Redis 实现限流策略
Posted 完了学不下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis 实现限流策略相关的知识,希望对你有一定的参考价值。
除了控制流量,限流还有一个应用目的是用于控制用户行为,避免垃圾请求。
比如在 UGC 社区,用户的发帖、回复、点赞等行为都要严格受控,一般要严格限定某行为在规定 时间内允许的次数,超过了次数那就是非法行为。对非法行为,业务必须规定适当的惩处策略。
如何使用 Redis 来实现简单限流策略?
接口的定义
# 指定用户 user_id 的某个行为 action_key 在特定的时间内 period 只允许发生一定的次数
max_count
def is_action_allowed(user_id, action_key, period, max_count):
return True
# 调用这个接口 , 一分钟内只允许最多回复 5 个帖子
can_reply = is_action_allowed("laoqian", "reply", 60, 5)
if can_reply:
do_reply()
else:
raise ActionThresholdOverflow()解决方案
这个限流需求中存在一个滑动时间窗口,想想 zset 数据结构的 score 值,是不是可以通过 score 来圈出这个时间窗口来。
而且我们只需要保留这个时间窗口,窗口之外的数据都可以砍掉。那这个 zset 的 value 填什么比较合适呢?它只需要保证唯一性即可,用 uuid 会比较浪费空间,那就改用毫秒时间戳吧。
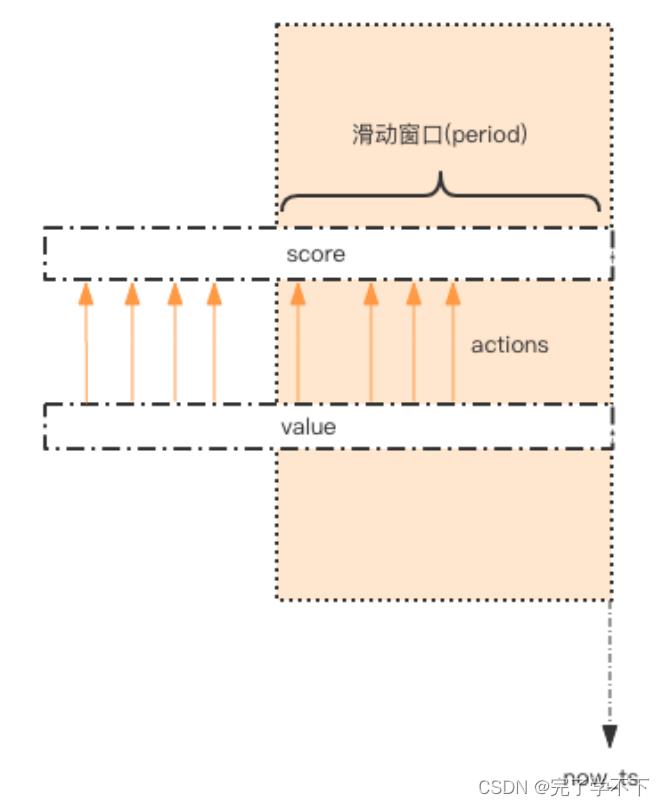
如图所示,用一个 zset 结构记录用户的行为历史,每一个行为都会作为 zset 中的一个 key 保存下来。同一个用户同一种行为用一个 zset 记录。
为节省内存,我们只需要保留时间窗口内的行为记录,同时如果用户是冷用户,滑动时间窗口内的行为是空记录,那么这个 zset 就可以从内存中移除,不再占用空间。
通过统计滑动窗口内的行为数量与阈值 max_count 进行比较就可以得出当前的行为是否 允许。用代码表示如下:
import org.apache.shiro.util.CollectionUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisCallback;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.nio.charset.StandardCharsets;
import java.util.List;
@Component
public class SimpleRateLimiter
@Resource
private RedisTemplate<String, Object> redisTemplate;
public boolean isActionAllowed(String userId, String actionKey, int period, long maxCount)
String key = String.format("hist:%s:%s", userId, actionKey);
long nowMills = System.currentTimeMillis();
List<Object> objects = redisTemplate.executePipelined((RedisCallback<Object>) connection ->
// 打开管道
connection.openPipeline();
byte[] keyBytes = key.getBytes(StandardCharsets.UTF_8);
// 添加命令
connection.zAdd(keyBytes, nowMills
, String.valueOf(nowMills).getBytes(StandardCharsets.UTF_8));
// 清楚无用数据
connection.zRemRangeByScore(keyBytes, 0, nowMills - period * 1000L);
// 判断规定时间内请求数量
connection.zCard(keyBytes);
// 重新设置过期时间
connection.expire(keyBytes, period + 1);
// 关闭管道 不需要close 否则拿不到返回值
// connection.closePipeline();
// 这里一定要返回null,最终pipeline的执行结果,才会返回给最外层
return null;
);
if (!CollectionUtils.isEmpty(objects))
return (Long) objects.get(2) <= maxCount;
return true;
测试:
import com.hcx.common.redisdemo.SimpleRateLimiter;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
class MallCommonApplicationTests
@Autowired
private SimpleRateLimiter limiter;
@Test
void contextLoads()
for (int i = 0; i < 20; i++)
System.out.println("结果:" + limiter.isActionAllowed("laoqian", "reply", 60, 5));
/*
结果:true
结果:true
结果:true
结果:true
结果:true
结果:false
结果:false
结果:false
结果:false
结果:false
结果:false
结果:false
结果:false
结果:false
结果:false
结果:false
结果:false
结果:false
结果:false
结果:false
*/
整体思路就是:每一个行为到来时,都维护一次时间窗口。将时间窗口外的记录全部清理掉,只保留窗口内的记录。
zset 集合中只有 score 值非常重要,value 值没有特别的意义,只需要保证它是唯一的就可以了。 因为这几个连续的 Redis 操作都是针对同一个 key 的,使用 pipeline 可以显著提升 Redis 存取效率。
但这种方案也有缺点,因为它要记录时间窗口内所有的行为记录,如果这个量很大,比如限定 60s 内操作不得超过 100w 次这样的参数,它是不适合做这样的限流的,因为会消耗大量的存储空间。
高级限流算法——漏斗限流

漏斗限流是最常用的限流方法之一,顾名思义,这个算法的灵感源于漏斗(funnel)的结构。
漏洞的容量是有限的,如果将漏嘴堵住,然后一直往里面灌水,它就会变满,直至再也 装不进去。如果将漏嘴放开,水就会往下流,流走一部分之后,就又可以继续往里面灌水。 如果漏嘴流水的速率大于灌水的速率,那么漏斗永远都装不满。
如果漏嘴流水速率小于灌水的速率,那么一旦漏斗满了,灌水就需要暂停并等待漏斗腾空。
所以,漏斗的剩余空间就代表着当前行为可以持续进行的数量,漏嘴的流水速率代表着 系统允许该行为的最大频率。
单机版漏斗算法实现_JAVA
import java.util.HashMap;
import java.util.Map;
public class FunnelRateLimiter
private final Map<String, Funnel> funnels = new HashMap<>();
public static void main(String[] args)
FunnelRateLimiter limiter = new FunnelRateLimiter();
for (int i = 0; i < 20; i++)
System.out.println("次数" + (i + 1) + ": " + limiter.isActionAllowed("user", "get", 10, 1));
/**
* @param userId 用户ID
* @param actionKey 行为key
* @param capacity 漏斗容量
* @param leakingRate 漏嘴流水速率 单位mill
* @return 行为能否执行
*/
public boolean isActionAllowed(String userId, String actionKey, int capacity, float leakingRate)
String key = String.format("%s:%s", userId, actionKey);
Funnel funnel = funnels.get(key);
if (funnel == null)
funnel = new Funnel(capacity, leakingRate);
funnels.put(key, funnel);
return funnel.watering(1); // 需要 1 个 quota
static class Funnel
/**
* 漏斗容量
*/
int capacity;
/**
* 漏嘴流水速率
*/
float leakingRate;
/**
* 漏斗剩余空间
*/
int leftQuota;
/**
* 上一次漏水时间
*/
long leakingTs;
public Funnel(int capacity, float leakingRate)
this.capacity = capacity;
this.leakingRate = leakingRate;
this.leftQuota = capacity;
this.leakingTs = System.currentTimeMillis();
/**
* 计算剩余空间
*/
void makeSpace()
long nowTs = System.currentTimeMillis();
long deltaTs = nowTs - leakingTs; // 距离上一次漏水过去了多久
int deltaQuota = (int) (deltaTs * leakingRate); // 腾出多少空间
if (deltaQuota < 0) // 间隔时间太长,整数数字过大溢出
this.leftQuota = capacity;
this.leakingTs = nowTs;
return;
if (deltaQuota < 1) // 腾出空间太小,最小单位是 1
return;
this.leftQuota += deltaQuota;
this.leakingTs = nowTs;
if (this.leftQuota > this.capacity)
this.leftQuota = this.capacity;
/**
* @param quota 待申请空间
* @return 申请是否成功
*/
boolean watering(int quota)
makeSpace();
if (this.leftQuota >= quota)
this.leftQuota -= quota;
return true;
return false;
/*
次数1: true
次数2: true
次数3: true
次数4: true
次数5: true
次数6: true
次数7: true
次数8: true
次数9: true
次数10: true
次数11: false
次数12: false
次数13: false
次数14: false
次数15: false
次数16: false
次数17: false
次数18: false
次数19: false
次数20: false
*/
Funnel 对象的 make_space 方法是漏斗算法的核心,其在每次灌水前都会被调用以触发漏水,给漏斗腾出空间来。
能腾出多少空间取决于过去了多久以及流水的速率。Funnel 对象占据的空间大小不再和行为的频率成正比,它的空间占用是一个常量。
分布式的漏斗算法该如何实现?能不能使用 Redis 的基础数据结构来搞定?
观察 Funnel 对象的几个字段,发现可以将 Funnel 对象的内容按字段存储到一 个 hash 结构中,灌水的时候将 hash 结构的字段取出来进行逻辑运算后,再将新值回填到 hash 结构中就完成了一次行为频度的检测。
但是有个问题,无法保证整个过程的原子性。从 hash 结构中取值,然后在内存里运算,再回填到 hash 结构,这三个过程无法原子化,意味着需要进行适当的加锁控制。
而一旦加锁,就意味着会有加锁失败,加锁失败就需要选择重试或者放弃。
- 如果重试的话,就会导致性能下降。
- 如果放弃的话,就会影响用户体验。
同时,代码的复杂度也跟着升高很多。
Redis-Cell——限流 Redis 模块
Redis 4.0 提供了一个限流 Redis 模块,它叫 redis-cell。该模块也使用了漏斗算法,并 提供了原子的限流指令。
该模块只有 1 条指令 cl.throttle,它的参数和返回值都略显复杂,接下来让我们来看看这 个指令具体该如何使用。
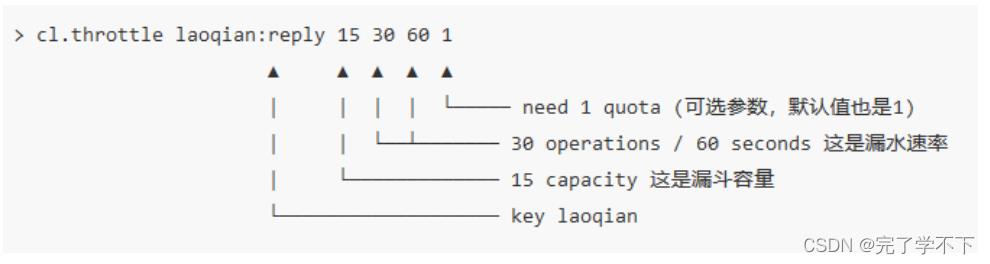
上面这个指令的意思是允许「用户老钱回复行为」的频率为每 60s 最多 30 次(漏水速 率),漏斗的初始容量为 16,也就是说一开始可以连续回复 16 个帖子,然后才开始受漏水速率的影响。我们看到这个指令中漏水速率变成了 2 个参数,替代了之前的单个浮点数。用 两个参数相除的结果来表达漏水速率相对单个浮点数要更加直观一些。
- > cl.throttle laoqian:reply 15 30 60
- 1) (integer) 0 # 0 表示允许,1 表示拒绝
- 2) (integer) 15 # 漏斗容量 capacity
- 3) (integer) 14 # 漏斗剩余空间 left_quota
- 4) (integer) -1 # 如果拒绝了,需要多长时间后再试(漏斗有空间了,单位秒)
- 5) (integer) 2 # 多长时间后,漏斗完全空出来(left_quota==capacity,单位秒)
在执行限流指令时,如果被拒绝了,就需要丢弃或重试。cl.throttle 指令考虑的非常周 到,连重试时间都帮你算好了,直接取返回结果数组的第四个值进行 sleep 即可,如果不想 阻塞线程,也可以异步定时任务来重试。
package com.hcx.common.redisdemo;
import org.apache.shiro.util.CollectionUtils;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.script.DefaultRedisScript;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.Collections;
import java.util.List;
@Component
public class FunnelRateLimiter
/**
* lua 脚本
*/
public static final String LUA_SCRIPT = "return redis.call('cl.throttle',KEYS[1], ARGV[1], ARGV[2], ARGV[3], ARGV[4])";
@Resource
private RedisTemplate<String, Object> redisTemplate;
/**
* @param key 键值
* @param capacity 总漏斗容量-1
* @param operations 漏水速率
* @param seconds 漏水周期
* @param quota 待申请空间
* @return 申请结果
*/
public boolean isActionAllowed(String key, int capacity, int operations, int seconds, int quota)
try
DefaultRedisScript<List> script = new DefaultRedisScript<>(LUA_SCRIPT, List.class);
List<Long> rs = redisTemplate.execute(script, Collections.singletonList(key), capacity, operations, seconds, quota);
if (CollectionUtils.isEmpty(rs)) return false;
System.out.println("漏斗容量:" + rs.get(1));
System.out.println("剩余空间:" + rs.get(2));
System.out.println("最少多长时间后再试:" + rs.get(3));
System.out.println("多长时间后漏斗为空:" + rs.get(4));
return rs.get(0) == 0;
catch (Exception e)
e.printStackTrace();
return false;
/*
漏斗容量:16
剩余空间:15
最少多长时间后再试:-1
多长时间后漏斗为空:2
结果:true
……
最少多长时间后再试:-1
多长时间后漏斗为空:27
结果:true
漏斗容量:16
剩余空间:1
最少多长时间后再试:-1
多长时间后漏斗为空:29
结果:true
漏斗容量:16
剩余空间:0
最少多长时间后再试:-1
多长时间后漏斗为空:31
结果:true
漏斗容量:16
剩余空间:0
最少多长时间后再试:1
多长时间后漏斗为空:31
结果:false
漏斗容量:16
剩余空间:0
最少多长时间后再试:1
多长时间后漏斗为空:31
结果:false
漏斗容量:16
剩余空间:0
最少多长时间后再试:1
多长时间后漏斗为空:31
结果:false
漏斗容量:16
剩余空间:0
最少多长时间后再试:1
多长时间后漏斗为空:31
结果:false
*/
在执行限流指令时,如果被拒绝了,就需要丢弃或重试。cl.throttle 指令考虑的非常周 到,连重试时间都帮你算好了,直接取返回结果数组的第四个值进行 sleep 即可,如果不想 阻塞线程,也可以异步定时任务来重试。
主流的几种限流策略,我都可以通过python+redis实现
python+redis 实现限流
保护高并发系统的三大利器:缓存、降级和限流。
那什么是限流呢?用我没读过太多书的话来讲,限流就是限制流量。
我们都知道服务器的处理能力是有上限的,如果超过了上限继续放任请求进来的话,可能会发生不可控的后果。
而通过限流,在请求数量超出阈值的时候就排队等待甚至拒绝服务,就可以使系统在扛不住过高并发的情况下做到有损服务而不是不服务。
举个例子,如各地都出现口罩紧缺的情况,武汉政府为了缓解市民买不到口罩的状况,上线了预约服务,只有预约到的市民才能到指定的药店购买少量口罩。
这就是生活中限流的情况,说这个也是希望大家这段时间保护好自己,注意防护 :
接下来就跟大家分享下接口限流的常见玩法吧,部分算法用python + redis粗略实现了一下,关键是图解啊!你品,你细品~
固定窗口法
固定窗口法是限流算法里面最简单的,比如我想限制1分钟以内请求为100个,从现在算起的一分钟内,请求就最多就是100个,这分钟过完的那一刻把计数器归零,重新计算,周而复始。
伪代码实现
def can_pass_fixed_window(user, action, time_zone=60, times=30):
"""
:param user: 用户唯一标识
:param action: 用户访问的接口标识(即用户在客户端进行的动作)
:param time_zone: 接口限制的时间段
:param time_zone: 限制的时间段内允许多少请求通过
"""
key = ':'.format(user, action)
# redis_conn 表示redis连接对象
count = redis_conn.get(key)
if not count:
count = 1
redis_conn.setex(key, time_zone, count)
if count < times:
redis_conn.incr(key)
return True
return False
这个方法虽然简单,但有个大问题是无法应对两个时间边界内的突发流量。如上图所示,如果在计数器清零的前1秒以及清零的后1秒都进来了100个请求,那么在短时间内服务器就接收到了两倍的(200个)请求,这样就有可能压垮系统。会导致上面的问题是因为我们的统计精度还不够,为了将临界问题的影响降低,我们可以使用滑动窗口法。
滑动窗口法
滑动窗口法,简单来说就是随着时间的推移,时间窗口也会持续移动,有一个计数器不断维护着窗口内的请求数量,这样就可以保证任意时间段内,都不会超过最大允许的请求数。例如当前时间窗口是0s~60s,请求数是40,10s后时间窗口就变成了10s~70s,请求数是60。
时间窗口的滑动和计数器可以使用redis的有序集合(sorted set)来实现。score的值用毫秒时间戳来表示,可以利用 当前时间戳- 时间窗口的大小 来计算出窗口的边界,然后根据score的值做一个范围筛选就可以圈出一个窗口;value的值仅作为用户行为的唯一标识,也用毫秒时间戳就好。最后统计一下窗口内的请求数再做判断即可。

伪代码实现
def can_pass_slide_window(user, action, time_zone=60, times=30):
"""
:param user: 用户唯一标识
:param action: 用户访问的接口标识(即用户在客户端进行的动作)
:param time_zone: 接口限制的时间段
:param time_zone: 限制的时间段内允许多少请求通过
"""
key = ':'.format(user, action)
now_ts = time.time() * 1000
# value是什么在这里并不重要,只要保证value的唯一性即可,这里使用毫秒时间戳作为唯一值
value = now_ts
# 时间窗口左边界
old_ts = now_ts - (time_zone * 1000)
# 记录行为
redis_conn.zadd(key, value, now_ts)
# 删除时间窗口之前的数据
redis_conn.zremrangebyscore(key, 0, old_ts)
# 获取窗口内的行为数量
count = redis_conn.zcard(key)
# 设置一个过期时间免得占空间
redis_conn.expire(key, time_zone + 1)
if not count or count < times:
return True
return False
虽然滑动窗口法避免了时间界限的问题,但是依然无法很好解决细时间粒度上面请求过于集中的问题,就例如限制了1分钟请求不能超过60次,请求都集中在59s时发送过来,这样滑动窗口的效果就大打折扣。 为了使流量更加平滑,我们可以使用更加高级的令牌桶算法和漏桶算法。
令牌桶法
令牌桶算法的思路不复杂,它先以固定的速率生成令牌,把令牌放到固定容量的桶里,超过桶容量的令牌则丢弃,每来一个请求则获取一次令牌,规定只有获得令牌的请求才能放行,没有获得令牌的请求则丢弃。

伪代码实现
令牌桶法,具体步骤:
- 请求来了就计算生成的令牌数,生成的速率有限制
- 如果生成的令牌太多,则丢弃令牌
- 有令牌的请求才能通过,否则拒绝
def can_pass_token_bucket(user, action, time_zone=60, times=30):
"""
:param user: 用户唯一标识
:param action: 用户访问的接口标识(即用户在客户端进行的动作)
:param time_zone: 接口限制的时间段
:param time_zone: 限制的时间段内允许多少请求通过
"""
# 请求来了就倒水,倒水速率有限制
key = ':'.format(user, action)
rate = times / time_zone # 令牌生成速度
capacity = times # 桶容量
tokens = redis_conn.hget(key, 'tokens') # 看桶中有多少令牌
last_time = redis_conn.hget(key, 'last_time') # 上次令牌生成时间
now = time.time()
tokens = int(tokens) if tokens else capacity
last_time = int(last_time) if last_time else now
delta_tokens = (now - last_time) * rate # 经过一段时间后生成的令牌
if delta_tokens > 1:
tokens = tokens + tokens # 增加令牌
if tokens > tokens:
tokens = capacity
last_time = time.time() # 记录令牌生成时间
redis_conn.hset(key, 'last_time', last_time)
if tokens >= 1:
tokens -= 1 # 请求进来了,令牌就减少1
redis_conn.hset(key, 'tokens', tokens)
return True
return False
令牌桶法限制的是请求的平均流入速率,优点是能应对一定程度上的突发请求,也能在一定程度上保持流量的来源特征,实现难度不高,适用于大多数应用场景。
漏桶算法
漏桶算法的思路与令牌桶算法有点相反。大家可以将请求想象成是水流,水流可以任意速率流入漏桶中,同时漏桶以固定的速率将水流出。如果流入速度太大会导致水满溢出,溢出的请求被丢弃。

通过上图可以看出漏桶法的特点是:不限制请求流入的速率,但是限制了请求流出的速率。这样突发流量可以被整形成一个稳定的流量,不会发生超频。
关于漏桶算法的实现方式有一点值得注意,我在浏览相关内容时发现网上大多数对于漏桶算法的伪代码实现,都只是实现了
根据维基百科,漏桶算法的实现理论有两种,分别是基于 meter的和 基于 queue 的,他们实现的具体思路不同,我大概介绍一下。
基于meter的漏桶
基于meter 的实现相对来说比较简单,其实它就有一个计数器,然后有消息要发送的时候,就看计数器够不够,如果计数器没有满的话,那么这个消息就可以被处理,如果计数器不足以发送消息的话,那么这个消息将会被丢弃。
那么这个计数器是怎么来的呢,基于 meter 的形式的计数器就是发送的频率,例如你设置得频率是不超过 5条/s ,那么计数器就是 5,在一秒内你每发送一条消息就减少一个,当你发第 6 条的时候计时器就不够了,那么这条消息就被丢弃了。
这种实现有点类似最开始介绍的固定窗口法,只不过时间粒度再小一些,伪代码就不上了。
基于queue的漏桶
基于 queue 的实现起来比较复杂,但是原理却比较简单,它也存在一个计数器,这个计数器却不表示速率限制,而是表示 queue 的大小,这里就是当有消息要发送的时候看 queue 中是否还有位置,如果有,那么就将消息放进 queue 中,这个 queue 以 FIFO 的形式提供服务;如果 queue 没有位置了,消息将被抛弃。
在消息被放进 queue 之后,还需要维护一个定时器,这个定时器的周期就是我们设置的频率周期,例如我们设置得频率是 5条/s,那么定时器的周期就是 200ms,定时器每 200ms 去 queue 里获取一次消息,如果有消息,那么就发送出去,如果没有就轮空。
注意,网上很多关于漏桶法的伪代码实现只实现了水流入桶的部分,没有实现关键的水从桶中漏出的部分。如果只实现了前半部分,其实跟令牌桶没有大的区别噢😯
如果觉得上面的都太难,不好实现,那么我墙裂建议你尝试一下redis-cell这个模块!
redis-cell
Redis 4.0 提供了一个限流 Redis 模块,它叫 redis-cell。该模块也使用了漏斗算法,并提供了原子的限流指令。有了这个模块,限流问题就非常简单了。 这个模块需要单独安装,安装教程网上很多,它只有一个指令:CL.THROTTLE
CL.THROTTLE user123 15 30 60 1
▲ ▲ ▲ ▲ ▲
| | | | └───── apply 1 operation (default if omitted) 每次请求消耗的水滴
| | └──┴─────── 30 operations / 60 seconds 漏水的速率
| └───────────── 15 max_burst 漏桶的容量
└─────────────────── key “user123” 用户行为
执行以上命令之后,redis会返回如下信息:
> cl.throttle laoqian:reply 15 30 60
1) (integer) 0 # 0 表示允许,1表示拒绝
2) (integer) 16 # 漏桶容量
3) (integer) 15 # 漏桶剩余空间left_quota
4) (integer) -1 # 如果拒绝了,需要多长时间后再试(漏桶有空间了,单位秒)
5) (integer) 2 # 多长时间后,漏桶完全空出来(单位秒)
有了上面的redis模块,就可以轻松对付大多数的限流场景了。
最后,感谢您的阅读。您的每个点赞、留言、分享都是对我们最大的鼓励,笔芯~
如有疑问,欢迎在评论区一起讨论!
以上是关于Redis 实现限流策略的主要内容,如果未能解决你的问题,请参考以下文章