建立自己的数据库
Posted go2coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了建立自己的数据库相关的知识,希望对你有一定的参考价值。
为什么需要SQL
在现实生活中,东西多了,我们都会用到仓库,把所有的东西都规整得井然有序的,要找东西的时候能很快的找到,我们用同样的规则去存放东西,再按照同样的规则去取东西,保证仓库按照一定的规整进行工作。当我们需要对我们的东西进行统计的时候,我们就可以按照特有的方法,进行快速的统计了。
各行各业都需要有自己所属的仓库,老师需要建立学生的成绩仓库,这样可以很方便的了解学生的成绩情况;卖商品的店员需要建立自己的商品仓库,方便对商品进行统计进而更加清楚自己的销售情况。不管是数据的比较或者分析,对数据的挖掘处理,SQL都是最基础。这就是我们需要SQL的原因。
每一门语言都有特定的用途,SQL特别明显,SQL可以说不仅仅属于程序员的一种语言,每个统计行业的人员都得熟悉的一门语言。
通常来说,业务分析人员最关注产品的各个方面的数据,他们最了解市场,但是由于他们里产品开发比较远,不容易拿到自己产品的数据,用数据来判断之前的运营情况到底对产品有没有好的影响,对比出哪样的投放方式是比较好的。业务人员并没有办法自己统计出这方面的数据,很重要的一个环节,是业务人员对程序天生都有一个误解,觉得程序是程序员的事情,其实SQL语言是很通俗的一门统计语言,通俗到你只要知道英文语法,你就能写出SQL。
而对于一名程序员来讲,数据的存储和基本SQL的语法在编程中都是必然会用到的,如何设计数据库,如何高效的进行查询,整理等对数据库的操作都是作为一名程序员的基础技能。而很多程序员,特别是写客户端程序的人员,对SQL都是一知半解,希望通过这系列的教程,能够更加系统的了解SQL。
这一系列的文章,从最初的状态开始,一步一步的了解SQL的基础知识,特别适合初学者。
对于刚刚接触数据库的人员来说数据库都是一个比较虚的概念,不知道数据放在哪里,不知道怎么去连接数据,数据是以何种结构去存储,如何才能够取得数据,更不知道学了那么多的SQL语句,是要在哪里才能够用得上的,所以在一开始,并不着急介绍SQL的知识,而是从头开始,建立一个完整的数据库,并在数据库里建立自己的数据,它将成为了下面几个章节的试验场。
在windows上搭建数据库
一般来讲数据库通常搭建在服务器上,在服务器上安装了数据库的服务,我们通过一个客户端去连接我们需要的数据,在客户端写好语句后提交到服务器上面的数据库服务端,服务端计算完数据后,返回给客户端。而这个服务端的数据服务有非常多的选择,这里我们使用的是mysql。
用户可以根据如下的步骤来建立数据库服务,MySQL是一个很好的工具,它管理着数据,SQL语法负责对数据进行操作,初学者一定要有自己的数据服务,不然很难学懂SQL语法。
首先,需要安装MySQL服务端工具,到MySQL的官方网站下,下载windows的MySQL版本,地址在https://dev.mysql.com/downloads/windows/, 选择MySQL Installer,下载软件进行安装。
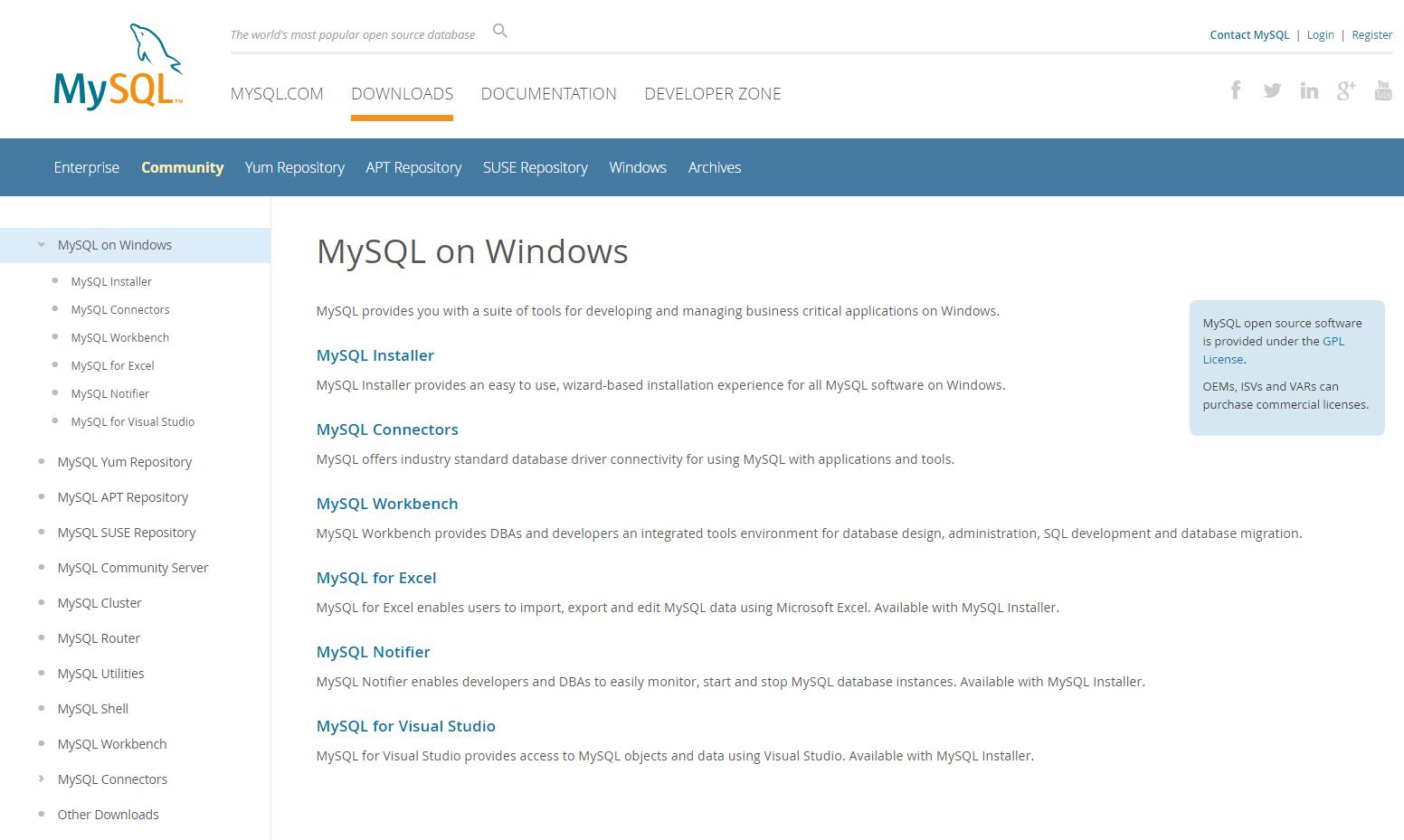
下载完成后,进行MySQL服务端的安装,它相当于一个服务,你可以安装在自己本地的机子上,这相当于,这台机子用来做服务端,等下又用来连接这个服务端,又当客户端。客户端相当于不存储任何的数据,所有的数据都存放在服务端上,所有的数据运算都在服务端上,客户端只写相应的计算代码和展现计算结果。
完成了主程序的安装以后,接下来就是对MySQL进行配置,配置MySQL的基本信息,比如端口号是多少等,如果不需要特殊配置,直接下一步就可以。

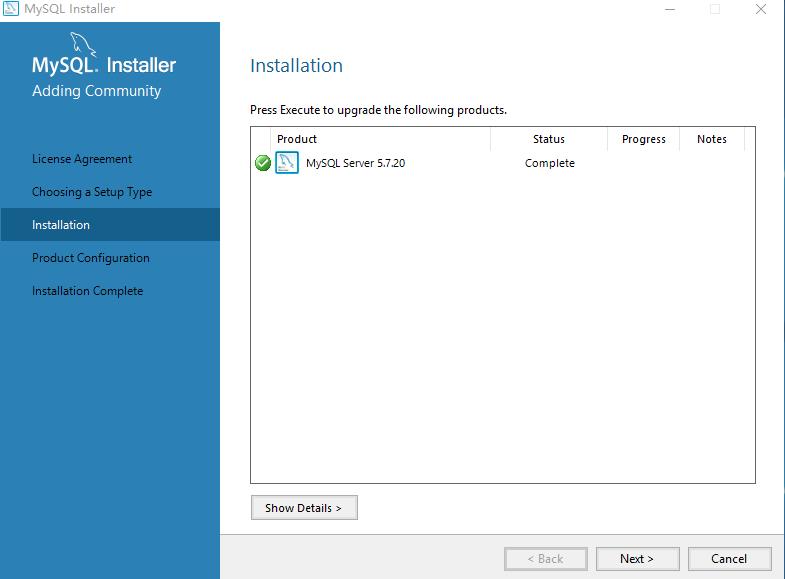
做为数据库的管理中心,为了数据的安全,并不希望任何用户只要知道数据库的地址就能获取数据库里的任何数据,因此需要设置用户信息,设置账号和密码:
不出意外的话,直接下一步就能够完成数据库的安装,这时候MySQL的各种服务已经安装到这台机子了,点击完成会启动MySQL的服务。

数据库的服务启动以后提供了各种对数据的管理和操作,一开始数据库里除了一些系统数据以外,并没有其他的数据,接下来就是用客户端连接数据库服务,看看数据库里面有什么东东。
连接数据库服务
连接数据服务的客户端非常的多,优秀的软件也很多,通常较为流行的是Navicat这款软件,连接的类型比较的多,同样在网上下载这款软件,完成安装,打开软件如下:
连接到刚才我们建立的数据服务器,也就是本机上,ip为127.0.0.1,在生产环境下,可以查问运维人员数据存放的具体ip地址。用户名一开始为root是超级用户,密码为刚才所设立的,这些教程主要是关于SQL的语法操作,MySQL的管理操作这里不详说。
打开MySQL后,会看到几个数据库information_schema,mysql,performance_schema,sys这些都是MySQL自带的数据库,暂且先放着不管。
建立试验数据
关于数据库有较多的概念,在这里不做详细的介绍,直接到具体的需求中实践去。
这里列举一个学校学生的具体例子。
为了方便管理,每一个项目在数据服务中,都有一个专门的数据库,又可以根据数据的属性分为不同的表。比如每个学生有年龄,班级,每个学生又有自己的课程,有自己的课程成绩。这样在学生项目的数据库中,可以有三个表,学生,课程,学生的课程成绩。这里把试验的项目名称取名为:school,新建数据库名称 school 。
选择新建数据库,建立 school 数据库。

新建三张表,students,score,courses
students表:用来存放学生信息courses表:课程信息score表:学生课程成绩
打开查询按钮,输入以下代码建立三个表格:
CREATE TABLE `students` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
`sex` varchar(100) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`tel` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `age` (`age`),
KEY `as` (`age`,`sex`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `score` (
`int` int(11) NOT NULL AUTO_INCREMENT,
`course_id` int(11) DEFAULT NULL,
`student_id` int(11) DEFAULT NULL,
`score` int(11) DEFAULT NULL,
PRIMARY KEY (`int`)
) ENGINE=InnoDB AUTO_INCREMENT=13 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `courses` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
执行如下的代码后,建立了三张表格,这三张表格以后会经常用到,可以双击打开这三张表,发现除了字段名称以外,这三张表没有任何数据。
如果你还不知道如何建表并没有关系,接下来会慢慢的介绍,SQL的语法跟MySQL搭建并没有什么关系,主要是为了以后能够在上面进行SQL的运算,也为了给自己一个可视化的界面。
关于数据库的操作就到这里,挺琐碎的一些东西,但是这些是我们以后的基础,如果没有这些数据服务,我们没有地方实现我们的SQL,也对数据库没有一个基本的认识。
如何建立自己的网络爬虫
互联网时代下,作为数据分析的核心,爬虫从作为一个新兴技术到目前应用于众多行业,已经走了很长的道路。互联网上有很多丰富的信息可以被抓取并转换成有价值的数据集,然后用于不同的行业。除了一些公司提供的一些官方公开数据集之外,我们应该在哪里获取数据呢?其实,我们可以建立一个网路爬虫去抓取网页上的数据。
网络爬虫的基本结构及工作流程
网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份。
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1、首先选取一部分精心挑选的种子URL;
2、将这些URL放入待抓取URL队列;
3、从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4、分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
创建网络爬虫的主要步骤
要建立一个网络爬虫,一个必须做的步骤是下载网页。这并不容易,因为应该考虑很多因素,比如如何更好地利用本地带宽,如何优化DNS查询以及如何通过合理分配Web请求来释放服务器中的流量。
在我们获取网页后,HTML页面复杂性分析随之而来。事实上,我们无法直接获得所有的HTML网页。这里还有另外一个关于如何在AJAX被用于动态网站的时候检索Javascript生成的内容的问题。另外,在互联网上经常发生的蜘蛛陷阱会造成无数的请求,或导致构建不好的爬虫崩溃。
虽然在构建Web爬虫程序时我们应该了解许多事情,但是在大多数情况下,我们只是想为特定网站创建爬虫程序,而不是构建一个通用程序,例如Google爬网程序。因此,我们最好对目标网站的结构进行深入研究,并选择一些有价值的链接来跟踪,以避免冗余或垃圾URL产生额外成本。更重要的是,如果我们能够找到关于网络结构的正确爬取路径,我们可以尝试按照预定义的顺序抓取目标网站感兴趣的内容。
找到一个合适的网络爬虫工具
网络爬虫的主要技术难点:
· 目标网站防采集措施
· 不均匀或不规则的网址结构
· AJAX加载的内容
· 实时加载延迟
要解决上诉问题并不是一件容易的事情,甚至可能会花费很多的时间成本。幸运的是,现在您不必像过去那样抓取网站,并陷入技术问题,因为现在完全可以利用从目标网站或者数据。用户不需要处理复杂的配置或编程自己构建爬虫,而是可以将更多精力放在各自业务领域的数据分析上。
兔子动态换IP软件可以实现一键IP自动切换,千万IP库存,自动去重,支持电脑、手机多端使用,智能加速技术多IP池自动分配。
以上是关于建立自己的数据库的主要内容,如果未能解决你的问题,请参考以下文章