五使用Python操作数据库
Posted Lvcx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了五使用Python操作数据库相关的知识,希望对你有一定的参考价值。
(六)使用Python操作数据
程序运行时,数据是在内存中。当程序终止时,通常需将数据保存在磁盘上。为了便于程序保存和读取数据,并能直接通过条件快速查询到指定数据,数据库(Database)这种专门用于集中存储和查询的软件应运而生。本节介绍Python数据库编程接口知识,以及使用SQLite和mysql存储数据的方法。
1. 数据库编程接口
在项目开发中,数据库应用必不可少。数据库种类很多,有如SQLite、MySQL、Oracle等,它们功能基本是一样的,为了对数据库进行同一的操作,大多数语言都提供了简单的、标准化的数据库接口(API)。在Python Database API 2.0规范中,定义了Python数据库API接口的各个部分,如模块接口、连接对象、游标对象、类型对象和构造器、DB API的可选扩展以及可选的错误机制等。
1. 连接对象
数据库连接对象(Connection Object)主要提供获取数据库游标对象和提交/回滚事务的方法,以及关闭数据连接。
1. 获取连接对象
如何获取连接对象呢?这就需要使用connect()函数,该函数有多个参数,具体使用哪个参数,取决于使用的数据库类型。例如,如果访问Qracle数据库和MySQL数据库模块,这些模块在获取连接对象时,都需要使用connect()函数。
connect()函数常用的参数及说明
| 参数 | 说明 |
|---|---|
| dsn | 数据源名称,给出该参数表示数据库依赖 |
| user | 用户名 |
| password | 用户密码 |
| host | 主机名 |
| database | 数据库名称 |
使用PyMySQL模块连接MySQL数据库。需要预先安装PyMSQL模块。
pip install PyMySQL
import pymysql
conn = pymysql.connect(host="localhost",
user="root",
password="数据库密码",
db="db_school",
charset="utf8",
cursorclass=pymysql.cursors.DictCursor)
pymysql.connect()使用的参数与表中并不完全相同。在使用时,要以具体的数据库模块为准。
2. 连接对象的方法
connect()函数返回连接对象,该对象表示当前与数据库的会话。连接对象支持的方法如下表:
| 方法 | 说明 |
|---|---|
| close() | 关闭数据库连接。 |
| commit() | 提交事务。 |
| rollback() | 回滚事务。 |
| cursor() | 获取游标对象,操作数据库,如执行DML操作,调用存储过程等。 |
commit()方法用于提交事务,事务主要用于处理大量、复杂度高的数据。如果操作的是一系列的动作,例如,张三给李四转账,有以下两种操作:
(1)张三账户金额减少;
(2)李四账户金额增加。
这时使用事务可以维护数据库的完整性,保证两个操作要么全部执行,要么全部不执行。
2. 游标对象
游标对象(Cursor Object)代表数据库中的游标,用于指示抓取数据操作的上下文,主要提供执行SQL语句、调用过程、获取查询结果等方法。
如何获取游标对象呢?通过使用连接对象的cursor()方法可以获取游标对象。
游标对象的主要属性及说明
| 属性 | 说明 |
|---|---|
| description属性 | 表示数据库列类型和值的描述信息。 |
| rowcount属性 | 返回结果的行数统计信息,如SELECT、UPDATE、CALLPROC等。 |
游标对象的方法及方法说明
| 方法名 | 说明 |
|---|---|
| callproc(procname[, parameters]) | 调用存储过程,需要数据库支持。 |
| close() | 关闭当前游标。 |
| execute(operation[, parameters]) | 执行数据库操作,SQL语句或者数据库命令。 |
| executemany(operation, seq_of_params) | 用于批量操作,如批量更新。 |
| fetchone() | 获取查询结果集中的下一条记录。 |
| fetchmany(size) | 获取指定数量的记录。 |
| fetchall() | 获取结果集的所有记录。 |
| nextset() | 跳至下一个可用的结果集。 |
| arraysize() | 指定使用fetchmany()获取的行数,默认为1。 |
| setinputsizes(sizes) | 设置在调用execute*()方法时分配的内存区域大小。 |
| setoutputsize(sizes) | 设置列缓冲区大小,对大数据例如LONGS和BLOBS尤其有用。 |
2. 使用内置的SQLite
与许多其他数据库管理系统不同,SQLite不是一个客户端/服务器结构的数据库引擎,而是一种嵌入式数据库,该数据库本身就是一个文件。SQLite将整个数据库(包括定义、表、索引以及数据本身)作为一个单独的、可跨平台使用的文件存储在主机中。由于SQLite本身是使用C语言开发的,而且体积很小,所以经常被集成到各种应用程序中。Python就内置了SQLite3,所以在Python中使用SQLite数据库,不需要安装任何模块,直接可以使用。
Python操作数据库的通用流程图
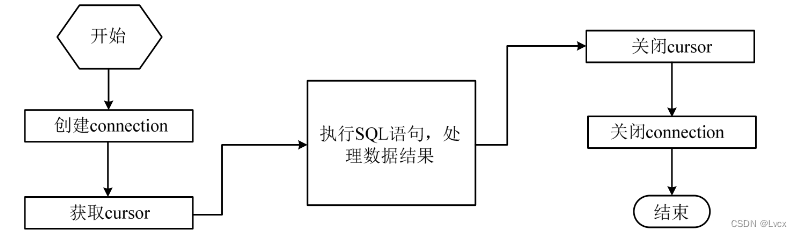1. 创建数据库文件
由于Python中已经内置了SQLite3,所以可以直接使用import语句导入SQLite3模块。
示例:创建SQLite数据库文件
创建一个mrsoft.db的数据库文件,然后执行SQL语句创建一个user(用户表),user表包含id和name两个字段。
代码如下:
import sqlite3
# 连接到SQLite数据库
# 数据库文件是mrsoft.db,如果文件不存在,会自动在当前目录创建
conn = sqlite3.connect("mrsoft.db")
# 创建一个Cursor
cursor = conn.cursor()
# 执行一条SQL语句,创建user表
cursor.execute("create table user(id int(10) primary key, name varchar(20))")
# 关闭游标
cursor.close()
# 关闭Connection
conn.close()
在上面代码中,使用sqlite3.connect()方法连接SQLite数据库文件mrsoft.db,由于mrsoft.db文件并不存在,所以会在本实例Python代码同级目录下创建mrsoft.db文件,该文件包含了user表的相关信息。

再次运行上面示例时,会出现提示信息:sqlite3.OperationalError:table user alread exists。这是因为user表已经存在。

2. 操作SQLite
1. 新增用户信息
向数据表中新增数据可以使用SQL中的insert语句。语法如下:
insert into 表名(字段名1, 字段名2, ... , 字段名n) values (字段值1, 字段值2, ... , 字段值n)
在上面示例创建的user表中,有2个字段,字段名分别为id和name,而字段值需要根据字段的数据类型来赋值,如id是一个长度为10的整型,name是长度为20的字符串类型数据。向user表中插入3条用户信息记录,则SQL语句如下:
cursor.execute('insert into user (id, name) values (1, "mrsoft")')
cursor.execute('insert into user (id, name) values (2, "andy")')
cursor.execute('insert into user (id, name) values (3, "李好丫")')
示例:新增用户数据信息
由于在前面的示例中已经创建了user表,所以本例中可直接操作user表,向user表中插入3条用户信息。此外,由于是新增数据,需要使用commit()方法提交事务。因为对于增加、修改和删除操作,使用commit()方法提交事务后,如果相应操作失败,可以使用rollback()方法回滚到操作之前的状态。新增用户数据信息具体代码如下:
import sqlite3
# 连接到SQLite数据库
# 数据库文件是mrsoft.db
# 如果文件不存在,会自动在当前目录创建
conn = sqlite3.connect("mrsoft.db")
# 创建一个Cursor
cursor = conn.cursor()
# 执行一条SQL语句,插入记录
cursor.execute("insert into user (id, name) values (1, 'mrsoft')")
cursor.execute("insert into user (id, name) values (2, 'andy')")
cursor.execute("insert into user (id, name) values (3, '李好丫')")
# 关闭游标
cursor.close()
# 提交事务
conn.commit()
# 关闭Connection
conn.close()
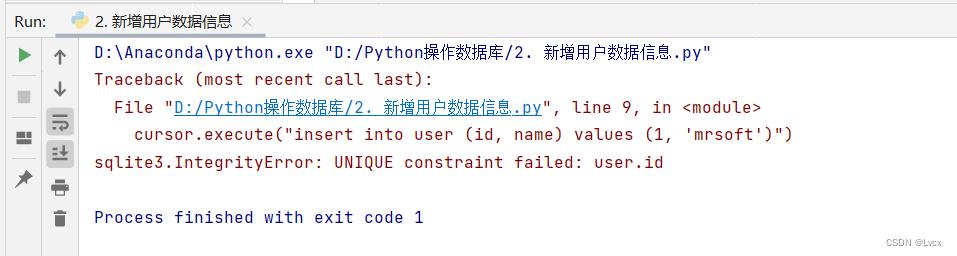
运行该程序,会向user表中插入3条记录。为验证程序是否正常运行,可以再次运行,提示如下信息,则说明插入成功(因为user表已经保存了上一次插入的记录,由于主键id具有唯一性,所以再次插入会报错):
2. 查看用户数据信息
查找数据表中的数据可以使用SQL中的select语句。语法如下:
select 字段名1, 字段名2, 字段名3, ... from 表名 where 查询条件
查看用户信息的代码与插入数据信息大致相同,不同点在于使用的SQL语句不同。此外,查询数据时通常使用如下3种方式。
查询数据时常用的3种方法
| 方法 | 说明 |
|---|---|
| fetchone() | 获取查询结果集中的下一条记录。 |
| fetchmany(size) | 获取指定数量的记录。 |
| fetchall() | 获取结构集的所有记录。 |
示例:使用3种方式查询用户数据信息
分别使用fetchone()、fetchmany()、fetchall()这3种方式查询用户信息。
使用fetchone()方法查询数据
import sqlite3
# 连接到SQLite数据库,数据库文件是mrsoftdb.db
conn = sqlite3.connect("mrsoft.db")
# 创建一个Cursor
cursor = conn.cursor()
# 执行查询语句
cursor.execute("select * from user")
# 获取查询结果方式1:
result1 = cursor.fetchone() # 使用fetchone()查询一条数据
print(result1)
# 关闭游标
cursor.close()
# 关闭Connection
conn.close()
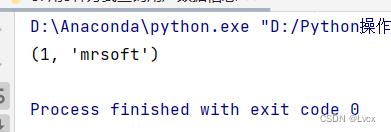
使用fetchone()方法返回的result1是一个元组:
使用fetchmany(size)方法查询数据
import sqlite3
# 连接到SQLite数据库,数据库文件是mrsoftdb.db
conn = sqlite3.connect("mrsoft.db")
# 创建一个Cursor
cursor = conn.cursor()
# 执行查询语句
cursor.execute("select * from user")
# # 获取查询结果方式1:
# result1 = cursor.fetchone() # 使用fetchone()查询一条数据
# print(result1)
# 获取查询结果方式2:
result2 = cursor.fetchmany(2) # 使用fetchmany(size)查询多条数据
print(result2)
# 关闭游标
cursor.close()
# 关闭Connection
conn.close()
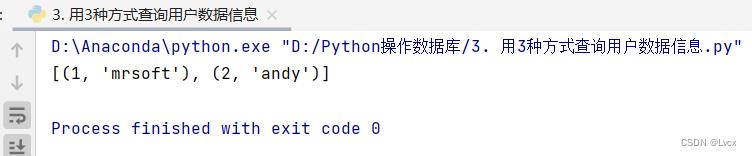
使用fetchmany()方法传递一个参数,其值为2,默认为1.返回的result2为一个列表,列表中包含两个元组。运行结果如下:
使用fetchall()方法查询数据
import sqlite3
# 连接到SQLite数据库,数据库文件是mrsoftdb.db
conn = sqlite3.connect("mrsoft.db")
# 创建一个Cursor
cursor = conn.cursor()
# 执行查询语句
cursor.execute("select * from user")
# # 获取查询结果方式1:
# result1 = cursor.fetchone() # 使用fetchone()查询一条数据
# print(result1)
# # 获取查询结果方式2:
# result2 = cursor.fetchmany(2) # 使用fetchmany(size)查询多条数据
# print(result2)
# 获取查询结果方式3:
result3 = cursor.fetchall()
print(result3)
# 关闭游标
cursor.close()
# 关闭Connection
conn.close()
使用fetchall()方法返回的result3是一个列表,列表中包含所有user表中数据组成的元组。运行结果如下:

修改前面的代码如下:
import sqlite3
# 连接到SQLite数据库,数据库文件是mrsoftdb.db
conn = sqlite3.connect("mrsoft.db")
# 创建一个Cursor
cursor = conn.cursor()
# 执行查询语句
# cursor.execute("select * from user")
# # 获取查询结果方式1:
# result1 = cursor.fetchone() # 使用fetchone()查询一条数据
# print(result1)
# # 获取查询结果方式2:
# result2 = cursor.fetchmany(2) # 使用fetchmany(size)查询多条数据
# print(result2)
# # 获取查询结果方式3:
# result3 = cursor.fetchall()
# print(result3)
cursor.execute("select * from user where id > ?", (1, )) # 查询id值大于1的记录
result4 = cursor.fetchall()
print(result4)
# 关闭游标
cursor.close()
# 关闭Connection
conn.close()
在select查询语句中,使用问号作为占位符代替具体的数值,然后使用一个元组来替换问号(注意,不要忽略元组中最后的逗号)
上面的这条查询语句等价于:
cursor.execute("select * from user where id > 1")
运行结果如下:
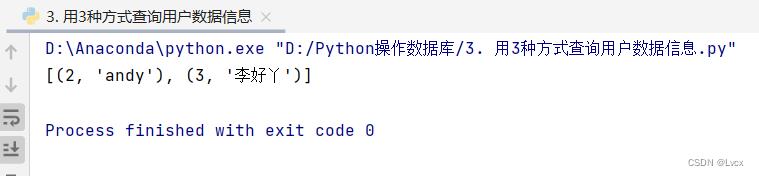
使用占位符的方式可以避免SQL注入的风险,推荐使用占位符这种方式。
3. 修改用户数据信息
修改数据表中的数据可以使用SQL中的update语句,语法如下:
update 表名 set 字段名 = 字段值 where 查询条件
示例:修改用户数据信息
将SQLite数据库中user表id=1的数据的name字段值“mrsoft”改为“MR”,并使用fetchall()方法获取修改后表中的所有数据。
import sqlite3
#连接到SQLite数据库,数据库文件是mrsoft.db
conn = sqlite3.connect("mrsoft.db")
# 创建一个Cursor
cursor = conn.cursor()
cursor.execute("update user set name = ? where id = ?", ("MR", 1))
cursor.execute("select * from user")
result = cursor.fetchall()
print(result)
# 关闭游标
cursor.close()
# 关闭Connection:
conn.close()
运行结果:
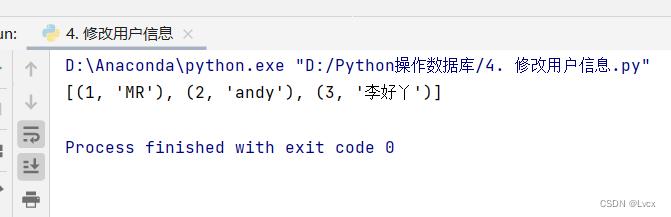
4. 删除用户数据
删除数据表中的数据可以使用SQL中的delete语句,语法如下:
delete from 表名 where 查询条件
示例:删除用户数据信息
将SQLite数据库中user表ID为1的数据删除,并使用fetchall()获取表中的所有数据,查看删除后的结果。
import sqlite3
# 连接到SQLite数据库,数据库文件是mrsoft.db
conn = sqlite3.connect("mrsoft.db")
# 创建一个Cursor
cursor = conn.cursor()
# 删除ID为1的用户
cursor.execute("delete from user where id = ?", (1, ))
# 获取所有用户信息
cursor.execute("select * from user")
# 记录查询结果
result = cursor.fetchall()
print(result)
# 关闭游标
cursor.close()
# 关闭Connection:
conn.close()
执行代码后,user表中id为1的数据将被删除:
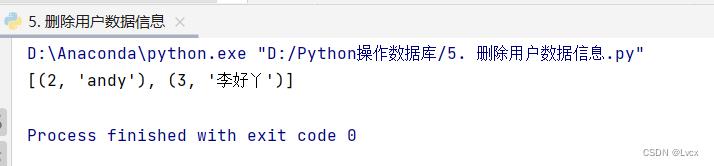
3. MySQL数据库的使用
MySQL数据库是Oracle公司所属的一款开源数据库软件,由于其免费特性,得到了全世界用户的喜爱。
1. 下载安装MySQL
1. 下载MySQL
MySQL数据库最新版本是8.0版,比较常用的还有5.7版本。以MySQL8.0为例安装。
(1)在浏览器的地址栏中输入地址:https://dev.mysql.com/downloads/windows/installer/8.0.html,并按Enter键,将进入当前最新版本MySQL 8.0的下载页面,选择离线安装包。
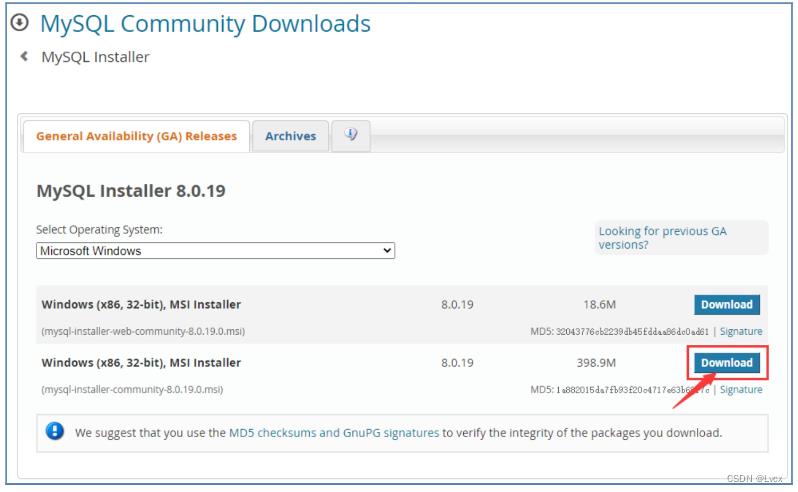
如果想要使用MySQL 5.7版本,可以访问https://dev.mysql.com/downloads/windows/installer/5.7.html进行下载。
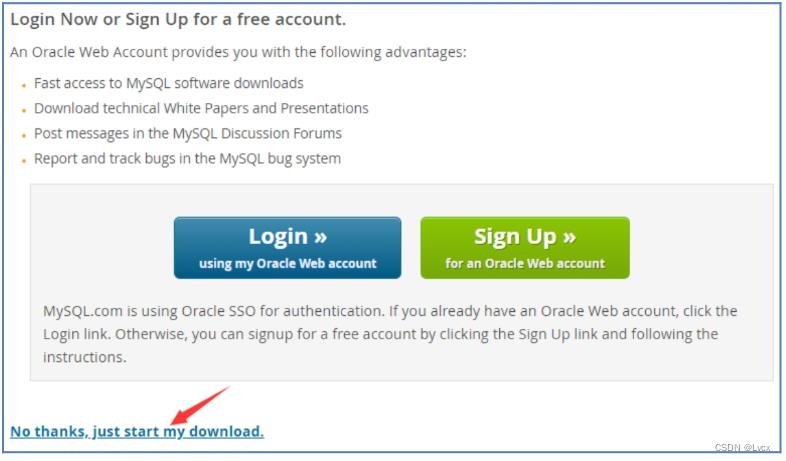
(2)单击“Download”按钮下载,进入开始下载页面,如果有MySQL的账户,可以单击Login按钮,登录账户后下载,如果没有,可以直接单击下方的“No thanks, just start my download.”超链接,跳过注册步骤,直接下载。
2. 安装MySQL
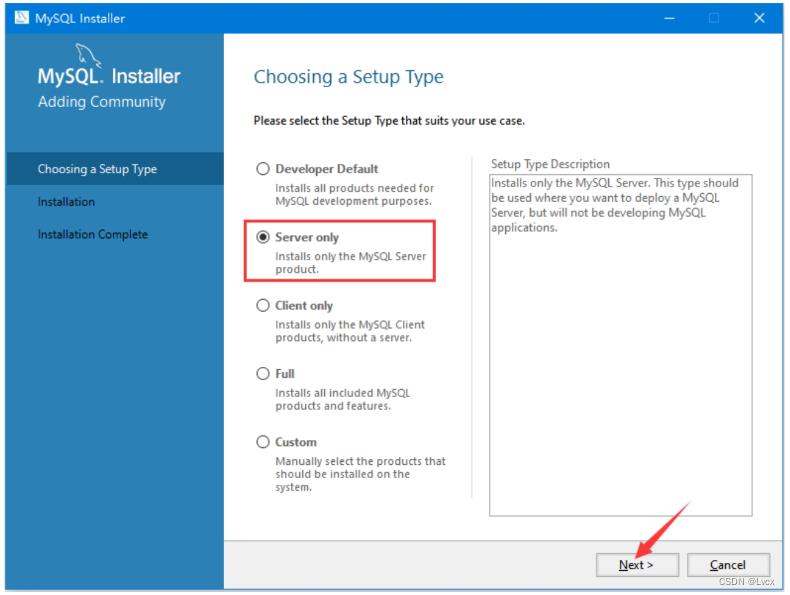
下载完成以后,开始安装MySQL。双击安装文件,在界面中选中“I accept the license terms”,单击“Next”,进入选择设置类型界面。在选择设置中有5种类型。
安装MySQL时的设置类型选项及其说明
| 类型 | 说明 |
|---|---|
| Developer Default | 安装MySQL服务器以及开发MySQL应用所需的工具。工具包括开发和管理服务器的GUI工作台、访问操作数据的Excel插件、与Visual Studio集成开发的插件、通过NET/Java/C/C++/ODBC等访问数据的连接器、官方示例和教程、开发文档等。 |
| Server only | 仅安装MySQL服务器,适用于部署MySQL服务器。 |
| Client only | 仅安装客户端,适用于基于已存在的MySQL服务器进行MySQL应用开发的情况。 |
| Full | 安装MySQL所有可用组件。 |
| Custom | 自定义需要安装的组件。 |
MySQL会默认选择“Developer Default”类型,这里我们选择纯净的“Server only”类型。
3. 设置环境变量
安装完成以后,默认的安装路径是“C:\\Program Files\\MySQL\\MySQL Server 8.0\\bin”。
设置环境变量,以便在任意目录下使用MySQL命令。右键单击“此电脑”,选择“属性”→“高级系统设置”→“环境变量”→“PATH”→“编辑”,在弹出的“编辑环境变量”对话框中,单击“新建”按钮,然后将“C:\\Program Files\\MySQL\\MySQL Server 8.0\\bin”写入变量值中。

4. 启动MySQL
使用MySQL数据库前,需要先启动MySQL。在CMD窗口中输入命令行“net start mysql80”来启动MySQL 8.0。启动成功后,使用账户和密码进入MySQL。输入命令“mysql -u root -p”,按Enter键,提示“Enter password:”,输入安装MySQL时设置的密码,这里输入“root”,即可进入MySQL。

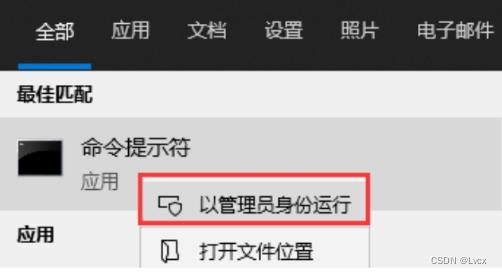
如果在CMD命令窗口中使用“net start mysql80”命令启动MySQL服务时,出现如下图所示的提示,这主要是由于Windows 10系统的权限设置引起的,只需要以管理员身份运行CMD命令窗口即可。

5. 使用Navicat for MySQL管理软件
在命令提示符下操作MySQL数据库的方式对初学者并不友好,而且需要有专业的SQL语言知识,所以各种MySQL图形化管理工具应运而生,其中Navicat for MySQL就是一个广受好评的桌面版MySQL数据库管理和开发工具,它使用图形化的用户界面,可以让用户使用和管理MySQL数据库更为轻松,官方网址:https://www.navicat.com.cn。
Navicat for MySQL是一个收费的数据库管理软件,官方提供免费试用版,可以试用14天,如果要继续使用,需要从官方购买,或者通过其他方法解决。
首先下载并安装Navicat for MySQL,安装完之后打开,新建MySQL连接。

弹出“新建连接”对话框,在该对话框中输入连接信息。输入连接名,这里输入“mr”,输入主机名或IP地址为“localhost”或“127.0.0.1”,输入MySQL数据库的登录密码。
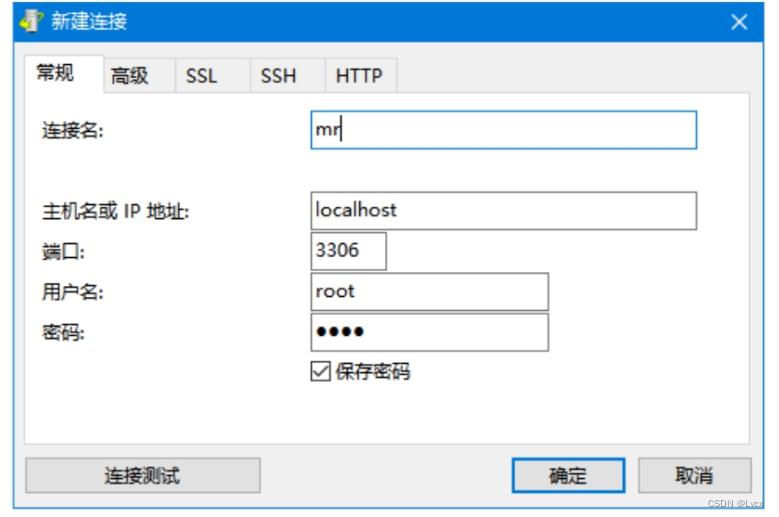
单击“确定”按钮,创建完成。此时,双击新建的数据连接名“mr”,即可查看该连接下的数据库。
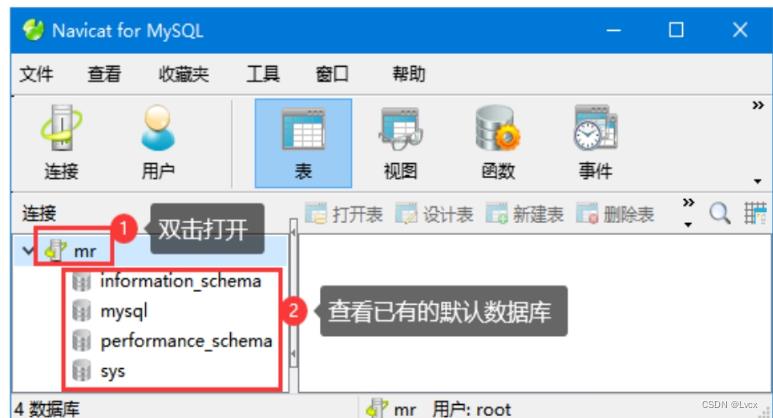
下面使用Navicat创建一个名为“mrsoft”的数据库,步骤为:右键单击“mr”,选择“新建数据库”,输入数据库信息。

2. 安装PyMySQL模块
由于MySQL服务器以独立的进程运行,并通过网络对外服务,所以,需要支持Python的MySQL驱动连接到MySQL服务器。在Python中支持MySQL数据库的模块有很多(如PyMySQL、SQLAchemy、DBUtils等),这里选择使用PyMySQL。
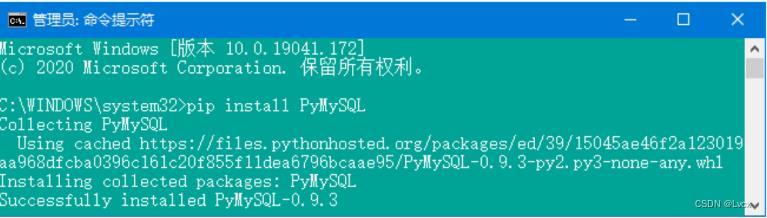
PyMySQL的安装比较简单,使用管理员身份运行系统的CMD命令窗口,然后输入如下命令:
pip install PyMySQL
按Enter键,效果如下图:
3. 连接数据库
使用数据库的第一步是连接数据库,接下来使用PyMySQL模块连接MySQL数据库。由于PyMySQL也遵循Python Database API 2.0规范,所以操作MySQL数据库的方式与SQLite相似。
示例:使用PyMySQL连接数据库
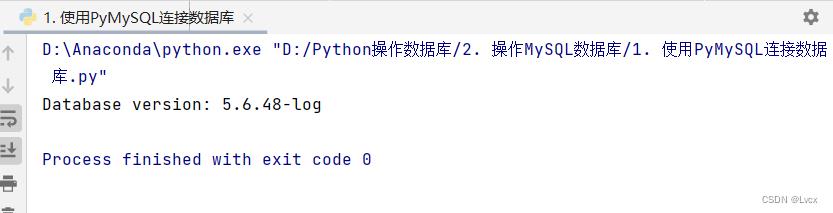
前面已经创建了一个MySQL数据库“mrsoft”,并且在安装数据库时设置了数据库的用户名“root”和密码。下面通过以上信息,使用connect()方法连接MySQL数据库。
import pymysql
# 打开数据库连接,
# 参数1:数据库域名或IP;
# 参数2:数据库账号;
# 参数3:数据库密码;
# 参数4:数据库名称。
db = pymysql.connect(host="localhost", user="root", password="数据库密码", database="mrsoft")
# 使用cursor()方法创建一个游标对象cursor
cursor = db.cursor()
# 使用execute()方法执行SQL查询
cursor.execute("select VERSION()")
# 使用 fetchone()方法获取单条数据
data = cursor.fetchone()
print("Database version: %s" % data)
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()
首先使用connect()方法连接数据库,并使用cursor()方法创建游标;然后使用excute()方法执行SQL语句查看MySQL数据库的版本,并使用fetchone()方法获取数据;最后使用close()方法关闭游标对象和数据库连接。运行结果如下:
4. 创建数据表
数据库连接成功以后,我们就可以为数据库创建数据表了。下面通过execute()方法来为数据库创建books图书表。
示例:创建books图书表
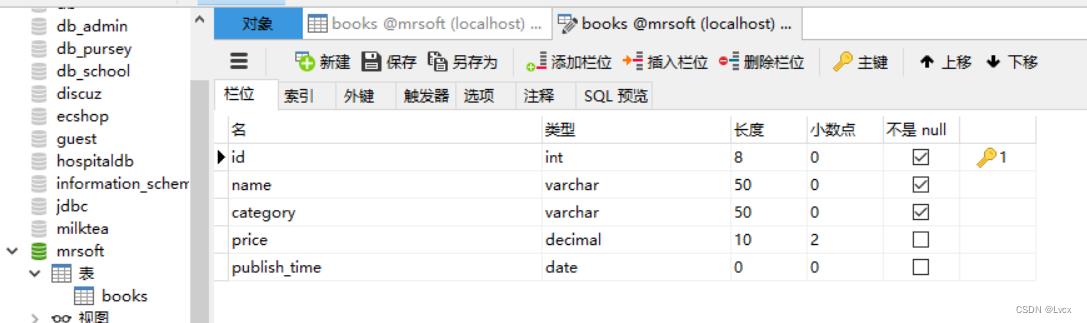
books表包含id(主键)、name(图书名称)、category(图书分类)、price(图书价格)和publish_time(出版时间)5个字段。创建books表的SQL语句如下:
CREATE TABLE books (
id int(8) NOT NULL AUTO_INCREMENT,
name varchar(50) NOT NULL,
category varchar(50) NOT NULL,
price decimal(10, 2) DEFAULT NULL,
publish_time date DEFAULT NULL,
PRIMARY KEY(id)
)ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
在创建数据表前,使用如下语句检测是否已经存在该数据库:(如果数据表存在就删除数据表)
DROP TABLE IF EXISTS 'books';
如果mrsoft数据库中已经存在books,那么先删除books,然后再创建books数据表。
完整代码如下:
import pymysql
# 打开数据库连接
db = pymysql.connect(host="localhost", user="root", password="数据库密码", database="mrsoft")
# 使用 cursor()方法创建一个游标对象cursor
cursor = db.cursor()
# 使用execute()方法执行SQL,如果表存在就删除表
cursor.execute("drop table if exists books")
# 使用预处理语句创建表
sql = """
create table books (
id int(8) not null auto_increment,
name varchar(50) not null,
category varchar(50) not null,
price decimal(10, 2) default null,
publish_time date default null,
primary key(id)
)engine=MyISAM auto_increment=1 default charset=utf8;
"""
# 执行SQL语句
cursor.execute(sql)
# 关闭游标对象
cursor.close()
# 关闭数据库连接
db.close()
运行上述代码后,在mrsoft数据库中即可创建一个books表。打开Navicat(如果已经打开,请按F5键刷新),发现mrsoft数据库下多了一个books表,右键单击books,选择“设计表”,效果如下图:
5. 操作MySQL数据表
MySQL数据表的操作主要包括数据的增删改查,与操作SQLite类似。
示例:批量添加图书数据
在向books图书表中插入图书数据时,可以使用excute()方法添加一条记录,也可以使用executemany()方法批量添加多条记录。executemany()方法格式如下:
executemany(operation, seq_of_params)
executemany()方法的参数说明
| 参数 | 说明 |
|---|---|
| operation | 操作的SQL语句。 |
| seq_of_params | 参数序列。 |
| 使用executemany()方法批量添加多条记录的具体代码如下: |
import pymysql
# 打开数据库连接
db = pymysql.connect(host="localhost", user="root", password="数据库密码", database="mrsoft", charset="utf8")
# 使用cursor方法获取操作游标
cursor = db.cursor()
# 数据列表
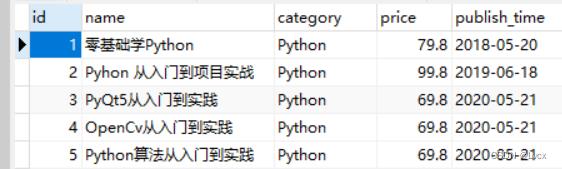
data = [("零基础学Python", "Python", "79.80", "2018-5-20"),
("Pyhon 从入门到项目实战", "Python", "99.80", "2019-6-18"),
("PyQt5从入门到实践", "Python", "69.80", "2020-5-21"),
("OpenCv从入门到实践", "Python", "69.80", "2020-5-21"),
("Python算法从入门到实践", "Python", "69.80", "2020-5-21"),
]
try:
# 执行sql语句,插入多条数据
cursor.executemany('insert into books(name, category, price, publish_time) values (%s, %s, %s, %s)', data)
# 提交数据
db.commit()
except:
# 发生错误时回滚
db.rollback()
# 关闭游标
cursor.close()
# 关闭数据库连接
db.close()
上面代码需要注意的几点是:
- 使用connect()方法连接数据库时,额外设置字符集charset=utf8,可以防止插入中文时出现乱码。
- 在使用insert语句插入数据时,使用%s作为占位符,可以防止SQL注入。
运行程序,然后在Navicat中查看books表中的数据:
孤荷凌寒自学python第五十四天使用python来删除Firebase数据库中的文档
孤荷凌寒自学python第五十四天使用python来删除Firebase数据库中的文档
(完整学习过程屏幕记录视频地址在文末)
今天继续研究Firebase数据库,利用google免费提供的这个数据库服务,今天主要尝试使用firebase_admin模块来对firebase数据库进行删除文档操作
获得成功。
一、简单总结下今天对firebase_admin模块对象的学习
(一)删除一个文档
要删除Firebase数据库中的一个集合下的一个文档
只需要执行文档对象的delete()方法。
具体用法如下:
文档对象.delete()
通过此方法,就可以完全删除这一文档,并且同时文档中的所有字段及记录也都没有了。
(二)删除文档中的某个字段的内容:
官方的文档是这样说的:
要从文档中删除特定字段,请在更新文档时使用 FieldValue.delete() 方法。
但他的示例方法是这样的:
city_ref = db.collection(u‘cities‘).document(u‘BJ‘)
city_ref.update({
u‘capital‘: firestore.DELETE_FIELD
})
可是我在实际测试中,却发现,使用这种方法,直接在:
firestore.DELETE_FIELD
这个地方报错!
提示没有DELETE_FIELD这个对象的存在。
当然我想到了解决方案:
(1)先get到指定文档的所有记录内容,转换为一个字典(dict)对象
(2)将字典对象中的要删除的那个字段(Key)键名键值对从字典对象中删除掉。
(3)重新使用文档对象的set()方法将修改后的字典(dict)对象覆盖写入文档 对象,完成对文档 中指定 字段的删除操作。
(三)删除数据库中的一个集合
根据官方文档 描述,要删除数据库中的一个集合,只要这个集合中的所有文档 都不复存在 ,则集合就不再存在 了,那么 要删除集合,就是说,只需要通过 循环词句,删除这个集合中的所有文档 就可以了。
二、我的测试练习代码
```
# _** coding:utf-8 _*_
# 孤荷凌寒自学Python第五十四天_连接firebase数据库(nosql数据库类型)第二天尝试
import firebase_admin
from firebase_admin import credentials
from firebase_admin import firestore
cred = credentials.Certificate("ghlhfirst.json")
firebase_admin.initialize_app(cred)
db=firestore.client() #建立连接
jiheinfo=db.collection(u‘ghlh‘) #得到集合
doc=jiheinfo.document(u‘yiLfGDecALwWYw9VSoIm‘) #得到文档对象
info=doc.get() #获取文档内容
print(u‘文档一 data: {}‘.format(info.to_dict())) #转变为字典对象后输出
jihesub=doc.collection(u‘subone‘) #文档下存在的一个子集合 #此处证明,这种数据库中的结构是可以像俄罗斯套娃一样无限循环嵌套的。
docsub=jihesub.document(u‘subonedoc‘) #子集合中的子文档一
infosub=docsub.get() #获取子文档一中的内容
print(u‘子文档一 data: {}‘.format(infosub.to_dict())) #转变为字典对象后输出
#-----添加文档的方法
dictdata={
u‘姓名‘:u‘张四丰‘,
u‘性别‘:u‘女‘,
u‘年龄‘:39,
u‘爱好‘:
{
u‘书法‘:u‘10级‘,
u‘计算机‘:u‘8级‘,
u‘英语‘:u‘4级‘
},
u‘婚否‘:False
}
#添加一个文档,并写入这些数据记录
jihesub.document(u‘new201812‘).set(dictdata)
#---将他读出来
docsub2=jihesub.document(u‘new201812‘) #子集合中的子文档二
infosub2=docsub2.get() #获取子文档二的内容
print(u‘子文档二data: {}‘.format(infosub2.to_dict())) #转变为字典对象后输出
#追加数据到subonedoc这个文档中
#docsub.update(dictdata)
#重新读出追加后的新文档的情况
#infosub=docsub.get() #获取子文档一中的内容
#print(u‘Document data: {}‘.format(infosub.to_dict())) #转变为字典对象后输出
#修改子文档二
#docsub2.update(dictdata)
#删除一个字段
#操作失败
#重新读
infosub2=docsub2.get() #获取子文档二的内容
print(u‘子文档二修改后data: {}‘.format(infosub2.to_dict())) #转变为字典对象后输出
```
#今天专门写的删除指定文档的一个Py文件:
```
# _** coding:utf-8 _*_
# 孤荷凌寒自学Python第五十四天_连接firebase数据库(nosql数据库类型)第五天尝试
import firebase_admin
from firebase_admin import credentials
from firebase_admin import firestore
cred = credentials.Certificate("ghlhfirst.json")
firebase_admin.initialize_app(cred)
db=firestore.client() #建立连接
jiheinfo=db.collection(u‘ghlh‘) #得到集合
doc=jiheinfo.document(u‘yiLfGDecALwWYw9VSoIm‘) #得到文档对象
jihesub=doc.collection(u‘subone‘) #文档下存在的一个子集合 #此处证明,这种数据库中的结构是可以像俄罗斯套娃一样无限循环嵌套的。
docsub=jihesub.document(u‘subonedoc‘) #子集合中的子文档一
docsub2=jihesub.document(u‘new201812‘) #子集合中的子文档二
docsub2.delete() #删除这个文档
```
朋友们,不知不觉,2018年即将过去,在2018年这似乎转瞬即逝的日子里,感恩有你们的支持与陪伴!
在此向关注本栏目与关心喜马拉雅未来书屋频道的朋友们道一声:新年快乐!祝愿在即将到来的2019年,大家心想事成,开心快乐每一天。
——————————
今天整理的学习笔记完成,最后例行说明下我的自学思路:
根据过去多年我自学各种编程语言的经历,认为只有真正体验式,解决实际问题式的学习才会有真正的效果,即让学习实际发生。在2004年的时候我开始在一个乡村小学自学电脑 并学习vb6编程语言,没有学习同伴,也没有高师在上,甚至电脑都是孤岛(乡村那时还没有网络),有的只是一本旧书,在痛苦的自学摸索中,我找到适应自己零基础的学习方法:首先是每读书的一小节就作相应的手写笔记,第二步就是上机测试每一个笔记内容是否实现,其中会发现书中讲的其实有出入或错误,第三步就是在上机测试之后,将笔记改为电子版,形成最终的修订好的正确无误的学习笔记 。
通过反复尝试错误,在那个没有分享与交流的黑暗时期我摸黑学会了VB6,尔后接触了其它语言,也曾听过付费视频课程,结果发现也许自己学历果然太低,就算是零基础的入门课程,其实也难以跟上进度,讲师的教学多数出现对初学者的实际情况并不了解的情况,况且学习者的个体也存在差异呢?当然更可怕的是收费课程的价格往往是自己难以承受的。
于是我的所有编程学习都改为了自学,继续自己的三步学习笔记法的学习之路。
当然自学的最大问题是会走那么多的弯路,没有导师直接输入式的教学来得直接,好在网络给我们带来无限搜索的机会,大家在网络上的学习日志带给我们共享交流的机会,而QQ群等交流平台、网络社区的成立,我们可以一起自学,互相批评交流,也可以获得更有效,更自主的自学成果。
于是我以人生已过半的年龄,决定继续我的编程自学之路,开始学习python,只希望与大家共同交流,一个人的独行是可怕的,只有一群人的共同前进才是有希望的。
诚挚期待您的交流分享批评指点!欢迎联系我加入从零开始的自学联盟。
这个时代互联网成为了一种基础设施的存在,于是本来在孤独学习之路上的我们变得不再孤独,因为网络就是一个新的客厅,我们时刻都可以进行沙龙活动。
非常乐意能与大家一起交流自己自学心得和发现,更希望大家能够对我学习过程中的错误给予指点——是的,这样我就能有许多免费的高师了——这也是分享时代,社区时代带来的好福利,我相信大家会的,是吧!
根据完全共享的精神,开源互助的理念,我的个人自学录制过程是全部按4K高清视频录制的,从手写笔记到验证手写笔记的上机操作过程全程录制,但因为4K高清文件太大均超过5G以上,所以无法上传至网络,如有需要可联系我QQ578652607对传,乐意分享。上传分享到百度网盘的只是压缩后的720P的视频。
我的学习过程录像百度盘地址分享如下:(清晰度:1280x720)
链接:https://pan.baidu.com/s/15-9K_Nncsc91_LDIpKJLVw
提取码:n9d4
bilibili:
https://www.bilibili.com/video/av39276634/
喜马拉雅语音笔记:
https://www.ximalaya.com/keji/19103006/149147084
以上是关于五使用Python操作数据库的主要内容,如果未能解决你的问题,请参考以下文章