的每一行;
唯一(UNIQUE)约束:每列字段的值不能相同;
外键(FOREIGN KEY)约束:用来维护从表与主表之间的引用完整性;
条件(CHECK)约束:表中每行都要满足该约束条件。
8、oracle与mysql的区别
1、Oracle是大型数据库,而MySQL是中小型数据库。
2、Oracle的内存占有量非常大,而mysql非常小
3、MySQL支持主键自增长,指定主键为auto increment,插入时会自动增长。Oracle主键一般使用序列。
4、group by用法:MySQL中group by在select语句中可以随意使用,但是在Oracle中如果查询语句中有组函数,那其他列名必须是组函数处理过的或者是group by子句中的列,否则报错。
5、引号方面:MySQL中用双引号包起字符串,Oracle中只可以用单引号包起字符串。
9、创建索引
优点:
索引是数据库优化
表的主键会默认自动创建索引
大量降低数据库的IO磁盘读写成本,极大提高了检索速度
索引事先对数据进行了排序,降低查询是数据排序的成本,降低CPU的消耗
缺点:
索引本身也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也要占用空间
索引表中的内容,在业务表中都有,数据是重复的,空间是“浪费的”
虽然索引大大提高了查询的速度,但反向影响了增、删、改操作的效率。如表中数据变化之后,会造成索引内容不正确,需要更新索引表信息,如果数据量非常巨大,重新创建索引的时间就大大增加
随着业务的不断变化,之前建立的索引可能不能满足查询需求,需要消耗我们的时间去更新索引
10、对表数据进行分区
优点:
1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
缺点:
分区表相关,已经存在的表没有方法可以直接转化为分区表。不过 Oracle 提供了在线重定义表的功能。
11、exists和in区别
1.in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
一直以来认为exists比in效率高的说法是不准确的。
2.如果查询的两个表大小相当,那么用in和exists差别不大。
3.如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in
12、范式
(1)简单归纳:
第一范式(1NF):如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式
第二范式(2NF):有主键,非主键字段依赖主键;
第三范式(3NF):非主键字段不能相互依赖。
(2)解释:
1NF:原子性。 字段不可再分,否则就不是关系数据库;;
2NF:唯一性 。一个表只说明一个事物;
3NF:每列都与主键有直接关系,不存在传递依赖。
13、Oracle体系架构
内存结构、进程结构、存储结构
内存结构主要由SGA和PGA构成;
进程结构主要由用户进程和ORACLE进程组成;
存储结构主要由逻辑存储和物理存储构成。
SGA系统全局区是Oracle Instance的基本组成部分,在实例启动时分配。是一组包含一个Oracle实例的数据和控制信息的共享内存结构。主要是用于存储数据库信息的内存区,该信息为数据库进程所共享(PGA不能共享的)。它包含Oracle 服务器的数据和控制信息,它是在Oracle服务器所驻留的计算机的实际内存中得以分配,如果实际内存不够再往虚拟内存中写。
PGA是一块包含一个服务进程的数据和控制信息的内存区域。你每启动一个数据库进程就会在内存中创建一个pga,它是独有的,非共享。
14、窗口函数
排名 rank() over(partition by 重复字段 order by )
dense_rank() over(partition by 重复字段 order by)
分页/去重 row_number() over(partition by 重复字段 order by )
累计 sum() over(parition by order by )
同期/上期/环比 lag( 列,n) over(parition by order by )
lead(列,n) over(parititon by order by )
逗号拼接 wm_concat listagg
15、删除重复数据
delete from project a
where a.rowid>(select min(b.rowid) from project b where b.ID=a.ID);
16、SQL优化
(1)最重要的是尽量避免全表扫描
(2)适当的创建索引,考虑在where及order by涉及的列上建立索引(把所建的索引所用列名,用在where语句中,并尽量在条件的最右边,索引相关知识:https://www.jianshu.com/p/f588c41f1cb5)
(3)尽量避免在 where 子句中对字段进行 null 值判断、使用!=或<>操作符、使用 or 来连接条件、对字段进行函数操作等
(4)in 和 not in 也要慎用,否则可能会导致全表扫描
(5)很多时候用 exists 代替 in 是一个好的选择
(6)尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
(7)尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
(8)把条件最小的写在最右边,如果id=?写在最右边
(9)尽量少写子查询,用join语句代替,少写in,like,or
(10) 用UNION替换OR
17、索引、怎么建索引?建在哪个地方?
分类:唯一索引、主键索引、聚集索引
优点:1.大大加快数据的检索速度;
2.创建唯一性索引,保证数据库表中每一行数据的唯一性;
3.加速表和表之间的连接;
4.在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。
缺点:1.索引需要占物理空间。
2.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低了数据的维护速度。
1.索引应该建立在WHERE子句中经常使用的列上。如果某个大表经常使用某个字段进行查询,并且检索的啊行数小于总表行数的5%,则应该考虑在该列上建立索引。
2.对于两个表连接的字段,应该建立索引。
3.如果经常在某表的一个字段上进行Order By的话,则也应该在这个列上建立索引。
4.不应该在小表上建立索引。
18、存储过程
procedure:什么是存储过程?
简单理解,事先创建了一个函数,当需要使用的时候,可以直接调用,无需再重复写sql语句了。
如何使用存储过程?
使用存储过程需要:1)定义存储过程 2)使用已经定义好的存储过程
无参数的存储过程:create procedure <存储过程名称>()begin <sql语句>; end;
3.Oracle是怎样分页的:
Oracle用rownum进行分页
a.最内层sql,查询要分页的所有数据
b.第二层sql,通过rownum伪列确定显示数据的上限,并且给查询的数据添加rownum伪列的值
c.最外层sql,设置显示数据的下限功能:接受参数;调用另一过程;返回一个状态值给调用过程或批处理,指示调用成功或失败;返回若干个参数值给调用过程或批处理,为调用者提供动态结果;
优点:效率高,极大地改善SQL语句的性能、复用性高(只在创造时进行编译,以后每次执行存储过程都不需再重新编译)、安全性高、分布式工作
缺点:调试麻烦(没有像开发程序那样容易)
可移植性不灵活(因为存储过程依赖于具体的数据库)
匿名块
declare
begin
end;
create or replace procudure P_NAME( I_NAME IN TYPE,O_NAME2 OUT TYPE)
is/as
begin
end;
create or replace function F_NAME(I_NAME IN TYPE)
return type
is/as
begin
exception when others then
rollback;
--错误日志
commit;
end;
19、kettle为什么可以连接不同数据库
kettle 是纯 java 开发,开源的 ETL工具,用于数据库间的数据迁移。可以在 Linux、windows、unix 中运行。有图形界面,也有命令脚本还可以二次开发。
因为kettle是用java代码编写的,java代码中的jdbc可以根据不同的jar包连接数据库。
20、Ltrim、Rtrim与Trim的区别
Ltrim
返回不带前导(light)空格的字符串副本
Rtrim
返回不带后续(right)空格的字符串副本
Trim
返回不带前导和后续空格的字符串副本
21、锁表发生在insert update 、delete 中
A程序执行了对 tableA 的 insert ,并还未 commite时,B程序也对tableA 进行insert 则此时会发生资源正忙的异常 就是锁表
锁表常发生于并发而不是并行(并行时,一个线程操作数据库时,另一个线程是不能操作数据库的,cpu 和i/o 分配原则)
为什么要引入锁:当多个用户同时对数据库的并发操作时会带来以下数据不一致的问题
分类:从数据库管理的角度对锁进行划分:共享锁,排它锁
共享锁:对同一个数据,多个读操作可以同时进行,互不干扰
排他锁:如果当前写操作没有完毕,则无法进行其他操作
按粒度划分:行锁、页锁、表锁
查看是否锁表
select sess.sid,
sess.serial#,
lo.oracle_username,
lo.os_user_name,
ao.object_name,
lo.locked_mode
from v$locked_object lo,
dba_objects ao,
v$session sess
where ao.object_id = lo.object_id and lo.session_id = sess.sid;
解锁
alter system kill session '628,63405';
22、如何加表空间
利用“alter database datafile 表空间位置 resize 大小”增加表空间大小;
用“alter tablespace 表空间名 add datafile 数据文件地址 size 数据文件”增加表空间大小
第一步:查看表空间的名字及文件所在位置:
select tablespace_name, file_id, file_name, round(bytes/(1024*1024),0) total_space from dba_data_files order by tablespace_name
第二步:增大所需表空间大小:
方法一:
alter database datafile '表空间位置'resize 新的尺寸
例如:
alter database datafile '\\oracle\\oradata\\anita_2008.dbf' resize 4000m
方法二:增加数据文件个数
alter tablespace 表空间名称add datafile '新的数据文件地址' size 数据文件大小
例如:
alter tablespace ESPS_2008 add datafile '\\oracle\\oradata\\anita_2010.dbf' size 1000m
方法三:设置表空间自动扩展。
alter database datafile '数据文件位置' autoextend on next 自动扩展大小maxsize 最大扩展大小
例如:
alter database datafile '\\oracle\\oradata\\anita_2008.dbf' autoextend on next 100m maxsize 10000m
23、触发器
create or replace trigger 触发器名
before|after insert|update|delete on 表名
for each row()
declare
begin
end;
包头
procudure P_NAME( I_NAME IN TYPE,O_NAME2 OUT TYPE)
包体
procudure P_NAME( I_NAME IN TYPE,O_NAME2 OUT TYPE)
is/as
begin
end;
24、游标
隐式游标
insert
select;
update
delete
显示游标
reate or replace procedure p_cursor as
---statment:cur_emp
cursor cur_emp is
select * from emp;
v_emp_1 emp%rowtype;---和emp表具有相同的列及对应的数据类型
begin
open cur_emp;
loop
fetch cur_emp
into v_emp_1; --获取每一行记录给v_emp
exit when cur_emp%notfound;--游标的行如已获取完则推出循环
dbms_output.put_line(v_emp_1.empno);
end loop;
close cur_emp;
end;
25、oracle命名规则
1、Oracle 表名命名规则
1)必须以字母开头
2)长度不能超过 30 个字符
3)避免使用 Oracle 的关键字
4)只能使用 A-Z、a-z、0-9、_、#、$
2、使用带有特殊符号的表名
Oracle 在创建表时,表名会自动转换大写。Oracle 对表名大小写不敏感。 如果在定义表名时含有特殊符号,或者用小写字母来定义表名则需要在表名两侧添加双引号。但是不建议大家使用双引号定义表名,因为后期对表的操作会有所不方便。
26、kettle为什么可以跨平台
纯java编写的,因为java虚拟机能跨平台
27、oracle分页
Oracle用rownum进行分页
a.最内层sql,查询要分页的所有数据
b.第二层sql,通过rownum伪列确定显示数据的上限,并且给查询的数据添加rownum伪列的值
c.最外层sql,设置显示数据的下限
select * from
(select a.*,rownum r from (select * from 表名 where 条件 order by 列) a where rownum <= 页数 * 条数) b where r >(页数-1)*条数
数据库常见面试题总结
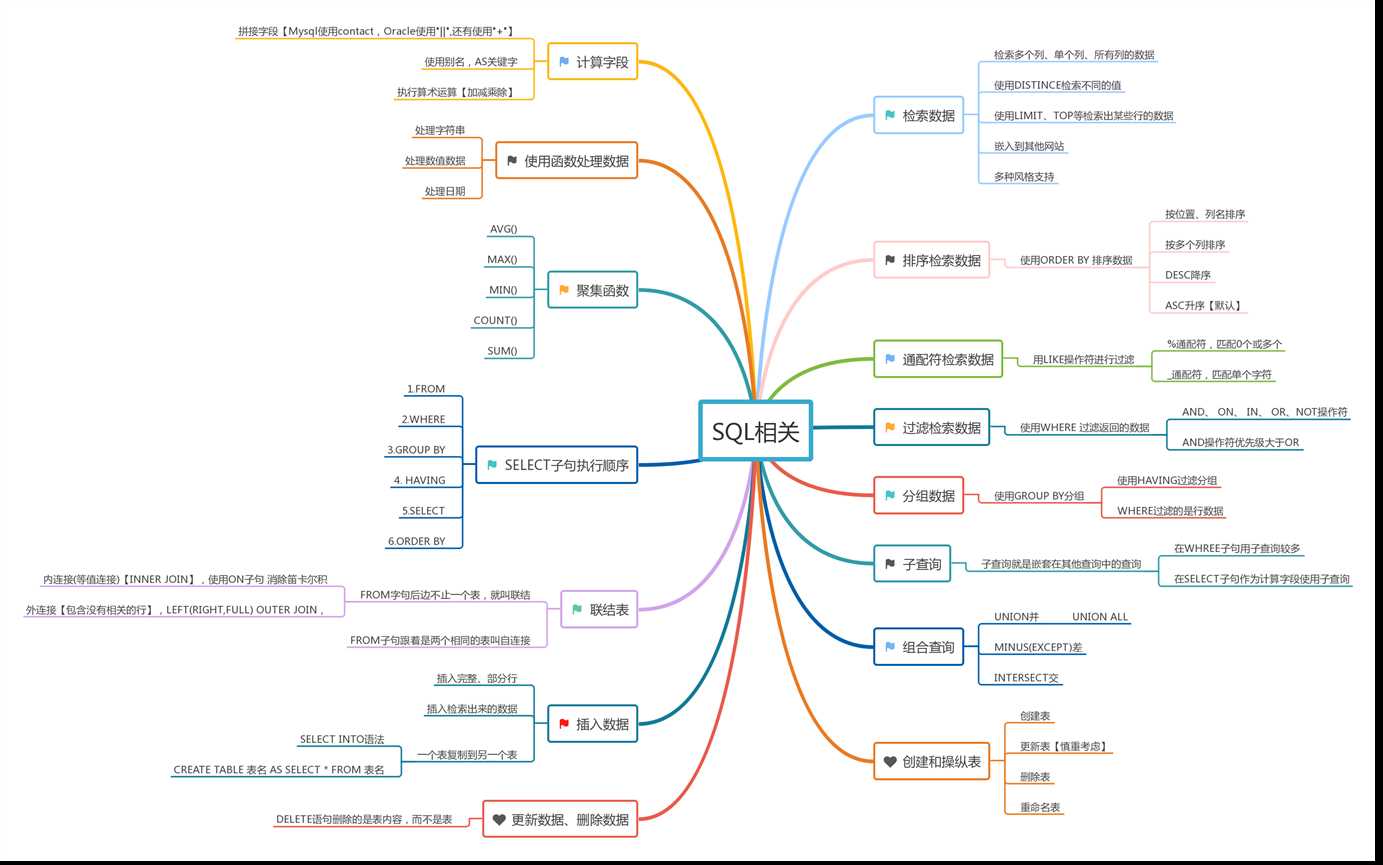
参考如下:
数据库常见面试题(开发者篇)
数据库优化
SQL数据库面试题及答案
常见面试题整理--数据库篇
以上是关于数据库开发常见面试题的主要内容,如果未能解决你的问题,请参考以下文章