mysql基本理论
Posted Kali-BugChen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql基本理论相关的知识,希望对你有一定的参考价值。
第二章 mysql基础
一、数据库基础
1、在dos窗口中连接mysql服务器。
(1)普通用户进入dos窗口
第一次安装mysql的时候,数据库是没有密码的,这时候使用输入win+R,然后输入cmd进入dos窗口,然后退出dos窗口,因为这样进入dos窗口是普通用户的形式进入dos窗口,mysqld install指令会失效。
第一步:使用win+R进入运行页面
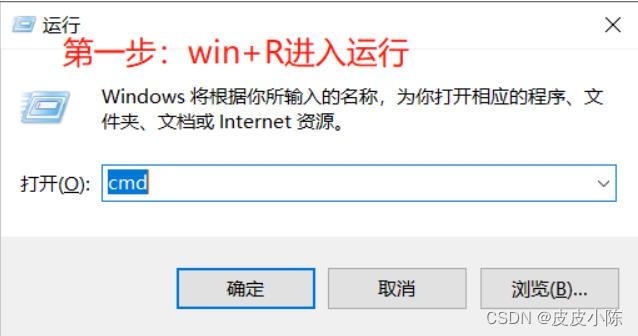
第二步:输入指令mysqld install指令

第三步:查看mysqld install指令是否运行成功
注意:mysqld是mysql服务器相关的指令,mysqld install是安装mysql服务器。mysqld start是启动mysql服务器,mysqld stop是停止mysql服务器。
(2)超级管理员进入dos窗口
第一步:以管理员的身份打开dos窗口

第二步:使用mysqld install 安装mysql服务器

注意:由于我之前已经安装了mysql服务器,所以提示信息为“The service already exists!”,如果没有安装mysql服务器的,显示的是successufly的提示信息。
第三步:使用mysqld start启动MySQL服务器
第四步:使用mysqld stop停止MySQL服务器即可。
2、普通用户在dos窗口连接mysql服务器
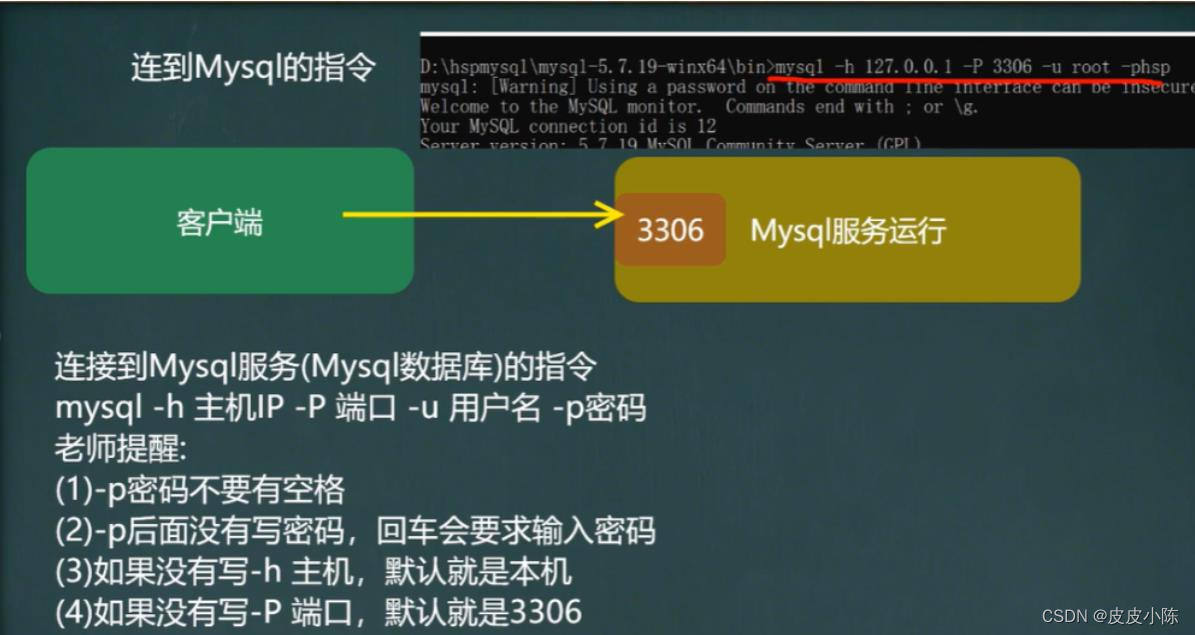
进入dos窗口之后,我们可以选择两种方式连接mysql,即本机连接和远程连接
(1)本机连接:mysql -u+mysql用户名 -p+mysql用户密码
一般情况下,我们使用的是mysql超级管理员的身份登录mysql,即mysql -uroot -proot登录,因为我的mysql超级管理员的密码为root,用户名也为root。出现以下的这种情况就表示连接成功了。
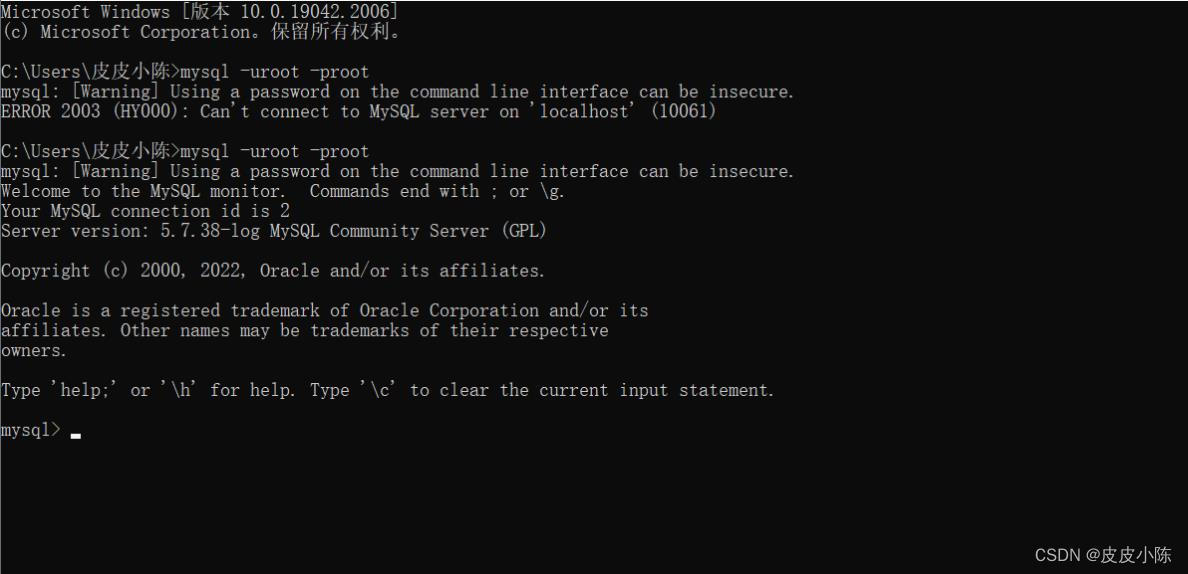
当我连接成功本地mysql服务器之后,我们可以使用exit指令退出连接,出现Bye的提示信息之后,表示我们退出连接。

注意:我们在连接的时候,可能会存在连接不上mysql服务器的情况,这时候不需要担心,可能是我们把计算机上的mysql服务器停止了了,这样的话肯定是无法连接的,这时候只需要将mysql服务器启动即可。
连接失败:

启动MySQL服务器:
启动成功:
(2)远程连接:mysql -u+mysql用户 -p+mysql用户密码 -h+远程连接的主机ip
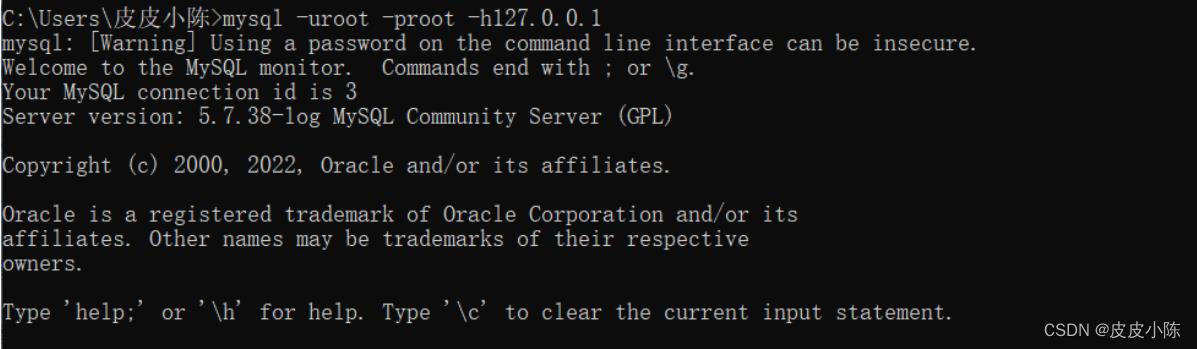
以本机为案例,本机的ip地址为127.0.0.1,-h参数填写本机地址,即可连接到本机,如果知道远程主机的ip地址,即可连接远程主机的mysql服务器。
总结:
1.我们在进行mysql服务器的连接时,必须保证mysql服务器是启动的。以管理员的身份进入dos窗口——》mysqld install 安装mysql服务器——》mysqld start启动服务器
2.mysql服务器的连接方式有两种:本地连接和远程连接
1)本地连接:mysql -u -p
其中:
-u:u指的是user,即mysql用户名,可以是普通用户,也可以是mysql的超级管理员,在练习中,我们使用的是root用户,即超级管理员,在工作中,用户是由DB(数据库管理员进行分配的),而DB就是root。
-p:指的是mysql用户对应的密码
2)远程连接:mysql -u -p -h
-u和-p和本地连接一样,-h则是用来指定需要连接mysql所在主机的ip地址,如果ip=127.0.0.1和连接本机就是一样的。
思考:如果我们连接mysql的时候,需要指定端口号怎么办?
使用mysql -h -P -u -p即可(原理和上面一样的)
3、数据库语句的分类(以下列举的是常用的sql语句)
(1)数据库定义语句(DDL ):
数据库定义语言,负责数据结构定义与数据库对象的定义,由create、alter、drop三个语法组成。
1.1数据库的创建
创建一个test数据库:
-- 默认字符集创建数据库
CREATE DATABASE test;
使用这种方式创建的数据库,它采用字符集编码是ltain1,因此我们需要在创建数据库的时候,指定数据库的字符编码集,这样的话,防止出现乱码的现象。
-- 指定字符集创建数据库
CREATE DATABASE test CHARACTER SET utf8;
使用character set utf8来指定数据库的编码方式。
使用test数据库:
-- 使用数据库
USE test;
删除test数据库:
-- 删除数据库
DROP DATABASE test;
1.2 数据表的创建
创建一个student表:
-- 默认字符集创建表
CREATE TABLE student(sname CHAR(50),sclass VARCHAR(50),sid INT(11));
使用这种方式创建的数据表,它采用字符集编码是ltain1,因此我们需要在创建数据库的时候,指定数据库的字符编码集,这样的话,防止出现乱码的现象。
-- 指定字符集创建表
CREATE TABLE student(sname CHAR(50),sclass VARCHAR(50),sid INT(11)) CHARACTER SET utf8;
使用character set utf8来指定数据库的编码方式。
注意:是utf8,而不是utf-8.
修改表student的名称:
-- 将student表的名称改成student1
ALTER TABLE student RENAME TO student1;
在student表指定的位置插入新的字段:
-- 在student1表指定的位置插入新的字段sage,默认是在student1的最后一个字段后加入新字段
ALTER TABLE student1 ADD COLUMN sage INT(11) ;
-- 在student1表指定的位置插入新的字段sdress,在sname之后插入
ALTER TABLE student1 ADD COLUMN sdress VARCHAR(50) AFTER sname;
删除student1中的sage这一列:
-- 删除student1中的sage这一列
ALTER TABLE student1 DROP COLUMN sage;
将student1中的sdress修改成sage:
-- 将student1中的sdress修改为sage
ALTER TABLE student1 CHANGE sdress sage INT(11);
将student1中的sid修改成varchar类型的数据:
-- 将student1中的sid修改成varchar类型的数据
ALTER TABLE student1 MODIFY sid VARCHAR(50);
数据库定义语言DDL总结:
1.操作数据库
1.1 默认创建数据库(采用的是ltain1的字符集编码)
create database 数据库名称;
1.2 指定字符集编码创建数据库
create database 数据库名称 character set utf8;
1.3 使用数据库
use 数据库名称
1.4 删除数据库
drop database 数据库名称
2.操作表
1)创建表:
1.1 默认字符集创建表格
create table 表名称(字段名称 数据类型(数据类型长度),…);
1.2 指定字符集创建表格
create table 表名称(字段名称 数据类型(数据类型长度),…)character set utf8;
1.3 指定存储引擎创建表格
create table 表名称(字段名称 数据类型(数据类型长度),…)engine = InnoDB;
1.4 在创建表格的时候,同时指定表格的相关属性
create table 表名称(字段名称 数据类型(数据类型长度),…)engine= InnoDB default charset=utf8 comment=‘学生信息表’;comment是表的注释。
2)删除表:
2.1 删除表
drop table 表名称;
3)修改表:
3.1 修改表的名称
alter table 表名称(旧) rename to 表名称(新);
3.2 修改表的注释
alter table 表名称 comment ‘新注释’;
3.3 在指定位置插入新字段
alter table 表名称 add column 字段名称 字段数据类型(长度) 是否为空 comment ’注释‘ after 指定字段名称;
注意:如果没有after之后的语句,默认在表的最后一个字段之后插入。atler table表示选中表。存储引擎作用在表上,并步作用在数据库上。
3.4 删除指定名称的字段
alter table 表名称 drop column 字段名称;
3.5 修改字段类型(字段类型、注释、默认值等)
alter table 表名称 modify column 字段名称 新数据类型 (长度) 新默认值 新注释;
(2)数据库操作语句(DML):
数据库操纵语言,负责对数据库对象进行访问和修改等相关操作,由insert、update、delete组成。
2.1 插入数据(insert)
单条数据插入(全部字段的插入):
-- 单条数据的插入(全部字段)
INSERT INTO student1 VALUES('陈文财',25,'三班','s001');
单条数据的插入(部分字段的插入):
-- 单条字段的插入(部分字段的插入)
INSERT INTO student1(sname,sage,sclass) VALUES('张三',18,'一班');
INSERT INTO student1(sage,sclass,sid) VALUES(20,'二班','s002');
多条数据的插入:
-- 多条数据的插入
INSERT INTO student1(sname,sage,sclass,sid) VALUES('李四',20,'一班','s001'),('王五',21,'二班','s002'),('麻子',22,'3班','s001');
INSERT INTO student1(sname,sage,sclass) VALUES('李四1',20,'一班'),('王五1',21,'二班'),('麻子1',22,'3班');
2.2 更新数据(update)
更改单个字段的数据:
-- 将姓名为空的设置为未知
UPDATE student1 SET sname='未知' WHERE sname IS NULL;
-- 没有条件,全部改变
UPDATE student1 SET sname='亚力士多长';
更改多个字段的数据:
UPDATE student1 SET sname='先王';
-- 将姓名为孙晓晓的数据修改
UPDATE student1 SET sclass ='三班',sid='s003' WHERE sname='孙晓晓';
-- 将姓名为麻子的数据修改
UPDATE student1 SET sname='赵信',sage=26 WHERE sname='麻子';
2.3 删除数据
删除所有数据:
-- 删除单条数据
DELETE FROM student1 WHERE sname = '陈德发';
删除所有数据:
DELETE FROM student1 WHERE sname = '陈德发';
-- 删除所有数据
DELETE FROM student1 ;
数据库操纵语句总结(DML):
1、新增数据(insert)
1.1单条完整数据的新增
insert into 表名称(列名称,列名称,列名称,列名称)values(数据,数据,数据,数据);
1.2 单条不完整数据的新增(第四列不添加,mysql用null来补充)
insert into 表名称(列名称,列名称,列名称) values(数据,数据,数据);
注意:当插入的是完整的数据的时候,表名称后面的每一列不用写:insert into 表名称 values(数据,数据,数据,数据);
1.3 新增多条完整的数据
insert into 表名称(列名称,列名称,列名称,列名称)values(数据,数据,数据,数据),values(数据,数据,数据,数据),values(数据,数据,数据,数据),values(数据,数据,数据,数据)…;
1.4 新增多条不完整的数据(第四列不添加,mysql用null来补充)
insert into 表名称(列名称,列名称,列名称) values(数据,数据,数据),(数据,数据,数据),(数据,数据,数据)…;
2、更新数据(update)
2.1 更新所有数据单个字段的值(没有条件就更新表中指定字段的所有值)
update 表名称 set 字段名称=数据;
2.2 更新所有数据多个字段的值(没有条件就更新表中指定字段的所有值)
update 表名称 set 字段名称=数据,字段名称=数据,字段名称=数据,字段名称=数据…;
注意:需要更新多个字段的值的时候,只需要用逗号隔开即可。
2.3 更新指定条件下的某个字段的值
update 表名称 set 字段名称=数据 where 条件;
3、删除数据(delete)
3.1 删除所有数据
delete from 表名称;
3.2 删除某条数据
delete from 表名称 where 条件;
备注:在实际的工作中,我们很少对数据进行删除的,因为数据对于公司来说是一笔价值,一般是通过删除标识符来标识,对于用户来说,他删除数据就是改变了该数据的删除标识状态,并未真正地删除数据。
(3)数据库查询语句(DQL Data Query Language):
数据库查询语言,只负责数据的查询操作而不会对数据库的数据进行修改或者删除,它是数据库的基本语句。关键词为select,通常配合where、group by等使用。说明:为了提升数据库的查询效率,在查询哪一列数据,是要全部标识出来的,本文在演示的过程中将查询所有列的情况用*来替代。
3.1 查询student1所有数据
-- 查询student1中的所有数据
SELECT * FROM student1;
3.2 查询单个或者多个字段的信息
-- 查询student1中的所有姓名
SELECT sname FROM student1;
-- 查询student1中所有sclass
SELECT sclass FROM student1;
-- 查询student1中的姓名和年龄
SELECT sname,sage FROM student1;
3.2 指定条件下查询某条数据
-- 查询student1中年龄为21的姓名
SELECT sname FROM student1 WHERE sage=21;
3.3 模糊查询
-- 查询姓王的所有数据
SELECT * FROM student1 WHERE sname LIKE '王%';
数据库查询语言总结(DQL):
1.数据库中常用的关键词(条件)
关键词 说明 or 或 and 与 between a and b 介于a和b之间([a,b]) having 分组之后附加的条件 group by 分组 oder by 排序查询 (asc升序;desc降序) in 存在于某个值中 not in 不存在于某个值中 inner join … on 多表连接 left join … on 左外连接 right jion … on 右外连接 left(right,inner)out jion … on 去重 distinct:(放在某个字段的前面即可) 去重 like ”关键词%“ , like ”like % 关键词“,like “%关键词%” 提取含有关键词的数据 where 1=1 全选 where 1=2 全不选 limit a to b 查询从a+1行开始的b条数据(分页查询) top a(用在select后面):select top a from 表名称 显示前a条数据 as:select * from student1 as s1;select count(列名) as '总数’ from student1; 给表或者字段起别名 2、数据库中常用的内置函数
函数 说明 案列 count(字段名称) 计算某个字段的总数 – 统计表student1中所有的姓名
SELECT COUNT(sname) AS ‘总数’ FROM student1 AS s1;avg(字段名称) 计算某个字段的平均值 – 计算所有学生的平均年龄
SELECT AVG(sage) AS ‘平均年龄’ FROM student1;sum(字段名称) 对某个字段进行求和 – 计算所有学生的年龄综合
SELECT SUM(sage) AS ‘年龄综合’ FROM student1;max(字段名称) 找出某个字段中的最大值 – 找出student1中的最大年龄
SELECT MAX(sage) AS ‘最大年龄’ FROM student1;min(字段名称) 找出某个字段中的最小值 – 找出student1中的最小年龄
SELECT MIN(sage) AS ‘最大年龄’ FROM student1;注意:以上的函数可以作为查询的条件,也可以作为单独查询的一列。
1.选择查询:
select * from 表名 where 范围;
2.完全查询:select * from 表名;
3.模糊查询:select * from 表名 where 列名 like ‘%value%’(查询包含value的值);
4.排序查询(倒序,默认为正序):select * from 表名 order by 列名 desc;
5.计数查询:select count as 别名 from 表名;
6.求和查询:select sum(field) as 别名 from 表名;
7.平均值查询:select avg(filed) as 别名 from 表名;
8.最大值查询:select max(filed) as 别名 from 表名;
9.最小值查询:select min(filed) as 别名 from 表名;
10.四舍五入查询:select round(min(filed),要保留的小数位数) as 别名 from 表名;
11.去重查询:select distinct 列名 from 表名;
12.分组查询:select * from 表名 group by 列名;
13.多条件查询:select * from 表名 where 列名=‘范围’ and 列名=‘范围’;
14.不确定条件查询:select * from 表名 where 列名=‘范围’ or 列名=‘范围’;
15.多条件分组求值查询:select 列名,min(filed)from 表名 where 列名=‘范围’ group by 列名 having sum(列名);
16.子查询(子查询的结果作为主查询的条件):select * from 表名 where=(select id from 表名 where 列名=‘范围’);
17.连表查询(内连接):select * from 表名 inner join 表名 on 主键=外键(必须有主外键);
18.连表查询(内连接)(去重):select * from 表名 inner out join 表名 on 主键=外键(必须有主外键);注:内连接只显示相关联的数据
19.连表查询(左外连接)(显示左表的全部信息和右表相关联的信息):select * from 表名 left join 表名 on 主键=外键(必须有主外键);
20.连表查询(右外连接)(显示右表的全部信息和左表相关联的信息):select * from 表名 right join 表名 on 主键=外键(必须有主外键);
21.连表查询(全外连接)(显示两个表中的所有记录):select * from 表名 full/cross join 表名 on 主键=外键(必须有主外键);
22.说明:几个高级查询运算词\\nA:union(结合两个结果表并消除其中的重复行而派生出另一个表);
例:select name from 表名1 union select name from 表名2(去除name的重复行);
B:except(通过包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重复行而派生出一个结果表;
C:intersect(通过只包括 TABLE1 和 TABLE2 中都有的行并消除所有重复行而派生出一个结果表);注:当这三个运算符与all一起使用时不消重复的行。
(4)数据库权限控制语句(DCL):
数据库控制语言,对数据库访问权限进行控制的一种sql语言,主要是对访问数据的用户进行授权操作。
(5)事务处理语句(TPL):
它的语句能确保DML语句影响的表所有行及时得到更新,主要由begin、transtaction、commit、rollbock组成。
4、查看当前的数据库和表
(1)查看当前数据库
show databases;
(2)查看当前数据库中的表的数量
use 数据库名称;
show tables;
5、数据库的导入与导出
(1)数据库的导出(>)大于符号
mysqldump -u用户名 -p密码 数据库 表1 表2 … 表n > d:\\\\文件名.sql;
(2)数据库的导入(<)小于符号
mysql -u用户名 -p密码 数据库 < d:\\\\文件名.sql;
6、内连接(自链接)
自连接是指同一张表的连接查询【将同一张表看作两张表】。
-- 多表查询的 自连接
-- 思考题: 显示公司员工名字和他的上级的名字
-- 老韩分析: 员工名字 在emp, 上级的名字的名字 emp
-- 员工和上级是通过 emp表的 mgr 列关联
-- 这里老师小结:
-- 自连接的特点 1. 把同一张表当做两张表使用
-- 2. 需要给表取别名 表名 表别名
-- 3. 列名不明确,可以指定列的别名 列名 as 列的别名
SELECT worker.ename AS '职员名' , boss.ename AS '上级名'
FROM emp worker, emp boss
WHERE worker.mgr = boss.empno;
SELECT * FROM emp;
7、外连接
(1)问题的提出

(2)左外连接和右外连接



-- 外连接
-- 比如:列出部门名称和这些部门的员工名称和工作,
-- 同时要求 显示出那些没有员工的部门。
-- 使用我们学习过的多表查询的SQL, 看看效果如何?
SELECT dname, ename, job
FROM emp, dept
WHERE emp.deptno = dept.deptno
ORDER BY dname
SELECT * FROM dept;
SELECT * FROM emp;
-- 创建 stu
/*
id name
1 Jack
2 Tom
3 Kity
4 nono
*/
CREATE TABLE stu (
id INT,
`name` VARCHAR(32));
INSERT INTO stu VALUES(1, 'jack'),(2,'tom'),(3, 'kity'),(4, 'nono');
SELECT * FROM stu;
-- 创建 exam
/*
id grade
1 56
2 76
11 8
*/
CREATE TABLE exam(
id INT,
grade INT);
INSERT INTO exam VALUES(1, 56),(2,76),(11, 8);
SELECT * FROM exam;
-- 使用左连接
-- (显示所有人的成绩,如果没有成绩,也要显示该人的姓名和id号,成绩显示为空)
SELECT `name`, stu.id, grade
FROM stu, exam
WHERE stu.id = exam.id;
-- 改成左外连接
SELECT `name`, stu.id, grade
FROM stu LEFT JOIN exam
ON stu.id = exam.id;
-- 使用右外连接(显示所有成绩,如果没有名字匹配,显示空)
-- 即:右边的表(exam) 和左表没有匹配的记录,也会把右表的记录显示出来
SELECT `name`, stu.id, grade
FROM stu RIGHT JOIN exam
ON stu.id = exam.id;
-- 列出部门名称和这些部门的员工信息(名字和工作),
-- 同时列出那些没有员工的部门名。5min
-- 使用左外连接实现
SELECT dname, ename, job
FROM dept LEFT JOIN emp
ON dept.deptno = emp.deptno
-- 使用右外连接实现
SELECT dname, ename, job
FROM emp RIGHT JOIN dept
ON dept.deptno = emp.deptno
--
二、约束
1、mysql中的关系模式
(1)一对一
(2)一对多
(3)多对多
注意:对于多对的情况需要建立第三张表来维护两张表之间的关系。
1、表1和表2称为表3的主表,表3是表1和表2的从表。
2、表3的主键是主键是表1和表2的主键的组合。
3、在插入数据的时候,先出入主表数据,在插入从表数据。
4、在从表(表3)建立联合组建的时候,必须依赖于表1和表2,并且数据类型和长度与主表保持一致。
2、约束含义
约束是用于确保数据库的数据满足特定的商业规则。在mysql中主要有五种约束:
非空约束(not null)、唯一约束(unique)、primary key(主键约束),foreign key(外键约束)和check约束。
(1)主键约束(primary key):用于唯一标识一行数据的。基本使用为 字段名 字段类型 primary key。
使用细节:
- primary key不能重复而且不能为null。
- 一张表最多只能有一个主键,但是该主键可以是复合主键。
- 主键的指定方式有两种:(1)直接在字段后指定:字段名 primary key(2)在表定义最后写primary key(字段名)。
- 使用desc 表名可以看到primary key的情况。
- 在实际开发种,每张表都有一个主键。
案例:
-- 主键使用
-- id name email
CREATE TABLE t1
(id INT PRIMARY KEY, -- 表示id列是主键
`name` VARCHAR(32),
email VARCHAR(32));
-- 主键列的值是不可以重复
INSERT INTO t1
VALUES(1, 'jack', 'jack@sohu.com');
INSERT INTO t1
VALUES(2, 'tom', 'tom@sohu.com');
INSERT INTO t1
VALUES(1, 'hsp', 'hsp@sohu.com');
SELECT * FROM t1;
-- 主键使用的细节讨论
-- primary key不能重复而且不能为 null。
INSERT INTO t1
VALUES(NULL, 'hsp', 'hsp@sohu.com');
-- 一张表最多只能有一个主键, 但可以是复合主键(比如 id+name)
CREATE TABLE t2
(id INT PRIMARY KEY, -- 表示id列是主键
`name` VARCHAR(32), PRIMARY KEY -- 错误的
email VARCHAR(32));
-- 演示复合主键 (id 和 name 做成复合主键)
CREATE TABLE t2
(id INT ,
`name` VARCHAR(32),
email VARCHAR(32),
PRIMARY KEY (id, `name`) -- 这里就是复合主键
);
INSERT INTO t2
VALUES(1, 'tom', 'tom@sohu.com');
INSERT INTO t2
VALUES(1, 'jack', 'jack@sohu.com');
INSERT INTO t2
VALUES(1, 'tom', 'xx@sohu.com'); -- 这里就违反了复合主键
SELECT * FROM t2;
-- 主键的指定方式 有两种
-- 1. 直接在字段名后指定:字段名 primakry key
-- 2. 在表定义最后写 primary key(列名);
CREATE TABLE t3
(id INT ,
`name` VARCHAR(32) PRIMARY KEY,
email VARCHAR(32)
);
CREATE TABLE t4
(id INT ,
`name` VARCHAR(32) ,
email VARCHAR(32),
PRIMARY KEY(`name`) -- 在表定义最后写 primary key(列名)
);
-- 使用desc 表名,可以看到primary key的情况
DESC t4 -- 查看 t4表的结果,显示约束的情况
DESC t1
(2)非空约束(not null)和唯一约束(unique)
-
非空约束:如果在列上定义了not null,那么在插入数据的时候,就必须提供该列的数据。约束:字段名 字段类型 not null;
-
唯一约束:当定义了唯一约束之后,该列的值就不能重复。约束:字段名 字段类型 unique。
-
唯一约束细节:
1)如果唯一约束没有指定not null,则unique字段可以有多个null。
2)一张表可以有多个unique字段。
-- unique的使用
CREATE TABLE t5
(id INT UNIQUE , -- 表示 id 列是不可以重复的.
`name` VARCHAR(32) ,
email VARCHAR(32)
);
INSERT INTO t5
VALUES(1, 'jack', 'jack@sohu.com');
INSERT INTO t5
VALUES(1, 'tom', 'tom@sohu.com');
-- unqiue使用细节
-- 1. 如果没有指定 not null , 则 unique 字段可以有多个null
-- 如果一个列(字段), 是 unique not null 使用效果类似 primary key
INSERT INTO t5
VALUES(NULL, 'tom', 'tom@sohu.com');
SELECT * FROM t5;
-- 2. 一张表可以有多个unique字段
CREATE TABLE t6
(id INT UNIQUE ,
一台数据库服务器中会创建很多数据库(一个项目,会创建一个数据库)。
在数据库中会创建很多张表(一个实体会创建一个表)。
在表中会有很多记录(一个对象的实例会添加一条新的记录)
表和表时间会有一些约束
主键约束:primary key 主键约束默认就是唯一 非空的()auto-increment实现自增长
唯一约束:unique
非空约束:not null
SQL数据库的结构化查询语句
DDL 数据定义语言 create(创建)/drop(放弃)/alert(改变)
DML 数据操纵语音 insert(插入)/update(更新)/delete(删除)
DCL 数据控制语言 grant/if
DQL 数据查询语言 select(查看)
数据库的增删改查
show dataabases 展示所有的数据库
create database 数据库名 [character 字符集 collate 校对规则] 创建新的数据库
use 数据库名称 某一个数据库
drop database 数据库名 删除数据库
select database() 查看正在使用的数据库
show create database 数据库名称 查看指定的数据库
alert database chatater set 字符集 collate 校对规则
表的增删改查
创建表:create tabe 表名
字段名称 字段类型(长度) 约束,
字段名称 字段类型(长度) 约束,
添加字段:Altle table 表名 add 字段名 类型(长度) 约束
修改列:altle table 表名 modify 列名 类型 (长度) 约束
删除字段:altle table 表名 drop 字段名
修改字段:altle table 表名 change 旧字段名 新字段名 类型(长度) 约束
查看建表结构:desc 表名;
查看所有的表字段:show tables;
查看建表语句 show create table 表名
删除表 drop table表名
修改表名:rename table 表名 to 新表名
修改表的字符集:altle table 表名 character set 字符集(默认的是utf8 的)
建表常见的约束
主键约束:primary key 一般实现自增 auto-increment
非空约束:notnull
唯一约束:unique