MySQL的概念
Posted 怎么也想不出名字
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL的概念相关的知识,希望对你有一定的参考价值。
mysql的概念
一.数据库的基本概念
1、数据(Data)
• 描述事物的符号记录
• 包括数字,文字,图形,图像,声音,档案记录等
• 以“记录”形式按统一的格式进行存储
2、表
• 将不同的记录组织在一起
• 用来存储具体数据
3、数据库
• 表的集合,是存储数据的仓库
• 以一定的组织方式存储的相互有关的数据集合
4、数据库管理系统(DBMS)
数据库管理系统(Database Management System,简称DBMS)是为管理数据库而设计的电脑软件系统,一般具有存储、截取、安全保障、备份等基础功能
• 是实现对数据库资源有效组织、管理和存取的系统软件
数据库管理系统主要分为以下两类:
4.1 关系数据库
关系数据库是创建在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示.几乎所有的数据库管理系统都配备了一个开放式数据库连接(ODBC)驱动程序,令各个数据库之间得以互相集成。
典型代表有:MySQL、Oracle、Microsoft SQL Server、Access及PostgreSQL等
4.2 非关系型数据库 NoSQL
非关系型数据库是对不同于传统的关系数据库的数据库管理系统的统称。与关系数据库最大的不同点是不使用SQL作为查询语言。
典型代表有:Reids、BigTable(Google)、Cassandra、MongoDB、CouchDB;
还包括键值数据库:Apache Cassandra(Facebook)、LevelDB(Google)
5、数据库系统
• 是一个人机系统,由硬件、os、数据库、DBMS、应用软件和数据库用户组成
• 用户可以通过DBMS或应用程序操作数据库
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询语言。
作用:用于存取数据、查询、更新和管理关系数据库系统。
6、访问数据库的流程
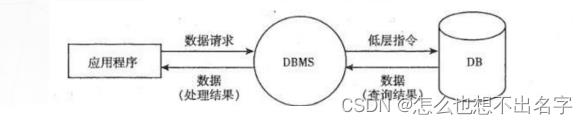
二.数据库系统发展史
1.第一代数据库
• 自20世纪60年代起,第一代数据库系统问世
• 是层次模型与网状模型的数据库系统
• 为统一管理和共享数据提供了有力的支撑
2.第二代数据库
• 20世纪70年代,第二代数据库—关系数据库开始出现
• 20世纪80年代,IBM公司的关系数据库系统DB2问世,开始逐步取代层次与网状模型的数据库,成为行业主流
• 到目前为止,关系数据库系统仍占领数据库应用的主要地位
3.第三代数据库
• 自20世纪80年代开始,适应不同领域的新型数据库系统不断涌现
• 面向对象的数据库系统,实用性强,适应面广
• 20世纪90年代后期,形成了多种数据库系统共同支撑应用的局面
• 一些新的元素被添加进主流数据库系统中
例如,Oracle支持的 “关系-对象"数据库模型
三、当今主流数据库介绍
1.SQL Server (微软公司产品)
• 面向Windows操作系统
• 简单、易用
2、Oracle (甲骨文公司产品)
• 面向所有主流平台,
• 安全、完善,操作复杂
3、DB2 (IBM公司产品)
• 面向所有主流平台
• 大型、安全、完善
4.MySQL (甲骨文公司收购)
• 免费、开源、体积小
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。
MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
在Java企业级开发中非常常用,因为 MySQL 是开源免费的,并且方便扩展。
四、关系数据库
• 关系数据库系统是基于关系模型的数据库系统
• 关系模型的数据结构使用简单易懂的二维数据表
• 关系模型可用简单的“实体关系”(E-R) 图来表示
• E-R图中包含了实体(数据对象)、关系和属性三个要素
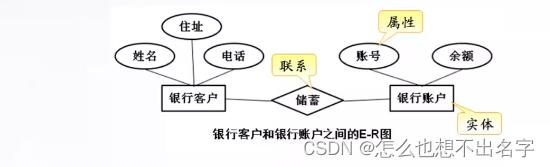
1、实体
-
也称为实例,对应现实世界中可区别于其它对象的“事件”或“事物”
- 如银行客户、银行账户等
2、属性
-
实体所具体的某一特性,一个实体可以有多个属性
- 如“银行客户”实体集中的每个实体均具有姓名、住址、电话等属性
3、联系
-
实体集之间的对应关系称为联系,也称为关系
-
如银行客户和银行账户存在“储蓄”的关系
-
所有实体及实体之间联系的集合构成一个关系数据库
-
关系数据库的存储结构是二维表格
-
在每个二维表中
-
每一行称为一条记录,用来描述一个对象的信息
-
每一列称为一个字段,用来描述对象的一个属性
4、关系数据库
• Oracle , MySQL
• SQLServer、Sybase
• Informix、access
• DB2、FoxPRO
5、关系数据库的应用
12306用户信息系统------------Oracle,MySQL
淘宝账号系统---------------------SQLServer、Sybase
联通手机号信息系统----------- Informix、access
银行用户账号系统---------------DB2、FoxPRO
网站用户信息系统---------------PostgreSQL
六、非关系数据库
非关系数据库也被称作NoSQL (Not Only SQL)
存储数据不以关系模型为依据,不需要固定的表格式
1、非关系型数据库的优点
• 数据库可高并发读写
• 对海数据高效率存储与访问
• 数据库具有高扩展性与高可用性
2、常用的非关系数据库
Redis、mongoDB等
七、MySQL的介绍
1 MySQL数据库介绍
一款深受欢迎的开源关系型数据库
Oracle旗下的产品
遵守GPL协议,可以免费使用与修改
特点:
性能卓越、服务稳定
开源、无版权限制、成本低
多线程、多用户
基于C/S(客户端/服务器)架构
安全可靠
2、MySQL商业版与社区版
MySQL商业版是由MySQL AB公司负责开发与维护,需要付费才能使用
MySQL社区版是由分散在世界各地的MySQL开发者、爱好者一起开发与维护,可以免费使用
两者区别
商业版组织管理与测试环节更加严格,会比社区版更稳定
商业版不遵守GPL,社区版遵从GPL可以免费使用
商业版可获得7*24小时的服务,社区版则没有
3、 MySQL产品阵营
第一阵营:5.0-5.1阵营,可说是早期产品的延续
第二阵营:5.4-5.7阵营,整合了MySQL AB公司、社区和第三方公司开发的存储引擎,从而提高性能
第三阵营:6.0-7.1阵营,就是MySQL Cluster版本, 为适应新时代对数据库的集群需求而开发
下载网址:
http://www.dev.mysql.com/downloads
八、编译安装MySQL数据库
脚本一键安装部署
#!/bin/bash
yum -y install gcc gcc-c++ ncurses ncurses-devel bison cmake
#创建程序用户管理
useradd -s /sbin/nologin mysql
cd /opt
tar zxvf mysql-5.7.17.tar.gz -C /opt
cd /opt
tar zxvf boost_1_59_0.tar.gz -C /usr/local/
mv /usr/local/boost_1_59_0 /usr/local/boost
cd /opt/mysql-5.7.17
cmake \\
-DCMAKE_INSTALL_PREFIX=/usr/local/mysql \\
-DMYSQL_UNIX_ADDR=/usr/local/mysql/mysql.sock \\
-DSYSCONFDIR=/etc \\
-DSYSTEMD_PID_DIR=/usr/local/mysql \\
-DDEFAULT_CHARSET=utf8 \\
-DDEFAULT_COLLATION=utf8_general_ci \\
-DWITH_EXTRA_CHARSETS=all \\
-DWITH_INNOBASE_STORAGE_ENGINE=1 \\
-DWITH_ARCHIVE_STORAGE_ENGINE=1 \\
-DWITH_BLACKHOLE_STORAGE_ENGINE=1 \\
-DWITH_PERFSCHEMA_STORAGE_ENGINE=1 \\
-DMYSQL_DATADIR=/usr/local/mysql/data \\
-DWITH_BOOST=/usr/local/boost \\
-DWITH_SYSTEMD=1
make -j2 && make install
#创建普通用户管理mysql
useradd -s /sbin/nologin mysql
chown -R mysql:mysql /usr/local/mysql/
#更改管理主/组
chown mysql:mysql /etc/my.cnf
#调整配置文件
echo '[client]
port = 3306
default-character-set=utf8
socket = /usr/local/mysql/mysql.sock
[mysql]
port = 3306
default-character-set=utf8
socket = /usr/local/mysql/mysql.sock
[mysqld]
user = mysql
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
port = 3306
character_set_server=utf8
pid-file = /usr/local/mysql/mysqld.pid
socket = /usr/local/mysql/mysql.sock
bind-address = 0.0.0.0
skip-name-resolve
max_connections=2048
default-storage-engine=INNODB
max_allowed_packet=16M
server-id = 1
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_AUTO_VALUE_ON_ZERO,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,PIPES_AS_CONCAT,ANSI_QUOTES
' > /etc/my.cnf
#设置环境变量
echo "PATH=$PATH:/usr/local/mysql/bin" >> /etc/profile
source /etc/profile
#初始化数据库
cd /usr/local/mysql/bin/
echo "wait..."
./mysqld \\
--initialize-insecure \\
--user=mysql \\
--basedir=/usr/local/mysql \\
--datadir=/usr/local/mysql/data
cp /usr/local/mysql/usr/lib/systemd/system/mysqld.service /usr/lib/systemd/system/
#数据库开启
systemctl daemon-reload
systemctl start mysqld.service
systemctl enable mysqld
yum -y install expect &> /dev/null
source /etc/profile
#设置Mysql密码
/usr/bin/expect <<-EOF
spawn mysqladmin -u root -p password
expect
"Enter password"
send "\\r";exp_continue
"New password"
send "123456\\r";exp_continue
"Confirm new password"
send "123456\\r"
expect eof
EOF
echo "mysql密码为123456"
MySQL数据库Day01-数据库MySQL的基本概念
数据库MySQL的基本概念
MySQ启动和登录
- 启动MySQL:
# service mysql start
mysql.server start
- 授权MySQL远程登录权限:
grant all priviliges on *.* to 'root' identified by '123456'
flush priviliges
MySQL索引
基本概念
- 索引: index
- 是一种有序的,为了高效获取数据库数据的一种数据结构
- 索引是数据库维护的一种满足特定查找算法的数据结构,这个数据结构以特定的方式引用或者指向数据
- 索引本身很大,不会存储在内存中,通常以索引文件的形式存储在磁盘上. 索引是数据库中用来提高性能的最常用工具
索引特点
- 优点:
- 提高查询数据的效率,降低数据库的IO成本
- 可以通过索引对数据库数据进行排序,降低数据排序的成本,降低CPU消耗
- 缺点:
- 索引也是一张表,表中保存了主键和索引字段,并且指向实体数据记录,所以要占用一定的空间
- 索引在提升查询效率时,也降低了数据库的更新效率.比如对表进行插入INSERT, 更新UPDATE和删除DELETE操作时 ,MySQL数据库不仅要更新实体数据,还需要更新保存索引文件中每次更新添加的索引列字段,都会调整实体数据变化后的索引信息
索引结构
- 索引是在MySQL的存储引擎层实现的,而不是在服务器层实现的
- 不同的存储引擎支持的索引结构不一定完全相同 ,MySQL中包含以下4中索引结构:
- BTree: 常用的索引类型,大部分引擎都支持BTree索引
- Hash: 只有Memory引擎支持的索引,使用场景简单
- R-tree: 空间索引. 空间索引是MyISAM中的一个特殊的索引类型,主要适用于地理空间数据类型
- Full-text: 全文索引. 全文索引是MyISAM中的一个特殊的索引类型,主要用于全文索引
| 索引结构 | InnoDB 引擎 | MyISAM 引擎 | Memory 引擎 |
|---|---|---|---|
| BTree 索引 | 支持 | 支持 | 支持 |
| Hash 索引 | 不支持 | 不支持 | 支持 |
| R-tree 索引 | 不支持 | 支持 | 不支持 |
| Full-text 索引 | 支持(5.6) | 支持 | 不支持 |
- 通常说的索引是指B+ 树结构组织的索引,是一个多路搜索树,不一定是二叉树
- 聚集索引,复合索引,前缀索引,唯一索引默认都是使用B+ 树索引
- B树结构: 多路平衡搜索树,比如一棵m叉的BTree
- 树中的每个节点最多包含 m m m个孩子
- 除了根节点和叶子节点以外,每个节点至少有 c e i l ( m 2 ) ceil(\\fracm2) ceil(2m)个孩子
- 如果根节点不是叶子节点,那么至少有两个孩子
- 所有叶子节点都在同一层
- 每一个非叶子节点都是由 n n n个key和 n + 1 n+1 n+1个指针组成 . n的取值范围 [ c e i l ( m 2 ) − 1 , m − 1 ] . [ceil(\\fracm2) -1,m-1]. [ceil(2m)−1,m−1].
- 当非叶子节点的key值超出范围时,中间节点向上一层分裂到父节点,两边节点分裂成为子节点
- B树比起二叉树,因为B树的层级比二叉树小,所以查询效率更高,搜索速度快
- B+树结构: B+树是B树的扩展 ,B+树和B树之间有区别
- m m m叉B+ 树最多包含 m m m个key. 而 m m m叉B树最多包含 m − 1 m-1 m−1个key
- B+ 树的所有叶子节点保存所有的key信息,根据key的大小顺序排列
- 所有的非叶子节点都可以看作是所有key信息的索引
- B+ 树中所有key信息都保存在叶子节点,查询任何key都需要从根节点遍历到叶子节点,所以B+ 树的查询效率更加稳定
- MySQL中的B+树结构:
- MySQL中中使用了优化的B+ 树结构
- 在原有的B+ 树的结构的基础上 ,MySQL中增加了一个指向相邻叶子节点的链表指针,形成了一个带有顺序指针的B+ 树
- 这样MySQL中的B+ 树结构有利于范围访问,提高了区间的访问性能
索引分类
- 单值索引: 一个索引只包含一个单列.一个表中可以建立多个单值索引
- 唯一索引: 索引列的值必须唯一,允许存在多个空值null
- 复合索引: 一个索引包含多个列
索引语法
- 创建索引:
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON table_name(column_list);
- 查看索引:
SHOW INDEX FROM table_name;
- 删除索引:
DROP INDEX ON table_name;
- ALTER命令:
-- 添加一个主键.索引值必须唯一并且不能为null
ALTER TABLE table_name ADD PRIMARY KEY(colum);
-- 添加一个唯一索引.索引的值必须唯一,不包括null,如果有null,null可以出现多次
ALTER TABLE table_name ADD UNIQUE index_name(colum_list);
-- 添加普通索引.索引值可以出现多次
ALTER TABLE table_name ADD INDEX index_name(colum_list);
-- 添加全文索引,用于全文搜索
ALTER TABLE table_name ADD FULL_TEXT index_name(column_list);
索引原则
- 对于查询频次较高,数据量大的数据表建立索引
- 索引字段最好从WHERE的子句的条件中提取. 如果WHERE子句中的组合比较多,最好挑选最常用的,过滤效果最好的列的组合
- 最好使用唯一索引.因为索引的区分度越高,索引的使用效率越高
- 索引可以有效提升查询效率,但不是索引数量越多越好. 索引越多,索引维护的代价也就越高.对于插入,更新,删除等DML操作频繁的表而言,索引越多,维护的代价越高,降低DML操作的效率,增加操作的时间成本. 索引越多,也会增加MySQL的选择成本,尽管最终会找到一个可用的索引,但是提高了选择的代价
- 最好使用短索引. 创建的索引是使用硬盘来存储的,可以提升索引访问的I/O效率,也可以提升总体的访问效率.当构成索引的总长度较短时,就可以在给定大小的存储块内存储更多的索引值,可以有效的提升MySQL访问索引的I/O效率
- 利用好最左前缀原则 . N个列组合而成的索引,就相当于创建了N个索引. 查询时WHERE的子语句中使用了组成索引的前几个字段,这条SQL语句就可以利用组合索引提升查询效率
MySQL视图
基本概念
- 视图: View
- 一种MySQL数据库中虚拟存在的表
- MySQL数据库中不存在视图的表,视图中行和列的数据来源于定义视图时查询中使用到的表,在使用视图时动态生成
- 视图就是SELECT语句返回的结果集,创建视图主要工作就是写好视图的SELECT语句
- 视图的优点:
- 简单: 使用的视图就是一个已经过滤好的复合条件的结果集,不需要关心视图后面对应的表的结构,关联条件和筛选条件
- 安全: MySQL中可以实现表的权限管理,但是无法精确到对表的某个行和列,使用视图可以简单实现对数据的访问精确到某个表的某行和某列中
- 数据独立: 使用的视图确定好后,视图后面对应的表结构变化不会影响视图的结构. 如果对应的表增加列完全不会影响到视图,如果对应的表修改了列名,只需要对应的修改视图的列名即可,不会引发数据访问的问题
视图语法
- 创建视图:
CREATE [OR REPLACE] [ALGORITHM = UNDEFINED | MERGE | TEMPTABLE]
VIEW view_name [(cloumn_list)]
AS select_statement
[WITH [CASCADE | LOCAL] CHECK POINT]
- 视图既主要用于查询,在特殊的情况也可以进行更新,但是不建议对视图进行更新
- WITH [CASCADE | LOCAL] CHECK POINT : 用于指定是否允许对视图中的数据记录进行更新的操作
- CASCADE: 默认,必须满足当前视图依赖的所有视图的条件可以进行更新操作
- LOCAL: 满足当前视图的条件可以进行更新操作
- WITH [CASCADE | LOCAL] CHECK POINT : 用于指定是否允许对视图中的数据记录进行更新的操作
- 修改视图:
ALTER [ALGRITHM = UNDEFINED | MERGE | TEMPTABLE]
VIEW view_name [(cloumn_list)]
AS select_statement
[WITH [CASCADE | LOCAL] CHECK POINT
- 查看视图:
-- 从 MySQL 5.1 版本以后,使用SHOW TABLE不仅可以查看表的名称,也可以查看视图的名称
SHOW TABLES
-- 从 MySQL 5.1 版本以后,使用SHOW STATUS不仅可以查看表的信息,也可以查看视图的信息
SHOW STATUS
-- 查看视图的创建语句
SHOW CREATE VIEW view_name
- 删除视图:
DROP VIEW [IF EXISTS] view_name [,..view_name] [RESTRICT | CASCADE]
存储过程和存储函数
基本概念
- 存储过程和存储函数:
- 事先经过编译并且存储在数据库中的一段SQL语句的集合
- 可以减少数据在数据库和应用服务器之间的数据传输次数,有利于提高数据处理效率
- 存储过程: 一个没有返回值的函数
- 存储函数: 一个有返回值的过程
存储过程
创建存储过程
- 创建存储过程的语法中,因为存储过程体中的SQL语句结束符分号和MySQL的语句默认的分隔符分号冲突,所以需要使用DELIMITER命令修改MySQL中的语句分隔符
- DELIMITER : 分隔符,默认为分号
- 用来声明MySQL数据库中的分隔符的关键字
- 定义指定的符号表明MySQL命令编写结束,可以执行
DELIMITER $
- 创建存储过程:
CREATE PROCEDURE procedure_name([procedure_parameter, ...])
BEGIN
select_statement
...
END$
DELIMITER ;
调用存储过程
- 调用存储过程:
CALL procedure_name();
查看存储过程
- 查看存储过程:
-- 查询MySQL数据库db_name中所有的存储过程的名称
SELECT name FROM mysql.proc WHERE db='db_name';
-- 查询MySQL数据库中存储过程的状态信息
SHOW PROCEDURE STATUS
-- 查看MySQL数据库中指定存储过程的创建语句
SHOW CREATE PROCEDURE procedure_name [\\G];
删除存储过程
- 删除存储过程:
DROP PROCEDURE [IF EXISTS] procedure_name;
语法
- 存储过程时有可编程的性质,所以可以在存储过程中使用变量,表达式和条件控制结果来实现复杂的功能
变量操作
- DECLARE:
- 可以使用DECLARE声明一个局部变量
- 使用DECLARE声明的局部变量的作用范围在当前的begin和end的过程方法体中
DECLARE var_name[,...] var_type [DEFAULT var_value];- 示例:
DELIMITER $ CREATE PROCEDURE procedure_variable() BEGIN DECLARE num int DEFAULT 6; SELECT num+10; END $ - SET:
- 可以使用SET对变量进行赋值
- 使用SET可以对变量赋值为常量或者表达式
SET var_name=expr [,...var_name=expr]- 示例:
DELIMITER $ CREATE PROCEDURE procedure_variable() BEGIN DECLARE name varchar(20); SET name='Chova'; SELECT name; END$ - INTO:
- 可以使用SELECT…INTO的方式为变量赋值为常量或者表达式
DECLARE $ CREATE PROCEDURE procedure_variable() BEGIN DECLARE count int; SELECT count(1) INTO count FROM table_name; END$
条件判断
- 使用if实现条件判断:
IF search_condition THEN statement_list
[ELSE IF search_condition THEN statement_list]
[ELSE statement_list]
END IF;
参数定义
- 可以在创建存储过程的语法定义中定义参数,实现存储过程参数变量的输入和输出操作
CREATE PROCEDURE procedure_variable([IN | OUT | INOUT] 参数名 参数类型, ...)
BEGIN
...
END$
- IN : 输入参数,需要调用方调用时传入参数值.默认定义的参数为输入参数
- OUT : 输出参数,定义的参数可以作为执行存储过程的返回值,不需要进行返回操作,参数可以在函数执行结束,直接返回. 使用一个变量接收即可
- INOUT : 既可以作为输入参数,也可以作为输出参数. 也就是既可以是调用方调用时传入的参数值,也可以是执行存储过程的返回值
- MySQL中的变量:
- @ : 用户会话变量. 在变量名称前面使用,代表在整个用户会话中使用.会话结束,变量消失.
- @@ : 系统变量
选择结构
- case结构:
CASE
WHEN when_value THEN statement;
[WHEN when_value THEN statement;]
...
[ELSE statement;]
END CASE;
--
CASE
WHEN search_condition THEN statement;
[WHEN search_condition THEN statement;]
...
[ELSE statement;]
END CASE;
循环结构
while循环
- while: 条件循环控制语句,满足条件则进入循环
WHILE search_condition DO
statement;
END WHILE;
repeat循环
- repeat: 条件循环控制语句,满足条件则退出循环
REPEAT
statement;
UNTIL search_condition
END REPEAT;
loop循环
- loop: 使用loop语句可以实现简单的循环,退出循环的条件需要使用到其余的语句定义,否则会进入死循环. 通常情况下,使用leave语句实现循环退出
[alias:] LOOP
statement;
leave [alias];
END LOOP [alias];
- leave:
- 用来从标注的流程结构中退出
- 通常和BEGIN…END或者循环结构联合使用
游标
- 游标: 用来存储查询结果集的数据类型
- 在存储过程和存储函数中可以使用游标对结果集进行循环地处理
- 游标的使用方式包括声明游标,开启游标,获取游标和关闭游标
- 声明游标:
DECLARE cursor_name CURSOR FOR select_statement;
- 开启游标:
OPEN cursor_name;
- 获取游标: 每次获取结果集中的一行数据
FETCH cursor_name INTO var_name [,var_name...];
- 关闭游标:
CLOSE cursor_name;
- MySQL中的句柄:
DECLARE EXIT HANDLER FOR NOT FOUND SET varaible_name = variable_value
- 注意: 如果游标和句柄联合使用时,句柄定义语句要紧接在游标定义语句之后
存储函数
- 存储函数是有返回值的
创建存储函数
- 创建存储函数:
CREATE FUNCTION function_name([function_param param_type])
RETURN return_type
BEGIN
statement
END$
调用存储函数
- 获取存储函数的返回值:
SELECT function_name(param);
删除存储函数
- 删除存储函数:
DROP FUNCTION [IF EXISTS] function_name;
- 存储函数的语法和存储过程的语法是一样的
触发器
基本概念
- 触发器的定义: 触发器是与数据库表有关的数据库对象. 可以在INSERT, UPDATE, DELETE操作之前或者之后,触发并执行触发器中定义的SQL语句集合
- 触发器的特点:
- 可以协助应用在数据库端确保数据的完整性
- 可以进行日志记录,数据校验操作等
- 行记录变量: 可以使用行记录变量OLD和NEW来引用触发器中发生变化的记录内容
- MySQL中的触发器目前只支持行级触发,不支持语句级触发
| 触发器类型 | 行记录变量 |
|---|---|
| INSERT 型触发器 | NEW 表示将要或者已经新增的记录内容 |
| UPDATE 型触发器 | OLD 表示修改之前的记录内容 NEW 表示修改之后的记录内容 |
| DELETE 型触发器 | OLD 表示将要或者已经删除的记录内容 |
创建触发器
- 创建触发器:
CREATE TRIGGER trigger_name
BEFORE/AFTER INSERT/UPDATE/DELETE
ON table_name
FOR EACH ROW
BEGIN
sql_statement;
END$
查看触发器
- 可以通过以下命令查看触发器的状态和语法等信息
SHOW TRIGGERS;
删除触发器
- 可以删除指定数据库中的触发器,默认为当前数据库
DROP TRIGGER [schema_name.]trigger_name;
以上是关于MySQL的概念的主要内容,如果未能解决你的问题,请参考以下文章