MySQL主从不一致问题处理
Posted 羌俊恩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL主从不一致问题处理相关的知识,希望对你有一定的参考价值。
一、背景
某业务采取mysql的主从架构,但因为存储的问题,导致备库一直无法存储,数据同步一致性问题一直也未恢复,某次安全检查要求完成主备倒换演练,必须限期恢复主备,但是在恢复过程中,同步显示正常一段时间后,便会出现sql线程异常,主备数据不一致导致的同步错误情况。
二、可能原因
1、网络的延迟
由于mysql主从复制是基于binlog的一种异步复制通过网络传送binlog文件,理所当然网络延迟是主从不同步的绝大多数的原因,特别是跨机房的数据同步出现这种几率非常的大,所以做读写分离,注意从业务层进行前期设计。
2、主从两台机器的负载不一致
由于mysql主从复制是主数据库上面启动1个io线程,而从上面启动1个sql线程和1个io线程,当中任何一台机器的负载很高,忙不过来,导致其中的任何一个线程出现资源不足,都将出现主从不一致的情况。
3、max_allowed_packet设置不一致
主数据库上面设置的max_allowed_packet比从数据库大,当一个大的sql语句,能在主数据库上面执行完毕,从数据库上面设置过小,无法执行,导致的主从不一致。
4、自增键不一致
key自增键开始的键值跟自增步长设置不一致引起的主从不一致。
5、同步参数设置问题
mysql异常宕机情况下,如果未设置sync_binlog=1或者innodb_flush_log_at_trx_commit=1很有可能出现binlog或者relaylog文件出现损坏,导致主从不一致。
6、自身bug
mysql本身的bug引起的主从不同步,一般不会
7、版本不一致
特别是高版本是主,低版本为从的情况下,主数据库上面支持的功能,从数据库上面不支持该功能的情况。
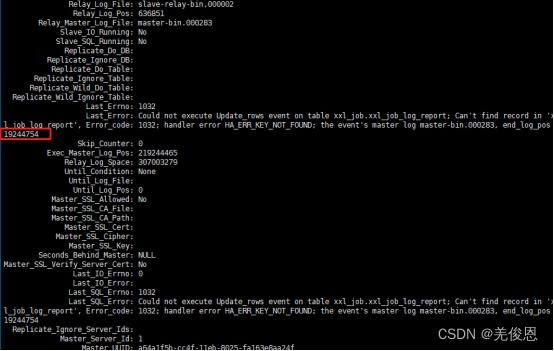
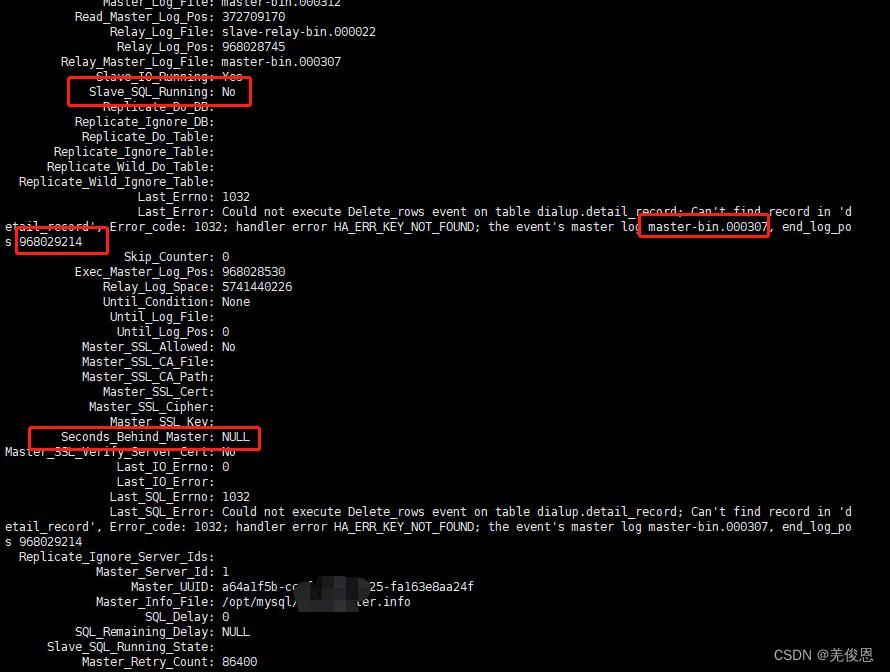
注意:sql_thread是根据主键匹配行记录,不会校验行数据;有没有主键的情况下,sql_thread是根据全表扫描匹配行记录,所以master更新在slave中找不到需要更新的行,报1032错误
Last_SQL_Error: Could not execute Update_rows event on table rsms.t_sys_file; Can’t find record in ‘t_sys_file’, Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event’s master log mysql-bin.004186, end_log_pos 269313742
MySQL主从同步的1032错误,一般是指在从节点侧要更改(update、delete)的数据不存在,SQL_THREAD提取的日志无法应用故报错,造成同步失败;(Update、Delete、Insert一条已经delete的数据)。1032的错误本身对数据一致性没什么影响,影响最大的是造成了同步失败、同步停止。如果主主(主从)有同步失败,要第一时间查看并着手解决。因为不同步,会造成读取数据的不一致。应在第一时间恢复同步
更改my.cnf文件,在Replication settings下添加:
slave-skip-errors = 1032 ;并重启数据库,然后start salve;它是只读参数,不能动态修改;这个参数针对gtid和传统复制有效,并且俩者的结果都一样。报错的SQL语句会跳过,但是其余的SQL还是正常执行。设置slave_skip_errors=1062或者1032在binlog_format是ROW的情况下,整个事务只会跳过报1062或者1032错误的sql,不执行这条SQL其余的sql正常进行。
ERROR 1062主键冲突的错误,无论binlog_format是ROW格式还是STATEMENT格式,从库发生主键冲突的行的值都会被主库同步过来的数据给覆盖掉,即认为在从库执行replace操作。
针对1032行找不到的错误,无论binlog_format是ROW格式还是STATEMENT格式,从库本地都会忽略这条SQL语句,不执行,只是执行事务的其他没有错误的SQL。
在binlog_format为ROW格式的情况下,在出现1032或者1062的情况下,并且table存在自增健为主键,并且在master上面执行insert操作的时候没有指定主键,这个时候需要注意主键的键值信息,很有可能在出现1032或者1062错误跳过之后master和slave俩者的主键下一个键值可能不一致。所以需要注意的操作有delete,insert,truncate。在binlog_format的格式是ROW格式的情况下面,无论是1032还是1062情况下设置sql_slave_skip_counter=1,它会将整个事务跳过去。在binlog_format的格式是statement的情况下,sql_slave_skip_counter=1并且是1062的错误,它会将整个事务跳过去。而针对1032错误,在整个事务当中出现修改一个主库存在,但是从库不存在的row的数据的时候,在从库是不会报错的,且该事务的其他sql语句是可以成功执行的。

附1:主从计算延迟的伪代码
//The pseudo code to compute Seconds_Behind_Master:
if(SQL thread is running)
//如果SQL线程启动了
if(SQL thread processed all the available relay log)
//如果SQL线程已经应用完了所有的IO线程写入的Event
if(IO thread is running)
//如果IO线程启动了
print0; //设置延迟为 0
else
printNULL; //否则为空值
else
compute Seconds_Behind_Master;
//如果SQL线程没有应用完所有的IO线程写入的Event,那么需要计算延迟。
else
printNULL; //如果连SQL线程也没有启动则设置为空值
*/
计算延迟的公式为:服务器当前时间-Event header中的timestamp - 主从服务器时间差
long time_diff= ((long)(time( 0)-last_master_timestamp)-clock_diff_with_master);
如果SQL线程没有应用完了所有的IO线程写入的Event,也就是Read_Master_Log_Pos和Exec_Master_Log_Pos存在一定的差值。判定标准为:
(get_master_log_pos -get_group_master_log_pos) &&(get_master_log_name-get_group_master_log_name))
也就是通过 IO线程读取到主库binary log的位置(Read_Master_Log_Pos) 和 SQL线程应用到的主库binary log位置进行比较来进行判断,只要他们出现差值就会进入延迟计算环节。也就是:服务器当前时间-Event header中的timestamp - 主从服务器时间差 这个公式必然出现了偏差。如果主库的压力越大出现这种情况的可能性就会越大,因为IO线程和SQL线程在处理Read_Master_Log_Pos和Exec_Master_Log_Pos的出现时间差的可能性就会越大。
三、处理
3.1、手动执行同步+忽略错误(在业务不保证数据强一致性的情况下,可以选择忽略)
1)先进入主库,进行锁表,防止数据写入
mysql> flush tables with read lock;
mysql> show master status
2)数据导出备份然后倒入从库
mysqldump -uroot -p --lock-all-tables --flush-logs db_name > /data/master.sql
3)登录从库停止slave从节点
stop slave;
4)倒入数据
mysql -u root -p db_name < /temp/master.sql
或mysql> source /temp/master.sql
5)配置重新主从同步
5.7及之后版本
mysql> update mysql.user set authentication_string = password (‘Password4’) where user = ‘testuser’ and host = ‘%’;
Query OK, 1 row affected, 1 warning (0.06 sec)
Rows matched: 1 Changed: 1 Warnings: 1
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
#5.6及之前版本
update mysql.user set password=password(‘新密码’) where user=‘用户名’ and host=‘host’;
mysql> change master to master_host=‘172.18.1.20’, master_port=3306, master_user=‘repl’,master_password=‘123456’, master_log_file=‘mysql-bin.000031’,master_log_pos=932;
6)开启slave
start slave;
7)查看slave状态
show slave status\\G //正常输出如下
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
……
Seconds_Behind_Master:0
8)如果一段时间后,出现了报错,停止slave:
set global sql_slave_skip_counter =1; #这个参数只是针对传统复制有效,针对GTID复制只能使用gtid_next.
9)start slave再次验证,重复几次,把所有错误忽略掉;
3.2、手动执行同步+手动更正
前7步同上;
通过第7步的报错位置,在主库执行:
mysqlbinlog -v --stop-position=xxx ./data/master-bin.xxx > ./binlog.update
cat ./binlog.update |awk ‘/end_log_pos xxx/ print NR’
根据上面的NR行数,查看附近的行,定位数据不一致的地方,后续手动补全
cat ./binlog.update |awk ‘NRxxx-50,NRxxx+50’|grep -i update -A 200|grep xxxx -B 200|less
找到数据位置,@1表第一个字段值;其中@1 @2 @3…分别对应表的列名
或:
比如,报错位置 end_log_pos 440267874。可利用mysqlbinlog工具找出440267874的事件
/usr/local/mysql-5.6.30/bin/mysqlbinlog --base64-output=decode-rows -vv mysql-bin.000003 |grep -A 20 ‘440267874’
或者/usr/local/mysql-5.6.30/bin/mysqlbinlog --base64-output=decode-rows -vv mysql-bin.000003 --stop-position=440267874 | tail -20
或者usr/local/mysql-5.6.30/bin/mysqlbinlog --base64-output=decode-rows -vv mysql-bin.000003 > decode.log
主库创建临时表:
Create table xxl_job_temp like xxl_job_log_report;
将该段数据写入临时表导出导入到备库;
start slave;
show slave status\\G
结果说明:
Slave_IO_Running: 该参数可作为io_thread的监控项,Yes表示io_thread的和主库连接正常并能实施复制工作,No则说明与主库通讯异常,多数情况是由主从间网络引起的问题;
Slave_SQL_Running: 该参数代表sql_thread是否正常,具体就是语句是否执行通过,常会遇到主键重复或是某个表不存在。
Seconds_Behind_Master:是通过比较sql_thread执行的event的timestamp和io_thread复制好的event的timestamp(简写为ts)进行比较,而得到的这么一个差值;NULL—表示io_thread或是sql_thread有任何一个发生故障,也就是该线程的Running状态是No,而非Yes。0 — 该值为零,是我们极为渴望看到的情况,表示主从复制良好,可以认为lag不存在。正值 — 表示主从已经出现延时,数字越大表示从库落后主库越多。负值 — 几乎很少见,我只是听一些资深的DBA说见过,其实,这是一个BUG值,该参数是不支持负值的,也就是不应该出现。
其他:增大从库innodb_buffer_pool_size,让更多操作在Mysgl内存中完成,减少磁盘操作,减少延迟;
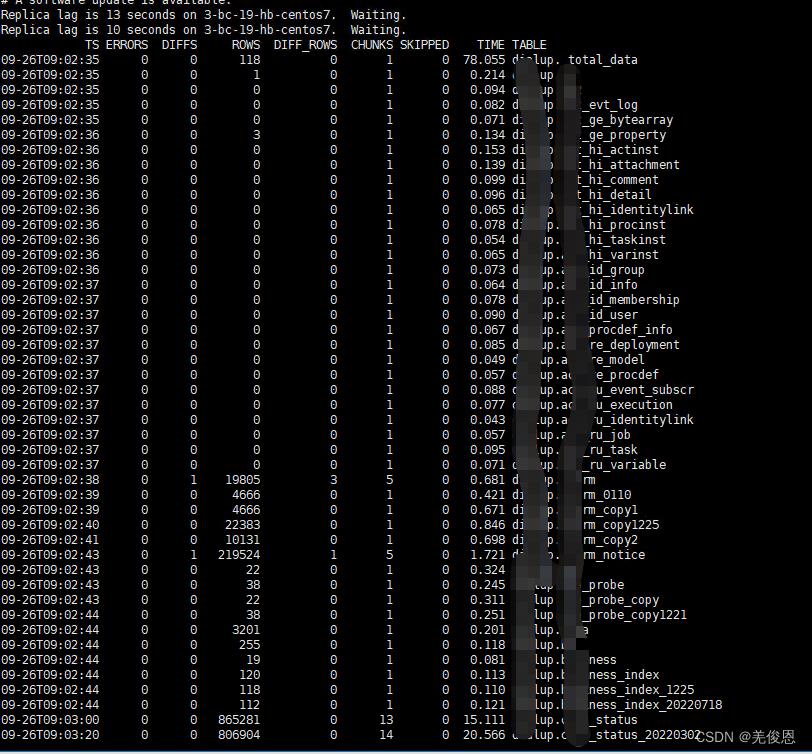
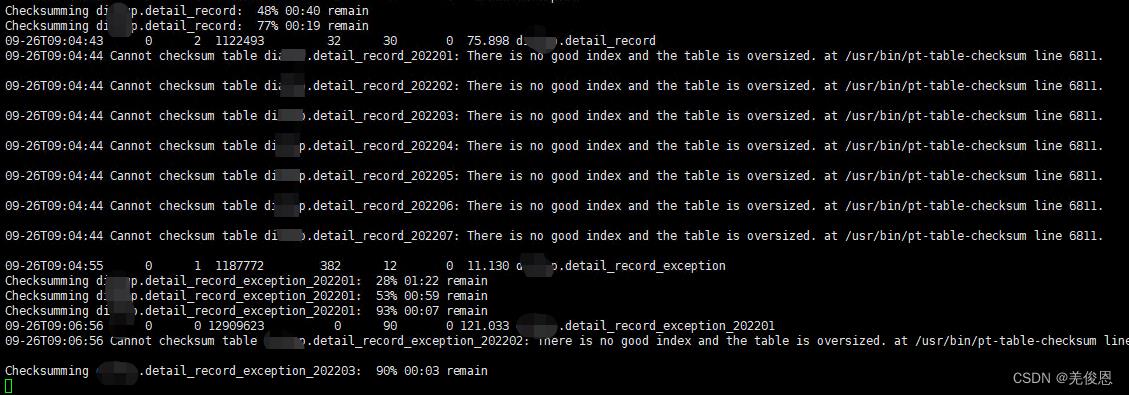
四、第三方工具pt-table-sync来辅助实现

Percona Toolkit是mysql运维的一组命令的集合, 是 Percona 支持人员用来执行各种 MySQL、MongoDB 和系统任务的高级命令行工具集,它们是完全独立的,不依赖与特定的库,因此安装也很简单;该工具中最主要的三个组件分别是:
| 项目 | Value |
|---|---|
| pt-table-checksum | 负责监测mysql主从数据一致性 |
| pt-table-sync | 负责当主从数据不一致时修复数据,让它们保存数据的一致性 |
| pt-heartbeat | 负责监控mysql主从同步延迟 |
官网:https://docs.percona.com/percona-toolkit/index.html
文档:https://docs.percona.com/percona-toolkit/installation.html
下载:https://www.percona.com/downloads/percona-toolkit/LATEST/
1)安装前准备
#percona-toolkit的yum仓库
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm -y
#MYSQL的yum仓库
yum install -y https://repo.mysql.com//mysql80-community-release-el7-3.noarch.rpm
yum install percona-release-0.1-6.noarch.rpm
yum list | grep mysql | grep libs-compat
mysql-community-libs-compat.i686 5.7.30-1.el7 mysql57-community
mysql-community-libs-compat.x86_64 5.7.30-1.el7 mysql57-community
yum -y install mysql-community-libs-compat.x86_64
#安装依赖
yum install perl perl-DBI perl-DBD-MySQL perl-IO-Socket-SSL perl-Time-HiRes perl-Digest-MD5 perl-ExtUtils-MakeMaker -y
#下载
wget https://www.percona.com/redir/downloads/percona-release/redhat/0.1-6/percona-release-0.1-6.noarch.rpm
2)安装
sudo yum install percona-toolkit //直接
yum list | grep percona-toolkit
#离线编译安装,下载工具集
#wget https://www.percona.com/downloads/percona-toolkit/2.2.18/tarball/percona-toolkit-2.2.18.tar.gz
#https://downloads.percona.com/downloads/percona-toolkit/2.2.1/deb/percona-toolkit_2.2.1-2.tar.gz
wget https://downloads.percona.com/downloads/percona-toolkit/3.1.0/binary/tarball/percona-toolkit-3.1.0_x86_64.tar.gz
#https://downloads.percona.com/downloads/percona-toolkit/3.2.0/binary/tarball/percona-toolkit-3.2.0_x86_64.tar.gz
#https://downloads.percona.com/downloads/percona-toolkit/3.3.0/binary/tarball/percona-toolkit-3.3.0_x86_64.tar.gz
#https://downloads.percona.com/downloads/percona-toolkit/3.4.0/binary/tarball/percona-toolkit-3.4.0_x86_64.tar.gz
#解压缩
tar -xzf percona-toolkit-3.2.0_x86_64.tar.gz
#进入目录
cd percona-toolkit-3.2.0/
bin CONTRIBUTE.md COPYING docs Gopkg.toml lib MANIFEST run-tests.sh
Changelog CONTRIBUTING.md docker-compose.yml Gopkg.lock INSTALL Makefile.PL README.md runtests.s
#执行perl脚本
perl Makefile.PL
Checking if your kit is complete...
Looks good
Writing Makefile for percona-toolkit
#编译
make
#安装
make install
……
Installing /usr/local/bin/pt-duplicate-key-checker
Installing /usr/local/bin/pt-config-diff
Installing /usr/local/bin/pt-stalk
Appending installation info to /usr/lib64/perl5/perllocal.pod
#验证
pt-table-checksum --version //现场版本3.2.0,输出如下
pt-table-checksum 3.2.0
pt-query-digest --version //输出如下
pt-query-digest 3.2.0

3)配置使用
#主库授权,从库也验证下
mysql> grant select,process,super,replication slave,create,delete,insert,update on *.* to 'repl'@'%' identified by '123456';
# 主库执行命令,检查主从数据一致性;通过pt-table-checksum命令来进行检测,注意检测时需要指定一个表(表名可自定义),这个表用来记录差异点 为后续同步数据作为参考
//对现有只读用户授权
mysql> update user set authentication_string = PASSWORD('123456') where user = 'cmcc' AND host = 'localhost';
mysql> GRANT SELECT, PROCESS, SUPER, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'cmcc'@'172.18.1.19';
mysql> GRANT ALL PRIVILEGES ON `percona`.* TO 'cmcc'@'172.18.1.19';
mysql> revoke all on *.* from cmcc@localhost;
mysql> flush privileges;
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --replicate=test.checksums --create-replicate-table --databases=mysql h=172.18.1.19,u=repl,p='123456',P=3306
#参数说明
--nocheck-replication-filters :不检查复制过滤器,建议启用,这样我们可以自定义检查哪个数据库的数据,否则将会检查mysql所有被同步的数据库。
--no-check-binlog-format : 不检查复制的binlog模式,pt-table-checksum默认是运行在statement下,如果是其它日志格式,需加--no-check-binlog-format参数;要是binlog模式是ROW,则会报错
--replicate-check-only :只显示不同步的信息,根据情况可加可不加,不加就会显示全部表的信息。
--replicate= :把checksum的信息写入到指定表中,建议直接写到被检查的数据库当中。
--databases= :指定需要被检查的数据库,多个则用逗号隔开,建议一个一个检查。
--tables= :指定需要被检查的表,多个用逗号隔开
--host= :Master的地址
--user= :用户名,也可以使用root用户,或者自己创建用户赋予查询,修改,删除,同步权限,注意数据库权限也要赋予
ldconfig -p | grep mysql
libmysqlclient.so.20 (libc6,x86-64) => /usr/lib64/mysql/libmysqlclient.so.20
libmysqlclient.so.18 (libc6,x86-64) => /usr/lib64/mysql/libmysqlclient.so.18
libmysqlclient.so (libc6,x86-64) => /usr/lib64/mysql/libmysqlclient.so

pt-slave-restart工具的作用是监视某些特定的复制错误,然后忽略,并且再次启动SLAVE进程(Watch and restart MySQL replication after errors)。忽略所有1062错误,并再次启动SLAVE进程:
pt-slave-resetart -S /var/lib/mysql/mysql.sock —error-numbers=1062
pt-slave-resetart -S /var/lib/mysql/mysql.sock —error-text=”test.t1” //检查到错误信息只要包含 test.t1,就一概忽略,并再次启动 SLAVE 进程
五、附录及FAQ
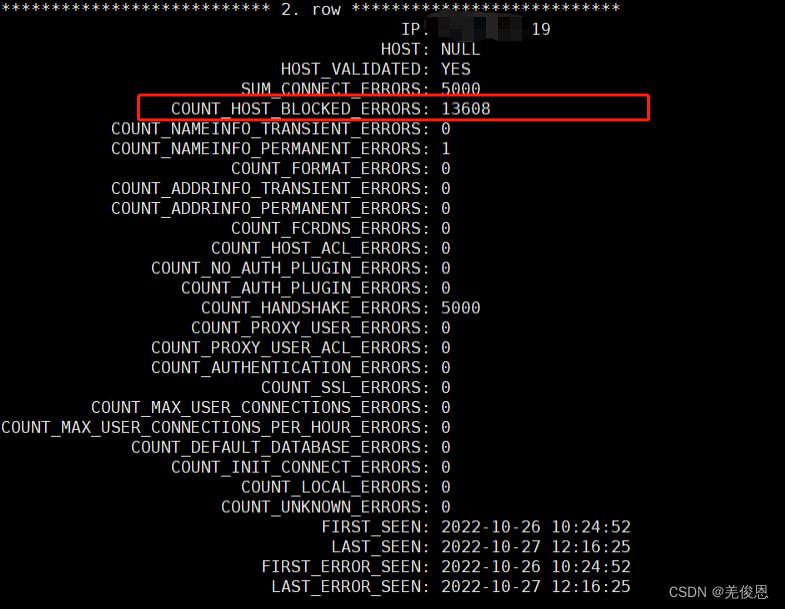
5.1 主从同步报无法连接数据库,测试报:Host is blocked because of many connection errors
原因:
当同一个ip在短时间内产生太多(超过数据库max_connection_errors的最大值)中断的数据库连接而导致的阻塞;当slave与master出现未正常连接时,master后续新提交的事务无法在后续主从连接同步给slave,即master如果想删除了数据,同步到slave,而slave没有这条数据,也就无法完成同步删除操作,两边不一致,这就会导致slave_sql_running停止运行,状态显示NO;
If more than this many successive connection requests from a host are interrupted without a successful connection, the server blocks that host from further connections. You can unblock blocked hosts by flushing the host cache. To do so, issue a FLUSH HOSTS statement or execute a mysqladmin flush-hosts command. If a connection is established successfully within fewer than max_connect_errors attempts after a previous connection was interrupted, the error count for the host is cleared to zero. However, once a host is blocked, flushing the host cache is the only way to unblock it. The default is 100.
There seems to be confusion around that variable. It does not really block hosts for repeated invalid passwords but for aborted connections due to network errors.(不是密码错误导致的,一般是因网络问题导致连接重复尝试失败导致的)
某个IP输入了错误密码,MySQL会在performance_schema数据库下的host_cache表中记录。它会累计记录在COUNT_AUTHENTICATION_ERRORS字段;host_cache表中的SUM_CONNECT_ERRORS字段是统计被视为“阻塞”的连接错误的数量(根据max_connect_errors系统变量进行评估)。 只计算协议握手错误,并且仅用于通过验证的主机(HOST_VALIDATED = YES);MySQL客户端与数据库建立连接需要发起三次握手协议,正常情况下,这个时间非常短,但是一旦网络异常,网络超时等因素出现,就会导致这个握手协议无法完成,MySQL有个参数connect_timeout,它是MySQL服务端进程mysqld等待连接建立完成的时间,单位为秒。如果超过connect_timeout时间范围内,仍然无法完成协议握手话,MySQL客户端会收到异常,异常消息类似于: Lost connection to MySQL server at ‘XXX’, system error: errno,该变量默认是10秒;失败会导致在MySQL服务器上查询host_cache表时,那么你就会看到SUM_CONNECT_ERRORS自增1了,COUNT_HANDSHAKE_ERRORS也会自增1
host_cache表说明:The MySQL server maintains a host cache in memory that contains information about clients: IP address, host name, and error information. The server uses this cache for nonlocal TCP connections. It does not use the cache for TCP connections established using a loopback interface address (127.0.0.1 or ::1), or for connections established using a Unix socket file, named pipe, or shared memory.(将非本地TCP连接信息缓存起来)

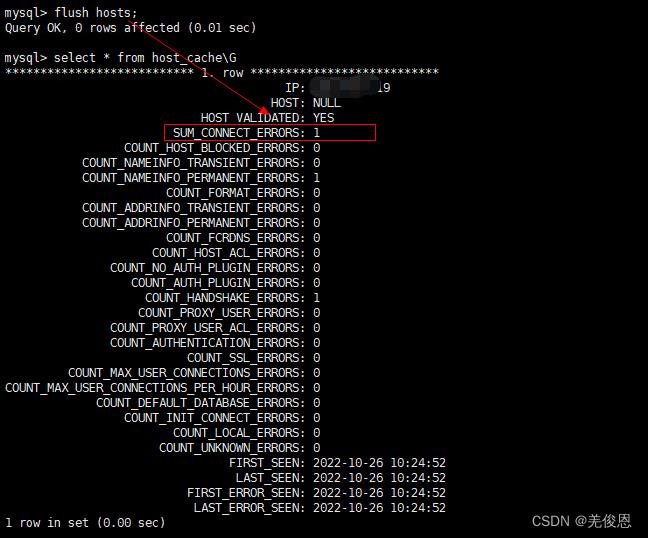
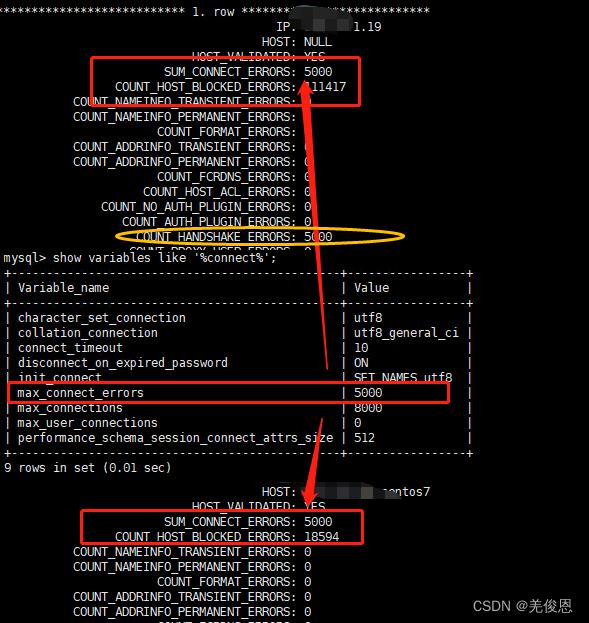
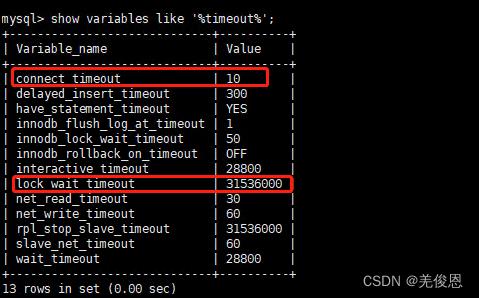
相关经验表明:当connet_timeout 配置不恰当,会导致某些时候查询大表时,报错:Lost connection to MySQL server at ‘xx.xxx.xx.xxx:3306’,这是我们可以调整connet_timeout :SET GLOBAL wait_timeout=15000;connect_timeout指的是连接过程中握手的超时时间,官方文档显示在5.0.52以后默认为10秒,之前版本默认是5秒。
mysql有个监听线程循环接收请求,当有请求来时,创建线程(或者从线程池中取)来处理这个请求。由于mysql连接采用TCP协议,那么之前势必是需要进行TCP三次握手的。TCP三次握手成功之后,客户端会进入阻塞,等待服务端的消息。服务端这个时候会创建一个线程(或者从线程池中取一个线程)来处理请求,主要验证部分包括host和用户名密码验证。host验证我们比较熟悉,因为在用grant命令授权用户的时候是有指定host的。用户名密码认证则是服务端先生成一个随机数发送给客户端,客户端用该随机数和密码进行多次sha1加密后发送给服务端验证。如果通过,整个连接握手过程完成。
mysql数据库有⼀个wait_timeout的配置,默认值为28800(即8⼩时);如果连续8⼩时内都没有访问数据库的操作,再次访问mysql数据库的时候,mysql数据库会拒绝访问,闲置连接的超时时间由wait_timeout控制。下面是关于数据量连接驱动中关于connection_timeout的设定,可以看到 connet_timeout 会直接把客户端 socket 对象的超时时间给改了,这也就是一旦超时 tcp 连接就断了的原因:
# 其一
self._connection_timeout = DEFAULT_CONFIGURATION["connect_timeout"]
# 其二
try:
self.sock = socket.socket(self._family, socktype, proto)
self.sock.settimeout(self._connection_timeout)
self.sock.connect(sockaddr)
except IOError as err:
... ...
except Exception as err:
raise errors.OperationalError(str(err))
现场配置如下:show global variables like ‘%timeout%’;
处理办法:
将变量max_connection_errors的值设置为一个更大的值;但这只是个临时方案,只是延迟了触发IP被禁止访问的条件而已,而且在复杂情况或高并发的情况下,需要设置一个很大的值,否则很容易就会再次被触发。另外,变量只对当前环境生效,如果重启就会失效,如果需要永久有效,需要在my.cnf配置文件里面配置:max_connect_errors=10000;或mysqld_safe --max_connect_errors=10000 &
mysql> flush hosts;
或 mysqladmin -uroot -pmysql flush-host极端:将变量host_cache_size设置为0,生产环境禁止操作
show variables like ‘%host_cache_size%’;
set global host_cache_size=0;
select * from performance_schema.host_cache;设置connect_timeout
设置全局变量connect_timeout为12小时(12*3600=43200)
set global connect_timeout=43200
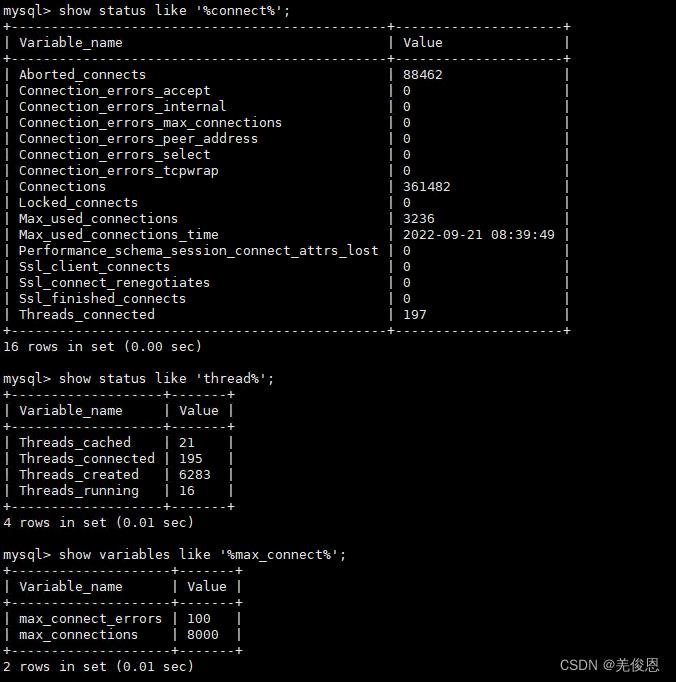
#检查当前连接数情况:
show status like '%connect%';
#重置连接错误数
flush hosts;
#设置最大连接错误数
set global max_connect_errors = 1000;
#查看最大连接错误数
show variables like 'max_connect_errors';
mysql> select @@global.max_connect_errors;
#主从同步一致性跳过错误重新同步
mysql> stop slave;
mysql> set global sql_slave_skip_counter=1; #跳过当前错误
mysql> start slave;
#如果错误数太多,主从不一致,从库执行如下,尝试重新同步,逐步加大数字
#This statement skips the next N events from the master. This is useful for recovering from replication stops caused by a statement.
mysql> set global sql_slave_skip_counter=N #这里的N是指跳过N个event
#验证
mysql> show slave status\\G;
#如果数据量不大,一致性要求较高,手动锁定主库,从新的位置让slave重新同步
mysql> set global read_only=on/off
mysql> CHANGE MASTER TO MASTER_HOST='172.28.2.20',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000305',
MASTER_LOG_POS=3303782;
#查看语句记录功能开启状态
mysql> select * from performance_schema.setup_consumers where name like 'events_statements%';
#结果中指标意义如下
events_statements_current ## 默认只记录每个线程最近的一条SQL信息
events_statements_history ## 默认记录每个线程最近的十条SQL信息
events_statements_history_long ## 默认记录每个线程最近的10000条SQL信息
#开启语句记录
mysql> update performance_schema.setup_consumers set enabled = 'YES' where name in ('events_statements_history','events_statements_history_long');
#根据slave上错误号查找详情
mysql> select * from performance_schema.events_statements_history_long where mysql_errno=1062\\G;
#查看binlog位置信息;其中:IN 'log_name' 指定要查询的binlog文件名(不指定就是第一个binlog文件)
#FROM pos 指定从哪个pos起始点开始查起(不指定就是从整个文件首个pos点开始算)
#LIMIT [offset,] 偏移量(不指定就是0)
#row_count 查询总条数(不指定就是所有行)
#log_name, pos 可从slave上报错信息获取
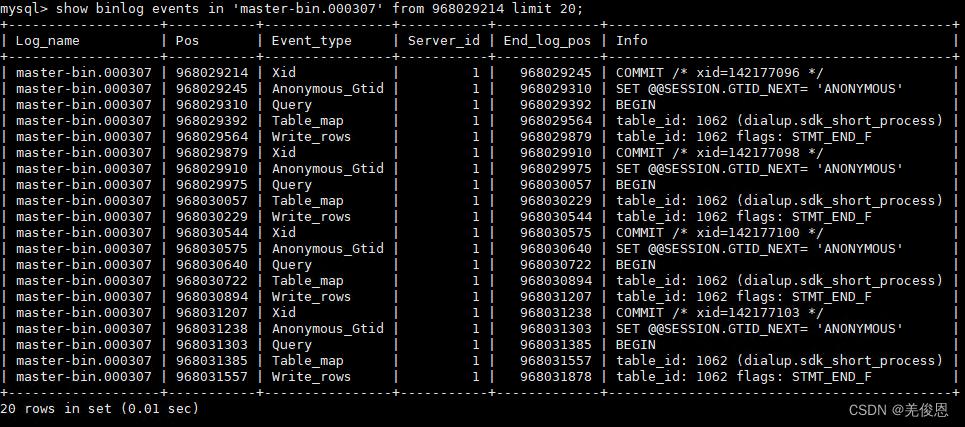
mysql> show binlog events [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count];
mysql> show binlog events IN 'master-bin.000307' FROM 968029214 LIMIT 20;
#当前也可以编辑slave配置文件来跳过报错
vi /etc/my.cnf //如下
[mysqld]
slave-skip-errors=1062,1053,1146 #跳过指定error no类型的错误
slave-skip-errors=all #跳过所有错误
#对于采用GTID协议主从复制时,当报错某位置(比如33)上发生错误,手动调整SLAVE已清除的GTID列表 GTID_PURGED,通知SLAVE哪些事务已经被清除了,如下处理:
mysql> STOP SLAVE;
mysql> RESET MASTER;
mysql> SET @@GLOBAL.GTID_PURGED = “3a16ef7a-75f5-11e4-8960-deadeb54b599:1-283,f2b6c829-9c87-11e4-84e8-deadeb54b599:1-33”; //跳过/忽略33这个错误
mysql> START SLAVE;
//注意:在GTID主从的建立初期,slave的数据一定要是从master mysqldump过去的并且更加--all-databases参数。否则手动补齐的数据会出现slave_sql_running为NO的情况,这是因为主的操作记录会保存在GTID与binlog中,然后slave会同步主的GTID与binlog并进行相应的操作,这时两边的数据虽然是一致的,但是同步过来master的GTID中包含了主做过的一些sql操作,而此时slave的环境不满足sql语句的执行就会冲突。
//解决办法是:
//1.)不断的执行跳过事务的操作直到没有报错。
//2.)刷新master的GTID“reset master”然后重新再slave执行change同步。
//master确认已经purge的部分,stop slave,在slave上通过set global gtid_purged='xxxx'的方式,跳过已经purge的部分;注意开启主从复制之后,就不可以在从的上面进行操作,否则会出现slave_sql_running为NO的提示
mysql> show global variables like '%gtid%';
更多参看官网关于host_cache说明。附录:
show status like '%hand%'; #分析一个SQL的性能好坏时,除了执行计划,另外一个常看的指标是"Handler_read_*"相关变量。
flush status #重置大多数状态变量到0


其中:
Handler_read_key基于索引来定位记录,该值越大,代表基于索引的查询越多;. 无论是基于主键,还是二级索引进行等值查询,Handler_read_key都会加1。对于二级索引,如果返回了N条记录,Handler_read_next会相应加N。
Handler_read_first:读取索引的第一个值,该值越大,代表涉及索引全扫描的查询越多。但是,这并不意味着查询利用到了索引,还需要结合其它的Handler_read_xxx来分析。
Handler_read_last:和Handler_read_first相反,是读取索引的最后一个值。该值增加基本上可以判定查询中使用了基于索引的order by desc子句。
Handler_read_next:根据索引的顺序来读取下一行的值,常用于基于索引的范围扫描和order by limit子句中。
Handler_read_prev:根据索引的顺序来读取上一行的值。一般用于基于索引的order by desc子句中。
Handler_read_rnd:基于固定位置来读取记录。对记录基于某种标准进行排序,然后再根据它们的位置信息来遍历排序后的结果,这往往会导致表的随机读。
Handler_read_rnd_next:读取下一行记录的次数,常用于全表扫描中。
5.2 MySQL的GTID主从 与 传统主从复制的区别
1)传统主从复制:
普通主从复制主要是基于二进制日志文件位置的复制,因此主必须启动二进制日志记录并建立唯一的服务器ID,复制组中的每个服务器都必须配置唯一的服务器ID。如果您省略server-id(或者明确地将其设置为其默认值0),则主设备将拒绝来自从设备的任何连接。
在传统的主从复制slave端,binlog是不用开启的,但是在GTID中slave端的binlog是必须开启的,目的是记录执行过的GTID(强制)。
传统一主多从(mysql5.6之前)的模型中当master down掉后,我们不只是需要将一个slave提成master就可以,还要将其他slave的同步目的地从以前的master改成现在master,而且bin-log的序号和偏移量也要去查看,这是十分不方便和耗时的,但mysql5.6引入gtid之后解决了这个问题。
2) GTID (Global Transaction ID)主从: 主从复制更简单,一致性更可靠
从MySQL 5.6.5 开始新增了一种基于 GTID 的复制方式。全局事务标识符(GTID)是MySQL 5.6 的新特性之一,它会创建唯一标识符,并与在源(主)服务器上与提交的每个事务相关联。此标识符的唯一是在复制组中所有服务器上都是唯一的。所有交易和所有GTID之间都有一对一的映射关系 。它由服务器ID以及事务ID组合而成。这个全局事务ID不仅仅在原始服务器上唯一,在所有存在主从关系 的mysql服务器上也是唯一的。正是因为这样一个特性使得mysql的主从复制变得更加简单,以及数据库一致性更可靠。一个GTID在一个服务器上只执行一次,避免重复执行导致数据混乱或者主从不一致。
一个GTID被表示为一对坐标,用冒号(:)分隔,如下所示:GTID = source_id:transaction_id,source_id标识的源服务器。通常情况下,服务器 server_uuid用于这个目的。这transaction_id是一个序列号,由在此服务器上提交事务的顺序决定 。当在主库上提交事务或者被从库应用时,可以定位和追踪每一个事务,从而无需手工去定位偏移量的值了,而是通过CHANGE MASTER TO MASTER_HOST=‘xxx’, MASTER_AUTO_POSITION=1;即可方便的搭建从库,在故障修复中也可以采用MASTER_AUTO_POSITION=‘X’的方式。
总之,通过 GTID 保证了每个在主库上提交的事务在集群中有一个唯一的ID。这种方式强化了数据库的主备一致性,故障恢复以及容错能力。更多参看官网
GTID = server_uuid:transaction_id //GTID实际上是由UUID+TID组成的
注意: 其中UUID是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。server_uuid 一般是发起事务的uuid, 标识了该事务执行的源节点,存储在数据目录中的auto.cnf文件中,transaction_id 是在该主库上生成的事务序列号,从1开始,1-2代表第二个事务;第1-n代表n个事务。
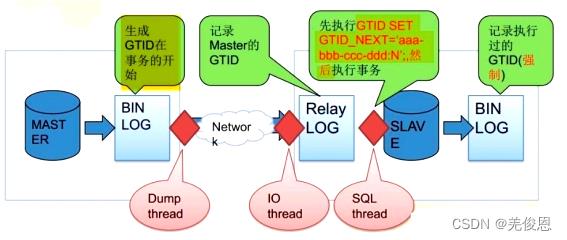
- 当一个事务在主库端执行并提交时,产生 GTID,一同记录到 binlog 日志中。
- binlog 传输到 slave,并存储到 slave 的 relaylog 后,读取这个 GTID 的这个值设置 gtid_next 变量,即告诉 Slave,下一个要执行的 GTID 值。
- sql 线程从 relay log 中获取 GTID,然后对比 slave 端的 binlog 是否有该 GTID。
- 如果有记录,说明该 GTID 的事务已经执行,slave 会忽略。
- 如果没有记录,slave 就会执行该 GTID 事务,并记录该 GTID 到自身的 binlog;其中,IO thread 决定了Retrieved_Gtid_Set;SQL thread 决定了Executed_Gtid_Set;负责获取master上的binary log, 然后多个sql threads负责执行。由于IO thread先于SQL thread;
- 在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描。下图为GTID生命周期:
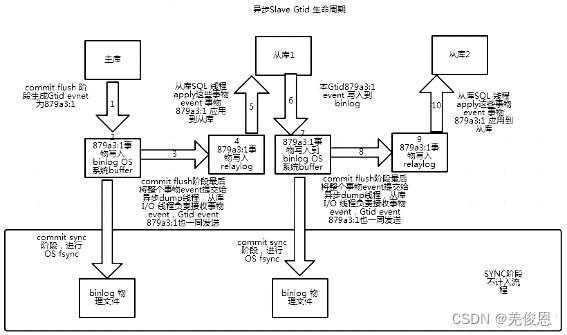
在主从复制中,尤其是半同步复制中, 由于Master 的dump进程一边要发送binlog给Slave,一边要等待Slave的ACK消息,这个过程是串行的,即前一个事物的ACK没有收到消息,那么后一个事物只能排队候着; 这样将会极大地影响性能;有了GTID后,SLAVE就直接可以通过数据流获得GTID信息,而且可以同步;
另外,主从故障切换中,如果一台MASTER down,需要提取拥有最新日志的SLAVE做MASTER,这个是很好判断,而有了GTID,就只要以GTID为准即可方便判断;而有了GTID后,SLAVE就不需要一直保存这bin-log 的文件名和Position了;只要启用MASTER_AUTO_POSITION即可。当MASTER crash的时候,GTID有助于保证数据一致性,因为每个事物都对应唯一GTID,如果在恢复的时候某事物被重复提交,SLAVE会直接忽略;因GTID因为是全局唯一,所以适合用于分布式环境中,很容易识别。
GTID的优点:
- 根据 GTID 可以快速的确定事务最初是在哪个实例上提交的。
- 实现 failover更简单,无需再找 log_file 和 log_pos了。
- 主从复制搭建更简单,确保了每个事务只会被执行一次。
- 比传统的复制更加安全,一个 GTID 在一个服务器上只执行一次,避免重复执行导致数据混乱或者主从不一致。
- GTID是连续的没有空洞的,保证数据的一致性,零丢失
- GTID 用来代替classic的复制方法,不再使用 binlog+pos 开启复制。而是使用 master_auto_postion=1 的方式自动匹配 GTID 断点进行复制。
- GTID 的引入,让每一个事务在集群事务的海洋中有了秩序,使得 在运维中做集群变更时更加方便。
GTID的缺点:
- 主从库的表存储引擎必须是一致的
主从库的表存储引擎不一致,就会导致数据不一致。如果主从库的存储引擎不一致,例如一个是事务存储引擎,一个是非事务存储引擎,则会导致事务和 GTID 之间一对一的关系被破坏,结果就会导致基于 GTID 的复制不能正确运行;
master:对一个innodb表做一个多sql更新的事物,效果是产生一个GTID。
slave:假设对应的表是MYISAM引擎,执行这个GTID的第一个语句后就会报错,因为非事务引擎一个sql就是一个事务。
当从库报错时简单的stop slave; start slave;就能够忽略错误。但是这个时候主从的一致性已经出现问题,需要手工的把slave差的数据补上,这里要将引擎调整为一样的,slave也改为事务引擎。
\\- 不允许一个SQL同时更新一个事务引擎和非事务引擎的表
事务中混合多个存储引擎,就会产生多个 GTID。当使用 GTID 时,如果在同一个事务中,更新包括了非事务引擎(如 MyISAM)和事务引擎(如 InnoDB)表的操作,就会导致多个 GTID 分配给了同一个事务。
\\- 在一个复制组中,必须要求统一开启GTID或是关闭GTID;
\\- 不支持create table….select 语句复制(主库直接报错);
create table xxx as select的语句,其实会被拆分为两部分,create语句和insert语句,但是如果想一次搞定,MySQL会抛出如下的错误。
ERROR 1786 (HY000): Statement violates GTID consistency: CREATE TABLE … SELECT.
create table xxx as select 的方式可以拆分成两部分,如下:
create table xxxx like data_mgr;
insert into xxxx select *from data_mgr;
\\- 对于create temporary table 和 drop temporary table语句不支持
使用GTID复制模式时,不支持create temporary table 和 drop temporary table。但是在autocommit=1的情况下可以创建临时表,Master端创建临时表不产生GTID信息,所以不会同步到slave,但是在删除临时表的时候会产生GTID会导致,主从中断.
\\- 不支持sql_slave_skip_counter.
mysql在主从复制时如果要跳过报错,可以采取以下方式跳过SQL(event)组成的事务,但GTID不支持以下方式。
set global SQL_SLAVE_SKIP_COUNTER=1;
start slave sql_thread;
配置参考:
#主master:
[mysqld]
#GTID主从:
server_id=1 #服务器id,与slave的server_id区分开来
gtid_mode=on #开启gtid模式
log_slave_updates ## 表示可以当从也可以当主
enforce_gtid_consistency=on #强制gtid一致性,开启后对于特定create table不被支持
#binlog
log_bin=master-binlog
#log-bin=/data/mysql/mysql-bin.log //binlog日志文件,(文件名如果是绝对路径,必须指定索引文件)
#log_bin_index =/var/lib/mysql/mysql-bin.index //是binlog文件的索引文件,这个文件管理了所有的binlog文件的目录
log-slave-updates=1
binlog_format=row #binlog日志格式,强烈建议,其他格式可能造成数据不一致
expire_logs_days=7 //binlog过期清理时间
#relay logskip_slave_start=1
#登录MySQL授权允许登录从库
mysql> GRANT REPLICATION SLAVE ON *.* TO repl@10.18.1.11 IDENTIFIED BY '123456';
mysql> flush privileges;
#从slave配置: 注意跟MASTER_AUTO_POSITION=1参数
##MASTER_AUTO_POSITION: (mysql5.6.5及其后续版本)进行change master to时使用MASTER_AUTO_POSITION = 1,slave连接master将使用基于GTID的复制协议。等于0则恢复到老的文件复制协议
CHANGE MASTER TO MASTER_HOST='10.18.1.12',MASTER_PORT=3306,MASTER_USER='repl',MASTER_PASSWORD='123456',MASTER_AUTO_POSITION=1;
#启动验证
mysql> start slave;
mysql> show slave status\\G;
#结果说明
Retrieved_Gtid_Set:aaa-bbb-ccc-ddd:N #表示收到的事务
Executed_Gtid_Set:aaa-bbb-ccc-ddd:N #表示已经执行完的事务
5.3 MySQL开启慢查询日志检查超时SQL
开启慢查询日志功能可能需要mysql的版本达到5.7(select VERSION();)下面是如何临时和永久开启慢查询。
show variables like 'slow_query%';
#超过多少秒才记录(才算是慢查询)
show variables like 'long_query%';
#临时开启
set global slow_query_log_file='/var/lib/mysql/tmp_slow.log';
set global long_query_time=1; //设置后需要打开一个新的查询窗口(会话)才能看到新设置的值。老的查询窗口还是显示之前的值,其实已经改了
set long_query_time=0; //设置慢日志触发查询时间阀值为0,这样任何查询都会写进去
set global log_output='FILE,TABLE'; //默认是FILE。如果也有TABLE,则同时输出到mysql库的slow_log表中。
set global slow_query_log='ON';
#永久开启(数据库服务重启后不失效),修改配置文件my.cnf,在[mysqld]下的下方加入
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/tmp_slow.log //linux
long_query_time = 1
#查看慢查询
mysqldumpslow -t 10 /var/lib/mysql/tmp_slow.log //显示出慢查询日志中最慢的10条sql
#如果mysql服务在docker容器里,可以这样执行查看
docker exec -i 79d3204efc6b mysqldumpslow -t 10 /var/lib/mysql/tmp_slow.log
//mysqldumpslow能将相同的慢SQL归类,并统计出相同的SQL执行的次数,每次执行耗时多久、总耗时,每次返回的行数、总行数,以及客户端连接信息等。
mysqldumpslow语法说明:
-s ,按照什么方式起来排序。默认at,也就是按照平均查询时间来排序。都是按照倒序排列。
al: average lock time 平均锁定时间
ar: average rows sent 平均返回行数
at: average query time 平均查询时间
c: count 总执行次数
l: lock time 总锁定时间
r: rows sent 总返回行数
t: query time 总查询时间
-t ,show the top n queries,显示前多少名的记录
-a ,默认不开启这个选项。mysqldumpslow将相似的SQL的值(字符串或者数字)替换为N,开启mysql5.6 主从不一致排错
环境:centos6.5 mysql 5.6
问题描述:今天早晨在从库中 show slave status,发现主从同步停止,因为着急排查问题,所以没来得及截图,但是错误日志还在,
1 在从库查看报错日志

在show slave status 中的报错和错误日志中的一致
根据报错内容,是说这条记录在从库中已经存在,不能再插入了,所以停止主从同步。
2 根据报错,到从库中查询是否真正存在这个记录,查询结果确实能看到这条记录
3 我没有按照网上说的方法跳过报错继续同步,而是比较野蛮的删除了从库中的这个记录,前提是我的从库没设置成只读
4 删除记录后,打算恢复主从同步
步骤是
1) stop slave
2) change master to master_host=‘X.X.X.X‘,master_user=‘X‘,master_password=‘X‘,master_log_file=‘mysql-bin.000078‘,master_log_pos=697694259; 注意,这里的 master_log_file 和 master_log_pos 要根据报错日志修改,目前我是这么认为的。
3) start slave
4) show slave status .到此发现主从已经又开始同步了
遗留问题
目前主从数据还有一定差距,还无法检查数据是否一致。
本文出自 “点滴积累” 博客,请务必保留此出处http://16769017.blog.51cto.com/700711/1867744
以上是关于MySQL主从不一致问题处理的主要内容,如果未能解决你的问题,请参考以下文章