MySqlmysql 常用查询优化策略详解
Posted 逆风飞翔的小叔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySqlmysql 常用查询优化策略详解相关的知识,希望对你有一定的参考价值。
前言
在程序上线运行一段时间后,一旦数据量上去了,或多或少会感觉到系统出现延迟、卡顿等现象,出现这种问题,就需要程序员或架构师进行系统调优工作了,其中,大量的实践经验表明,调优的手段尽管有很多,但涉及到SQL调优的内容仍然是非常重要的一环,本文将结合实例,总结一些工作中可能涉及到的SQL优化策略;
查询优化
可以说,对于大多数系统来说,读多写少一定是常态,这就表示涉及到查询的SQL是非常高频的操作;
前置准备,给一张测试表添加10万条数据
使用下面的存储过程给单表造一批数据,将表换成自己的就好了
create procedure addMyData()
begin
declare num int;
set num =1;
while num <= 100000 do
insert into XXX_table values(
replace(uuid(),'-',''),concat('测试',num),concat('cs',num),'123456'
);
set num =num +1;
end while;
end ;然后调用该存储过程
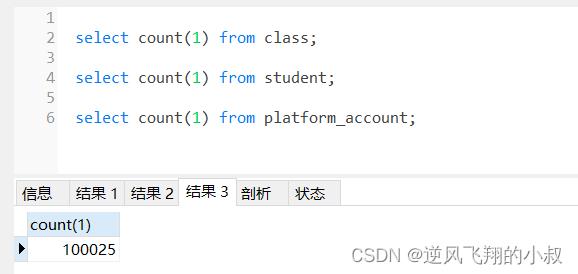
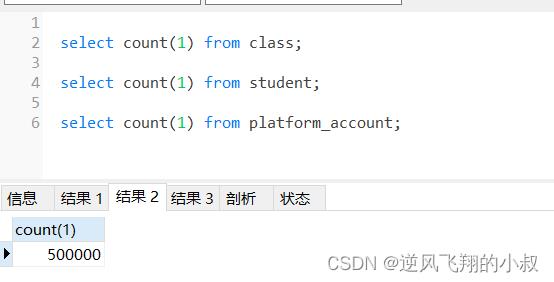
call addMyData();本篇准备了3张表,分别为学生(student)表,班级(class)表,账户(account)表,各自有50万,1万和10万条数据用于测试;
1、分页查询优化
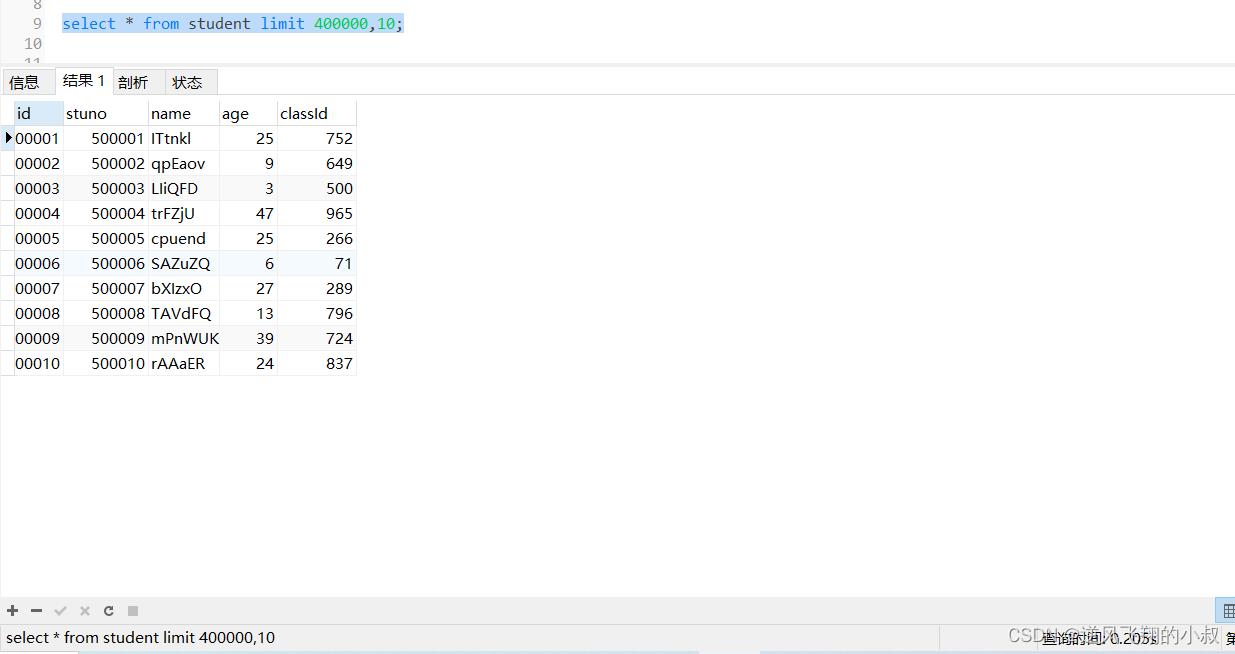
分页查询是开发中经常会遇到的,有一种情况是,当分页的数量非常大的时候,查询的时候往往非常耗时,比如查询student表,使用下面的sql查询,耗时达到0.2秒;
 实践经验告诉我们,越往后,分页查询效率越低,这就是分页查询的问题所在,
因为,当在进行分页查询时,如果执行
limit 400000,10
,此时需要
mysql
排序前4000
10
记
录,仅仅返回400000 - 4
00010 的记录,其他记录丢弃,查询排序的代价非常大
实践经验告诉我们,越往后,分页查询效率越低,这就是分页查询的问题所在,
因为,当在进行分页查询时,如果执行
limit 400000,10
,此时需要
mysql
排序前4000
10
记
录,仅仅返回400000 - 4
00010 的记录,其他记录丢弃,查询排序的代价非常大
优化思路:
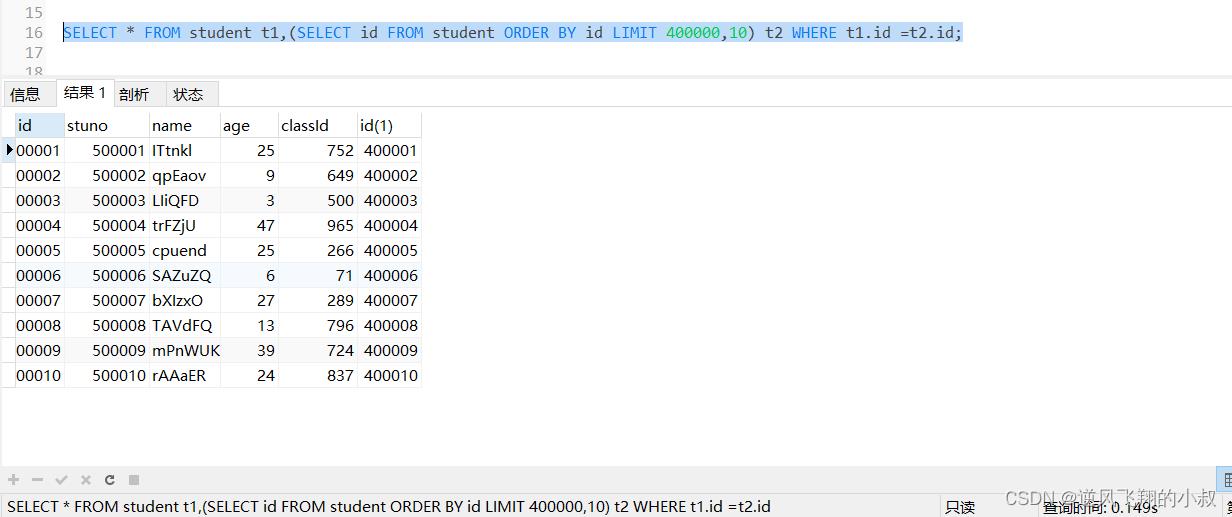
一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化;1) 在索引上完成排序分页操作,最后根据主键关联回原表查询所需要的其他列内容
SELECT * FROM student t1,(SELECT id FROM student ORDER BY id LIMIT 400000,10) t2 WHERE t1.id =t2.id;
执行上面的sql,可以看到响应时间有一定的提升;
2)对于主键自增的表,可以把Limit 查询转换成某个位置的查询
select * from student where id > 400000 limit 10;
执行上面的sql,可以看到响应时间有一定的提升;

2、关联查询优化
在实际的业务开发过程中,关联查询可以说随处可见,关联查询的优化核心思路是,最好为关联查询的字段添加索引,这是关键,具体到不同的场景,还需要具体分析,这个跟mysql的引擎在执行优化策略的方案选择时有一定关系;
2.1 左连接或右连接
下面是一个使用left join 的查询,可以预想到这条sql查询的结果集非常大
select t.* from student t left join class cs on t.classId = cs.id;为了检查下sql的执行效率,使用explain做一下分析,可以看到,第一张表即left join左边的表student走了全表扫描,而class表走了主键索引,尽管结果集较大,还是走了索引;

针对这种场景的查询,思路如下:
- 让查询的字段尽量包含在主键索引或者覆盖索引中;
- 查询的时候尽量使用分页查询;
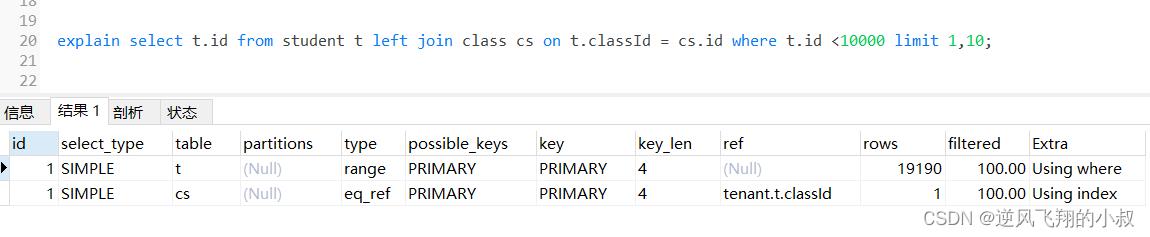
关于左连接(右连接)的explain结果补充说明
- 左连接左边的表一般为驱动表,右边的表为被驱动表;
- 尽可能让数据集小的表作为驱动表,减少mysql内部循环的次数;
- 两表关联时,explain结果展示中,第一栏一般为驱动表;
2.2 关联查询关联的字段建立索引
看下面的这条sql,其关联字段非表的主键,而是普通的字段;
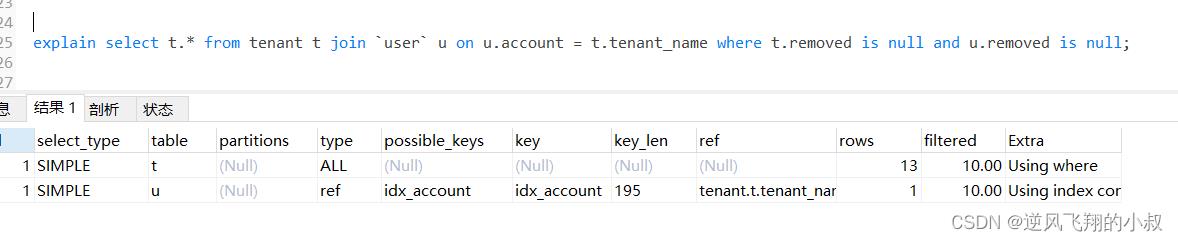
explain select u.* from tenant t left join `user` u on u.account = t.tenant_name where t.removed is null and u.removed is null;
通过explain分析可以发现,左边的表走了全表扫描,可以考虑给左边的表的tenant_name和user表的account 各自创建索引;
create index idx_name on tenant(tenant_name);
create index idx_account on `user`(account);
再次使用explain分析结果如下

可以看到第二行type变为ref,rows的数量优化比较明显。这是由左连接特性决定的,LEFT JOIN条件用于确定如何从右表搜索行,左边一定都有,所以右边是我们的关键点,一定需要建立索引 。
2.3 内连接关联的字段建立索引
我们知道,左连接和右连接查询的数据分别是完全包含左表数据,完全包含右表数据,而内连接(inner join 或join) 则是取交集(共有的部分),在这种情况下,驱动表的选择是由mysql优化器自动选择的;
在上面的基础上,首先移除两张表的索引
ALTER TABLE `user` DROP INDEX idx_account;
ALTER TABLE `tenant` DROP INDEX idx_name;
使用explain语句进行分析

然后给user表的account字段添加索引,再次执行explain我们发现,user表竟然被当作是被驱动表了;
此时,如果我们给tenant表的tenant_name加索引,并移除user表的account索引,得出的结果竟然都没有走索引,再次说明,使用内连接的情况下,查询优化器将会根据自己的判断进行选择;

3、子查询优化
子查询在日常编写业务的SQL时也是使用非常频繁的做法,不是说子查询不能用,而是当数据量超出一定的范围之后,子查询的性能下降是很明显的,关于这一点,本人在日常工作中深有体会;
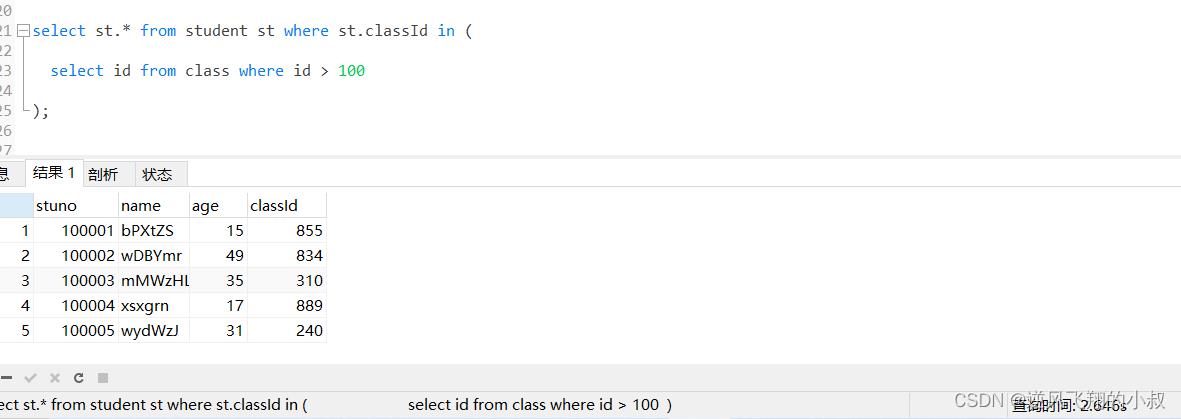
比如下面这条sql,由于student表数据量较大,执行起来耗时非常长,可以看到耗费了将近3秒;
select st.* from student st where st.classId in (
select id from class where id > 100
);
通过执行explain进行分析得知,内层查询 id > 100的子查询尽管用上了主键索引,但是由于结果集太大,带入到外层查询,即作为in的条件时,查询优化器还是走了全表扫描;
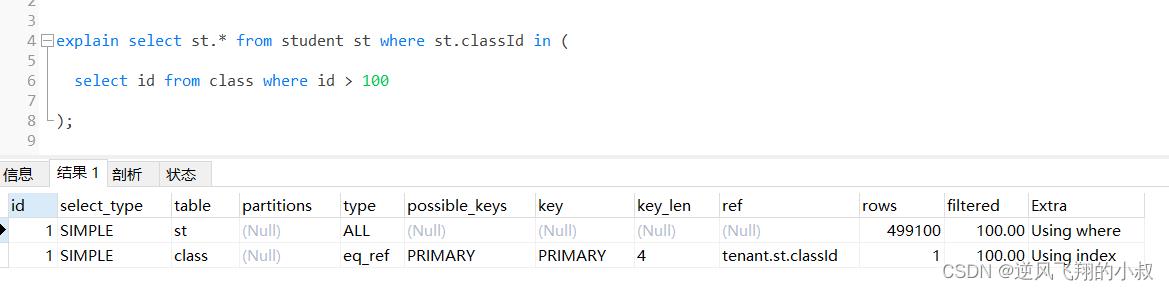
针对上面的情况,可以考虑下面的优化方式
select st.id from student st join class cl on st.classId = cl.id where cl.id > 100;
子查询性能低效的原因
- 子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表 ,然后外层查询语句从临时表中查询记录,查询完毕后,再撤销这些临时表 。这样会消耗过多的CPU和IO资源,产生大量的慢查询;
- 子查询结果集存储的临时表,不论是内存临时表还是磁盘临时表都不能走索引 ,所以查询性能会受到一定的影响;
- 对于返回结果集比较大的子查询,其对查询性能的影响也就越大;
使用mysql查询时,可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表 ,其速度比子查询要快 ,如果查询中使用索引的话,性能就会更好,尽量不要使用NOT IN 或者 NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL替代;
一个真实的案例
在下面的这段sql中,优化前使用的是子查询,在一次生产问题的性能分析中,发现某个tenant_id下的数据达到了35万多,这样直接导致某个列表页面的接口查询耗时达到了5秒左右;
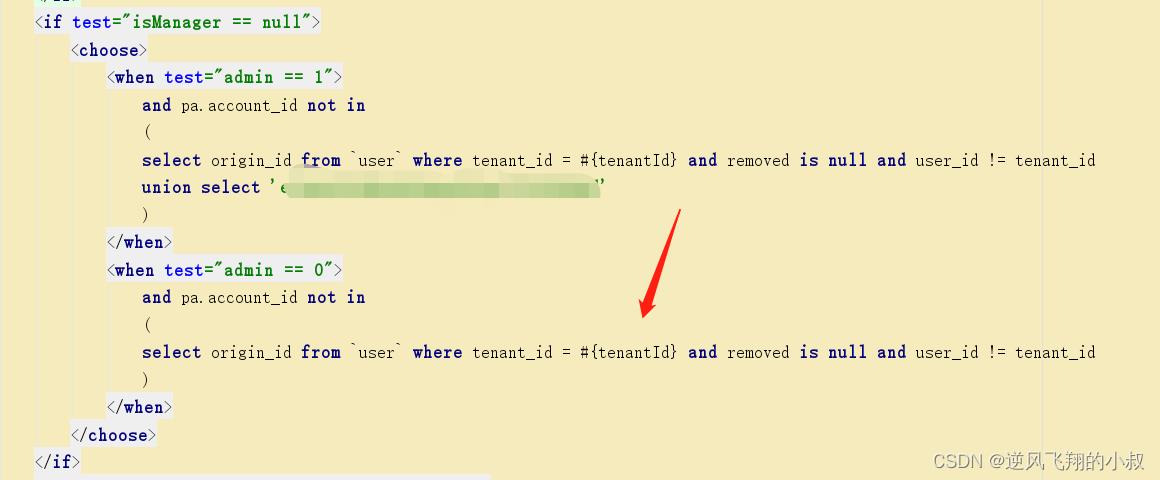
找到了问题的根源后,尝试使用上面的优化思路进行解决即可,优化后的sql大概如下,
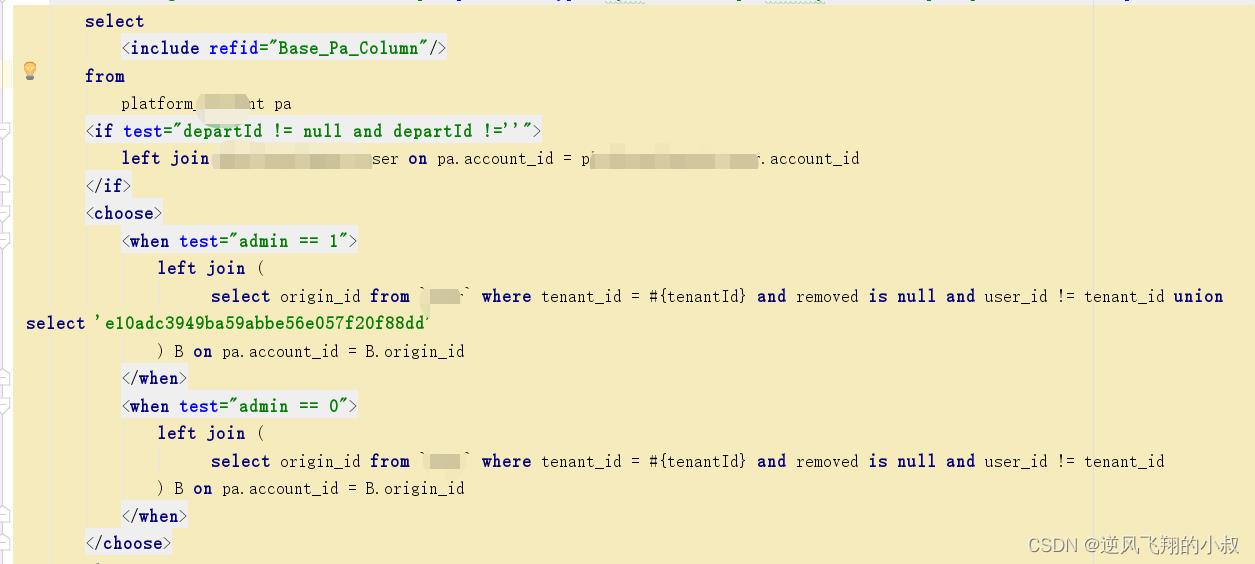
4、排序(order by)优化
在mysql,排序主要有两种方式
- Using filesort : 通过表索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort
buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序; - Using index : 通过有序的索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高;
对于以上两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index
4.1 使用age字段进行排序
由于age字段未加索引,查询结果按照age排序的时候发现使用了filesort,排序性能较低;

给age字段添加索引,再次使用order by时就走了索引;

4.2 使用多字段进行排序
通常在实际业务中,参与排序的字段往往不只一个,这时候,就可以对参与排序的多个字段创建联合索引;
如下根据stuno和age排序

给stuno和age添加联合索引
create index idx_stuno_age on `student`(stuno,age);
再次分析时结果如下,此时排序走了索引

关于多字段排序时的注意事项
1)排序时,需要满足最左前缀法则,否则也会出现 filesort;
在上面我们创建的联合索引顺序是stuno和age,即stuno在前面,而age在后,如果查询的时候调换排序顺序会怎样呢?通过分析结果发现,走了filesort;

2)排序时,排序的类型保持一致
在保持字段排序顺序不变时,默认情况下,如果都按照升序或者降序时,order by可以使用index,如果一个是升序,另一个是降序会如何呢?分析发现,这种情况下也会走filesort;

5、分组(group by)优化
group by 的优化策略和order by 的优化策略非常像,主要列举如下几个要点:
- group by 即使没有过滤条件用到索引,也可以直接使用索引;
- group by 先排序再分组,遵照索引建的最佳左前缀法则;
- 当无法使用索引列时,增大 max_length_for_sort_data 和 sort_buffer_size 参数的设置;
- where效率高于having,能写在where限定的条件就不要写在having中了;
- 减少使用order by,能不排序就不排序,或将排序放到程序去做。Order by、groupby、distinct这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的;
- 如果sql包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢;
5.1 给group by的字段添加索引
如果字段未加索引,分析结果如下,这种结果性能显然很低效

给stuno添加索引之后

给stuno和age添加联合索引

如果不遵循最佳左前缀,group by 性能将会比较低效

遵循最佳左前缀的情况如下

6、count 优化
count() 是一个聚合函数,对于返回的结果集,一行行判断,如果 count 函数的参数不是NULL,累计值就加 1,否则不加,最后返回累计值;
用法:count(*)、count(主键)、count(字段)、count(数字)
如下列举了count的几种写法的详细说明
| 用法 | 说明 |
| count(主键) | InnoDB 会遍历整张表,把每一行的主键id值都取出来,返回给服务层,服务层拿到主键后,直接按行进行累加(主键不可能为null); |
| count(*) | InnoDB不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加; |
| count(字段) | 没有not null 约束 : InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加,有not null 约束:InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加; |
| count(数字) | InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加; |
经验值总结
按照效率排序来看,count(字段) < count(主键 id) < count(1) ≈ count(*),所以尽量使用 count(*)
Hibernate - HQL_QBC查询详解--抓取策略优化机制
Hibernate 的查询方式
在 Hibernate 中提供了很多种的查询的方式。Hibernate 共提供了五种查询方式。
1、Hibernate 的查询方式:OID 查询
OID检索:Hibernate根据对象的OID(主键)进行检索。
① 使用 get 方法
Customer customer = session.get(Customer.class,1l);
② 使用 load 方法
Customer customer = session.load(Customer.class,1l);
2、Hibernate 的查询方式:对象导航检索
对象导航检索:Hibernate根据一个已经查询到的对象,获得其关联的对象的一种查询方式。
LinkMan linkMan = session.get(LinkMan.class,1l); Customer customer = linkMan.getCustomer(); Customer customer = session.get(Customer.class,2l); Set<LinkMan> linkMans = customer.getLinkMans();
3、Hibernate 的查询方式:HQL 检索
HQL查询:Hibernate Query Language,Hibernate的查询语言,是一种面向对象的方式的查询语言,语法类似SQL。通过session.createQuery(),用于接收一个HQL进行查询方式。
在进行 HQL 查询之前,先做一些准备。首先,新建一个 Java 项目,在项目里面新建一个文件夹,命名为 lib,并将上一个项目用到的包复制过来,添加的构建路径中去 。把工具类和配置文件拷贝过来。
① 初始化数据
package com.itheima.hibernate.demo1; import java.util.Arrays; import java.util.List; import org.hibernate.Query; import org.hibernate.Session; import org.hibernate.Transaction; import org.junit.Test; import com.itheima.hibernate.domain.Customer; import com.itheima.hibernate.domain.LinkMan; import com.itheima.hibernate.utils.HibernateUtils; /** * HQL的查询方式的测试类 * * @author jt * */ public class HibernateDemo1 { @Test /** * 初始化数据 */ public void demo1() { Session session = HibernateUtils.getCurrentSession(); Transaction tx = session.beginTransaction(); // 创建一个客户 Customer customer = new Customer(); customer.setCust_name("李向文"); for (int i = 1; i <= 10; i++) { LinkMan linkMan = new LinkMan(); linkMan.setLkm_name("王东" + i); linkMan.setCustomer(customer); customer.getLinkMans().add(linkMan); session.save(linkMan); } session.save(customer); tx.commit(); }
3.1、HQL 的简单查询
/** * HQL的简单查询 */ public void demo2() { Session session = HibernateUtils.getCurrentSession(); Transaction tx = session.beginTransaction(); // 简单的查询 // 返回一个 Query 的接口,而且支持链式写法 Query query = session.createQuery("from Customer"); List<Customer> list = query.list(); // sql中支持*号的写法:select * from cst_customer; 但是在HQL中不支持*号的写法。 /* * Query query = session.createQuery("select * from Customer");// 报错 * List<Customer> list = query.list(); */ // 再打印的时候,会默认调用对象的 toString(),两边不要都 toString(),都设置的话,其实就是一个死循环 // 为什么呢?因为你客户里面有联系人的集合,它需要把联系人给打印了;联系人那边呢,又有客户;客户又有联系人... // 这样的话就是一个死循环,所以在 toString() 的时候,把集合先去掉;打印先不打印集合,只是单纯的去看客户的一些数据 // 这里一定需要注意,除了客户的打印,像你 JSON 的转换,两边互相与对象的时候,JSON 一转换,它也是一个死循环。 for (Customer customer : list) { System.out.println(customer); } tx.commit(); }
需要注意的是“from customer”这里是一个对象,正常的写法应该是带包名的;但是在映射里面已经配置的包了,所以这个地方可以省略。一定要注意 ,这个地方是类名,而不是你的表名。
3.2、HQL 的别名查询
@Test /** * 别名查询 */ public void demo3() { Session session = HibernateUtils.getCurrentSession(); Transaction tx = session.beginTransaction(); // 别名的查询 /* * Query query = session.createQuery("from Customer c"); List<Customer> * list = query.list(); */ // 支持.属性的写法,但是需要注意的是 ,这种方式得到的 list 里面放的就不是一个对象了 Query query = session.createQuery("select c from Customer c"); List<Customer> list = query.list(); for (Customer customer : list) { System.out.println(customer); } tx.commit(); }
3.3、HQL 的排序查询
它跟 SQL 语句很类似的,所以再做排序查询的时候跟 SQ L也是很相似的。
里面也可以使用 order by,后面跟的是类里面的属性名,默认情况下就是升序的。
@Test /** * 排序查询 */ public void demo4() { Session session = HibernateUtils.getCurrentSession(); Transaction tx = session.beginTransaction(); // 排序的查询 // 默认情况 // List<Customer> list = session.createQuery("from Customer order by // cust_id").list(); // 设置降序排序 升序使用asc 降序使用desc List<Customer> list = session.createQuery("from Customer order by cust_id desc").list(); for (Customer customer : list) { System.out.println(customer); } tx.commit(); }
3.4、HQL 的条件查询
支持两种条件查询的方式,
@Test /** * 条件查询 */ public void demo5() { Session session = HibernateUtils.getCurrentSession(); Transaction tx = session.beginTransaction(); // 条件的查询 // 一、按位置绑定:根据参数的位置进行绑定。 // 一个条件 /* * Query query = session.createQuery("from Customer where cust_name = ?" * ); query.setParameter(0, "李兵"); List<Customer> list = query.list(); */ // 多个条件 /* * Query query = session.createQuery( * "from Customer where cust_source = ? and cust_name like ?"); * query.setParameter(0, "小广告"); query.setParameter(1, "李%"); * List<Customer> list = query.list(); */ // 二、按名称绑定,名称随便起 Query query = session.createQuery("from Customer where cust_source = :aaa and cust_name like :bbb"); // 设置参数: query.setParameter("aaa", "朋友推荐"); query.setParameter("bbb", "李%"); List<Customer> list = query.list(); for (Customer customer : list) { System.out.println(customer); } tx.commit(); }
3.5、HQL 的投影查询
投影查询:查询对象的某个或某些属性。
@Test /** * 投影查询 */ public void demo6() { Session session = HibernateUtils.getCurrentSession(); Transaction tx = session.beginTransaction(); // 投影查询 // 单个属性,封装的是对象
// 返回一个 list,但里面装的是一个字符串类型的值。Object 可以强转称字符串 /* * List<Object> list = session.createQuery( * "select c.cust_name from Customer c").list(); for (Object object : * list) { System.out.println(object); } */ // 多个属性,封装的是对象的数组
// list 集合里面放置的是一个 Object 数组,不同类型的值要想通用,只能放到一个数组之中 /* * List<Object[]> list = session.createQuery( * "select c.cust_name,c.cust_source from Customer c").list(); for * (Object[] objects : list) { * System.out.println(Arrays.toString(objects)); } */ // 查询多个属性,但是我想封装到对象中。 List<Customer> list = session.createQuery("select new Customer(cust_name,cust_source) from Customer").list(); for (Customer customer : list) { System.out.println(customer); } tx.commit(); }
4、Hibernate 的查询方式:QBC 检索
5、Hibernate 的查询方式:SQL 检索
以上是关于MySqlmysql 常用查询优化策略详解的主要内容,如果未能解决你的问题,请参考以下文章