Java 数据结构与算法-Map和Set以及其实现类
Posted 学Java的冬瓜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 数据结构与算法-Map和Set以及其实现类相关的知识,希望对你有一定的参考价值。
作者:学Java的冬瓜
博客主页:☀冬瓜的主页🌙
专栏:【JavaEE】
分享:
主要内容:Map和Set的常用方法以及其特性。TreeMap和TreeSet的性质,HashMap和HashSet的性质。关于HashMap的面试题。

文章目录
一、Java中常见集合
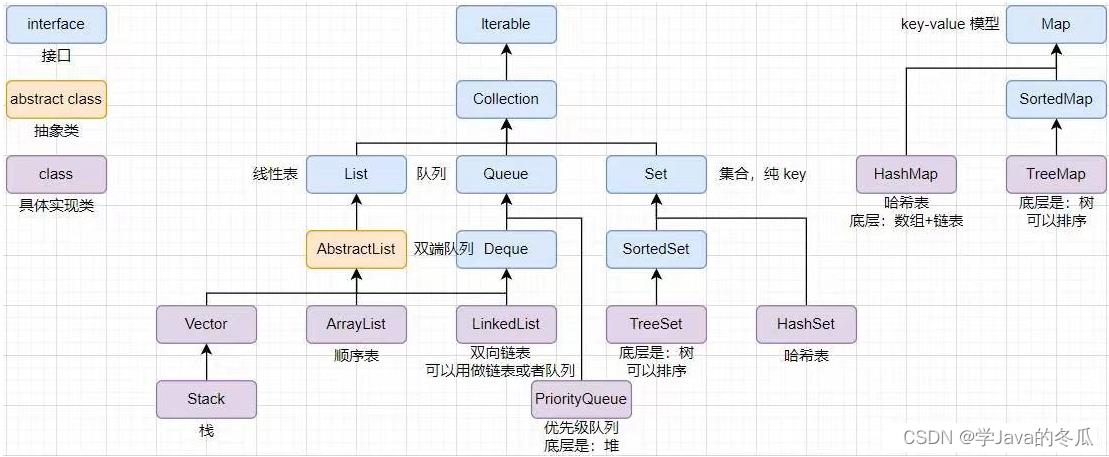
二、Map和Set
1、概念和场景
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。以前常见的 搜索方式有:
- 直接遍历,时间复杂度为O(N),元素如果比较多效率会非常慢
- 二分查找,时间复杂度为O(logN) ,但搜索前必须要求序列是有序的
上述排序比较适合静态类型的查找,即一般不会对区间进行插入和删除操作了,而现实中的查找比如:
- 根据姓名查询考试成绩
- 通讯录,即根据姓名查询联系方式
- 不重复集合,即需要先搜索关键字是否已经在集合中
可能在查找时进行一些插入和删除的操作,即动态查找,那上述两种方式就不太适合了,而
Map和Set是 一种适合动态查找的集合容器。
2、模型

3、Map和Set常用方法
- 注意:Map 没有继承 Iterator 所以不能返回迭代器,而 Set 继承了 Iterator 可以采用迭代器遍历
1>Map常用方法
Map的常用方法:
| 方法 | 解释 |
|---|---|
V get(Object key) | 返回 key 对应的 value |
| V getOrDefault(Object key, V defaultValue) | 返回 key 对应的 value,key 不存在,返回默认值 |
V put(K key, V value) | 设置 key 对应的 value |
V remove(Object key) | 删除 key 对应的映射关系 |
Set keySet() | 返回所有 key 的不重复集合 |
| Collection values() | 返回所有 value 的可重复集合 |
Set<Map.Entry<K, V>> entrySet() | 返回所有的 key-value 映射关系 |
| boolean containsKey(Object key) | 判断是否包含 key |
| boolean containsValue(Object value) | 判断是否包含 value |
@ Map方法演示
接下来我们在代码中来使用相关的方法,简单的就不演示了,以下代码只演示了keySet,values,entrySet三个方法。
HashMap和TreeMap都都适用以下方法,因为它们都是是Map,是key-value模型。
代码如下:
public class Main
public static void main(String[] args)
Map<Integer,String> map1 = new TreeMap<>();
map1.put(1,"张三");
map1.put(3,"lisi");
map1.put(5,"lisi");
System.out.println("keySet获取map的所有key的不重复集合");
Set<Integer> keySets = map1.keySet();
System.out.println(keySets);
System.out.println("values获取map所有value的可重复集合");
Collection<String> values = map1.values();
System.out.println(values);
System.out.println("entrySet获取所有的key-value映射关系");
// entrySet方法功能:把map的key和value打包成Map.Entry<Integer,String>,然后放入Set中作为Set的key
Set<Map.Entry<Integer, String>> entries = map1.entrySet();
System.out.println("遍历1 toString:");
System.out.println(entries);
System.out.println("遍历2 foreach:");
for (Map.Entry<Integer,String> entry : entries)
System.out.print(entry.getKey() + ":" + entry.getValue() + " ");
结果:
values获取map所有value的可重复集合
[张三, lisi, lisi]
entrySet获取所有的key-value映射关系
遍历1 toString:
[1=张三, 3=lisi, 5=lisi]
遍历2 foreach:
1:张三 3:lisi 5:lisi
在上面代码中,使用Set<Map.Entry<k,v>> entrySet()把Map打包成Map.Entry<k,v>,然后把它放进Set后遍历使用foreach时,使用了以下方法的前两个。
k getKey() 返回ertry中的key
v getValues() 返回entry中的value
v setValue(V value) 将键值对中的value替换为指定value
那么问题来了,不能直接用foreach遍历Map吗?
不行!要想用foreach遍历,包括要用迭代器,必须实现Iterable接口,而Map没有实现,Set实现了。所以把Map变成Set再用foreach遍历。
那问题又来了,map可以使用哪些方法遍历?
第一种:先获取Map集合的全部key的set集合,遍历map的key的Set集合,通过map的key提取对应的value。
第二种:使用foreach遍历把map的key和value打包成Set的key后的这个Set集合
第三种:new一个BiConsumer<key, value>(),然后传入map.foreach()中(和传比较器一样)
第四种:使用lambda表达式
代码实现请看这篇博客:【遍历Map和Set的方式】
2>Set常用方法
Set的常用方法:
| 方法 | 解释 |
|---|---|
boolean add(E e) | 添加元素,但重复元素不会被添加成功 |
| void clear() | 清空集合 |
boolean contains(Object o) | 判断 o 是否在集合中 |
Iterator iterator() | 返回迭代器 |
boolean remove(Object o) | 删除集合中的 o |
| int size() | 返回set中元素的个数 |
| boolean isEmpty() | 检测set是否为空,空返回true,否则返回false |
| Object[] toArray() | 将set中的元素转换为数组返回 |
| boolean containsAll(Collection<?> c) | 集合c中的元素是否在set中全部存在 是返回true否则返回false |
boolean addAll(Collection<? extends E> c) | 将集合c中的元素添加到set中,可以达到去重的效果 |
@ Set方法演示
接下来我们用代码来使用Set的toArray和addall方法。
代码如下:
public class Main
// 测试使用Set的部分方法
public static void main(String[] args)
// boolean addAll方法
Set<Integer> set1 = new TreeSet<>();
set1.add(3);
set1.add(5);
Set<Integer> set2 = new TreeSet<>();
set2.add(1);
set2.add(5);
set1.addAll(set2);
System.out.println(set1);
// Object[] toArray 方法
Object[] objects = set1.toArray();
for (Object o : objects)
System.out.print(o + " ");
结果:
[1, 3, 5]
1 3 5
4、Map和Set的实现类概述

三、TreeMap和TreeSet
1、TreeMap和TreeSet的性质
TreeMap和TreeSet: | TreeMap | TreeSet |
|---|---|---|
| 底层结构 | 红黑树 | 红黑树 |
| 插入/删除/ 查找时间复杂度 | O(logn) | O(logn) |
| 是否有序 | 关于key有序 | 关于key有序 |
| 插入/删除/查找操作 | 需要进行元素比较,按照红黑树的特性进行插入删除 | 和TreeMap一样 |
| 比较 | key必须可以比较,否则会 抛出ClassCastException异常 | 和TreeMap一样 |
| 应用场景 | 需要key有序情况下 | 和TreeMap一样 |
我们一点一点来分析关于 TreeMap和 TreeSet的这个表中的内容:
1> 底层结构:
红黑树。首先TreeMap和TreeSet从名字上看很明显都和树有关,因为TreeMap和TreeSet的底层都是纯红黑树。
2> 有序性:
关于key有序(指的是平衡二叉搜索树这个结构关于key有顺序,而不是1,2,3,4这样有序)。因为底层是红黑树,即平衡二叉搜索树,插入数据时要根据比较key大小再插入。
中序遍历的结果可以让数据关于key从小到大排列,但中序遍历其实只是一种遍历的方式,和关于key有序无关。
3> 可比较:
由于在插入/删除/查找时,都需要比较key的大小,所以这个key必须是可比较的,如果是一个类比如Student类,那不能直接比较,就需要让它可比较,此时可以让Student类继承Comparable接口,再重写compareTo方法(或者写比较器传入new的TreeMap或TreeSet中)
如果从源码上看也可看出来TreeMap继承了SortedMap接口,而TreeSet继承了SortedSet接口,表示元素应该是可排序的,就得是可比较的才能进行排序。(看第一大点Java中常见集合)
而HashMap和HashSet都没有继承Sorted接口,所以不需要传入的数据可比较,因为它们是通过哈希表实现的。
2、TreeMap以Student的name作为比较
代码如下:
class Student
public int id;
public String name;
public Student(int id, String name)
this.id = id;
this.name = name;
@Override
public String toString()
return "(id:" + id + ",name:" + name + ")";
public class Main
public static void main(String[] args)
Map<String, Integer> map1 = new TreeMap<>();
map1.put("lisi",12);
map1.put("wangwu",37);
map1.put("zhaoliu",89);
map1.put("xiaosi",42);
System.out.println("TreeMap:");
System.out.print("map1:");
System.out.println(map1);
// 要求key可比较,所以以下的代码中,Student的类必须是可比较的
Map<Student,Integer> map2 = new TreeMap<>(new Comparator<Student>()
@Override
public int compare(Student o1, Student o2)
return o1.name.compareTo(o2.name); // 以Student对象的name为比较对象
);
map2.put(new Student(1,"zhangsan"),10);
map2.put(new Student(2,"lisi"),10);
//map2.put(null,10); //TreeMap的key不能为null
System.out.print("map2:");
System.out.println(map2);
结果:
TreeMap:
map1:lisi=12, wangwu=37, xiaosi=42, zhaoliu=89
map2:(id:2,name:lisi)=10, (id:1,name:zhangsan)=10
- 以上代码是对TreeMap的演示,因为TreeSet底层是TreeMap,所以是一样的。
- map1的key和value类型分别为String和Integer,而map2的key和value的类型分别是Student和Integer。
- 因为map1和map2是TreeMap,所以存入的元素必须是可比较的,对于map1来说,字符串类型可以比较,所以不用传比较器,会根据字母的顺序比较;但对于map2来说,就不能自动比较了,Student对象本身不可比较,但是Student对象的内容可比较,这时我们就需要传入比较器,比如上面的代码就是使用Student的name属性来给Student类型元素比较。
四、HashMap和HashSet
1、HashMap和HashSet的性质
HashMap和HashSet: | HashMap | HashSet |
|---|---|---|
| 底层结构 | 哈希桶 | 哈希桶 |
| 插入/删除/ 查找时间复杂度 | O(1) | O(1) |
| 是否有序 | 无序 | 无序 |
| 插入/删除/查找操作 | 通过哈希函数计算哈希地址 | 1.先计算key哈希地址 2.然后进行插入和删除 |
| 覆写 | 自定义类型需要覆写 equals和hashCode方法 | 和HashMap一样 |
| 应用场景 | key是否有序不关心,需要更高的时间性能 | 和HashMap一样 |
接下来我们来分析关于HashMap和HashSet的表中内容:
1> 底层结构:
哈希桶。那什么是哈希桶?我们来理一下,哈希表是一种数据结构,它通过哈希函数将key映射到地址(Hash(key)),然后在地址上存储value值。而哈希桶是哈希表的一种实现方式,它使用一个数组来存储键值对,每个数组元素都是一个链表或者红黑树,用于解决哈希冲突。那么怎么得到数组地址的? 操作是通过哈希函数将key映射到数组索引,所以哈希桶是哈希表的一种实现方式。
2> 无序性:
由于哈希函数是随机的,所以哈希表中的元素是无序的。
3> 覆写:
两个对象相等,hashcode必须相等;两个对象不相等,hashCode可能相等,这就会产生哈希冲突,用开散列(示例都是链地址法解决哈希冲突)。
相当于hashCode再通过哈希函数定位数组地址下标,再使用equals去比较当前元素和链表中的key是否相等。所以:两个对象的hashCode一样,equals不一定一样;两个对象的equals一样,hashCode一定一样。
注意:在以下示例中,Student就是Map的key,重写hashCode和重写equals都和map的value无关。
4> 重写hashCode:
HashMap种在put时,散列函数根据对象的哈希值计算然后找到对应的位置,如果该位置有元素,首先会使用hashCode方法判断新增元素和链表中的元素key是否相同,如果没有重写hashCode方法,那么就是使用object的hashcode方法,这样的话,即使两个对象的key相同,hashCode方法也会认为它们是不同的元素,会有不同的哈希值,但是我们知道HashMap的key是唯一的,那就产生了矛盾。
当重写了hashCode方法后就可以保证相同的key有相同的哈希值(比如Student作为HashMap的key,在Student类中重写hashCode方法,方法中return Objects.hash(id)),就可以保证相同的Student有相同的哈希值,就防止了key相同的两个对象重复插入的问题。在HashMap中没有相同的哈希值,散列函数再根据这个哈希值找到相同的数组下标。因此hashMap中key相同(与value无关)的元素重写hashcode后,哈希值相等。
5> 重写equals:
对于equals方法,我们知道HashMap中数据结构是哈希表,可以使用开散列(链地址法)解决哈希冲突,是数组+链表的形式,在我们重写hashCode后,解决了相同对象得到不同哈希值的问题,但是不同的对象可以得到相同的哈希值,从而散列到相同的数组下标下,如果没有重写equals,那就使用的是object的equals方法,内容是:return (this == obj),即比较的地址,那么插入元素的地址和在链表中元素的地址肯定是不一样的,那两个相同的Student类型的元素就会被判定为不相等,除非重写equals,去比较链表中的对象和新增对象是否一样,两个对象不一样就可以进行put了。因此,重写hashCode找到key后,再重写equals(用value作为比较对象,而不是Object类下的比较地址的方法),就可以实现正确的查找
五、总结
- Map没有实现Collection接口(单列),Map是双列的,即key-value模型。Map没有实现Iterable接口,所以不能使用foreach遍历,必须先用entrySet方法打包key-value为Set的key,再用foreach来遍历。
- TreeMap和TreeSet的key都不能为null,因为插入删除等操作时需要比较,而HashMap和HashSet的key和value都可以为null,因为不需要比较,而是使用哈希表的方式。
- 对于TreeMap和HashMap来说,插入两个元素,这两个元素key相同value不同,会怎么样? TreeMap和HashMap中只有后插入的元素。因为TreeMap和HashMap的key唯一,所以相当于把第二个插入的元素的value放在了第一个插入元素的value的位置,即只是更新了value。
对于TreeSet和HashSet来说,也是一样的,只是无法观察,因为它们只有key,没有value,即结果还是一个数据,还是和第一个插入的key一样。
六、问题
1、HashMap什么时候申请的空间
public HashMap()
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
- 不带容量参数时,是在第一次put时才申请空间,且默认是16(1>>>4)。
2、HashMap传入容量参数时申请空间多大?
public HashMap(int initialCapacity)
this(initialCapacity, DEFAULT_LOAD_FACTOR);
- HashMap传入容量参数时,使用容量参数的在有参构造方法中就申请空间,但是申请空间的大小并不一定是给定的容量参数,而是很接近容量参数同时满足是2的次方的空间。
3、讲一下你理解的hashCode和equals的区别?
- hashCode加上哈希函数定位数组地址,然后equals比较HashMap的具体的key。
4、当HashMap满了的时候,我们需要注意什么?
- 每个元素都需要重新哈希
5、什么时候树化?什么时候解树化?
- 树化:数组长度大于等于64且链表长度大于等于8就会树化(变成红黑树)。
- 解树化:当一棵红黑树不断删除元素,红黑树的元素个数小于等于6时,会把树转为链表。
Java 数据结构与算法-Map和Set的OJ题
作者:学Java的冬瓜
博客主页:☀冬瓜的主页🌙
专栏:【Java 数据结构与算法】
内容:1、只出现一次的数字 4、复制带随机指针的链表 5、石头里选出宝石 6、坏键盘打字
文章目录
一、正确选择Map和Set的实现类示例
Main方法:
public static void main(String[] args)
Random random = new Random();
int[] arr = new int[10_0000];
for (int i = 0; i < arr.length; i++)
arr[i] = random.nextInt(100);
f1(arr);
1、统计10w个数中不重复的数据,这些数据0-99
- 使用Set容器来装这些数据
public static void f1(int[] arr)
Set<Integer> set = new HashSet<>(); // TreeSet也行,只是效率上看HashSet更快
for (int i = 0; i < arr.length; i++)
set.add(arr[i]);
System.out.println(set);
2、打印10w个数中第一个重复的数据
- 创建一个Set容器,如果当前元素不在Set中,则add,如果已经在Set中,那么这个数据就是第一个重复的数据,打印然后直接return。
public static void f2(int[] arr)
Set<Integer> set = new HashSet<>();
for (int i = 0; i < arr.length; i++)
if(!set.contains(arr[i]))
// System.out.print(arr[i]+" "); //便于观察
set.add(arr[i]);
else
System.out.println();
System.out.println(arr[i]);
return;
3、统计10w个数据当中,每个数据出现的次数
- 遍历原来的数据,把a[i]作为map的key存入map中。遍历时,如果map中还没有以当前a[i]为key的数据,那就存入value=1,如果已经有了key对应的value,那就将value+1再存入。
public static void f3(int[] arr)
// 第一步:遍历原来的数据,统计每个数据出现的次数
Map<Integer,Integer> map = new HashMap<>();
for (int i = 0; i < arr.length; i++)
int key = arr[i];
// 第二步:判断以arr[i]作为key的值是否已经存在
if (map.get(key) == null)
map.put(key,1);
else
int val = map.get(key);
map.put(key, val + 1);
System.out.println(map);
二、Map和Set的OJ题
1、只出现一次的数字
法一:异或
- 相同的数异或结果为0,0和非0数异或结果为这个数。因为只有一个数只出现了1次,其它数都出现了两次,所以把数组中所以元素拿来异或,异或的结果就是这个只出现一次的数。
// 法一:使用异或
class Solution
public int singleNumber(int[] nums)
int x = nums[0];
for(int i=1; i<nums.length; i++)
x^=nums[i];
return x;
法二:Set解决
- 。因为只有一个数只出现了1次,其它数都出现了两次。遍历这个数组时,当我们遇到一个不在Set中的数据时,就把数据add进Set,当遇到一个在Set中的数据时,把这个数从Set中移除,这样Set中就只剩下了只出现一次的数据。
// 法二:使用集合Set
class Solution
public int singleNumber(int[] nums)
Set<Integer> set = new HashSet<>();
for(int i=0; i<nums.length; i++)
if(!set.contains(nums[i]))
set.add(nums[i]);
else
set.remove(nums[i]);
for(Integer x : set)
return x;
return -1;
法三:Map解决
- 先遍历一遍数组,使用Map统计各个数据出现的次数,再把Map拿来遍历,如果当前数据的Key对应的value == 1,那结果就是这个数据对应的key。
// 法三:使用集合Map
class Solution
public int singleNumber(int[] nums)
Map<Integer,Integer> map = new HashMap<>();
for(int i=0; i<nums.length; i++)
int key = nums[i];
if(map.get(key) == null)
map.put(key,1);
else
int val = map.get(key);
map.put(key,val+1);
// 开始遍历map,先把map变成set
Set<Map.Entry<Integer,Integer>> entrySet = map.entrySet();
for(Map.Entry<Integer,Integer> entry : entrySet)
if(entry.getValue() == 1)
return entry.getKey();
return -1;
2、只出现一次的数字II
// 使用Map解决
class Solution
public int singleNumber(int[] nums)
Map<Integer,Integer> map = new HashMap<>();
for(int i=0; i<nums.length; i++)
int key = nums[i];
if(map.get(key) == null)
map.put(key,1);
else
int val = map.get(key);
map.put(key,val+1);
// 开始遍历map,先把map变成set
Set<Map.Entry<Integer,Integer>> entrySet = map.entrySet();
for(Map.Entry<Integer,Integer> entry : entrySet)
if(entry.getValue() == 1)
return entry.getKey();
return -1;
3、只出现一次的数字 III
法一:Set解决
// 使用Set解决
class Solution
public int[] singleNumber(int[] nums)
// 法一:使用Set
Set<Integer> set = new HashSet<>();
for(int i=0; i<nums.length; i++)
if(!set.contains(nums[i]))
set.add(nums[i]);
else
set.remove(nums[i]);
List<Integer> list = new ArrayList<>();
for(Integer x : set)
list.add(x);
int[] ret = new int[list.size()];
for(int i=0; i<list.size(); i++)
ret[i] = list.get(i);
法二:Map解决
// 使用map解决
class Solution
public int[] singleNumber(int[] nums)
// 用Map统计每个元素出现的次数
Map<Integer,Integer> map = new HashMap<>();
for(int i=0; i<nums.length; i++)
int key = nums[i];
if(map.get(key) == null)
map.put(key,1);
else
int val = map.get(key);
map.put(key,val+1);
// 把结果放进ArrayList
List<Integer> list = new ArrayList<>();
int cnt = 0;
Set<Map.Entry<Integer,Integer>> entrySet = map.entrySet();
for(Map.Entry<Integer,Integer> entry : entrySet)
if(entry.getValue() == 1)
list.add(entry.getKey());
注意:遍历map时使用lambda表达式更简单
// map.forEach((k,v)->
// if(v == 1)
// list.add(k);
//
// );
// 把结果放进数组
int[] ret = new int[list.size()];
for(int i=0; i<list.size(); i++)
ret[i] = list.get(i);
return ret;
4、复制带随机指针的链表
/*
// Definition for a Node.
class Node
int val;
Node next;
Node random;
public Node(int val)
this.val = val;
this.next = null;
this.random = null;
*/
class Solution
public Node copyRandomList(Node head)
Map<Node,Node> map = new HashMap<>();
Node cur = head;
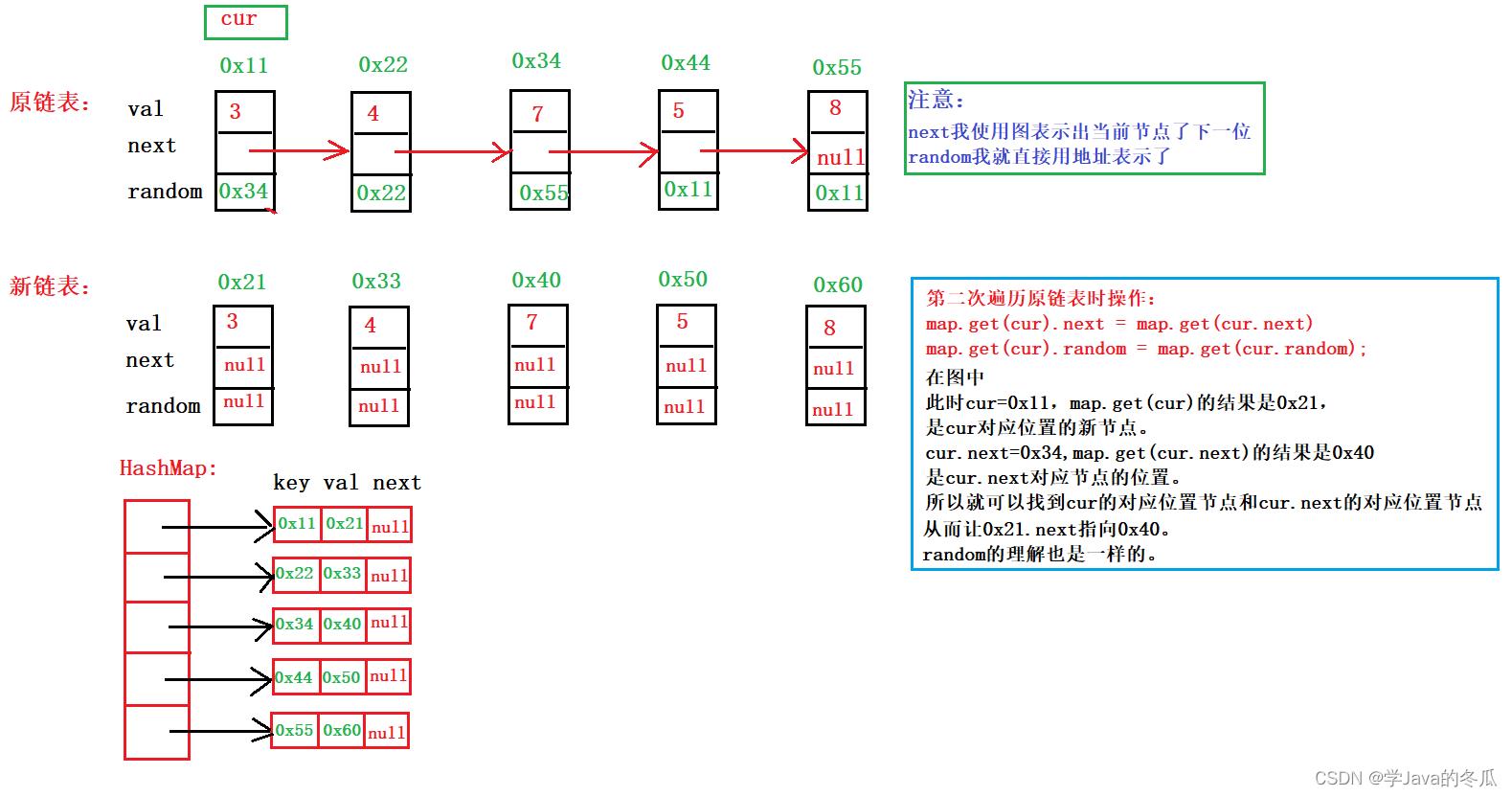
// 第一步:第一次遍历链表,申请新的空间,传节点的val值,把旧节点作为key,对应位置的新节点作为value存入map。
while(cur != null)
Node newNode = new Node(cur.val);
map.put(cur,newNode);
cur = cur.next;
// 第二步:第二次遍历链表,把新节点的next和random引用根据map指向正确的节点
cur = head;
while(cur != null)
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
// 第三步,返回原链表对应头节点的新链表的头节点。
return map.get(head);
- 第一次遍历链表,申请新的空间,传节点的val值,把旧节点作为key,对应位置的新节点作为value存入map。
第二次遍历链表,代码是map.get(cur).next = map.get(cur.next);当前cur是原节点,通过map和cur,map.get(cur)就是原节点对应的新节点,而map.get(cur.next)是原节点的下一个节点对应位置的新节点。
第三步,返回原链表对应头节点的新链表的头节点。
如果还有问题,在第二次开始遍历时,见下图:
5、石头里选出宝石
法一:两个for循环
//法一:使用两个for循环,借助ArrayList集合(或者使用个count计数也可)
class Solution
public int numJewelsInStones(String jewels, String stones)
List<Character> list = new ArrayList<>();
for (int i = 0; i < jewels.length(); i++)
char a = jewels.charAt(i);
for (int j = 0; j < stones.length(); j++)
char b = stones.charAt(j);
if (a == b)
list.add(a);
return list.size();
法二:Set的contains方法
// 法二:使用Set的contains方法
class Solution
public int numJewelsInStones(String jewels, String stones)
int count = 0;
Set<Character> set = new HashSet<>();
for(int i=0; i<jewels.length(); i++)
char a = jewels.charAt(i);
set.add(a);
for(int i=0; i<stones.length(); i++)
char b = stones.charAt(i);
if(set.contains(b))
count++;
return count;
6、坏键盘打字
链接:【牛客.旧键盘】
import java.util.*;
public class Main
public static void func(String str1, String str2)
以上是关于Java 数据结构与算法-Map和Set以及其实现类的主要内容,如果未能解决你的问题,请参考以下文章