超全mysql转换postgresql数据库方案
Posted 爱码代码的林子哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超全mysql转换postgresql数据库方案相关的知识,希望对你有一定的参考价值。
写在前文:
近期由于公司业务产品发展需要,要求项目逐渐国产化:(1)项目国产操作系统部署;(2)数据库国产化;国产数据库最终选型为highgo(瀚高),该数据库基于pg开发,所以要求先将mysql适配到postgresql数据库;
一、初识postgresql
1.1 docker安装postgresql
1.1.1 镜像拉取
dockerhub官网选取自己想安装的版本(https://hub.docker.com/_/postgres/tags),我这里选取的是13.9版本;
拉取镜像到本地
docker pull postgres:13.91.1.2 执行镜像安装postgresql
docker run --name 1.postgres \\
--restart=always \\
-e POSTGRES_PASSWORD='jY%kng8cc&' \\
-p 5432:5432 \\
-v /data/postgresql:/var/lib/postgresql/data \\
-d postgres:13.91.1.3 创建数据库,设置默认查询模式
-- 建库
CREATE DATABASE "test"
WITH
OWNER = "testuser" -- 数据库用户
;
-- 创建模式
CREATE SCHEMA "test" AUTHORIZATION "test";
-- 设置默认查询模式 pg连接时默认使用public这个schmel,想让项目连接时使用自己创建的模式需要修改一下默认查询模式
ALTER ROLE testuser SET search_path="test";1.2 postgresql学习
这里放上一个学习地址,大家可以参照性学习,边使用边学习
https://www.sjkjc.com/postgresql/psql-commands/
1.3 项目中引入postgresql数据库
1.3.1 版本问题
postgresql-42.2.10(支持PostgreSQL 42)
JDK 8 - JDBC 4.2 Support for JDBC4 methods is not complete, but the majority of methods are implemented.
pg驱动版本:springboot2.5.14中默认集成的是42.2.25
1.3.2 添加maven依赖
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>1.3.3 配置文件修改
# 1.postgres为容器名称,也可以直接指定ip
pring.datasource.url=jdbc:postgresql://1.postgres:5432/test?autoReconnect=true&autoReconnectForPools=true&useUnicode=true&characterEncoding=utf8&createDatabaseIfNotExist=true&allowMultiQueries=true&zeroDateTimeBehavior=convertToNull
spring.datasource.username=testuser
spring.datasource.password=test
spring.datasource.driver-class-name=org.postgresql.Driver二、 MYSQL和PG基础语法差异汇总整理
2.1 数据结构对比
mysql | postgresql |
TINYINT | SMALLINT |
SMALLINT | SMALLINT |
MEDIUMINT | INTEGER |
BIGINT | BIGINT |
FLOAT | REAL |
DOUBLE | DOUBLE PRECISION |
BOOLEAN | BOOLEAN |
TINYTEXT | TEXT |
TEXT | TEXT |
MEDIUMTEXT | TEXT |
LONGTEXT | TEXT |
BINARY(n) | BYTEA |
VARBINARY(n) | BYTEA |
TINYBLOB | BYTEA |
BLOB | BYTEA |
MEDIUMBLOB | BYTEA |
LONGBLOB | BYTEA |
DATE | DATE |
TIME | TIME [WITHOUT TIME ZONE] |
DATETIME | TIMESTAMP [WITHOUT TIME ZONE] |
TIMESTAMP | TIMESTAMP [WITHOUT TIME ZONE] |
AUTO_INCREMENT | SERIAL , BIGSERIAL |
column ENUM (value1, value2, […] | column VARCHAR(255) NOT NULL, CHECK (column IN (value1, value2, […])) pg可以自定义数据类型实现类似效果: CREATE TYPE mood AS ENUM ('sad','ok','happy'); CREATE TABLE person ( current_mood mood ... ) |
2.2 基础语法差异对比
语法差异 | mysql | postgresql | 是否相同 |
分页 | select * from t1 limit 2,2; | select * from tbl limit 2 offset 2; | 否 |
插入数据时:如果不存在则insert,存在则update | replace实现 | upsert | 否 |
大小写兼容 | 通过配置可兼容 | 表字段或表名为大写时,字段或表名必须添加双引号 | 否 |
if(), case when | if(), case when 条件1 then 符合值 else 不符合值 end; | case when 条件1 then 符合值 else 不符合值 end; | 否 |
round(字段,小数位数) | round(字段,小数位数) | round(case(‘字段’ as numeric),小数位数) | 否 |
null值判断 | 支持 ifnull(),NVL(),COALESCE() | 支持COALESCE() | 否 |
Update-单表更新 | 相同 | 相同(不可全表更新) | 是 |
update-更新单表多个字段 | 相同 | 相同 | 是 |
update-更新并返回 | select tem1,tem2 from update test set tem1 = '',tem2 = '' | UPDATE test SET tem1 = '',tem2 = '' RETURNING tem2,tem2; | 否 |
Update表关联更新 | 相同 | 相同 | 是 |
Insert-单行插入 | 相同 | 相同 | 是 |
Insert-插入指定字段 | 相同 | 相同 | 是 |
insert-插入多行 | 相同 | 相同 | 是 |
insert-插入并返回 | 不支持 | INSERT INTO() RETURNING did | 否 |
Insert-插入,存在则更新 | INSERT INTO () VALUE() ON DUPLICATE KEY UPDATE name = EXCLUDED.name | INSERT INTO distributors ( did , dname ) VALUES ( 9 , ' Antwerp Design' ) ON CONFLICT (did)DO UPDATE SET name = EXCLUDED.name | 否 |
insert-不存在插入,存在更新 | replace实现 | upsert语句 | 否 |
SELECT | 相同 | 相同 | 是 |
DELETE | DELETE FROM table | DELTE FROM table(不可全表删除) | 是 |
DELETE | DELETE FROM table WHERE | DELETE FROM table WHERE | 是 |
DELETE-删除并返回 | 不支持 | DELETE FROM table WHERE RETURNING * ; | |
INDEX-add | 支持alter,create创建 | 支持create | |
INDEX-delete | 支持alter,drop | 支持drop | |
字符串常量 | 支持单双引号 | 支持双引号 | 否 |
插入数据时自增主键 | 写法一:insert into t1(name) values(‘zhangshan’); 写法二:insert into t1(id, name) values(null, ‘zhangshan’); | insert into t1(name) values(‘zhangshan’); | 否 |
库名长度 | 无强制限制 | 库名、表名限制命名长度,建议表名及字段名字符总长度小于等于63。 |
三、MYSQL数据结构转换PG数据结构
3.1 mysql数据结构转换PG数据结构
网上有很多转换工具,有些需要收费,这里借助一个最简单最常用的工具-navicat premium(我这里使用的是16版本)转换mysql数据结构到PG的数据结构
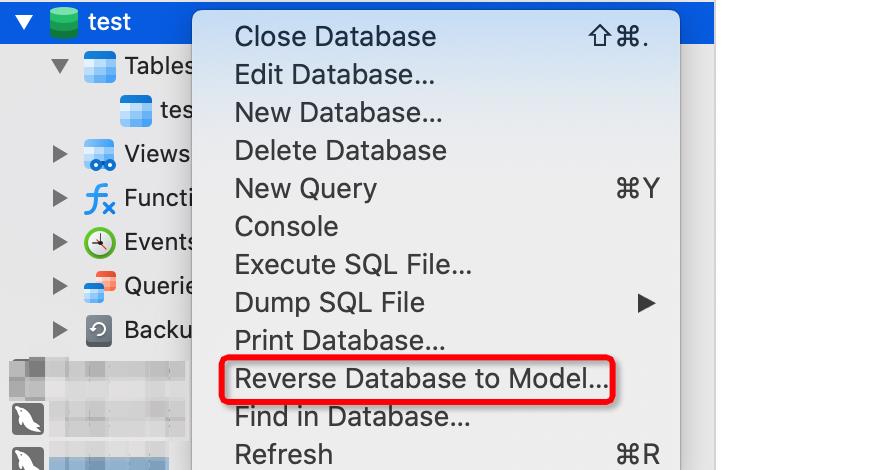
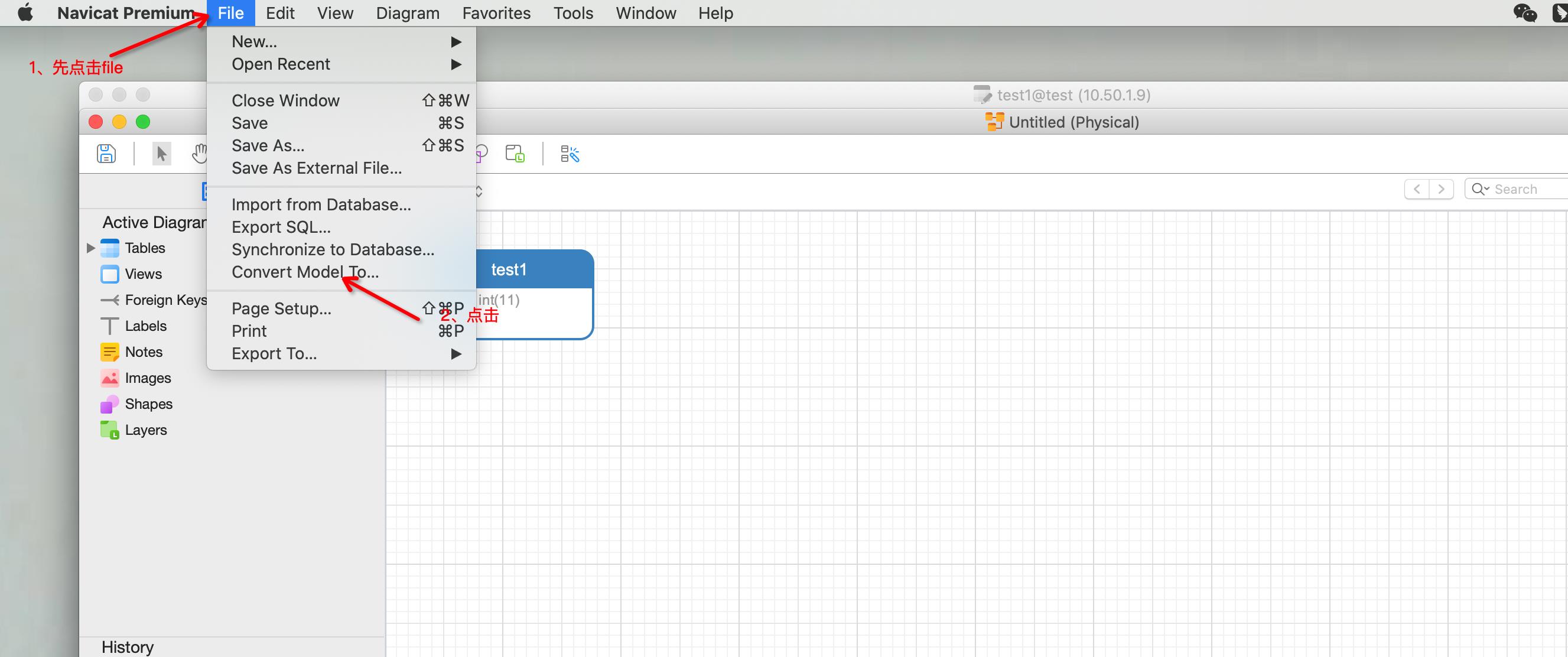
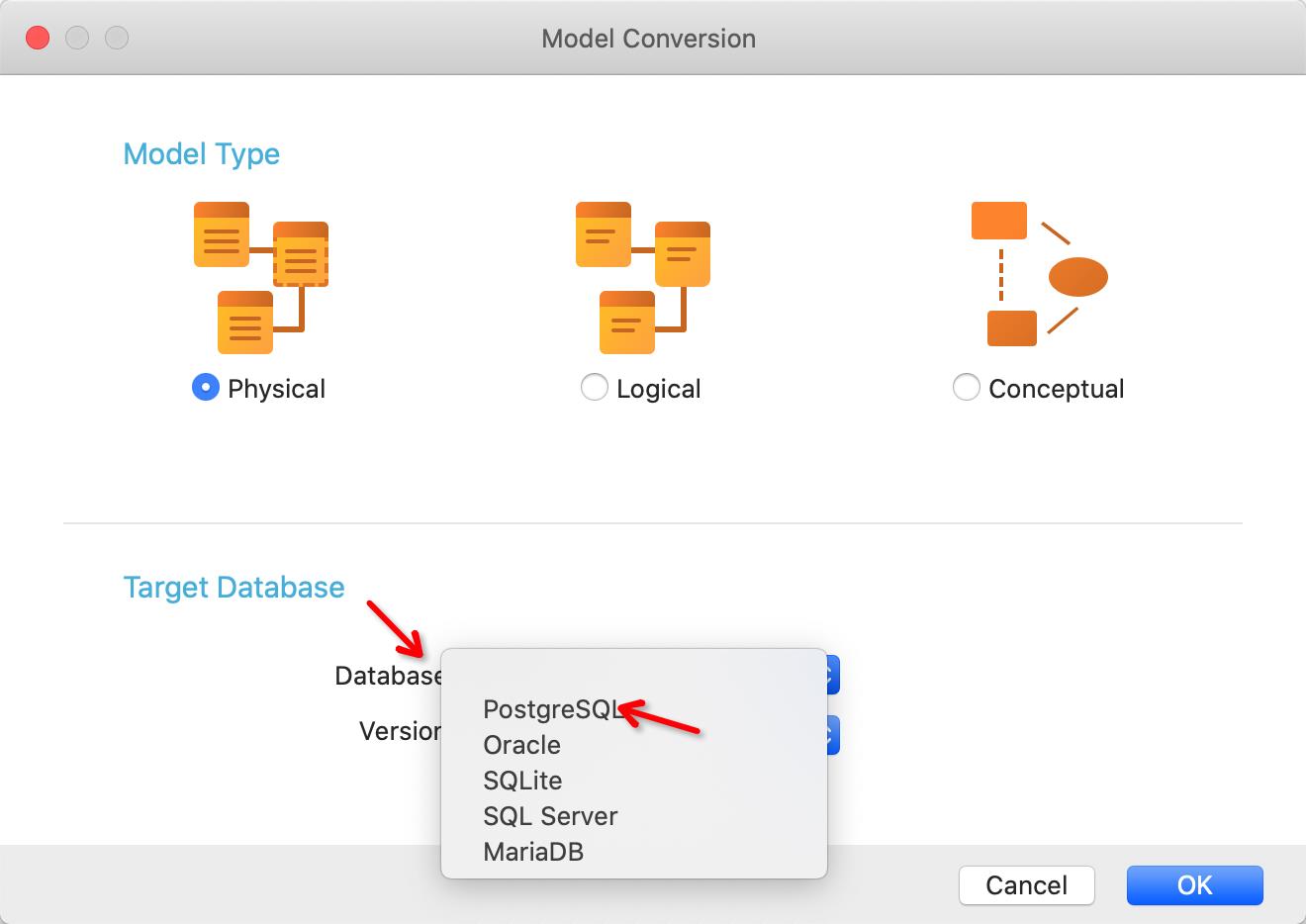
点击database选择你想转换的数据库,这里选择postgreSQL,下面选择版本
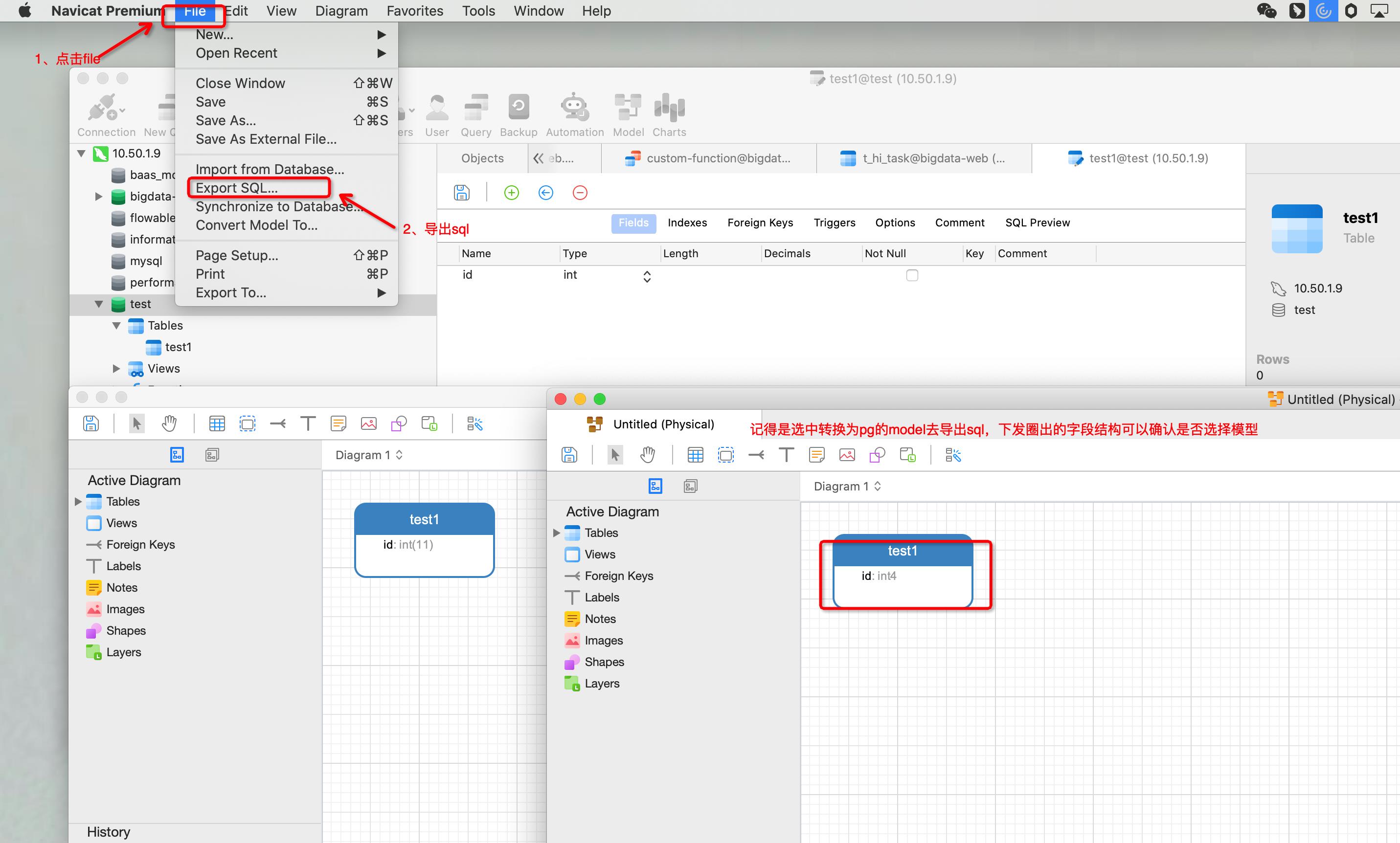
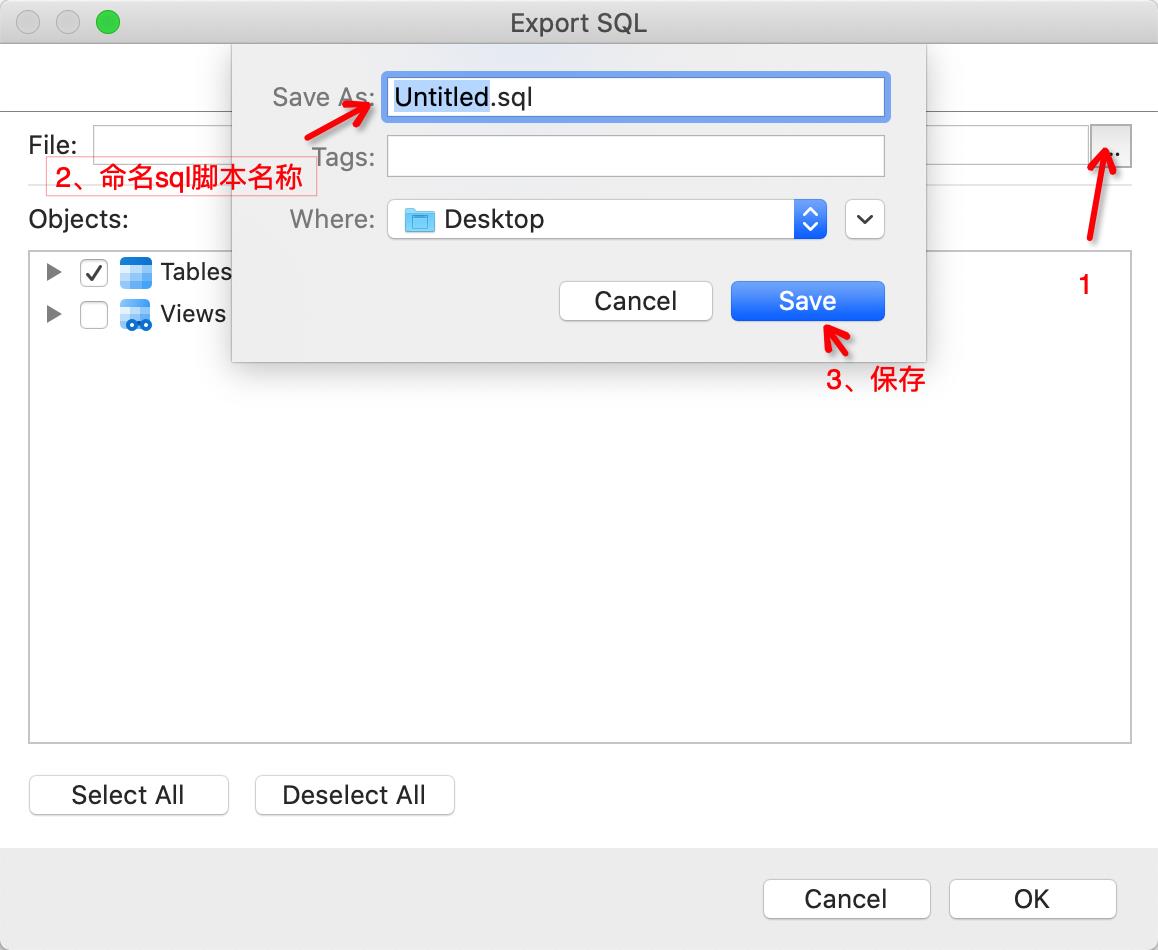
至此,一份pg的数据结构就保存完整了(注意:此时转换出来的数据结构会存在一些错误,还需要额外手动处理一些问题)
3.2 MYSQL转换PG数据结构存在的问题及解决方案
3.2.1 默认值丢失问题default
(1)时间字段的CURRENT_TIMESTAMP默认值丢失
解决方案:
-- 从mysql默认表information_schema中获取默认为CURRENT_TIMESTAMP列的信息
SELECT TABLE_NAME,column_name,column_default,extra FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND column_default = 'CURRENT_TIMESTAMP';
-- 拼接所有时间字段默认为CURRENT_TIMESTAMP的alter 语句,提取到脚本中执行
SELECT
CONCAT("ALTER TABLE \\"bigdata-web\\".\\"",TABLE_NAME, "\\" ALTER COLUMN ","\\"",column_name,"\\"", " SET DEFAULT ", column_default, ";")
FROM information_schema.columns
WHERE
table_schema = 'bigdata-web' and column_default is not null AND column_default = 'CURRENT_TIMESTAMP';
(2)时间字段类型的on update CURRENT_TIMESTAMP,PG中无该使用方式
解决方案:
利用触发器和pg扩展函数实现更新数据时更新时间字段值
-- 安装pg扩展函数moddatetime(使用pg的useradmin用户)
create extension moddatetime;
ALTER FUNCTION "moddatetime"() OWNER TO "test用户";
-- 触发器语句:create trigger gmt_modified_timestamp_trigger before update on test_ly for each row execute procedure moddatetime(gmt_modified);
-- 查询所有设置了on update CURRENT_TIMESTAMP的列
SELECT TABLE_NAME,COLUMN_NAME,EXTRA,DATA_TYPE FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND column_default != '' AND column_default = 'CURRENT_TIMESTAMP' AND EXTRA = 'on update CURRENT_TIMESTAMP';
-- 拼接处理默认值为on update CURRENT_TIMESTAMP字段类型的默认值,添加触发器的语句
SELECT CONCAT("create trigger ", COLUMN_NAME, "_trigger ","before update on \\"", TABLE_NAME, "\\" for each row execute procedure moddatetime(\\"",COLUMN_NAME,"\\");") FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND column_default != '' AND column_default = 'CURRENT_TIMESTAMP' AND EXTRA = 'on update CURRENT_TIMESTAMP';
(3)其他默认值可以参考上面拼接处理,如字符串,数字
解决方案
-- 拼接所有默认值为字符串的alter语句
SELECT TABLE_NAME,column_name,column_default,DATA_TYPE,extra FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND column_default != 'CURRENT_TIMESTAMP' AND DATA_TYPE = 'varchar' AND column_default != '';
SELECT
CONCAT("ALTER TABLE \\"bigdata-web\\".\\"",TABLE_NAME, "\\" ALTER COLUMN ","\\"",column_name,"\\"", " SET DEFAULT '", column_default, "';")
FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND column_default != 'CURRENT_TIMESTAMP' AND DATA_TYPE = 'varchar' AND column_default != '';
-- 拼接默认值字段为enum的alter语句
SELECT * FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND column_default != '' AND DATA_TYPE = 'enum';
SELECT
CONCAT("ALTER TABLE \\"bigdata-web\\".\\"",TABLE_NAME, "\\" ALTER COLUMN ","\\"",column_name,"\\"", " SET DEFAULT '", column_default, "';")
FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND column_default != '' AND DATA_TYPE = 'enum';
-- 查询默认值为数字的列,拼接alter语句 除了tinyint(1) TABLE_NAME,column_name,column_default,DATA_TYPE,extra
SELECT * FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND column_default != 'CURRENT_TIMESTAMP' AND DATA_TYPE IN('tinyint', 'int', 'bigint') AND column_default != ''
AND COLUMN_TYPE != 'tinyint(1)' and
table_name = 't_user'
SELECT
CONCAT("ALTER TABLE \\"bigdata-web\\".\\"",TABLE_NAME, "\\" ALTER COLUMN ","\\"",column_name,"\\"", " SET DEFAULT ", column_default, ";")
FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND column_default != 'CURRENT_TIMESTAMP' AND DATA_TYPE IN('tinyit', 'int', 'bigint') AND column_default != ''
AND COLUMN_TYPE != 'tinyint(1)';
-- double
SELECT * FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND DATA_TYPE IN('double') AND column_default != '';
SELECT
CONCAT("ALTER TABLE \\"bigdata-web\\".\\"",TABLE_NAME, "\\" ALTER COLUMN ","\\"",column_name,"\\"", " SET DEFAULT ", column_default, ";")
FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND DATA_TYPE IN('double') AND column_default != '';
-- decimal
SELECT * FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND DATA_TYPE IN('decimal') AND column_default != '';
SELECT
CONCAT("ALTER TABLE \\"bigdata-web\\".\\"",TABLE_NAME, "\\" ALTER COLUMN ","\\"",column_name,"\\"", " SET DEFAULT ", column_default, ";")
FROM information_schema.columns
WHERE table_schema = 'bigdata-web' and column_default is not null AND DATA_TYPE IN('decimal') AND column_default != '';
(4)MYSQL的tinyint(1)(业务代码中boolean值)转换为了int2
navicat工具转换映射时将mysql的bit(1)转换为了int2,需要处理该部分字段
-- tinyint
SELECT * FROM information_schema.columns
WHERE table_schema = 'test-database' AND COLUMN_TYPE = 'tinyint(1)'
ORDER BY TABLE_NAME
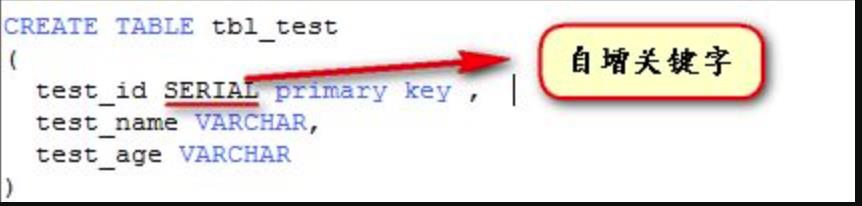
-- 批量转换语句拼接3.2.2 自增id设置丢失
navicat工具转换时将自增id设置丢失了
解决方案:
(1)修改建表语句,使用SERIAL关键字
(2)修改已经创建的表的某个字段为自增
--1、在PostgreSQL当中,我们实现ID自增首先创建一个关联序列,以下sql语句是创建一个从1开始的序列:
CREATE SEQUENCE menu_id_seq START 1;
--2、设置该字段默认值nextval('menu_id_seq'::regclass)
ALTER TABLE menu ALTER COLUMN id SET DEFAULT nextval('menu_id_seq'::regclass);
四、业务代码中的语法差异转换
4.1 常见修改场景汇总
序号 | 场景 | 示例 |
1 | mapper接口方法上使用注解编写sql语句 | @SELECT("SELECT * FROM TEST") |
2 | mapper的xml文件中的语句 | |
3 | mybatis-plus使用的实体类相关特殊列名修改 |
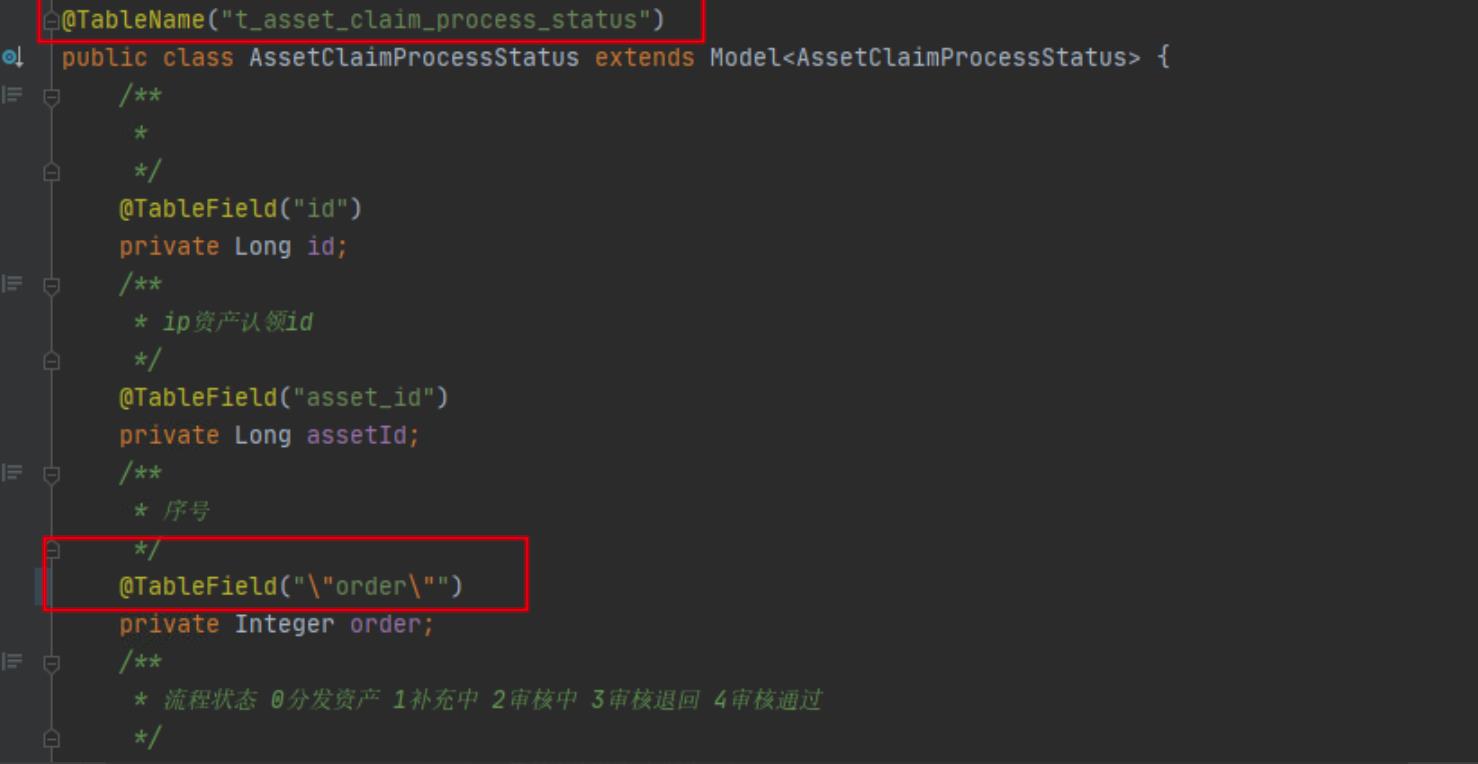
|
4 | mybatis-plus使用QueryWrapper条件构造相关列修改 | |
5 | 代码中使用字符串拼接的sql语句 |
4.2 业务代码语法修改问题汇总
序号 | 差异关键字 | 差异描述 | mysql示例 | pg示例 |
1 | limit | limit 0,1 改成 limit 1 offset 0 | select * from t_user limit 0,1 | select * from t_user limit 1 offset 0 |
2 | 字段大小写 | 查询字段为驼峰命名,加上双引号,select \\"startTime\\" form ... | - | - |
3 | ifnull | 没有ifnull函数,改用COALESCE()函数, | select ifnull(avatar, 'aa'),"name" from t_user; | select COALESCE(avatar, 'aa'),"name" from t_user; |
4 | DATE_SUB() | 没有DATE_SUB()时间计算函数,改用select now() + '1 seconds' 或 select now() + '-1 seconds' | select DATE_SUB(logintime,INTERVAL 1 DAY) from t_user; | select logintime + '1 days' from t_user; |
5 | 别名大小写 | 查询字段的别名也需要用双引号包起来,select start_time as \\"startTime\\" from ... | - | - |
6 | 正则表达式、REGEXP | 正则表达式匹配,where taget_name ~ '^123$|asd'...,其中~为匹配正则表达式区分大小写,~*为不区分大小写,前面加叹号则为不匹配正则表达式如:!~ | select * from t_user where name REGEXP '^adm*'; | select * from t_user where name ~ '^adm*'; |
7 | binary | mysql的where判断加上binary来区分大小写,where binary id = ‘abc’,在pg中是直接区分大小写的,将binary去掉就行 | select * from t_user where binary name = 'ADMIN'; | select * from t_user where name = 'ADMIN'; |
8 | group_concat_max_len | set session group_concat_max_len=...在pg中没有,注释 | - | - |
9 | GROUP_CONCAT() | GROUP_CONCAT()函数没有,使用array_to_string(array_agg(target_name), ',') from ... 代替 | select GROUP_CONCAT(industry) from t_company group by province; | select array_to_string(array_agg(industry), ',') from t_company group by province; |
10 | ISNULL | ISNULL没有使用is null来进行判断 | select * from t_user where ISNULL(avatar); | select * from t_user where avatar is null; |
11 | &&,|| | &&和||没有这个符号,用and和or替换 | select * from t_user where ISNULL(avatar) && realname = '日志管理员'; | select * from t_user where avatar is null and realname = '日志管理员'; |
12 | date_format() | date_format()函数用不了,换成 to_char,select to_char(create_time, 'yyyy-MM-dd hh24:mi:ss') from ... | select date_format(logintime, '%Y-%m-%d') from t_user; | select to_char(logintime, 'yyyy-MM-dd') from t_user; |
13 | if() | 没有if()函数,改用 case when 条件 then 值 else 值 end | select if(name = 'admin', true, false) as isAdmin from t_user | select case when name = 'admin' then true else false end as isAdmin from t_user |
14 | FIND_IN_SET() | where FIND_IN_SET('123', user_ids) ... 使用不了,换成 where '123' = ANY(string_to_array(user_id, ',')) ... | select * from t_company where find_in_set('浙江省', address); | select * from t_company where '浙江省' = ANY(string_to_array(address, ',')); |
15 | 数字字符串比较、连表 | mysql中能直接对数字和字符串进行=相等判断,pg不行,换成,'123' = cast(123 as VARCHAR) 或者 123 = cast('123' as INTEGER);或者123 = '123'::INTEGER 例如 select * from t_model_layout_task_record as r left join t_model_layout_form as f on r.formId = f.id,其中r.formId是vachar,f.id是int,这样连表是报错的, 改成:select * from t_model_layout_task_record as r left join t_model_layout_form as f on r.formId = cast(f.id as VARCHAR) | select * from t_model_layout_task_record as r left join t_model_layout_form as f on r.formId = f.id | select * from t_model_layout_task_record as r left join t_model_layout_form as f on r.formId = cast(f.id as VARCHAR) |
16 | SYSDATE() | 没有 SYSDATE() 函数,换成 NOW() | select SYSDATE(); | select now(); |
17 | from_unixtime() | 没有from_unixtime()函数,换成to_timestamp() | select from_unixtime(1673833489); | select to_timestamp(1673833489); |
18 | auto_increment | mysql查询information_schema.tables的auto_increment字段获取主键自增的值,而pg的information_schema.tables中不存在auto_increment。 pg通过该函数 pg_get_serial_sequence(‘库名.表名’, '自增字段名') 获取表的自增值 | - | - |
19 | unix_timestamp() | 没有unix_timestamp()函数,换成date_part('epoch', now())::integer,例如,select date_part('epoch', start_time)::integer from t_model_layout_task_record | select unix_timestamp(createtime) from t_user; | select date_part('epoch', createtime)::integer from t_user; |
20 | ON DUPLICATE KEY UPDATE | mysql的存在则更新写法,pg换成, 改成: INSERT INTO 表名(列1,列2...) VALUES ('值1', '值2', ...)ON CONFLICT(唯一或排除约束字段名) DO UPDATE SET 列1='值', 列2='值', ...; 如果是批量插入的话改成: INSERT INTO 表名(列1,列2...) VALUES ('值1', '值2', ...)ON CONFLICT(唯一或排除约束字段名) DO UPDATE SET 列1=excluded.列1, 列2=excluded.列2, ...; 需要注意的是: 唯一或排除约束字段名必须是一个唯一索引或唯一联合索引,如果填写多个唯一索引则不生效,如果要生效的话,必须把他们建立成一个唯一联合索引。 | insert into t_user(id,name,logintime,PASSWORD,createuser,updateuser) values(1,'test',now(),'test',1,1) on duplicate key update logintime = values(logintime); | insert into t_user(id,name,logintime,"PASSWORD",createuser,updateuser) values(1,'test',now(),'test',1,1) ON CONFLICT(id) DO UPDATE SET logintime=excluded.logintime; |
21 | instr() | 没有instr()函数,改成like。例: SELECT * FROM user WHERE INSTR(username,'2')>0 SELECT * FROM user WHERE username like '%2%' | select * from t_user where INSTR(name,'a')>0 | select * from t_user where name like '%a%' 将 MySql 转换为 PostgreSQL【中文标题】将 MySql 转换为 PostgreSQL【英文标题】:Convert MySql to PostgreSQL 【发布时间】:2010-11-27 01:23:14 【问题描述】:我想从 MySQL 迁移到 PostgreSQL,这还不是一个实时站点,即将推出,并且架构在 MySQL 中已经准备就绪,但考虑到业务模型,我想要一个更好的可扩展数据库,因此要将 MySQL 转换为PostgreSQL,我是否需要逐个表手动完成,或者是否有我可以使用的 GUI 工具(或脚本)来自动转换表/文件值? 我的应用是用 PHP 编写的。 【问题讨论】: 我没有迁移到 PostgreSQL 的经验,所以我不能肯定,但在即将启动时切换数据库听起来有点糟糕。 是的,但最好在我上线之前立即进行切换,而不是在我拥有实时用户数据后进行切换,并且可能会遇到停机时间/问题。 我希望你有一个非常好的测试套件。 MySQL 往往比 PostgreSQL 更宽容/DWIPM(做我可能的意思)。 目前都是手动测试。逐页浏览,查看所有数据都正确记录在后端,没有任何问题。 使用 GROUP BY 测试任何查询 -- PostgreSQL 不支持 MySQL's hidden columns "feature"。还有许多其他细微的差异——更换数据库供应商是一项非常艰巨的任务。 【参考方案1】:唯一为我做的工作是Navicat Premium,你可以获取 Navicat 并免费使用 14 天,这足以进行 DB 迁移... 只需创建2个连接(一个源mysql,另一个目标postgresql),然后选择Tools -> Data Transfer,就可以了! 我尝试过的其他工具: 使用 mysqldump 转储为与 postgresql 兼容 - 不起作用,因为 ansi sql - 不起作用,尝试 pgload - 不起作用,尝试使用 https://github.com/AnatolyUss/nmig Nmig 正确创建表,但数据丢失。 【讨论】: 你拯救了这一天。谢谢!一切都非常简单易行 谢谢!这是在 Windows 上唯一对我有用的东西【参考方案2】:
【讨论】: 【参考方案3】:MySQL 是一个高度可扩展的数据库,被互联网上一些最大和最活跃的网站所使用。我会有一些非常好的测试基准,表明 Postgres 在切换之前会给你带来显着的优势。 【讨论】: 看看这个:mysqlperformanceblog.com/2006/11/30/…以上是关于超全mysql转换postgresql数据库方案的主要内容,如果未能解决你的问题,请参考以下文章 |