博客系统(前后端分离版)
Posted fiance111
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了博客系统(前后端分离版)相关的知识,希望对你有一定的参考价值。
博客系统的具体实现
文章目录
在正式写后端程序之前,我已经将博客系统的前端最基本的页面写好,详情可以见我的gitee
https://gitee.com/dengchuanfei/vscode_demo/tree/master/blog_system
软件开发的基本流程
- 可行性分析
- 需求分析
- 概要设计
- 详细设计
- 编码
- 测试
- 发布
具体实现的八大功能
- 实现博客列表的展示功能
- 实现博客详情的展示功能
- 登录功能
- 强制用户登录
- 显示用户的信息
- 实现注销
- 发布博客
- 删除博客
数据库设计
写之前首先要进行规划,要做到“谋定而后动”
首先进行“数据库设计”,也就是想清楚需要几个库,几张表,每个表长啥样(属性是干什么的,是什么类型)
需要找到实体,然后分析实体之间的关联关系,再思考表的属性
这里业务比较简单,所以只需要两张表
博客表blog (blogId, tittle, content, postTime, userId)
用户表user (userId username password)
创建数据库
先建一个数据库,往里面添加数据
-- 拿到的数据库很可能并不干净,所以创建之前要确保之前没有同名的,还要删除同名的,注意:这是十分危险的操作,所以务必谨慎使用!!!
create database if not exists java_blog_system;
use java_blog_system;
drop table if exists blog;
-- 注意这里添加属性是使用()
create table blog(
blogId int primary key auto_increment,
title varchar(256),
content text,
postTime datetime,
--userId是文章作者的ID
userId int
);
drop table if exists user;
create table user
(
userId int primary key auto_increment,
username varchar(50),
password varchar(50)
);
-- 添加几个数据,测试一下
insert into blog values(null,"这是第一篇博客","从今天开始我要好好写代码,好好上课",now(),1);
insert into blog values(null,"这是第二篇博客","我要好好写代码,好好上课",now(),1);
insert into user values(null, "zhangsan","123");
insert into user values(null, "lisi","123");
这里设计的content是text类型的,text能放64KB的内容,一般是够博客使用的了,博客中的截图和博客文字不是存储在一起的,所以不用担心截图放不下
注意: 在SQL中的注释是 “-- ”,在–后面还有一个空格!
操作数据库
引入依赖
首先要先引入maven依赖,在.xml的中引入依赖
去中央仓库中,搜索servlet API(3.1.0),mysql connect Java(5.1.49), jackson Databind(2.13.4.2)(将JSON格式进行转换)
封装DataSource
由于DataSource只有一份,所以使用单例模式来实现会比较好
import com.mysql.jdbc.jdbc2.optional.MysqlDataSource;
import javax.sql.DataSource;
import javax.xml.crypto.Data;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
//使用这个类来封装DataSource,使用单例模式(懒汉模式 + 多线程判断)
//实现数据库的连接和断开
public class DBUtil
private static volatile DataSource dataSource = null;
public static DataSource getDataSource()
//第一次判断是否需要加锁
if (dataSource == null)
synchronized (DBUtil.class) //针对类对象加锁
//第二次判断是会否需要new对象
if (dataSource == null)
dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setURL("jdbc:mysql://127.0.0.1:3306/java_blog_system?characterEncoding=utf8&&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("1111");
return dataSource;
//建立连接
private static Connection getConnection() throws SQLException
return getDataSource().getConnection();
//关闭连接
//建立连接的顺序是connection statement resultSet,所以关闭的顺序是反着的
private static void close(Connection connection, Statement statement, ResultSet resultSet)
if (resultSet != null)
try
resultSet.close();
catch (SQLException e)
e.printStackTrace();
if (statement != null)
try
statement.close();
catch (SQLException e)
e.printStackTrace();
if (connection != null)
try
connection.close();
catch (SQLException e)
e.printStackTrace();
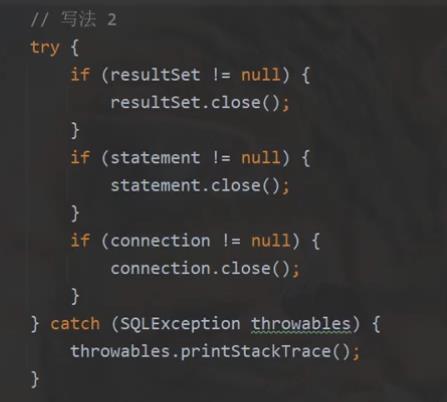
在关闭资源的时候, 要是像这样直接使用依次try catch就会导致一旦上面的抛出异常,下面的就不会被执行到了,此时就会导致资源泄漏,很严重
要是使用的是throws相当于上面的情况,后面的代码还是不会执行,导致资源泄漏
所以还是应该 细分一下,多用几个try catch,来保证3个对象都关闭了
创建实体类
一个实体类对象就对应表中的一条记录
表中的属性怎么写,实体类就这么写
这里需要创建2个实体类 User 和 Blog
里面需要有属性和getter和setter方法, IDEA快捷键是alt + fn + insert
import java.security.Timestamp;
public class Blog
private int blogId;
private String tittle;
private String content;
//mysql中的datetime和timestamp类型在java中都是使用Timestamp表示的
private Timestamp postTime;
private int userId;
public int getBlogId()
return blogId;
public void setBlogId(int blogId)
this.blogId = blogId;
public String getTittle()
return tittle;
public void setTittle(String tittle)
this.tittle = tittle;
public String getContent()
return content;
public void setContent(String content)
this.content = content;
public Timestamp getPostTime()
return postTime;
public void setPostTime(Timestamp postTime)
this.postTime = postTime;
public int getUserId()
return userId;
public void setUserId(int userId)
this.userId = userId;
public class User
private int userId;
private String username;
private String password;
public int getUserId()
return userId;
public void setUserId(int userId)
this.userId = userId;
public String getUsername()
return username;
public void setUsername(String username)
this.username = username;
public String getPassword()
return password;
public void setPassword(String password)
this.password = password;
将JDBC增删改查封装起来
这里创建的是BlogDao和UserDao类,这里的DAO是 Data Acess Object 数据访问对象
也就是说访问数据库的操作就可以使用这几个DAO对象来进行
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
//封装关于博客的相关操作
public class BlogDao
//插入博客--发布博客
public void insert(Blog blog)
Connection connection = null;
PreparedStatement statement = null;
//此处只要判断改变的行数是不是1就行了,所以没有resultSet
try
//1.建立连接
connection = DBUtil.getConnection();
//2.构造SQL
//sql对应着blog的属性
//blogId tittle content postTime userId
String sql = "insert into blog values (null, ? , ?, now(), ?)";
statement = connection.prepareStatement(sql);
statement.setString(1, blog.getTittle());
statement.setString(2, blog.getContent());
statement.setInt(3, blog.getUserId());
//3.执行sql
int ret = statement.executeUpdate();//executeUpdate的返回值是修改的行数
if (ret != 1)
System.out.println("博客插入失败!");
else
System.out.println("博客插入成功!");
//4.释放相关的资源--但是这里还是不适合,要是上面代码抛异常了,这里就会导致资源没有释放,资源泄露
catch (SQLException e)
e.printStackTrace();
finally
//方法哦finally就一定会执行到了,但是connection和statement是局部变量,所以就将这两个放到最外面,先置为null
DBUtil.close(connection, statement, null);//这里没有涉及到resultSet,所以填null
//查询一个博客--博客详情页
public Blog selectOne(int blogId)
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try
//1.建立连接
connection = DBUtil.getConnection();
//2.构造SQL
String sql = "select * from blog where blogId = ?";
statement = connection.prepareStatement(sql);
statement.setInt(1, blogId);
//3.执行SQL
resultSet = statement.executeQuery();
//遍历结果集合
if (resultSet.next())
Blog blog = new Blog();
blog.setBlogId(resultSet.getInt("blogId"));
blog.setTittle(resultSet.getString("tittle"));
blog.setContent(resultSet.getString("content"));
blog.setPostTime(resultSet.getTimestamp("postTime"));
blog.setUserId(resultSet.getInt("userId"));
return blog;
catch (SQLException e)
e.printStackTrace();
finally
//关闭资源
DBUtil.close(connection,statement,resultSet);
return null;//要是没有找到直接返回null就行
//查询所有博客--博客展示页
public List<Blog> selectAll()
List<Blog> blogs = new ArrayList<>();
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try
//1.建立连接
connection = DBUtil.getConnection();
//2.构造SQL
String sql = "select * from blog";
statement = connection.prepareStatement(sql);
//3.执行SQL
resultSet = statement.executeQuery();
//遍历结果集合,这里使用的是while循环来寻找
while(resultSet.next())
Blog blog = new Blog();
blog.setBlogId(resultSet.getInt("blogId"));
blog.setTittle(resultSet.getString("tittle"));
blog.setContent(resultSet.getString("content"));
blog.setPostTime(resultSet.getTimestamp("postTime"));
blog.setUserId(resultSet.getInt("userId"));
blogs.add(blog);//将所有搜到的blog都添加到blogs中
catch (SQLException e)
e.printStackTrace();
finally
//4.关闭资源
DBUtil.close(connection,statement,resultSet);
return blogs;
//删除博客
public void delete(int blogId)
Connection connection = null;
PreparedStatement statement = null;
try
//1.建立连接
connection = DBUtil.getConnection();
//2.构造SQL
String sql = "delete from blog where blogId = ?";
statement = connection.prepareStatement(sql);
statement.setInt(1, blogId);
//3.执行sql
int ret = statement.executeUpdate();//executeUpdate的返回值是修改的行数
if (ret != 1)
System.out.println("博客删除失败!");
else
System.out.println("博客删除成功!");
//4.释放相关的资源--但是这里还是不适合,要是上面代码抛异常了,这里就会导致资源没有释放,资源泄露
catch (SQLException e)
e.printStackTrace();
finally
//方法哦finally就一定会执行到了,但是connection和statement是局部变量,所以就将这两个放到最外面,先置为null
DBUtil.close(connection, statement, null);//这里没有涉及到resultSet,所以填null
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class UserDao
//根据用户名来查询用户--登录模块
//隐含条件:用户名必须要是唯一的
public User selectByName(String username)
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try
//1.建立连接
connection = DBUtil.getConnection();
//2.构造SQL
String sql = "select * from blog where username = ?";
statement = connection.prepareStatement(sql);
statement.setString(1, username);
//3.执行SQL
resultSet = statement.executeQuery();
//遍历结果集合
if (resultSet.next())
User user = new User();
user.setUserId(resultSet.getInt("userId"));
user.setUsername(resultSet.getString("username"));
user.setPassword(resultSet个人博客系统(前后端分离)
努力经营当下,直至未来明朗!
文章目录
普通小孩也要热爱生活!
一、项目简介
个人博客系统采用前后端分离的方法来实现,同时使用了数据库来存储相关的数据,同时使用tomcat进行项目的部署。前端主要有四个页面构成:登录页、列表页、详情页以及编辑页,以上模拟实现了最简单个博客列表页面。其结合后端实现了以下的主要功能:登录、编辑博客、注销、删除博客、以及强制登录等功能。
但是该项目没有设计用户注册功能,只能提前在数据库中存储用户信息后经过校验登录;并且用户头像不能自己设定,在进行前端页面的书写过程中已经将头像的图片写为静态了;而用户信息中的文章数以及分类数也没有在后端中具体实现,直接在前端页面中写为了静态的。
二、项目效果
必须在开着tomcat的情况下才能进行以下页面的操作。
-
登录页面

-
列表页面 / 主页

-
博客详情页

-
编辑页

三、项目实现
1. 软件开发的基本流程
① 可行性分析;
② 需求分析:明确程序要解决什么问题,做成啥样,都有啥功能。(实际开发中是产品经理制定的)
③ 概要设计
④ 详细设计
⑤ 编码
⑥ 测试
⑦ 发布
2. 博客系统 需求分析
① 实现博客列表页的展示功能
② 实现博客详情页的显示功能
③ 登录功能(暂时不实现注册)
④ 限制用户权限(强制要求登录)
⑤ 显示用户信息
⑥ 实现注销(退出登录)
⑦ 发布博客
⑧ 删除博客
3. 博客系统 概要设计
(写代码要“谋定而后动”)
其实这里主要是【数据库设计】
当前我们的业务比较简单,只需要两个表:
① 博客表blog(blogId,title,content,postTime,userId)
② 用户表user(userId,userName,password) (其中Gitee地址以及文章分类这样的功能先不考虑)
4. 创建maven项目
注:① auto-increment是从1开始的
② text的大小是64kb,博客内容一般不太会超过64kb,而博客中的截图不是和文本一起存储的。
5. 编写数据库操作的代码
- 引入依赖:servlet3.1.0、mysql5.1.49、jackson2.13.4.1
- 封装数据库的DataSource(单例模式+线程安全)
除了封装DataSource,把数据库的建立连接、断开连接也都进行封装。
补:
① ctrl+alt+t:surround功能
② Connection是 java.sql.Connection,不是 java.mysql.Connection
- 在关闭释放资源的时候,写法一是将三个需要释放的连接分别try…catch, 写法二是三个需要释放的连接只使用 一个try…catch连接。
写法一更好。
理由:写法一里如果某个环节抛出异常,不影响继续执行后续的close操作。而写法二一旦出现异常就会进入catch,此时后续的close就执行不到了,会造成资源泄露。
(直接抛出异常throws也是同理写法二,会造成资源泄露。)
- 根据需求创建实体类
一个实体类对象就对应表里的一条记录。
实体类怎么写?
——表结构怎么写,实体类就怎么写。
mysql中的datetime和timestamp类型都是在java中使用TimeStamp表示的。
- 针对上述实体类涉及到的 增删改查 进行进一步的封装,也就是把jdbc代码封装一下。
Dao: Data Access Object
访问数据库的操作就可以使用这几个Dao对象来进行。
statement.executeUpdate(); 返回的数据表示影响到几行
6. 进行前后端交互(重点)
让页面发起http请求,服务器返回http响应。(需要约定好http请求是啥样的,响应是啥样的)
1)博客列表页:
① 不要写死数据,而是让页面从数据库中获取到当前的博客列表。
(先将前端的所有相关文件粘贴到webapp目录下)
② 页面在加载的时候,通过ajax发起http请求,从服务器获取到博客列表数据。

③ 当web出现问题的时候,首先想到的就是“抓包”,看是前端原因还是后端原因。(如果有的没有抓取到就进行强制刷新ctrl+f5)
注:fiddler中出现的favicon是浏览器发送的请求,是获取页面图标的,如果该网站没有图标就会出现404

① 在前后端分离的程序中,获取页面和获取页面中的数据是分开的请求。
② 如果是只有页面没有数据,且抓包也抓不到获取数据的请求,那就说明是前端代码出问题了,前端没有正确发送ajax请求。
注:方法只有被调用之后才会生效!!
一定要仔细!!保证不会出现空指针异常!!
问题以及解决:
① 我们想要呈现的是格式化的时间,但是会发现此时出现的是时间戳!

原因:
通过抓包查看发现服务器返回的响应数据就是一个时间戳

服务器代码中,是将从mysql数据库中查询到的时间放到了postTime这个属性中,然后又通过jackson将其转为json字符串返回;即:在转json的过程中,将其变为了时间戳。

解决方法:
那么jackson是如何获取到Blog对象中的时间戳的? 通过getter方法来获取的。
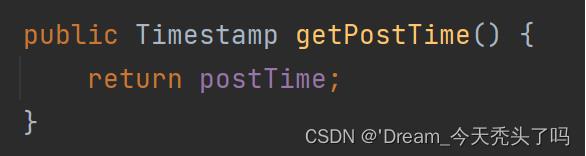
所以就魔改getter方法,让该方法返回一个String,而不是TimeStamp。String就是一个格式化好了的时间日期!

① 这个SimpleDateFormat类可以将时间戳转为格式化的时间!
(使用示例可以参考:SimpleDateFormat类使用)

② 需要把时间戳转成格式化时间,具体啥格式需要在构造方法中进行指定!
③ (参数格式可以自己指定,但是具体字母时不能改变的,每个都有自己的含义,如MM表示月份,mm表示分钟,具体的参数含义在使用的时候自己上网确认!)

(格式化时间日期)
② 另外,又发现问题:列表中的文章顺序应该是最近发布的在最上面,但是目前是按先发布排上面的顺序来排列的。

所以,解决方法:在查询的时候加上个排序。

③ 此时,如果插入的博客内容比较长的话就会占据很大篇幅的列表页,因为把整个正文篇幅都显示出来了;但是按理来说,博客列表页要显示的是正文的 “摘要”信息。

(长文)
解决方法:
针对博客的列表页中的内容进行截断,长度达到一定数值就取出一部分子串。(长度自己规定就ok)


(效果)
【注】当我们的程序出现了问题,该如何动手解决?
① 一定要梳理清楚出现问题的代码的流程
② 能够找到相关代码 (调试,不是对照着找!!)
2)实现博客详情页
① 点击查看全文就会跳转到详情页,并且看到详情页中对应的博客正文。
② 处理方式:
点击查看全文,此时就会发起一个get请求,该请求是在请求blog_detail.html这个页面;此时还需要告诉服务器我们请求的是哪个博客!
约定:在请求页url中加上query string来进行具体哪个博客的标识。(在生成“查看全文”按钮的时候就已经添加了query string进行标识了)
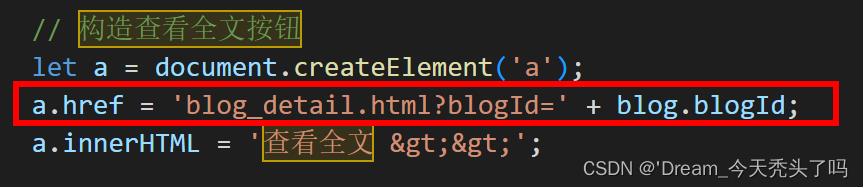
③ 进入博客详情页之后,需要让博客详情页再次发起ajax请求,向服务器获取到当前blogId对应的博客内容;再由博客详情页将拿到的数据添加到浏览器页面上。
④ 操作步骤:
1)约定前后端交互接口
在博客详情页中发起ajax请求,获取到具体的博客内容。

2)实现服务器代码
按照上述约定来返回数据
3)实现客户端代码
让页面发起的ajax请求来获取到博客数据
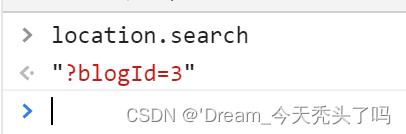
【注】location.search 用来获取query string
(每次修改代码都要重启服务器)
但是会发现当点击“查看全文”后,所跳转的页面还是之前的结果,这是触发了浏览器的缓存!
① 理由:
浏览器需要通过网络从远程服务器获取到当前的页面数据,可能比较耗时;此时为了提高效率,做法就是让浏览器把必要的数据进行缓存;下次访问就不必访问网络了,而是直接读取缓存。
② 做法:
所以,为了保证数据从网络上获取就需要进行强制刷新ctrl+f5.
如果发现前端页面有问题,就fn+f12调出控制台查看异常情况。
补充:
① VS里的编译器是cl.exe, IDEA的编译器是javac… 编译器一般都是命令行的。
②IDE是集成开发环境, IDE != IDEA
问题:
① 博客正文期待是markdown格式的(毕竟博客编辑页是一个markdown编辑器,提交的数据是markdown格式的,数据库中存储的也是markdown格式的,所以最终显示也应该是markdown格式的结果)

② 显示结果是纯文本(不符合预期,预期是渲染过的markdown)

解决方法:
使用editor.md这个库来完成渲染。
在blog_detail.html中引入editor.md依赖



(渲染之后)
如果想要内容的背景显示半透明效果,修改设置一下就ok。

(这个效果不好)

(transparent的意思就是让当前元素完全应用父元素的背景)
3)博客登录
登录逻辑:
① 用户访问login.html,输入用户名和密码
② 点击登录按钮后发起一个请求,将用户名和密码提交给服务器
③ 服务器对身份进行验证,验证成功就跳转到博客详情页
① 约定前后端接口

(注:请求再前端,响应在后端)
② 编写前端代码
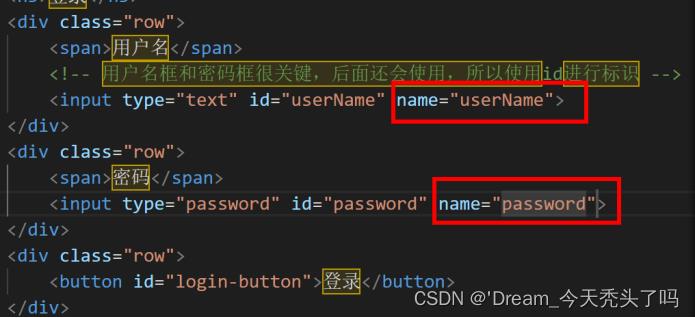
一定要指定name属性,为了与键值对中的键对应!
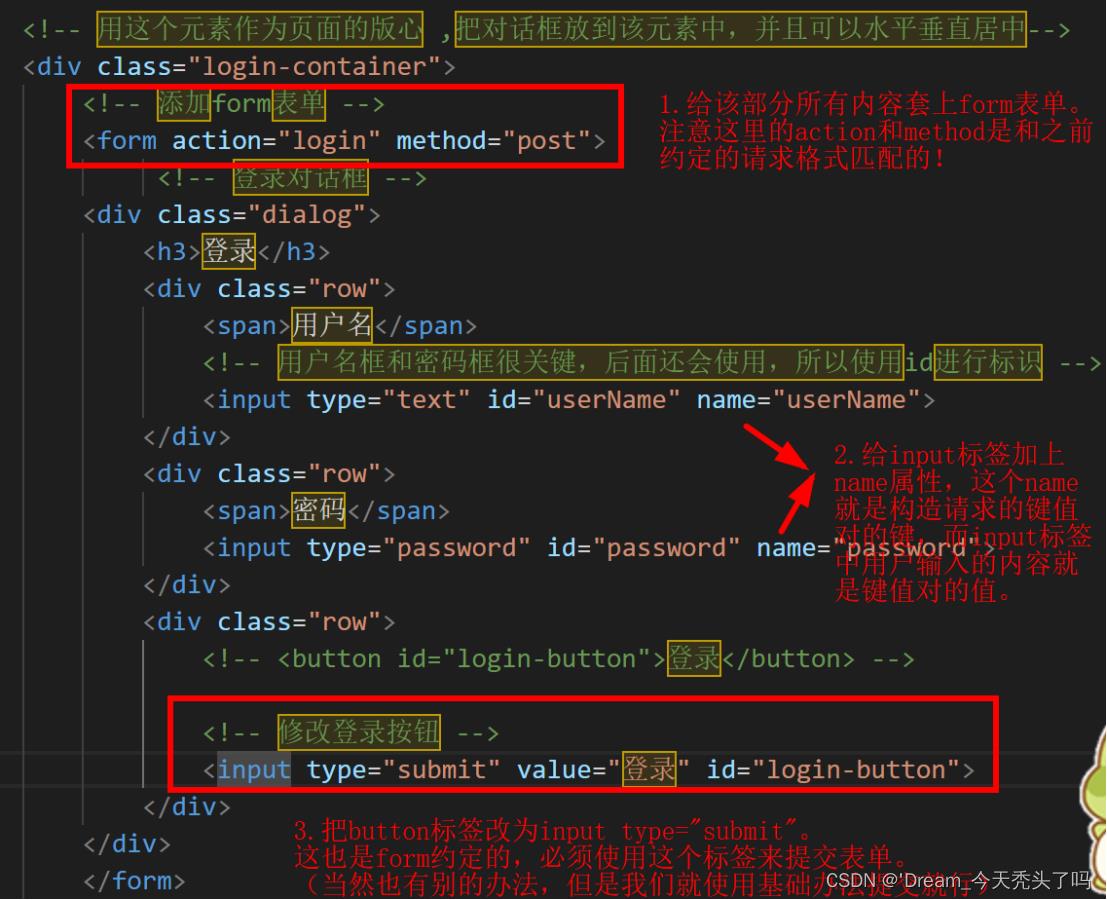
③ 编写后端代码
LoginServlet
4)实现在博客列表页、详情页和编辑页中强制登录后才能访问。(常见)
业务逻辑:
在博客列表页、详情页和编辑页中,都在页面加载时发起一个ajax请求,这个ajax请求就是从服务器获取当前的登录状态。如果当前是未登录就直接重定向到登录页面,如果是已经登录则不做任何处理。
① 前后端交互接口:

② 前端代码:判定状态码是200还是403,如果是200就无事发生,403就强行跳转

③ 后端代码:
只是单纯的查看当前用户是否为登录状态,即:获取会话以及里面的user对象,如果能拿到就已经登录过返回200,否则返回403.

因为 登录限制及跳转 在很多页面中都使用,但是我们没必要进行重复性的工作,所以直接在前端代码中新建一个文件夹js,并新建文件 app.js 来存储这些重复的代码,以此来实现代码的复用。
5)在列表页和详情页中动态显示用户信息
逻辑设定:
① 博客列表页:在页面进行加载的同时从服务器获取当前登录的用户信息,并把该信息显示到页面上。
② 博客详情页:在页面进行加载的同时从服务器获取博客作者用户信息,并把该信息显示到页面上。
① 前后端交互接口:

② 编写后端代码

(使用了两次sql查询,其实是可以使用一条sql搞定的:联合查询 or 子查询)
③ 编写前端代码

【小结】写web程序套路
其实以上实现的功能所做的事情都差不多:
① 业务逻辑梳理
② 设计前后端交互
③ 编写前端代码:基本上是ajax(发请求)+ dom(根据请求显示到页面上)操作
④ 写后端代码:基本上就是servlet + jdbc + jackson操作
(前后端编写代码顺序不定)
补充:
① 图片存入数据库其实存的是图片的路径,而图片是以文件的形式存到硬盘上。
② 不太建议将图片直接存入数据库,图片是二进制数据,对于关系型数据库是不太友好的。
6)注销(退出登录状态)
Windows的注销其实也就是退出登录状态sign out。
业务逻辑:
① 在博客列表页/详情页/编辑页的导航栏里都有 注销 按钮,并且我们的实现方式是一个a标签,点击的时候就会给服务器发送一个http请求(不是ajax,但是如果想要使用ajax做也是OK的)
② 发送的http请求就是告诉服务器咱们要退出登录了,服务器就会把对话中的user对象给删除,同时重定向到登录页。
③ 注:删除的是会话中的user对象而不是HttpSession对象,因为HttpSession没有一个直接用于删除的方法(Servlet没有提供),虽然可以通过设置过期时间的方式来删除会话,但是并不是一个好的选择;另外,我们在实现判定登录状态的条件是HttpSession存在&&user存在,所以这里可以直接删除user对象
① 前后端交互接口

② 前端代码
只需要给a标签的href属性设置个值就行,不需要写任何的js代码。
后端代码:
LogoutServlet
7)发布博客
业务逻辑:
在博客编辑页中获取到用户提交的数据并保存到数据库中。用户在博客编辑页中会填写标题和正文,在点击“发布文章”后发起一个http请求,然后服务器收到这些数据后构造一个Blog对象并插入数据库。
Blog对象:

① blogId自动生成
②title和content是用户提交的内容
③ postTime直接就是插入数据库的时间,不用手动指定,即:now()
④ userId:发布文章的时候登陆的用户就是作者,登陆的用户的信息是在HttpSession中的。
① 前后端交互接口:

② 实现服务器代码(响应)
【补充】
正常情况下,能够发起POST /blog请求应该是在已经登录状态下了,那为何还要再次检验是否是已经登录状态呢?
理由:
① 万一有手动构造呢?如使用postman直接构造请求,此时就绕开了登录直接插入博客数据了。
② 构造博客对象是需要知道userId的,此时只有知道了谁在登录才能够知道文章作者(userId)。而该userId就来自与HttpSession对象getAttribute。
③ 前端代码(客户端代码)的实现:
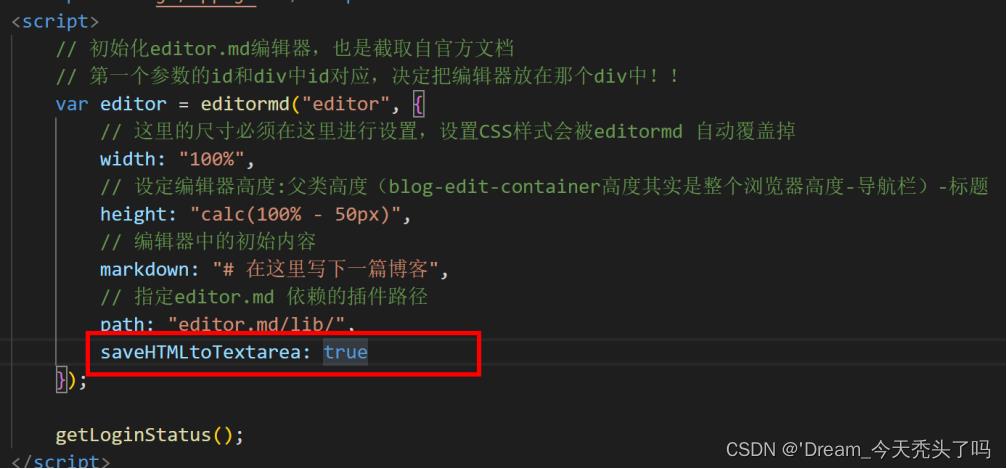
(也不涉及js的编码)

① 当写上< textarea name=”content” style=”display:none”> < /textarea>的时候,用户在页面上输入的markdow内容就能够被textarea自动获取到;但是需要给初始化editor.md时加上一个新的属性:saveHTMLtoTextarea: true
② 此时发现一个问题:Markdown编辑器页面大小缩水了

这显然是前端样式的问题,所以去查看前端样式(fn+f12)

(发现blog-edit-container正常,但是form那儿就缩水了)
③ 也就是说:form标签没有指定高度,此时自身就缩水,导致内部的子元素也就缩水了。
解决方法:给form指定高度,和父元素一样高就行。

8)删除博客
业务逻辑:
① 作者只能能删除自己的文章,不能删除别人的文章。
② 暂时没有管理员这个角色
③ 在博客详情页导航栏加上 删除按钮,当点击该按钮的时候就会触发删除操作。是通过a标签href属性发起的一个HTTP GET请求。
④ 删除的时候会进行校验:如果当前登录的用户就是文章作者才能够真正删除,否则就提示没有删除权限。
① 前后端交互接口:

② 实现服务器(后端代码):
大部分代码都是在判定非法情况,这是一个很好的意识。
③ 实现浏览器(前端)代码:
① 直接加个a标签

② 但是会发现:点击删除的时候url中是没有带上blogId的,这就导致无法删除。
③ 所以:可以在页面加载的时候通过js代码稍微修改一下href属性中的内容,使url中带上blogId。

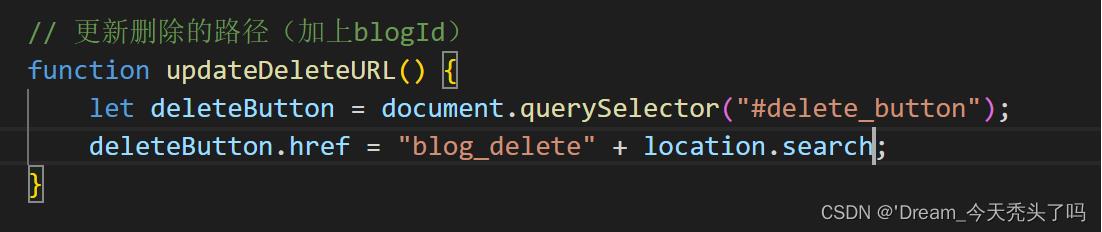
③ 注意区分:location.href(完整路径) 和 location.seach(query string)

location是dom api中自带的全局对象(js中的全局对象)
四、项目代码
-
环境:
IDEA + MySQL + smart tomcat + VSCode
-
项目布局

-
项目代码:
Gitee链接:个人博客系统
总结
- 在实现简单个人博客系统的过程中遇到了很多问题,其中的 前后端交互接口的约定 极其重要!!
- 只有不断重复、多练习才能更好地理解项目以及其实现。

有任何建议以及问题可以 直接私信 或 直接评论 嗷!
欢迎小窗踢踢! or 评论区见!
以上是关于博客系统(前后端分离版)的主要内容,如果未能解决你的问题,请参考以下文章