对SQL慢查询的优化(MySQL)
Posted 一碗谦谦粉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对SQL慢查询的优化(MySQL)相关的知识,希望对你有一定的参考价值。
一、慢查询原因
要对慢查询进行优化,首先要搞清楚慢查询的原因,原因主要有三:
(1)加载了不需要的数据列
(2)查询条件没有命中索引
(3)数据量太大
二、优化方案
优化也是针对这三个方向的:
(1)先分析语句,看看是否加载了额外的数据,可能是查询了多余的行并且抛弃掉了,可能是加载了许多结果中并不需要的列,如果有这些问题,则对语句进行分析、重写
(2)分析语句的执行计划,获得其使用索引的情况,然后修改语句或修改索引,使得语句尽可能地命中索引
(3)如果对语句的优化都已经无法进行了,可以考虑是否是表中数据量太大引起的慢查询,如果是,则可以进行横向或者纵向分表
三、补充-执行计划
1、mysql的执行计划怎么看
(1)最简单的做法是,使用可视化工具Navicat,执行查询时打开【解释】

(2)具体的含义

| 执行计划字段对照表 | ||
| 序号 | 字段 | 作用 |
| 1 | id | id是一个有顺序的编号,是查询的顺序号 (1)id的顺序按select出现的顺序增长,有几个select就显示几行,就有几个id。 (2)id列的值越大执行的优先级越高越先执行,id列的值相同则从上往下执行,id列的值为NULL最后执行 |
| 2 | select_type | 表示查询中每个select子句的类型 (1)SIMPLE: 表示此查询不包含 UNION 查询或子查询(2)PRIMARY: 表示此查询是最外层的查询(包含子查询) (3)SUBQUERY: 子查询中的第一个 SELECT (4)UNION: 表示此查询是 UNION 的第二或随后的查询 (5)DEPENDENT UNION: UNION 中的第二个或后面的查询语句,取决于外面的查询 (6)UNION RESULT,UNION 的结果 (7)DEPENDENT SUBQUERY:子查询中的第一个 SELECT,取决于外面的查询. 即子查询依赖于外层查询的结果 (8)DERIVED:衍生,表示导出表的SELECT(FROM子句的子查询) |
| 3 | table | 表示该语句查询的表 |
| 4 | partitions | |
| 5 | type | 是优化SQL的重要字段,判断SQL性能和优化程度的重要指标。 type的取值类型范围: (1)const:通过索引一次命中,匹配一行数据 (2)system:表中只有一行记录,相当于系统表 (3)eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配 (4)ref:非唯一性索引扫描,返回匹配某个值的所有 (5)range:只检索给定范围的行,使用一个索引来选择行,一般用于:between,<,> (6)index:只遍历索引树 (7)ALL:表示全表扫描,这个类型的查询是性能最差的查询之一。随着表的数量增多,执行效率变慢 *(8)执行效率: |
| 6 | possible_keys | 表示Mysql在执行该sql语句的时候,可能用到的索引信息,仅仅是可能,实际不一会用到。很多时候索引不一定会命中。 |
| 7 | key | 此字段是 mysql 在当前查询时所真正使用到的索引。 key是possible_keys的子集 |
| 8 | key_len | 表示查询优化器使用了索引的字节数,这个字段可以评估组合索引是否完全被使用,这也是我们优化sql时,评估索引的重要指标。 |
| 9 | ref | |
| 10 | rows | mysql 查询优化器根据统计信息,估算该sql返回结果集需要扫描读取的行数,这个值相关重要,索引优化之后,扫描读取的行数越多,说明索引设置不对,或者字段传入的类型之类的问题,说明要优化空间越大 |
| 11 | filtered | 返回结果的行占需要读到的行(rows列的值)的百分比,就是百分比越高,说明需要查询到数据越准确, 百分比越小,说明查询到的数据量大,而结果集 |
| 12 | extra | (1)using filesort :表示 mysql 对结果集进行外部排序,不能通过索引顺序达到排序效果。一般有using filesort都建议优化去掉,因为这样的查询 cpu 资源消耗大,延时大。 (2)using index:覆盖索引扫描,表示查询在索引树中就可查找所需数据,不用扫描表数据文件,往往说明性能不错。 (3)using temporary:查询有使用临时表, 一般出现于排序, 分组和多表 join 的情况, 查询效率不高,建议优化。 (4)using where :sql使用了where过滤,效率较高。 |
对1的一个例子:有多少个select就有多少行,就有多少id
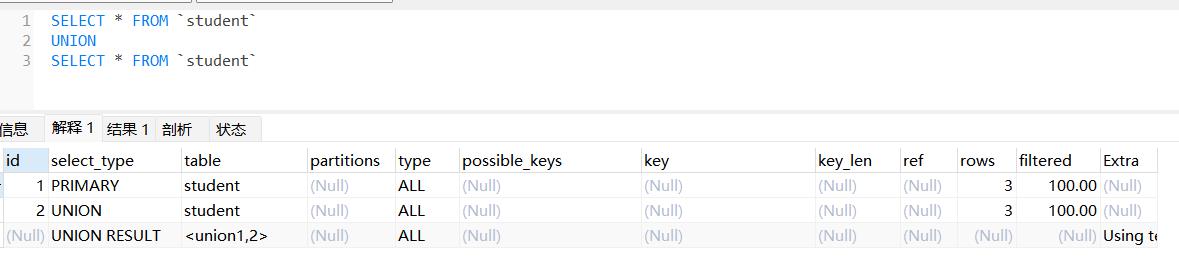
注:执行计划就是SQL的执行查询的顺序。
2、SQL语句的执行顺序
SQL语句的执行顺序是区别于,SQL的执行查询的顺序的,这感觉有点咬字眼了。
但是一般说的SQL语句的执行顺序是指:
SELECT * FROM `student` 这么一个select查询语句的执行顺序,这里是先from然后才是select。
如果有where等其他关键字:
select 语句的执行顺序
| 1 | from |
| 2 | join |
| 3 | on |
| 4 | where |
| 5 | group by |
| 6 | count、sum等统计函数 |
| 7 | having |
| 8 | select |
| 9 | distinct |
| 10 | order by |
| 11 | limit |
3、关于索引没有命中的一种猜想
如果创建了索引,特别是组合索引,却没有命中,那么优先要考虑创建的索引有没有符合最左前缀原则。
(1)最左前缀原则:顾名思义是最左优先,以最左边的为起点任何连续的索引都能匹配上。
1)如果第一个字段是范围查询需要单独建一个索引;
2)在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边;
当创建(a,b,c)复合索引时,想要索引生效的话,只能使用 a和ab、ac和abc三种组合。
(2)一个例子:
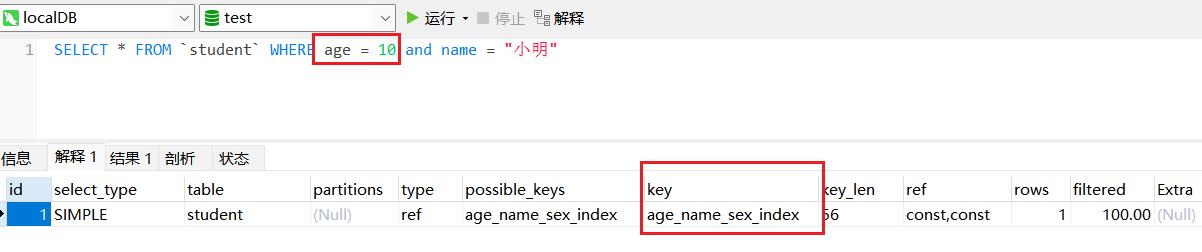
为student表创建一个组合索引 age_name_sex_index

在执行计划中可以看到,索引命中了,这时where 了 age字段
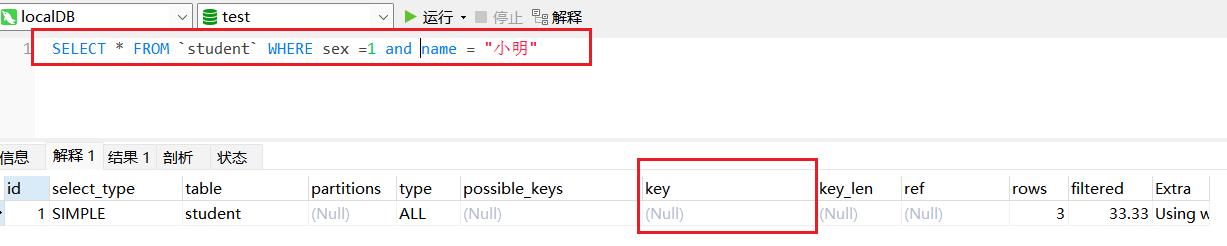
但是如果没有where了age字段,那么索引就不会命中
MySQL优化:慢SQL分析
对慢SQL优化一般可以按下面几步的思路:
1、开启慢查询日志,设置超过几秒为慢SQL,抓取慢SQL
2、通过explain对慢SQL分析(重点)
3、show profile查询SQL在Mysql服务器里的执行细节和生命周期情况(重点)
4、对数据库服务器的参数调优
一、慢查询日志
1、设置慢查询
(1)设置开启:SET GLOBAL slow_query_log = 1; #默认未开启,开启会影响性能,mysql重启会失效 (2)查看是否开启:SHOW VARIABLES LIKE \'%slow_query_log%\'; (3)设置阈值:SET GLOBAL long_query_time=3; (4)查看阈值:SHOW 【GLOBAL】 VARIABLES LIKE \'long_query_time%\'; #重连或新开一个会话才能看到修改值 (5)通过修改配置文件my.cnf永久生效,在[mysqld]下配置: [mysqld] slow_query_log = 1; #开启 slow_query_log_file=/var/lib/mysql/atguigu-slow.log #慢日志地址,缺省文件名host_name-slow.log long_query_time=3; #运行时间超过该值的SQL会被记录,默认值>10 log_output=FILE
2、获取慢SQL信息
查看慢查询日志记录数:SHOW GLOBAL STATUS LIKE \'%Slow_queries%\';
模拟语句:select sleep(4);
查看日志:cat atguigu-slow.log

3、搭配日志分析工具mysqldumpslow
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log #得到返回记录集最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/atguigu-slow.log #得到访问次数最多的10个SQL
mysqldumpslow -s t -t 10 -g "LEFT JOIN" /var/lib/mysql/atguigu-slow.log #得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s r -t 10 /var/lib/mysql/atguigu-slow.log | more #结合| more使用,防止爆屏情况
s:表示按何种方式排序
c:访问次数
l:锁定时间
r:返回记录
t:查询时间
al:平均锁定时间
ar:平均返回记录数
at:平均查询时间
t:返回前面多少条的数据
g:后边搭配一个正则匹配模式,大小写不敏感
二、explain分析慢SQL
通过explain分析慢SQL很重要,单独一章列举,MySQL优化(4):explain分析。
三、Show Profile分析慢SQL
Show Profile也是分析慢SQL的一种手段,但它能获得比explain更详细的信息,能分析当前会话中语句执行的资源消耗情况,能获得这条SQL在整个生命周期的耗时,相当于执行时间的清单,也很重要。
1、默认关闭。开启后,会在后台保存最近15次的运行结果,然后通过Show Profile命令查看结果。
开启:set profiling = on;
查看:SHOW VARIABLES LIKE \'profiling%\';
2、通过Show Profile能查看SQL的耗时

3、通过Query_ID可以得到具体SQL从连接 - 服务 - 引擎 - 存储四层结构完整生命周期的耗时

可用参数type:
ALL #显示所有的开销信息
BLOCK IO #显示块IO相关开销
CONTEXT SWITCHES #上下文切换相关开销
CPU #显示CPU相关开销信息
IPC #显示发送和接收相关开销信息
MEMORY #显示内存相关开销信息
PAGE FAULTS #显示页面错误相关开销信息
SOURCE #显示和Source_function,Source_file,Source_line相关的开销信息
SWAPS #显示交换次数相关开销的信息
4、出现这四个status时说明有问题,group by可能会创建临时表
#危险状态:
converting HEAP to MyISAM #查询结果太大,内存不够用了,在往磁盘上搬 Creating tmp table #创建了临时表,回先把数据拷贝到临时表,用完后再删除临时表 Copying to tmp table on disk #把内存中临时表复制到磁盘,危险!!! locked

四、全局查询日志
只在测试环境用,别在生产环境用,会记录所有使用过的SQL
1、开启:
开启:会将sql记录到mysql库的general_log表
set global general_log=1;
set global log_output=\'TABLE\';
配置文件的方式:
在my.cnf中配置
general_log=1 #开启
general_log_file=/path/logfile #记录日志文件的路径
log_output=FILE #输出格式
2、查看
select * from mysql.general_log;

以上是关于对SQL慢查询的优化(MySQL)的主要内容,如果未能解决你的问题,请参考以下文章