ConfluxNews2023.4.3 日拱一卒
Posted gtaxx2012
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ConfluxNews2023.4.3 日拱一卒相关的知识,希望对你有一定的参考价值。
1.【网络状态】当前版本V2.2.2,全网算力≈8T,昨日交易次数35K,昨日新增账户0.26K,昨日新增合约4个;
2.【POS参数】总锁仓245M,节点总数265,年利率14.6%(理论计算),总奖励21M;
3.【海外动态】@LBank_Exchange 正在联合 @Conflux_network 开展$10,000 CFX的有奖注册活动;
4.【海外动态】@BingXOfficial 已上线@Conflux_network 的存取业务;
5.【香港动态】@ForesightVen X OpenBuild 将与@Conflux_network 等多家项目在香港举办 黑松活动;
6.【香港动态】@iotex_io 将与@Conflux_network 等多家项目 在香港铜锣湾举办先锋合作庆典;
7.【香港动态】MOSSAI 元宇宙创始人@Landon 教授将参加在香港九龙举办的Web3.0浪尖私享会;
8.【国内动态】@Conflux_network 将于4月6日参加 中国通信工业协会区块链专委会&NFTNET GLOBAL联合举办的全球顶尖公链元宇宙高峰讨论会;
9.【国内动态】联合创始人@元杰 参加在长安WEB3数字艺术节的多场演说活动;
10.【声明】本文仅代表个人观点,不构成投资建议,行业有风险投资需谨慎。
-----------------------------
关注树图区块链,参与中国WEB3.0建设
新闻图文版:https://forum.conflux.fun/t/confluxnews-2023-4-3/18247
区块链浏览器:https://confluxscan.net
生态导航:https://123cfx.com
魔盒——日拱一卒,功不唐捐把
郑昀 创建于2017/6/29 最后更新于2017/6/30
关键词:大数据,Spark,SparkSQL,HBase,HDFS,工作流,任务,Flow,Job,监控报警
提纲:
-
为什么要大数据协作?
-
什么是愿景?
-
我们的DataCube
-
工作流什么样?
DataCube 是数据中心刘奎组推出的大数据协作平台。从2016年3月29日我提出数据中心的大一统平台建设目标至今,已经过去了整整一年零三个月时间。其实在很久以前,基于 Hadoop 集群的单一离线计算任务的上传和管理工作,针对 Mesos 集群、HBase、HDFS 的监控报警,刘奎、王银卡、崔建伟、陈少明、李少杰等人已经开发就绪。但真正要把数据仓库计算方方面面搬进来,仍然等了一年时间,因为在底层,运维工程师们还构建了一个 DataFlash 集群,情况比较复杂。
DataCube,中文名字是魔盒。
当初,我说魔盒主要是围绕着这四个核心概念构建一个体系:
-
资源
-
数据
-
流程
-
操作
什么体系?
-
资源,能看见。
-
流程,能流转。
-
数据,能共享。
-
操作,有记录。
出了问题,随时能通过图形化界面排查。
不需要知道的,都隐藏在黑暗之中,被封装为黑箱。
流程驱动数据,再驱动操作,形成闭环。
在2016年年初,我还对于运维自动化平台 SimpleWay 也提出了我的愿景:
在我的想象中,到了 2016年Q3 所见到的是:
线上配置同步到CMDB且可视化:我能在 SimpleWay 上看到任意一台 Nginx、Redis、MySQL、ElasticSearch、ZooKeeper等的物理信息和配置;
资源的调拨和历史可视化:我能在 SimpleWay 上看到任意一台物理机什么时候采购的、什么时候上架的、在哪个机柜、上面都有什么应用、跑了什么虚拟机、承载了什么容器等等;
资源申请、运维操作的流程化:SA、Dev、QA 对资源的申请,或变更配置,工作流的流转以及操作登记备案。
其实,对未来的这些愿景大同小异,都体现了窝窝和云纵的研发哲学:Don\'t make me think.
0x00,为什么要大数据协作?
2016年的时候,数据中心虽然有自助式报表、即席查询、数据库变更订阅中心、元数据管理、实时数据大屏等管理工具,即使2017年进一步演变出来了数屏、数据开放实验室,但仍不成体系。
什么叫不成体系?
数据,不能共享。
流程,不能流转。
资源,无法看见。
操作,没有记录。
各个模块各自为战。最令我无法忍受的是,Hadoop 集群的离线计算和实时计算线下部署和线上发布还以手工操作为主。
所以,我着重强调用“流程贯穿”提升研发的生产效率。
0x01,什么是愿景?
我曾经说过,在内部讨论技术平台和体系的时候,不要束缚自己的想象力,不要说因为我现在是这样,所以我按此演进,只能是那样。
NO!
一定要切换到朴素无华的脑力和心态(是的,我喜欢用朴素无华这个词),进入使用者场景,想象怎么才是用起来最舒服的状态,或者你所见过的最应当如此、最顺其自然的流程。
我说,我要如此。
可能,最后真的能如此。
举一个例子:
研发中心的协作平台,申请服务器资源是这个样子:
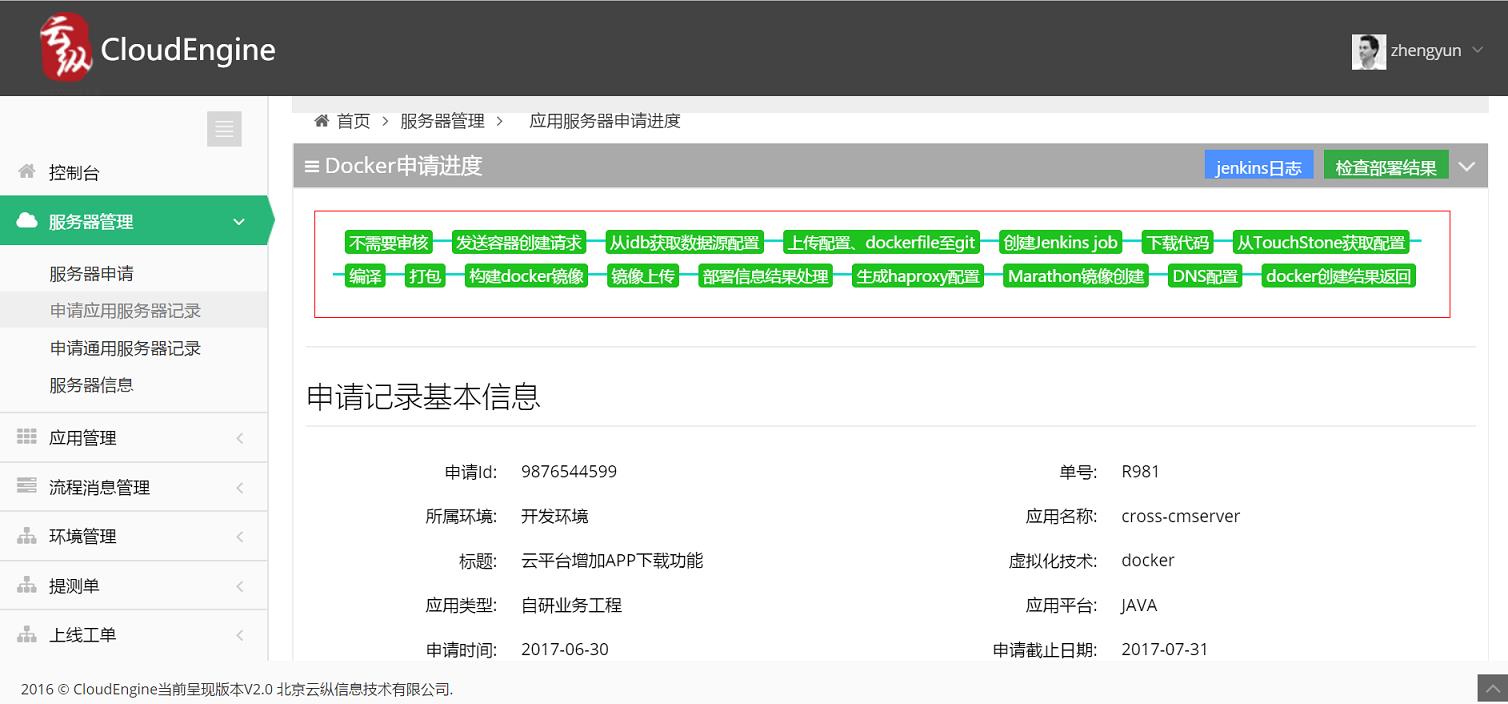
图1 我们这样申请测试资源
那时候我们期望如此。
后来梦想成真。
0x02,我们的DataCube
那么现如今,魔盒能做到什么呢?
先来一张靓照:
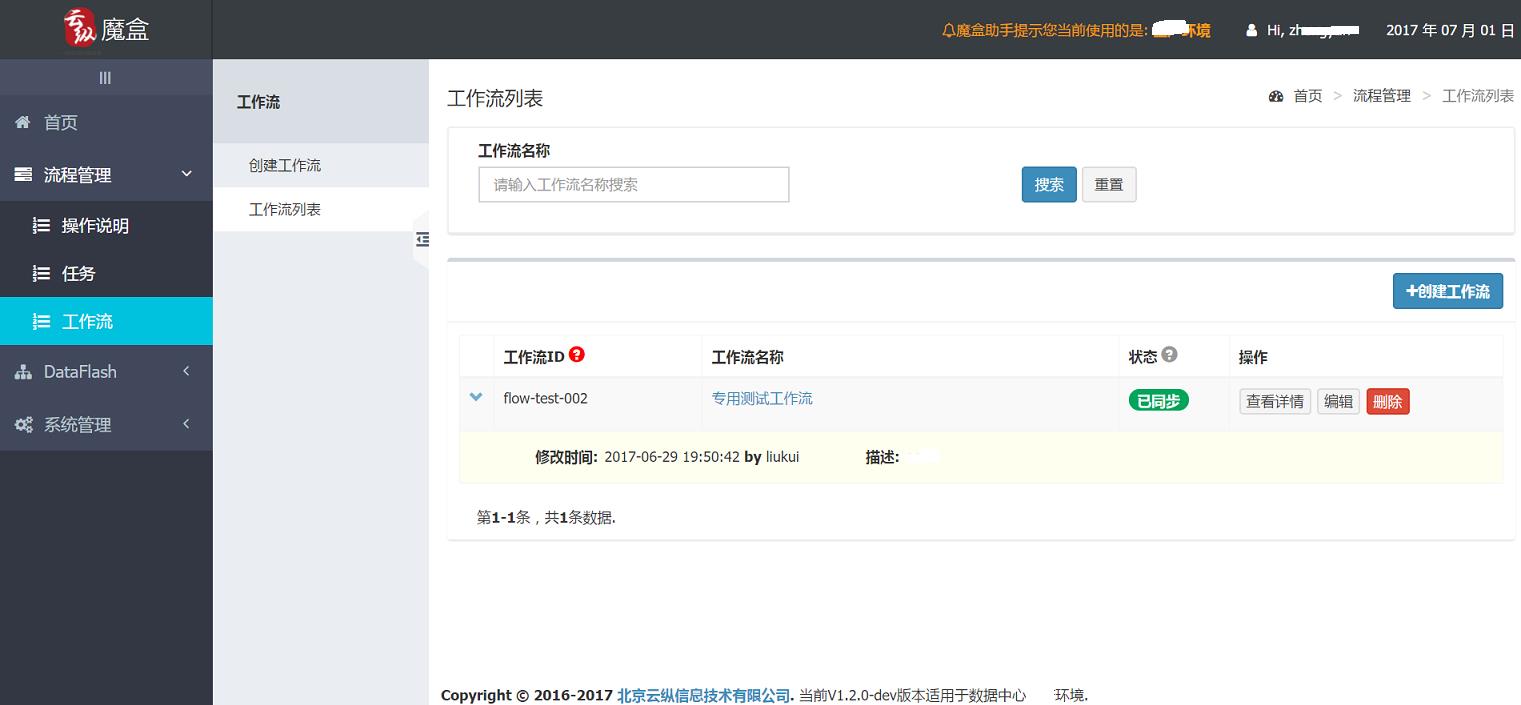
图2-0 DataCube靓照
生产环境的它有这些功能:
-
DashBoard
-
流程管理:
-
任务:
-
任务列表
-
任务详情
-
任务更新
-
任务删除
-
创建任务(Spark任务,SparkSQL任务)
-
工作流:
-
工作流列表
-
工作流详情
-
工作流编辑
-
工作流删除
-
创建工作流
-
配置流程
-
展示流程拓扑图
-
设定调度计划
-
DataFlash:主要是监控报警
-
集群概览
-
DataFlash实时监测
-
近一周报警走势
-
今日报警分类图
-
今日报警日志列表
-
Mesos
-
概览
-
实例列表
-
监控指标
-
报警规则(设置)
-
HBase
-
概览
-
实例列表
-
监控指标
-
报警规则(设置)
-
HDFS
-
概览
-
实例列表
-
监控指标
-
报警规则(设置)
-
系统管理:
-
公共资源配置
对 DataFlash 集群(Mesos/HBase/HDFS)的监控报警,暂且不提。大概齐长下面这个样子:

图2-1 针对DataFlash集群的监控报警体系
我们讲一下最新的工作流。
0x03,工作流什么样?
我作为一名数据仓库工程师,首先创建一个离线计算任务:
图3 创建任务
我可以创建一个 Spark任务 或 一个 SparkSQL 任务。
我不需要上传 jar 包。
指定 git 仓库地址即可,以及任务入口类名,还可以设置动态参数。
系统可以帮你构建和上传,不需要你操心。
提交任务之后,可以进入任务详情,亲手构建和发布上线。
图4 任务详情
这里的“发布上线”指的是,从测试环境推送到生产环境。当然了,生产环境需要对这次推送确认。
有了任务,还需要有工作流。
我们的工作流往往很复杂。
譬如这样的:
图5 工作流详情页上半部分
工作流中的任务可以依赖于其他任务或工作流。
我们在工作流身上设置时间调度规则。也可以选择立即执行。
可以在工作流详情页的下半部分看到执行详情:
图6 工作流详情页下半部分
点击上图中的工作流名称,可以看到本次执行的拓扑图,下图中的红色代表执行失败:
图7 工作流执行详情
还可以一路点击进去看到底错在哪里了:
图8 工作流执行-任务详情
还是解决不了问题的话,就点击查看日志,不再赘述。
总之,我们可以通过魔盒的图形化界面,解决85%~90%的大数据日常调度、管理和部署工作。
而这就是我们最初设定的愿景。
加速高质量的交付,提升开发者的价值。我们技术团队所做的每一个步骤、每一个过程都是叠加的、递增的,日拱一卒,功不唐捐。
下一步需要做什么?
实时计算还没有纳入其中。继续努力。
-EOF-
关注我的订阅号:

注:头图来自于bing.com
以上是关于ConfluxNews2023.4.3 日拱一卒的主要内容,如果未能解决你的问题,请参考以下文章
高效编码简单全面JDK的监控命令,看这一篇就够了!!日拱一卒