MySQL进阶教程 索引使用与设计原则
Posted 小新要变强
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL进阶教程 索引使用与设计原则相关的知识,希望对你有一定的参考价值。
前言

本文为 【MySQL进阶教程】 索引使用与设计原则 相关知识,下边将对索引的使用(包括:验证索引效率,最左前缀法则,范围查询,索引失效情况,SQL提示,覆盖索引,前缀索引,单列索引与联合索引)与索引设计原则等进行详尽介绍~
📌博主主页:小新要变强 的主页
👉Java全栈学习路线可参考:【Java全栈学习路线】最全的Java学习路线及知识清单,Java自学方向指引,内含最全Java全栈学习技术清单~
👉算法刷题路线可参考:算法刷题路线总结与相关资料分享,内含最详尽的算法刷题路线指南及相关资料分享~
👉Java微服务开源项目可参考:企业级Java微服务开源项目(开源框架,用于学习、毕设、公司项目、私活等,减少开发工作,让您只关注业务!)

目录
文章标题

一、索引使用
1️⃣ 验证索引效率
在讲解索引的使用原则之前,先通过一个简单的案例,来验证一下索引,看看是否能够通过索引来提升数据查询性能。在演示的时候,我们还是使用之前准备的一张表 tb_sku , 在这张表中准备了1000w的记录。
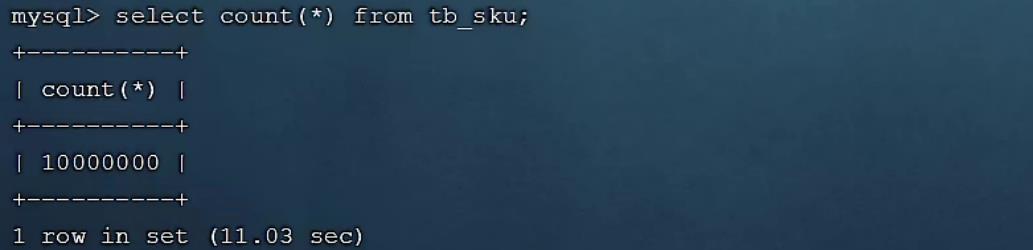
这张表中id为主键,有主键索引,而其他字段是没有建立索引的。 我们先来查询其中的一条记录,看
看里面的字段情况,执行如下SQL:
select * from tb_sku where id = 1\\G;
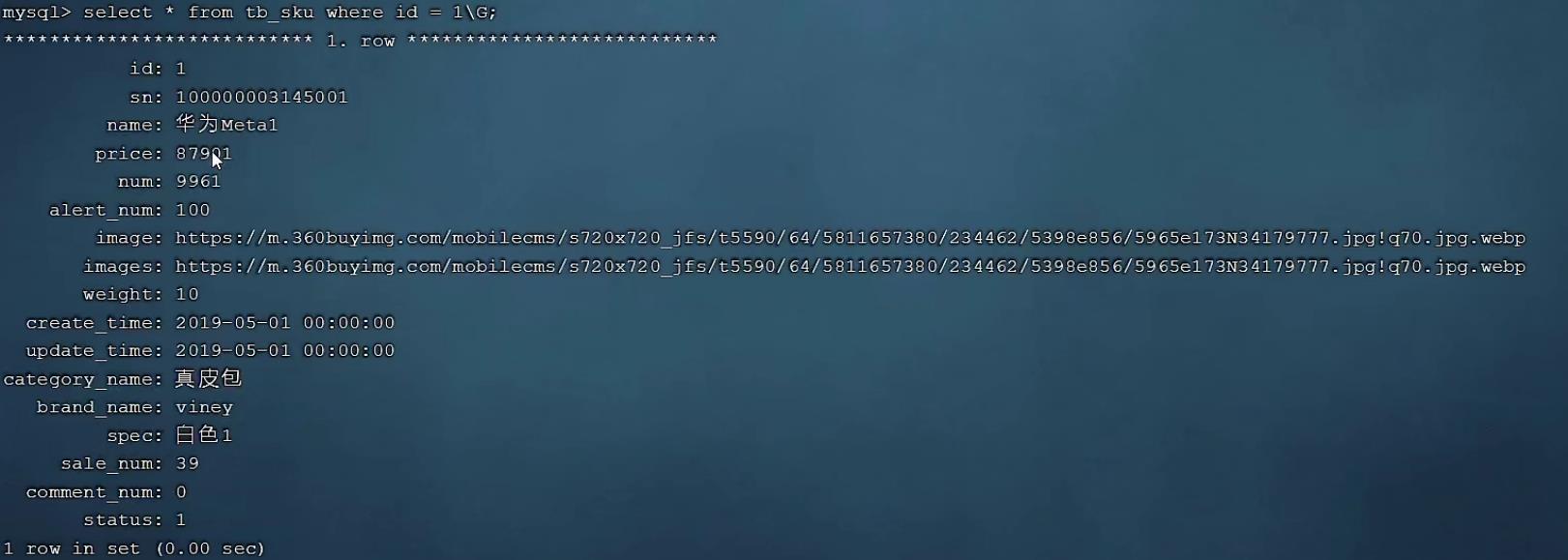
可以看到即使有1000w的数据,根据id进行数据查询,性能依然很快,因为主键id是有索引的。 那么接
下来,我们再来根据 sn 字段进行查询,执行如下SQL:
SELECT * FROM tb_sku WHERE sn = '100000003145001';
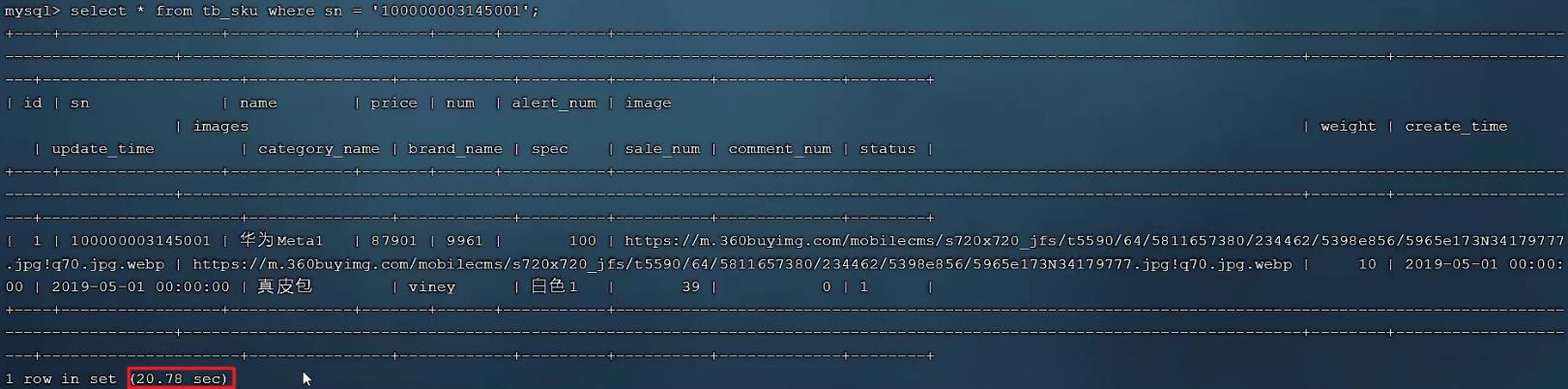
我们可以看到根据sn字段进行查询,查询返回了一条数据,结果耗时 20.78sec,就是因为sn没有索引,而造成查询效率很低。
那么我们可以针对于sn字段,建立一个索引,建立了索引之后,我们再次根据sn进行查询,再来看一下查询耗时情况。
创建索引:
create index idx_sku_sn on tb_sku(sn) ;

然后再次执行相同的SQL语句,再次查看SQL的耗时。
SELECT * FROM tb_sku WHERE sn = '100000003145001';
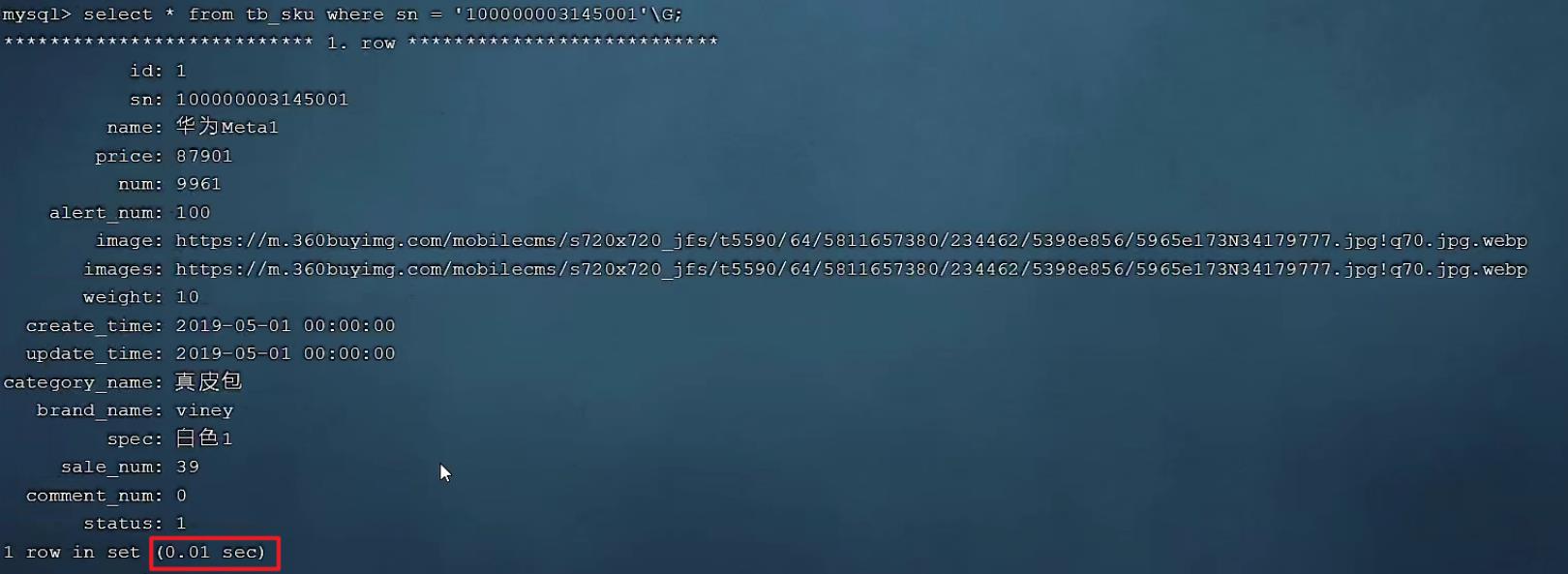
我们明显会看到,sn字段建立了索引之后,查询性能大大提升。建立索引前后,查询耗时都不是一个数量级的。
2️⃣最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)。
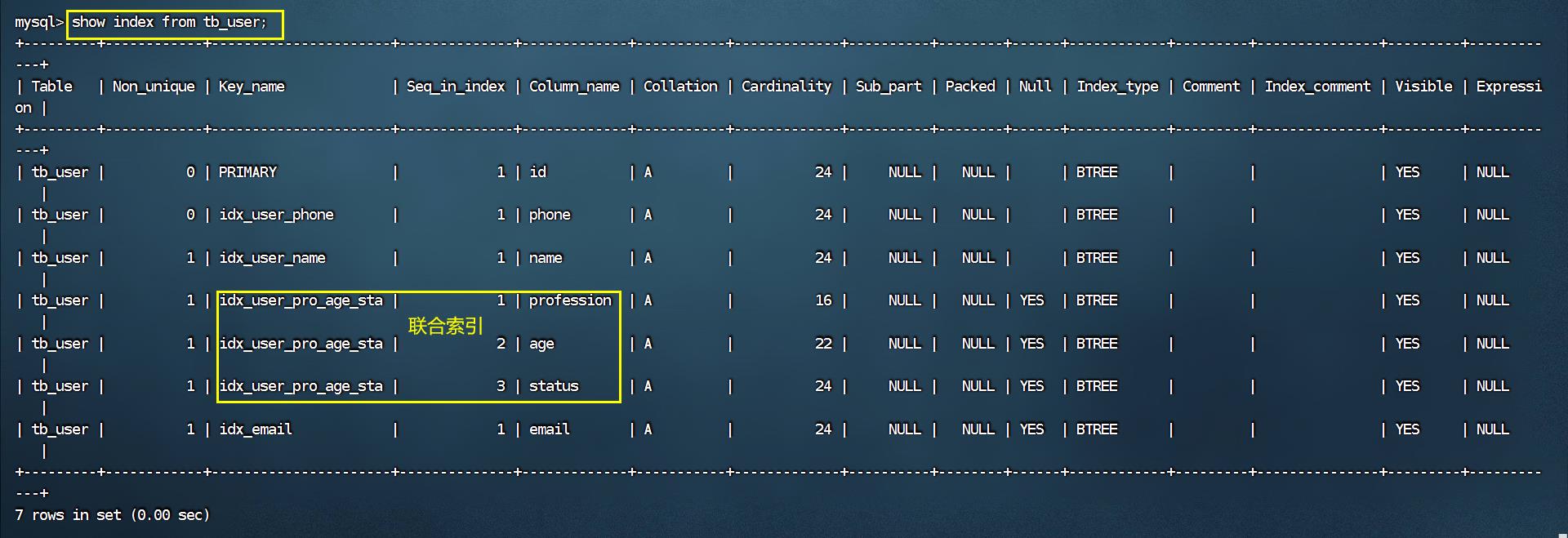
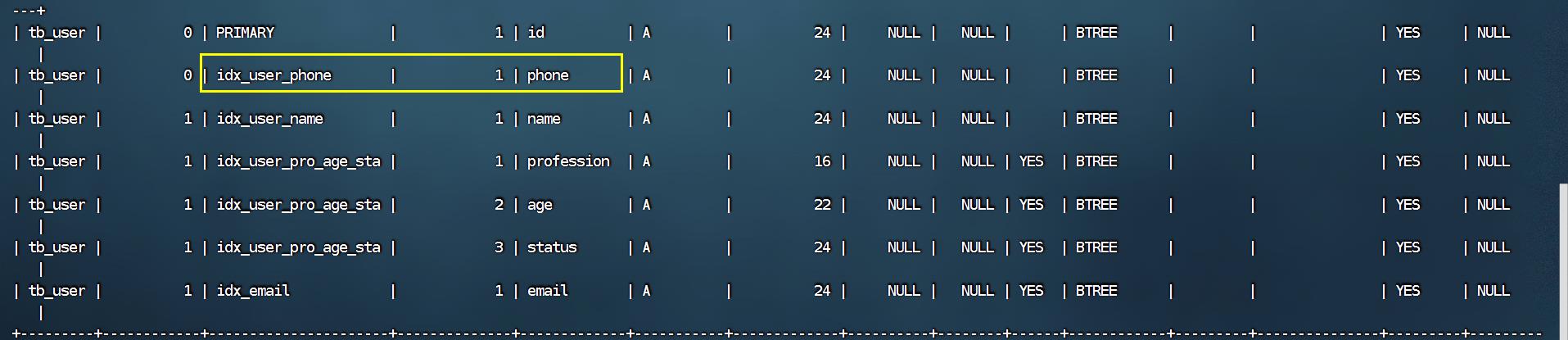
以 tb_user 表为例,我们先来查看一下之前 tb_user 表所创建的索引。

在 tb_user 表中,有一个联合索引,这个联合索引涉及到三个字段,顺序分别为:profession,age,status。
对于最左前缀法则指的是,查询时,最左变的列,也就是profession必须存在,否则索引全部失效。
而且中间不能跳过某一列,否则该列后面的字段索引将失效。 接下来,我们来演示几组案例,看一下具体的执行计划:
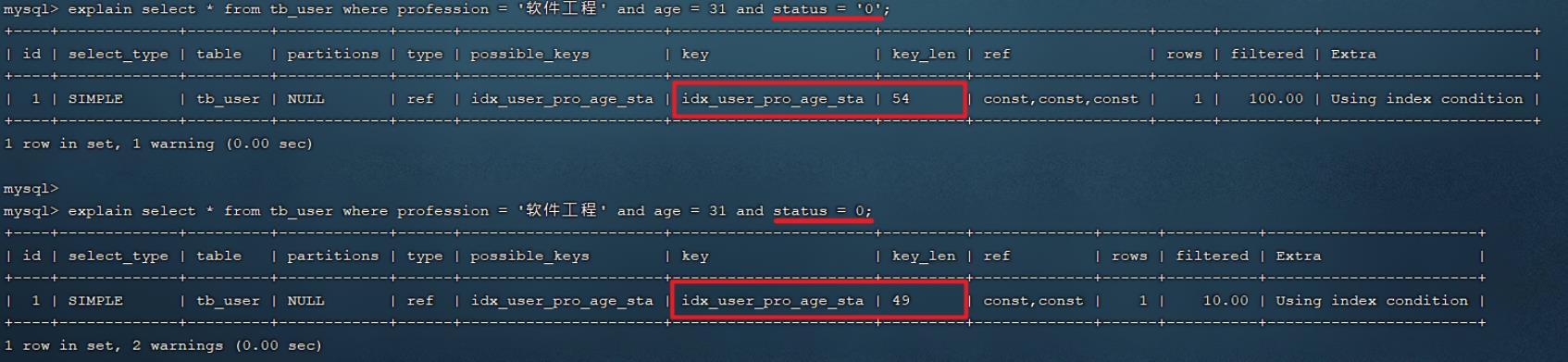
explain select * from tb_user where profession = '软件工程' and age = 31 and status
= '0';

explain select * from tb_user where profession = '软件工程' and age = 31;

explain select * from tb_user where profession = '软件工程';

以上的这三组测试中,我们发现只要联合索引最左边的字段 profession存在,索引就会生效,只不过索引的长度不同。 而且由以上三组测试,我们也可以推测出profession字段索引长度为47、age字段索引长度为2、status字段索引长度为5。
explain select * from tb_user where age = 31 and status = '0';

explain select * from tb_user where status = '0';

而通过上面的这两组测试,我们也可以看到索引并未生效,原因是因为不满足最左前缀法则,联合索引
最左边的列profession不存在。
explain select * from tb_user where profession = '软件工程' and status = '0';

上述的SQL查询时,存在profession字段,最左边的列是存在的,索引满足最左前缀法则的基本条件。但是查询时,跳过了age这个列,所以后面的列索引是不会使用的,也就是索引部分生效,所以索引的长度就是47。
3️⃣范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。
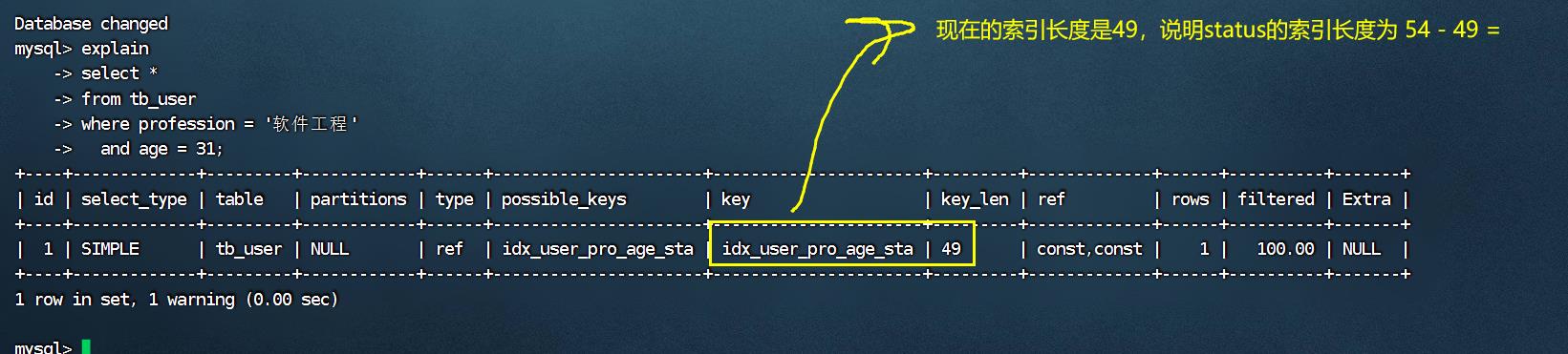
explain select * from tb_user where profession = '软件工程' and age > 30 and status = '0';

当范围查询使用> 或 < 时,走联合索引了,但是索引的长度为49,就说明范围查询右边的status字
段是没有走索引的。
explain select * from tb_user where profession = '软件工程' and age >= 30 and status = '0';

当范围查询使用>= 或 <= 时,走联合索引了,但是索引的长度为54,就说明所有的字段都是走索引的。
所以,在业务允许的情况下,尽可能的使用类似于 >= 或 <= 这类的范围查询,而避免使用 > 或 <。
4️⃣索引失效情况
🍀(1)索引列运算
不要在索引列上进行运算操作, 索引将失效。
在tb_user表中,除了前面介绍的联合索引之外,还有一个索引,是phone字段的单列索引。

A. 当根据phone字段进行等值匹配查询时, 索引生效。
explain select * from tb_user where phone = '17799990015';

B. 当根据phone字段进行函数运算操作之后,索引失效。
explain select * from tb_user where substring(phone,10,2) = '15';

🍀(2)字符串不加引号
字符串类型字段使用时,不加引号,索引将失效。
接下来,我们通过两组示例,来看看对于字符串类型的字段,加单引号与不加单引号的区别:
explain select * from tb_user where profession = '软件工程' and age = 31 and status = '0';
explain select * from tb_user where profession = '软件工程' and age = 31 and status = 0;
explain select * from tb_user where phone = '17799990015';
explain select * from tb_user where phone = 17799990015;
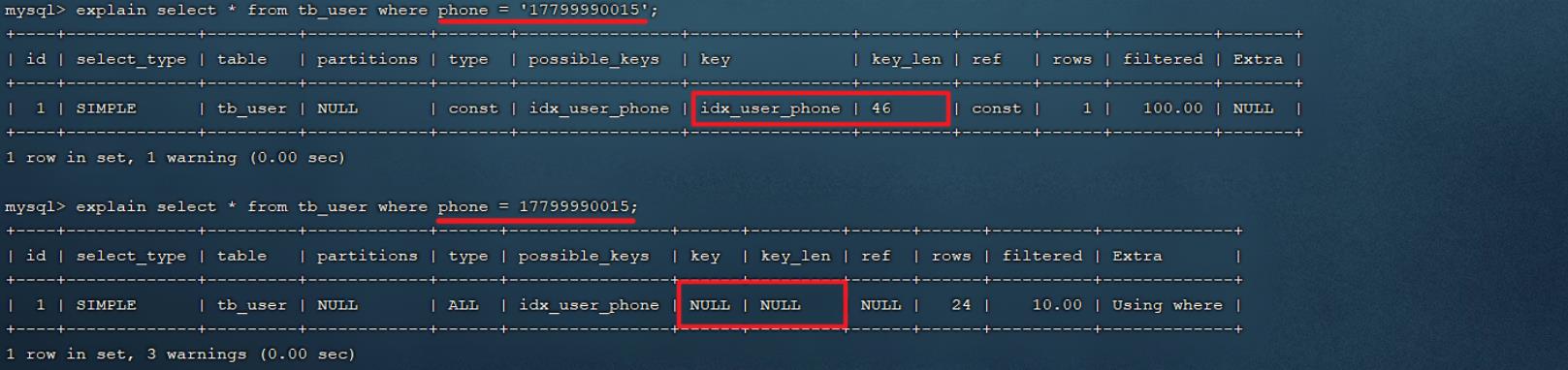
经过上面两组示例,我们会明显的发现,如果字符串不加单引号,对于查询结果,没什么影响,但是数据库存在隐式类型转换,索引将失效。
🍀(3)模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
接下来,我们来看一下这三条SQL语句的执行效果,查看一下其执行计划:
由于下面查询语句中,都是根据profession字段查询,符合最左前缀法则,联合索引是可以生效的,我们主要看一下,模糊查询时,%加在关键字之前,和加在关键字之后的影响。
explain select * from tb_user where profession like '软件%';
explain select * from tb_user where profession like '%工程';
explain select * from tb_user where profession like '%工%';
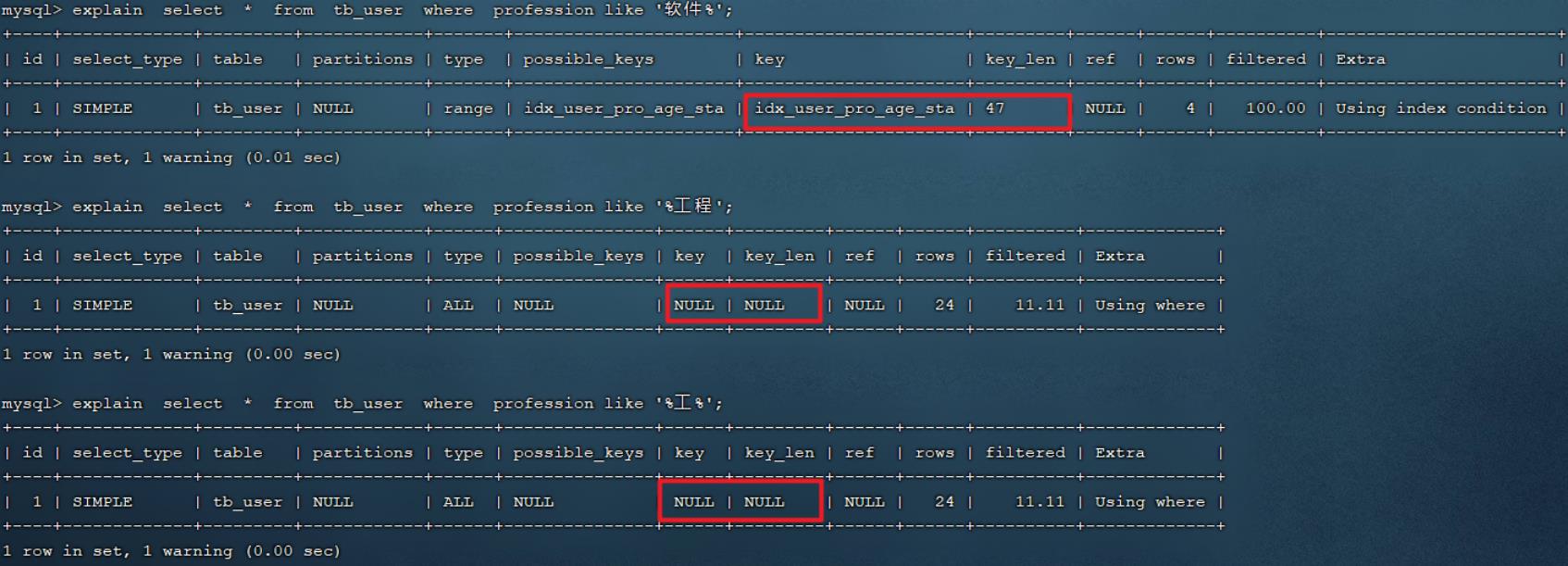
经过上述的测试,我们发现,在like模糊查询中,在关键字后面加%,索引可以生效。而如果在关键字
前面加了%,索引将会失效。
🍀(4)or连接条件
用or分割开的条件, 如果or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到。
explain select * from tb_user where id = 10 or age = 23;
explain select * from tb_user where phone = '17799990017' or age = 23;
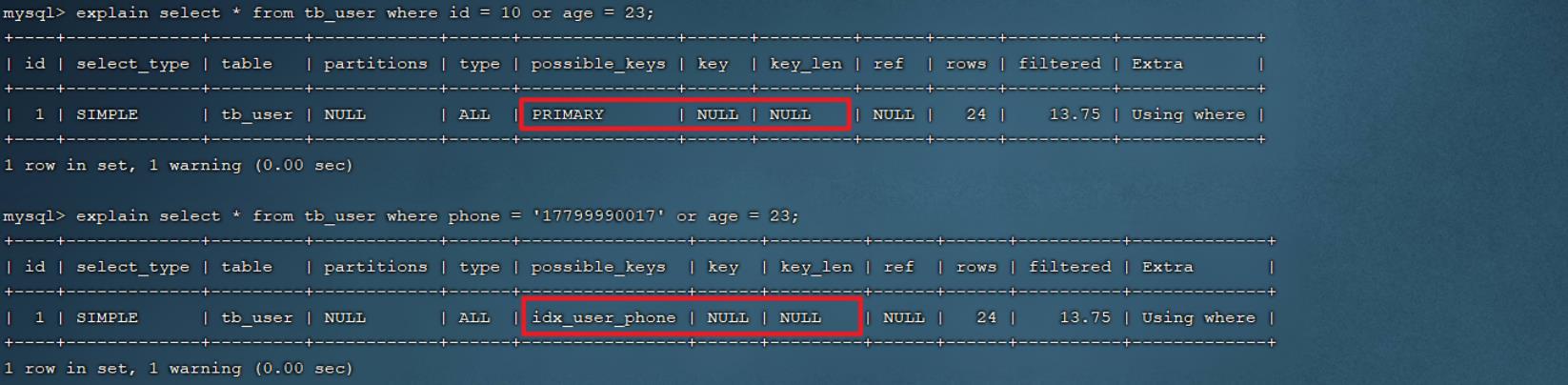
由于age没有索引,所以即使id、phone有索引,索引也会失效。所以需要针对于age也要建立索引。
然后,我们可以对age字段建立索引。
create index idx_user_age on tb_user(age); 1

建立了索引之后,我们再次执行上述的SQL语句,看看前后执行计划的变化。

最终,我们发现,当or连接的条件,左右两侧字段都有索引时,索引才会生效。
🍀(5)数据分布影响
如果mysql评估使用索引比全表更慢,则不使用索引。
select * from tb_user where phone >= '17799990005';
select * from tb_user where phone >= '17799990015';


经过测试我们发现,相同的SQL语句,只是传入的字段值不同,最终的执行计划也完全不一样,这是为什么呢?
就是因为MySQL在查询时,会评估使用索引的效率与走全表扫描的效率,如果走全表扫描更快,则放弃索引,走全表扫描。 因为索引是用来索引少量数据的,如果通过索引查询返回大批量的数据,则还不如走全表扫描来的快,此时索引就会失效。
接下来,我们再来看看 is null 与 is not null 操作是否走索引。
执行如下两条语句 :
explain select * from tb_user where profession is null;
explain select * from tb_user where profession is not null;
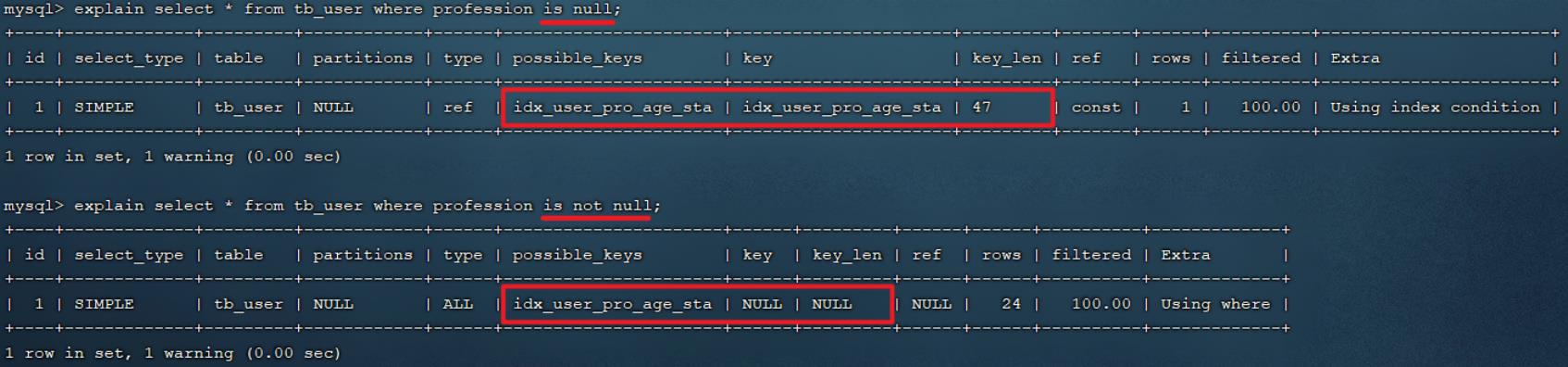
接下来,我们做一个操作将profession字段值全部更新为null。

然后,再次执行上述的两条SQL,查看SQL语句的执行计划。
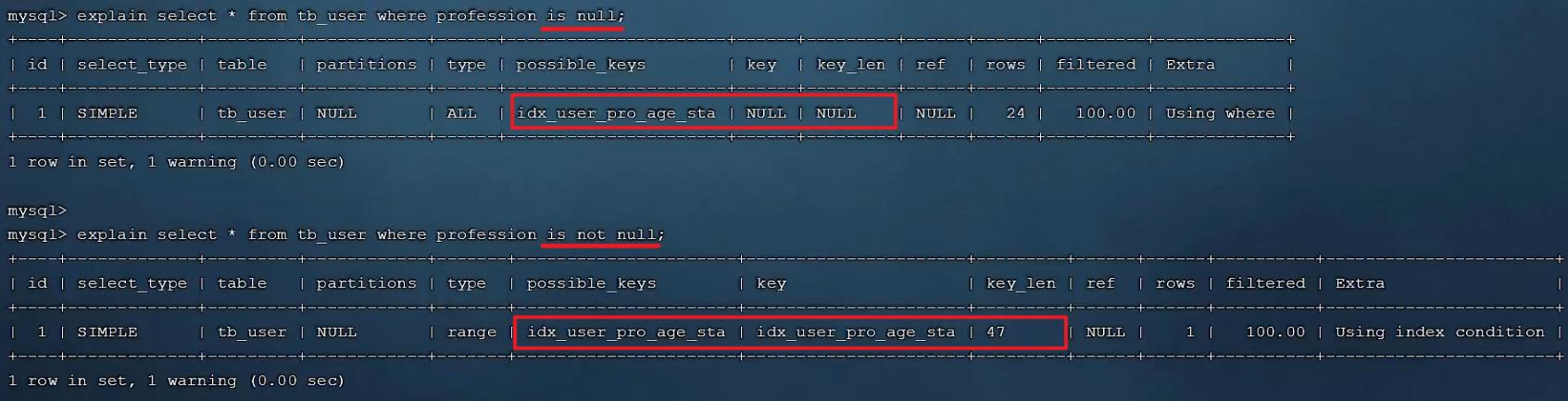
最终我们看到,一模一样的SQL语句,先后执行了两次,结果查询计划是不一样的,为什么会出现这种现象,这是和数据库的数据分布有关系。查询时MySQL会评估,走索引快,还是全表扫描快,如果全表扫描更快,则放弃索引走全表扫描。 因此,is null 、is not null是否走索引,得具体情况具体分析,并不是固定的。
5️⃣SQL提示
目前tb_user表的数据情况如下:
索引情况如下:

把上述的 idx_user_age, idx_email 这两个之前测试使用过的索引直接删除。
drop index idx_user_age on tb_user;
drop index idx_email on tb_user;
A. 执行SQL : explain select * from tb_user where profession = ‘软件工程’;

查询走了联合索引。
B. 执行SQL,创建profession的单列索引:create index idx_user_pro on tb_user(profession);

C. 创建单列索引后,再次执行A中的SQL语句,查看执行计划,看看到底走哪个索引。

测试结果,我们可以看到,possible_keys中 idx_user_pro_age_sta,idx_user_pro 这两个索引都可能用到,最终MySQL选择了idx_user_pro_age_sta索引。这是MySQL自动选择的结果。
那么,我们能不能在查询的时候,自己来指定使用哪个索引呢? 答案是肯定的,此时就可以借助于MySQL的SQL提示来完成。 接下来,介绍一下SQL提示。
SQL提示,是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
🍀(1)use index : 建议MySQL使用哪一个索引完成此次查询(仅仅是建议,mysql内部还会再次进行评估)。
explain select * from tb_user use index(idx_user_pro) where profession = '软件工程';
🍀(2)ignore index : 忽略指定的索引。
explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工程';
🍀(3)force index : 强制使用索引。
explain select * from tb_user force index(idx_user_pro) where profession = '软件工程';
示例演示:
A. use index
explain select * from tb_user use index(idx_user_pro) where profession = '软件工
程';

B. ignore index
explain select * from tb_user ignore index(idx_user_pro) where profession = '软件工程';

C. force index
explain select * from tb_user force index(idx_user_pro_age_sta) where profession =
'软件工程';

6️⃣覆盖索引
尽量使用覆盖索引,减少select *。 那么什么是覆盖索引呢? 覆盖索引是指 查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到 。
接下来,我们来看一组SQL的执行计划,看看执行计划的差别,然后再来具体做一个解析。
explain select id, profession from tb_user where profession = '软件工程' and age =
31 and status = '0' ;
explain select id,profession,age, status from tb_user where profession = '软件工程'
and age = 31 and status = '0' ;
explain select id,profession,age, status, name from tb_user where profession = '软
件工程' and age = 31 and status = '0' ;
explain select * from tb_user where profession = '软件工程' and age = 31 and status
= '0';
上述这几条SQL的执行结果为:

从上述的执行计划我们可以看到,这四条SQL语句的执行计划前面所有的指标都是一样的,看不出来差异。但是此时,我们主要关注的是后面的Extra,前面两天SQL的结果为 Using where; Using Index ; 而后面两条SQL的结果为: Using index condition 。
| Extra | 含义 |
|---|---|
| Using where; Using Index | 查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据 |
| Using index condition | 查找使用了索引,但是需要回表查询数据 |
因为,在tb_user表中有一个联合索引 idx_user_pro_age_sta,该索引关联了三个字段profession、age、status,而这个索引也是一个二级索引,所以叶子节点下面挂的是这一行的主键id。 所以当我们查询返回的数据在 id、profession、age、status 之中,则直接走二级索引直接返回数据了。 如果超出这个范围,就需要拿到主键id,再去扫描聚集索引,再获取额外的数据了,这个过程就是回表。 而我们如果一直使用select * 查询返回所有字段值,很容易就会造成回表查询(除非是根据主键查询,此时只会扫描聚集索引)。
为了大家更清楚的理解,什么是覆盖索引,什么是回表查询,我们一起再来看下面的这组SQL的执行过程。
A. 表结构及索引示意图:
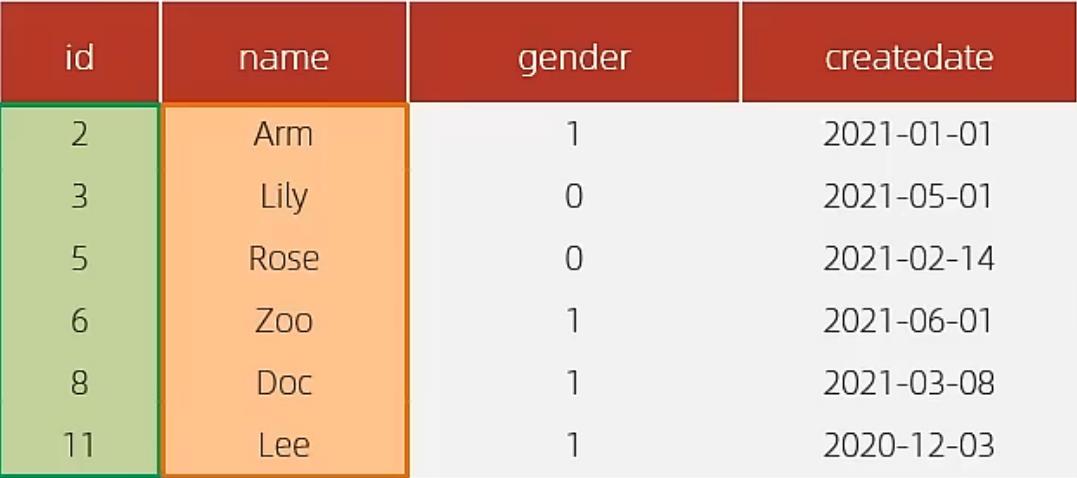
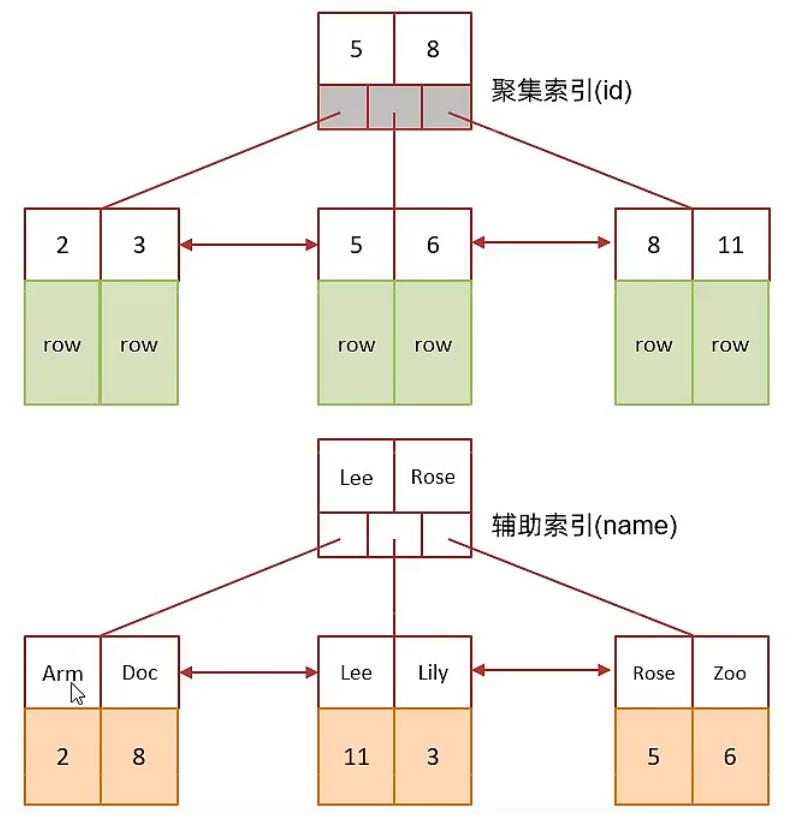
id是主键,是一个聚集索引。 name字段建立了普通索引,是一个二级索引(辅助索引)。
B. 执行SQL : select * from tb_user where id = 2;
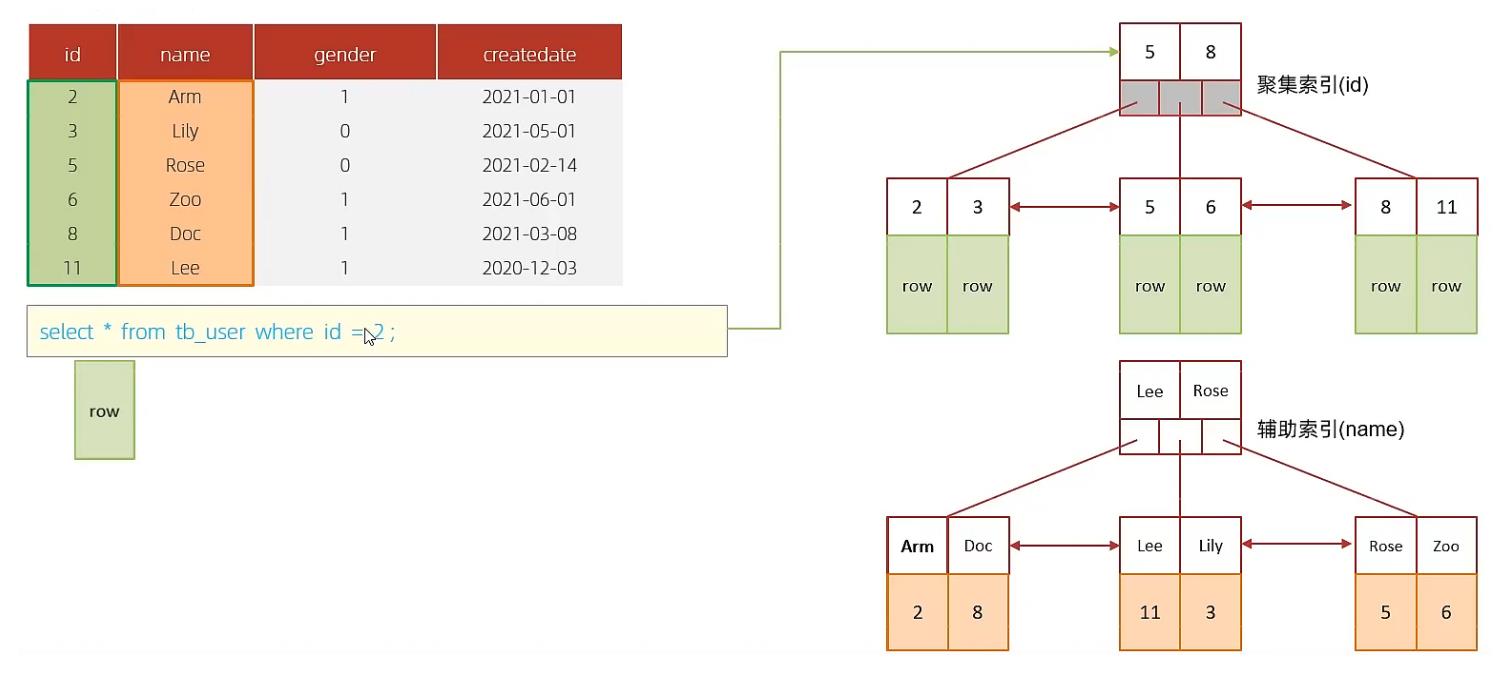
根据id查询,直接走聚集索引查询,一次索引扫描,直接返回数据,性能高。
C. 执行SQL:selet id,name from tb_user where name = ‘Arm’;
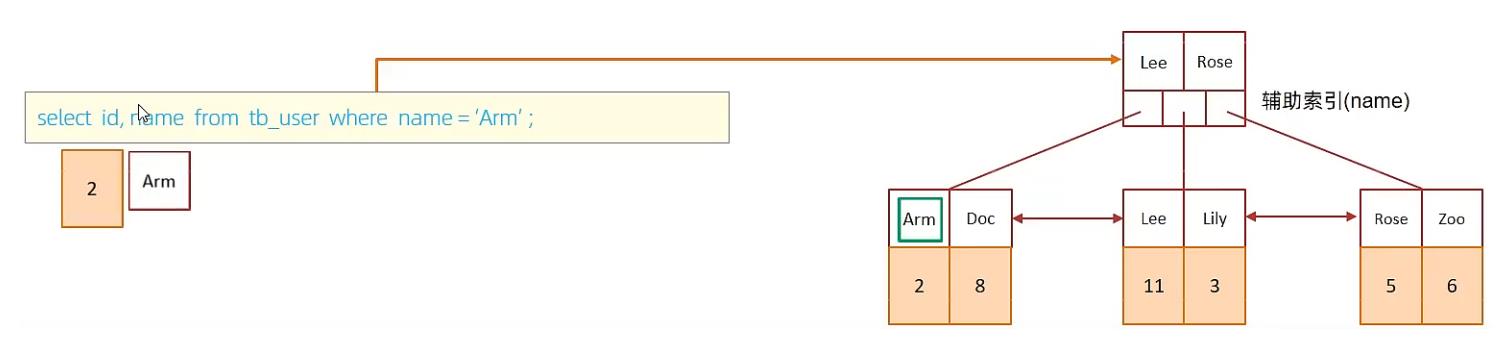
虽然是根据name字段查询,查询二级索引,但是由于查询返回在字段为 id,name,在name的二级索引中,这两个值都是可以直接获取到的,因为覆盖索引,所以不需要回表查询,性能高。
D. 执行SQL:selet id,name,gender from tb_user where name = ‘Arm’;
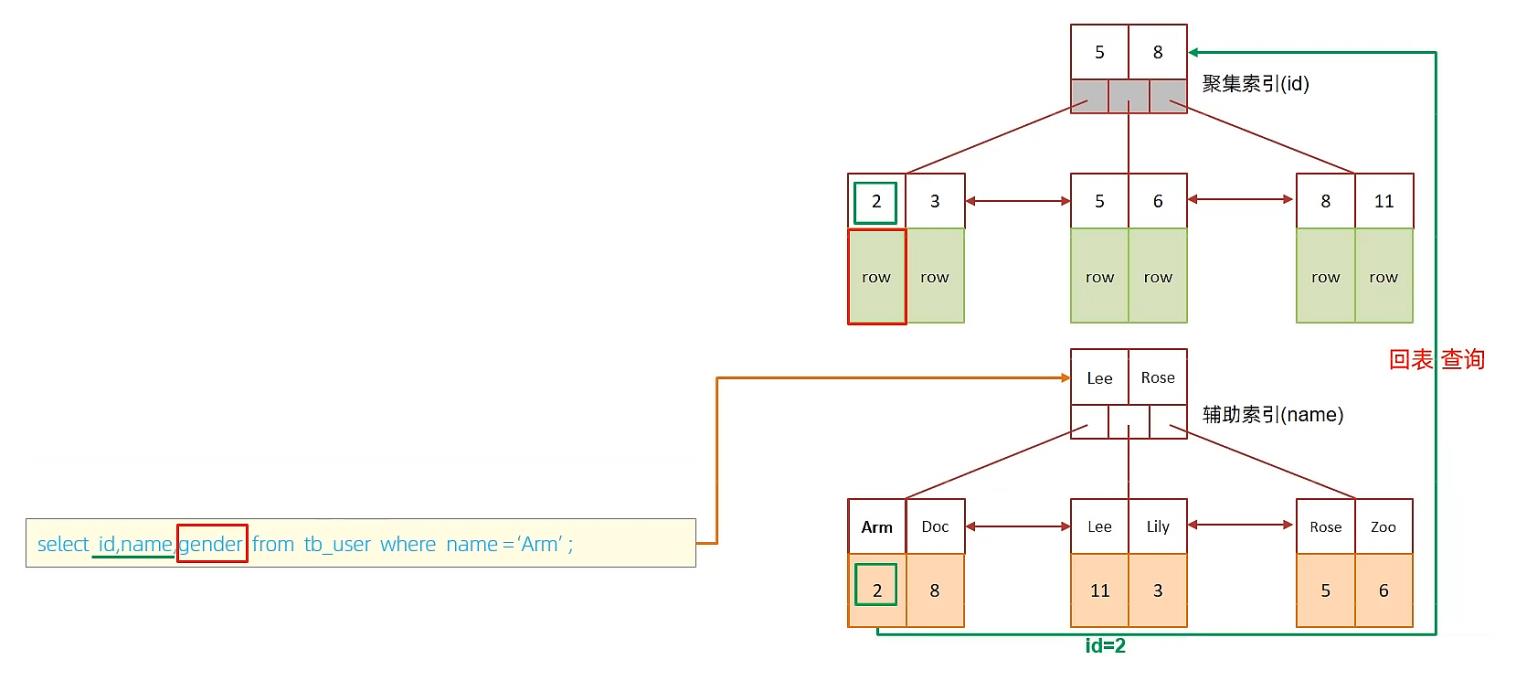
由于在name的二级索引中,不包含gender,所以,需要两次索引扫描,也就是需要回表查询,性能相对较差一点。
7️⃣前缀索引
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
🍀(1)语法
create index idx_xxxx on table_name(column(n)) ;
示例:
为tb_user表的email字段,建立长度为5的前缀索引。
create index idx_email_5 on tb_user(email(5));

🍀(2)前缀长度
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高, 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
select count(distinct email) / count(*) from tb_user ;
select count(distinct substring(email,1,5)) / count(*) from tb_user ;
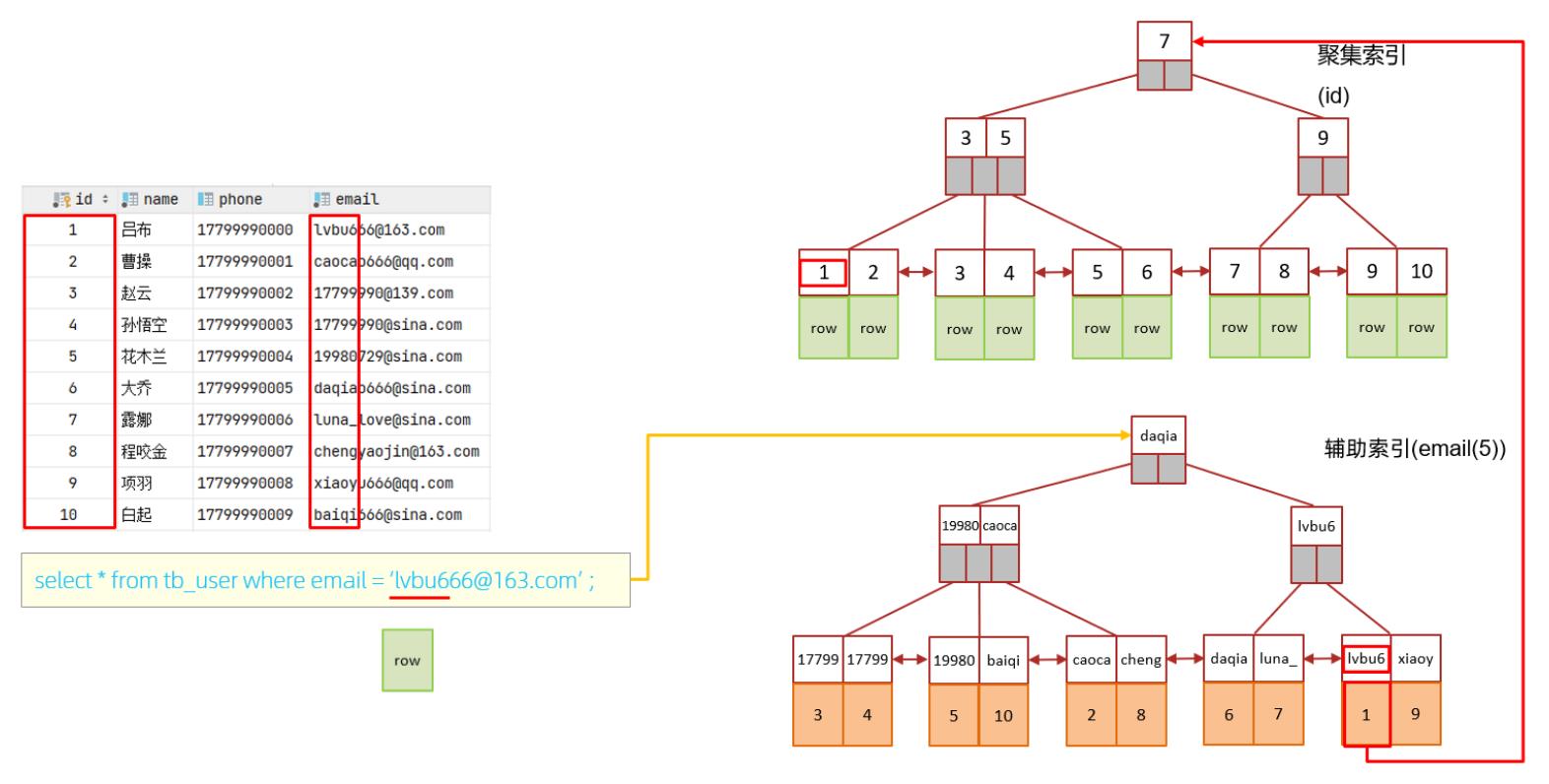
8️⃣单列索引与联合索引
单列索引:即一个索引只包含单个列。
联合索引:即一个索引包含了多个列。
我们先来看看 tb_user 表中目前的索引情况:

在查询出来的索引中,既有单列索引,又有联合索引。
接下来,我们来执行一条SQL语句,看看其执行计划:

通过上述执行计划我们可以看出来,在and连接的两个字段 phone、name上都是有单列索引的,但是最终mysql只会选择一个索引,也就是说,只能走一个字段的索引,此时是会回表查询的。
紧接着,我们再来创建一个phone和name字段的联合索引来查询一下执行计划。
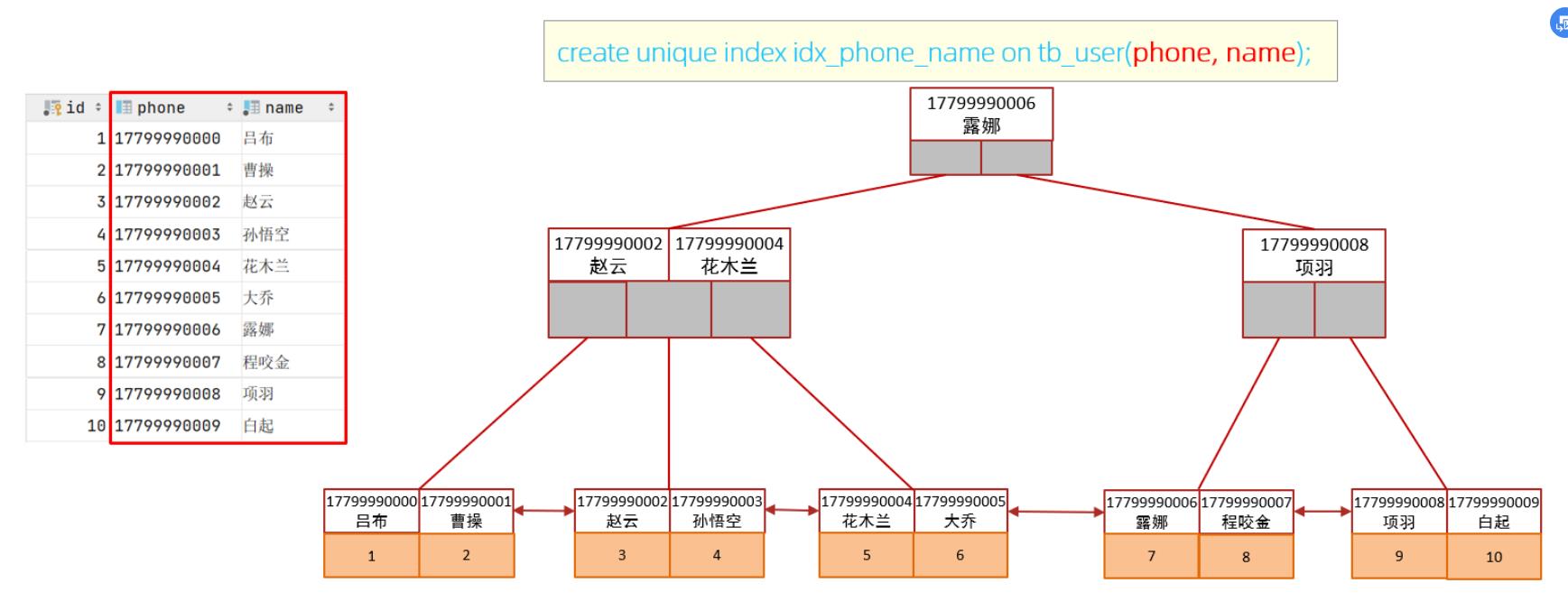
create unique index idx_user_phone_name on tb_user(phone,name);

此时,查询时,就走了联合索引,而在联合索引中包含 phone、name的信息,在叶子节点下挂的是对应的主键id,所以查询是无需回表查询的。
在业务场景中,如果存在多个查询条件,考虑针对于查询字段建立索引时,建议建立联合索引,而非单列索引。
如果查询使用的是联合索引,具体的结构示意图如下:
二、索引设计原则
- (1)针对于数据量较大,且查询比较频繁的表建立索引。
- (2)针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引。
- (3)尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高。
- (4)如果是字符串类型的字段,字段的长度较长,可以针对于字段的特点,建立前缀索引。
- (5)尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率。
- (6)要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价也就越大,会影响增删改的效率。
- (7)如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询。
后记

👉Java全栈学习路线可参考:【Java全栈学习路线】最全的Java学习路线及知识清单,Java自学方向指引,内含最全Java全栈学习技术清单~
👉算法刷题路线可参考:算法刷题路线总结与相关资料分享,内含最详尽的算法刷题路线指南及相关资料分享~
MySQL 进阶 索引 -- 索引使用原则(验证索引效率最左前缀法则范围查询索引失效情况SQL提示覆盖索引前缀索引单列索引与联合索引)索引设计原则
文章目录
1. 索引使用原则
1.1 验证索引效率
tb_sku 这张表中准备了 1000w 的记录。
 这张表中
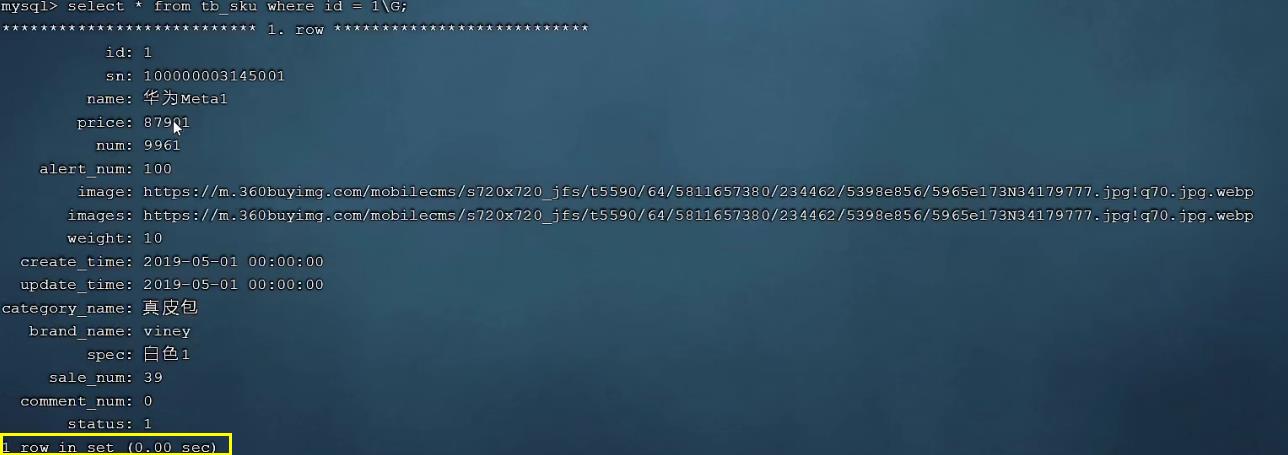
这张表中id为主键,有主键索引,而其他字段是没有建立索引的。 我们先来查询其中的一条记录,看看里面的字段情况,执行如下SQL:
select * from tb_sku where id = 1\\G;
 可以看到即使有
可以看到即使有1000w的数据,根据id进行数据查询,性能依然很快,因为主键id是有索引的。 那么接下来,我们再来根据 sn 字段进行查询,执行如下SQL:
SELECT * FROM tb_sku WHERE sn = '100000003145001';

我们可以看到根据sn字段进行查询,查询返回了一条数据,结果耗时 20.78sec,就是因为sn没有索引,而造成查询效率很低。
那么我们可以针对于sn字段,建立一个索引,建立了索引之后,我们再次根据sn进行查询,再来看一下查询耗时情况。
create index idx_sku_sn on tb_sku(sn) ;

然后再次执行相同的SQL语句,再次查看SQL的耗时。
SELECT * FROM tb_sku WHERE sn = '100000003145001';
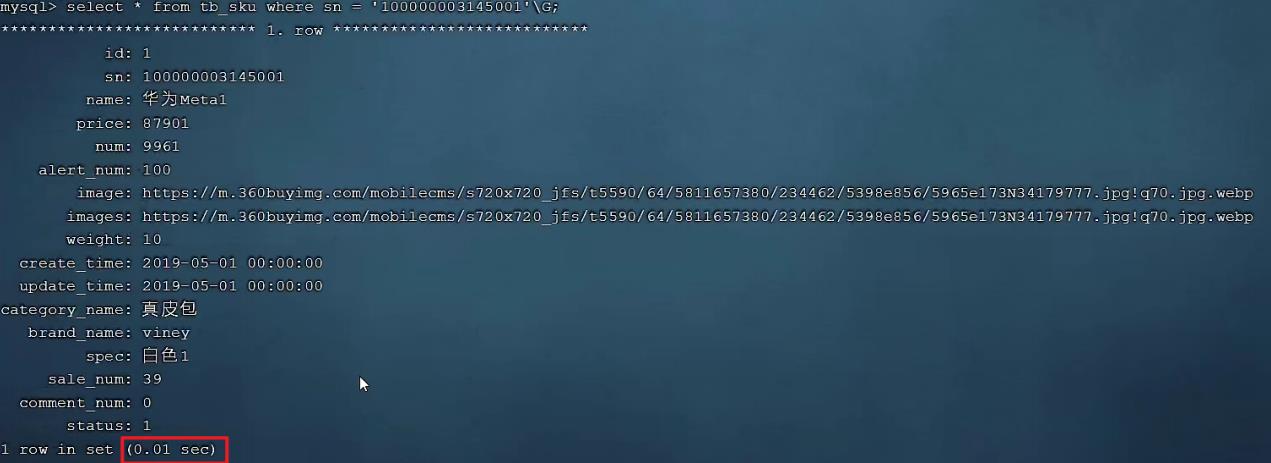
我们明显会看到,sn字段建立了索引之后,查询性能大大提升。建立索引前后,查询耗时都不是一个数量级的。

1.2 最左前缀法则
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。如果跳跃某一列,索引将会部分失效(后面的字段索引失效)。
注意 : 最左前缀法则中指的最左边的列,是指在查询时,联合索引的最左边的字段(即是第一个字段)必须存在,与我们编写SQL时,条件编写的先后顺序无关。
以 tb_user 表为例,我们先来查看一下之前 tb_user 表所创建的索引。
tb_user表的建表语句
CREATE TABLE `tb_user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(50) NOT NULL COMMENT '用户名',
`phone` varchar(11) NOT NULL COMMENT '手机号',
`email` varchar(100) DEFAULT NULL COMMENT '邮箱',
`profession` varchar(11) DEFAULT NULL COMMENT '专业',
`age` tinyint unsigned DEFAULT NULL COMMENT '年龄',
`gender` char(1) DEFAULT NULL COMMENT '性别 , 1: 男, 2: 女',
`status` char(1) DEFAULT NULL COMMENT '状态',
`createtime` datetime DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_phone` (`phone`),
KEY `idx_user_name` (`name`),
KEY `idx_user_pro_age_sta` (`profession`,`age`,`status`),
KEY `idx_email` (`email`)
) ENGINE=InnoDB AUTO_INCREMENT=25 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='系统用户表';
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('吕布', '17799990000', 'lvbu666@163.com', '软件工程', 23, '1', '6', '2001-02-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('曹操', '17799990001', 'caocao666@qq.com', '通讯工程', 33, '1', '0', '2001-03-05 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('赵云', '17799990002', '17799990@139.com', '英语', 34, '1', '2', '2002-03-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('孙悟空', '17799990003', '17799990@sina.com', '工程造价', 54, '1', '0', '2001-07-02 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('花木兰', '17799990004', '19980729@sina.com', '软件工程', 23, '2', '1', '2001-04-22 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('大乔', '17799990005', 'daqiao666@sina.com', '舞蹈', 22, '2', '0', '2001-02-07 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('露娜', '17799990006', 'luna_love@sina.com', '应用数学', 24, '2', '0', '2001-02-08 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('程咬金', '17799990007', 'chengyaojin@163.com', '化工', 38, '1', '5', '2001-05-23 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('项羽', '17799990008', 'xiaoyu666@qq.com', '金属材料', 43, '1', '0', '2001-09-18 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('白起', '17799990009', 'baiqi666@sina.com', '机械工程及其自动 化', 27, '1', '2', '2001-08-16 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('韩信', '17799990010', 'hanxin520@163.com', '无机非金属材料工 程', 27, '1', '0', '2001-06-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('荆轲', '17799990011', 'jingke123@163.com', '会计', 29, '1', '0', '2001-05-11 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('兰陵王', '17799990012', 'lanlinwang666@126.com', '工程造价', 44, '1', '1', '2001-04-09 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('狂铁', '17799990013', 'kuangtie@sina.com', '应用数学', 43, '1', '2', '2001-04-10 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('貂蝉', '17799990014', '84958948374@qq.com', '软件工程', 40, '2', '3', '2001-02-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('妲己', '17799990015', '2783238293@qq.com', '软件工程', 31, '2', '0', '2001-01-30 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('芈月', '17799990016', 'xiaomin2001@sina.com', '工业经济', 35, '2', '0', '2000-05-03 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('嬴政', '17799990017', '8839434342@qq.com', '化工', 38, '1', '1', '2001-08-08 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('狄仁杰', '17799990018', 'jujiamlm8166@163.com', '国际贸易', 30, '1', '0', '2007-03-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('安琪拉', '17799990019', 'jdodm1h@126.com', '城市规划', 51, '2', '0', '2001-08-15 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('典韦', '17799990020', 'ycaunanjian@163.com', '城市规划', 52, '1', '2', '2000-04-12 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('廉颇', '17799990021', 'lianpo321@126.com', '土木工程', 19, '1', '3', '2002-07-18 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('后羿', '17799990022', 'altycj2000@139.com', '城市园林', 20, '1', '0', '2002-03-10 00:00:00');
INSERT INTO tb_user (name, phone, email, profession, age, gender, status, createtime)
VALUES ('姜子牙', '17799990023', '37483844@qq.com', '工程造价', 29, '1', '4', '2003-05-26 00:00:00');
在 tb_user 表中,有一个联合索引,这个联合索引涉及到三个字段,顺序分别为:profession,age,status。
对于最左前缀法则指的是,查询时,最左边的列,也就是profession必须存在,否则索引全部失效。而且中间不能跳过某一列,否则该列后面的字段索引将失效。 接下来,我们来演示几组案例,看一下具体的执行计划:
explain
select *
from tb_user
where profession = '软件工程'
and age = 31
and status = '0';

explain
select *
from tb_user
where profession = '软件工程'
and age = 31;
explain
select *
from tb_user
where profession = '软件工程';

以上的这三组测试中,我们发现只要联合索引最左边的字段 profession 存在,索引就会生效,只不过索引的长度不同。 而且由以上三组测试,我们也可以推测出profession字段索引长度为47、age字段索引长度为2、status字段索引长度为5。
explain
select *
from tb_user
where age = 31
and status = '0';
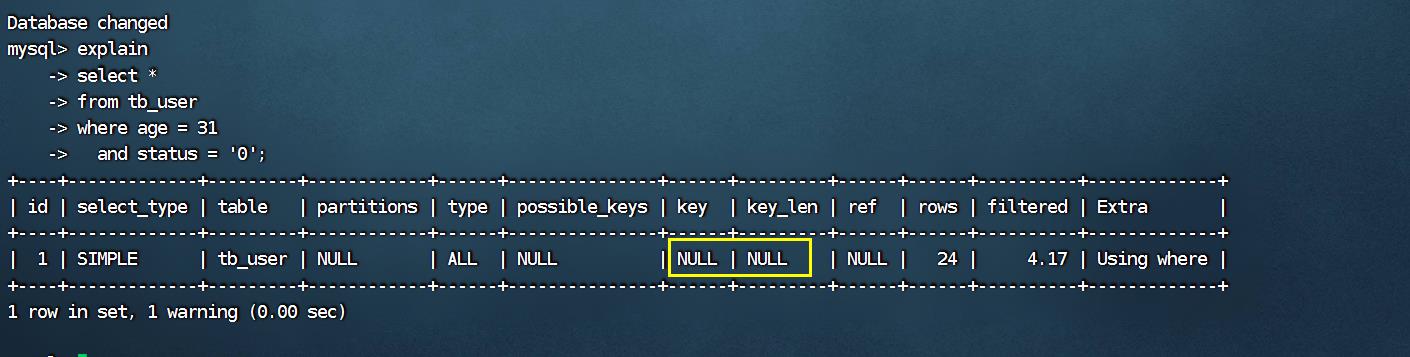
explain
select *
from tb_user
where status = '0';
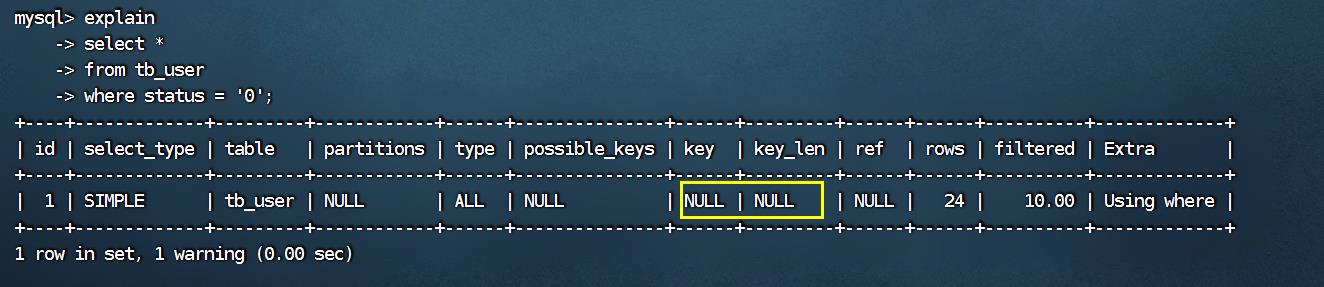
而通过上面的这两组测试,我们也可以看到索引并未生效,原因是因为不满足最左前缀法则,联合索引最左边的列profession不存在。
explain
select *
from tb_user
where profession = '软件工程'
and status = '0';

上述的SQL查询时,存在profession字段,最左边的列是存在的,索引满足最左前缀法则的基本条件。但是查询时,跳过了age这个列,所以后面的列索引是不会使用的,也就是索引部分生效,所以索引的长度就是47。
思考题:
当执行SQL语句(查询条件的顺序发生了变化):
explain
select *
from tb_user
where age = 31
and status = '0'
and profession = '软件工程';
时,是否满足最左前缀法则,走不走上述的联合索引,索引长度?

可以看到,是完全满足最左前缀法则的,索引长度54,联合索引是生效的。
1.3 范围查询
联合索引中,出现范围查询(>,<),范围查询右侧的列索引失效。
explain
select *
from tb_user
where profession = '软件工程'
and age > 30
and status = '0';
当范围查询使用 > 或 < 时,走联合索引了,但是索引的长度为49,就说明范围查询右边的status字段是没有走索引的。
explain
select *
from tb_user
where profession = '软件工程'
and age >= 30
and status = '0';
当范围查询使用 >= 或 <= 时,走联合索引了,但是索引的长度为54,就说明所有的字段都是走索引的。
所以,在业务允许的情况下,尽可能的使用类似于 >= 或 <= 这类的范围查询,而避免使用 > 或 < 。
1.4 索引失效情况
1.4.1 索引列运算
不要在索引列上进行运算操作,索引将失效。
在 tb_user 表中,除了前面介绍的联合索引之外,还有一个索引,是 phone 字段的单列索引。
A. 当根据phone字段进行等值匹配查询时,索引生效。
explain
select *
from tb_user
where phone = '17799990015';

B. 当根据phone字段进行函数运算操作之后,索引失效。
explain
select *
from tb_user
where substring(phone, 10, 2) = '15';

1.4.2 字符串不加引号
字符串类型字段使用时,不加引号,索引将失效。
接下来,我们通过两组示例,来看看对于字符串类型的字段,加单引号与不加单引号的区别:
第一组示例:
explain
select *
from tb_user
where profession = '软件工程'
and age = 31
and status = '0';

explain
select *
from tb_user
where profession = '软件工程'
and age = 31
and status = 0;

第二组示例:
explain
select *
from tb_user
where phone = '17799990015';

explain
select *
from tb_user
where phone = 17799990015;

经过上面两组示例,我们会明显的发现,如果字符串不加单引号,对于查询结果,没什么影响,但是数据库存在隐式类型转换,索引将失效。
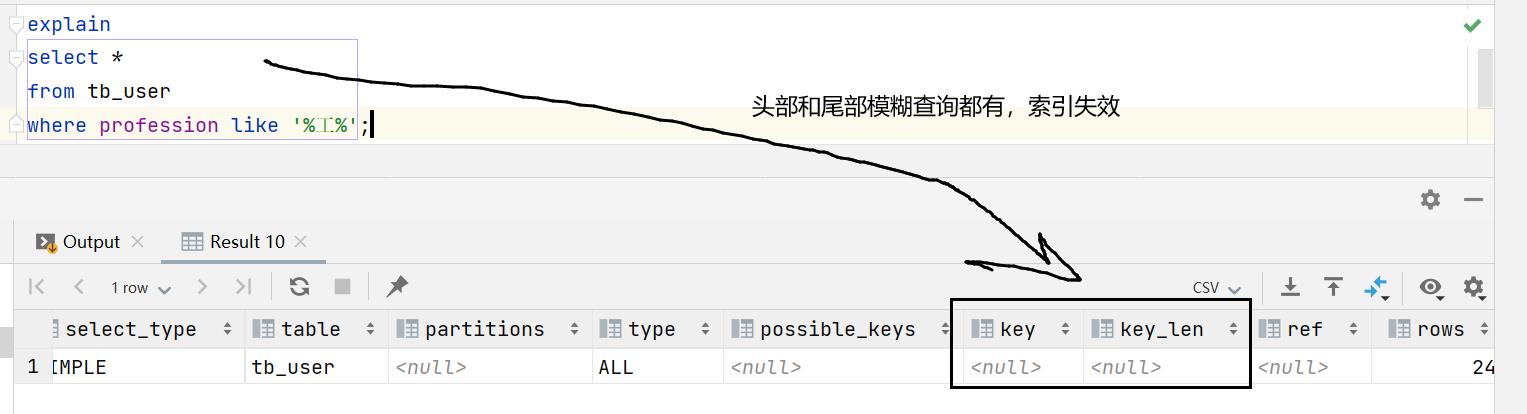
1.4.3 模糊查询
如果包含头部模糊匹配,索引失效。
接下来,我们来看一下这三条SQL语句的执行效果,查看一下其执行计划:
由于下面查询语句中,都是根据profession字段查询,符合最左前缀法则,联合索引是可以生效的,我们主要看一下,模糊查询时,%加在关键字之前,和加在关键字之后的影响。
explain
select *
from tb_user
where profession like '软件%';

explain
select *
from tb_user
where profession like '%工程';

explain
select *
from tb_user
where profession like '%工%';
以上是关于MySQL进阶教程 索引使用与设计原则的主要内容,如果未能解决你的问题,请参考以下文章