Young GC过于频繁
Posted 码海拾贝2023
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Young GC过于频繁相关的知识,希望对你有一定的参考价值。
背景知识 (background)
Young GC过于频繁,主要有以下影响:
- GC线程消耗的CPU时间过多,容易触发Linux CFS 限制进程的CPU
- 虽然单次GC停顿较短,但频次高了之后,整个服务的吞吐量会下降
- GC过于频繁,慢请求产生的临时对象经过几轮YoungGC后容易晋升到老年代
目前YoungGC一分钟超过60次,则会触发报警,建议控制在20次/分钟以内。
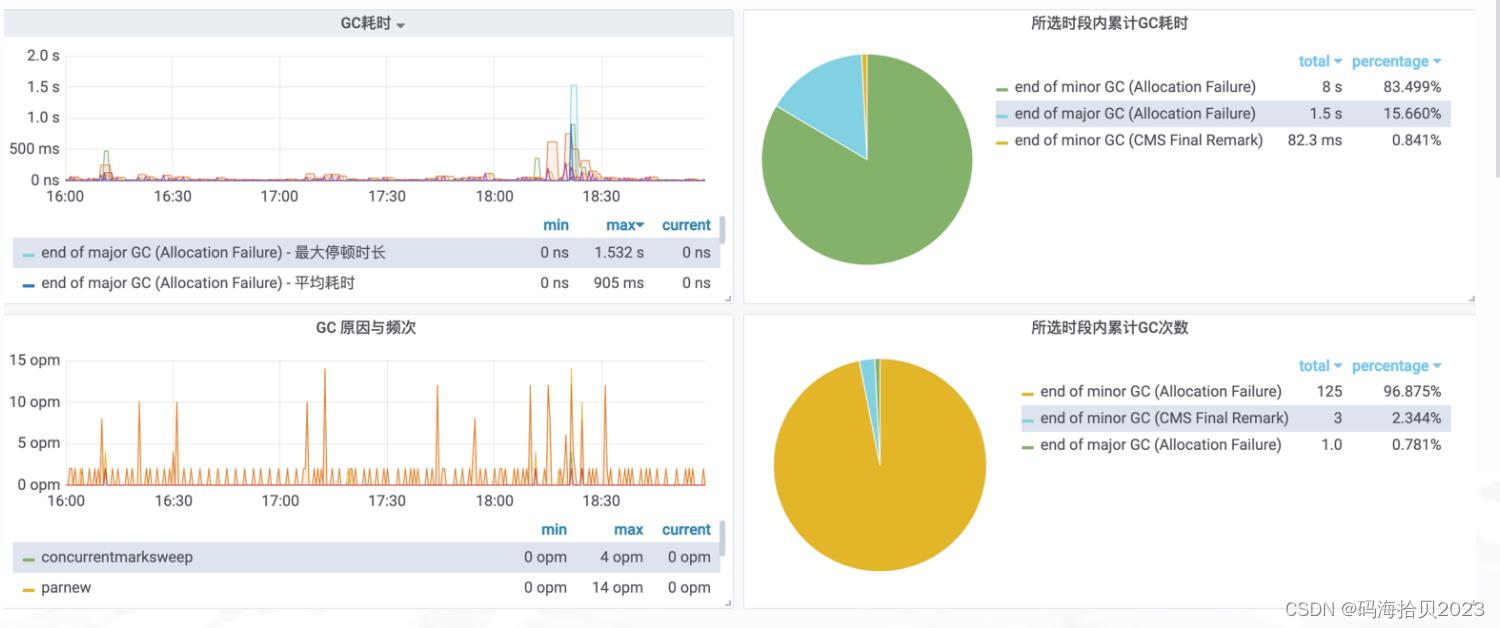
查看指标 (dashboard)
展开: JVM / 内存 / GC / ClassLoader这一行,找到监控面板:GC耗时 和 GC原因与频次。
止损措施 (action)
Young GC频繁,通常不用立即处理,大多需要优化代码。
不同物理机的配置、性能各异,若因CPU限制导致长尾请求集中在某个节点上,可先摘流。
事后改进(postmortem)
Young GC过于频繁,说明JVM内存分配压力大,可能是Young区比较小或者代码加载到内存的数据过多。
可参考原因部分,优化代码,调整GC参数。
尽量一次调整一个GC参数,灰度观察,排除干扰数据
可能的原因 (cause)
YoungGC频繁一般是内存问题,在优化代码降低频率的同时,也需关注某个时间段的累计耗时。总的来说,在CPU Quota允许的范围内,GC总耗时越少越好,GC频率反倒不是那么重要。
一、Eden区过小
g1 newSizePercent
二. 大批量加载数据。
三. 内存分配速率过高
代码原因导致的数据加载过多,常见于:
- 文件上传下载、报表导入导出
- 数据量随业务发展突增,代码没有分页或没有限制分页大小,或部分请求参数组合导致返回了大量数据
- 业务逻辑涉及的内存全量加载到内存里计算,不复用中间结果,相同的数据重复请求
- Redis缓存了大List,导致序列化/反序列化临时对象过多
JVM:30 实验:模拟频繁Young GC的场景
1. 程序的JVM参数示范
已知,平时系统运行创建的对象,除非是那种大对象,否则通常来说都是优先分配在新生代中的Eden区域的。
而且新生代还有另外两块Survivor区域,默认Eden区域占据新生代的80%,每块Survivor区域占据新生代的10%。
比如我们用以下JVM参数来运行代码:
-XX:NewSize=5242880 -XX:MaxNewSize=5242880 -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10485760 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
上述参数都是基于JDK 1.8 版本来设置的,不同的JDK版本对应的参数名称是不一样的,但是基本意思一致。
上面 “-XX:InitialHeapSize” 和 “-XX:MaxHeapSize” 就是初始堆大小和最大对大小, “-XX:NewSize” 和“-XX:MaxNewSize” 是初始新生代大小和最大新生代大小,“-XX:PretenureSizeThreshold=10485760 ” 指定了大对象阈值是10MB。
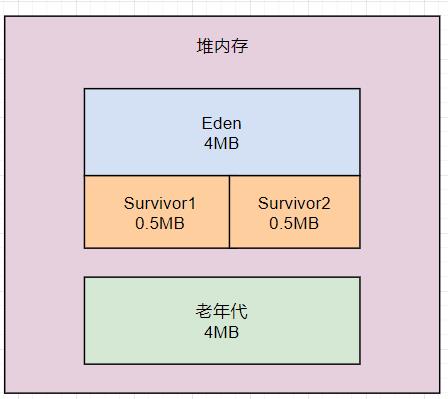
相当于给堆内存分配10MB内存空间,其中新生代是5MB内存空间,其中Eden区占4MB,每个Survivor区占0.5 MB,大对象必须超过10MB才会直接进入老年代,年轻代使用 ParNew垃圾回收器,老年代使用CMS垃圾回收器,如下图:
2. 如何打印出JVM GC日志?
我们需要在系统的JVM参数中加入GC日志的打印选型,如下所示:
- -XX:+PrintGCDetails: 打印详细的GC日志
- -XX:+PrintGCTimeStamps:这个参数可以打印出来每次GC发生的时间
- -Xloggc:gc.log:这个参数可以设置将GC日志写入一个磁盘文件
加上这几个参数后,JVM参数如下所示:
-XX:NewSize=5242880 -XX:MaxNewSize=5242880 -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10485760 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log
3. 示例程序代码
以下是当前的示例程序代码:
public class Demo1 {
public static void main(String[] args){
byte[] array1 = new byte[1024 * 1024];
array1 = new byte[1024 * 1024];
array1 = new byte[1024 * 1024];
array1 = null;
byte[] array2 = new byte[2 * 1024 * 1024];
}
}
4.对象是如何分配在Eden区内的
上面的这段代码,先通过 “new byte[1024 * 1024]” 这样的代码连续分配了3个数组,每个数组都是1MB。
然后通过array1这个局部变量依次引用这三个对象,最后还把array1这个局部变量指向了null。
那么在JVM中上述代码是如何运行的呢?
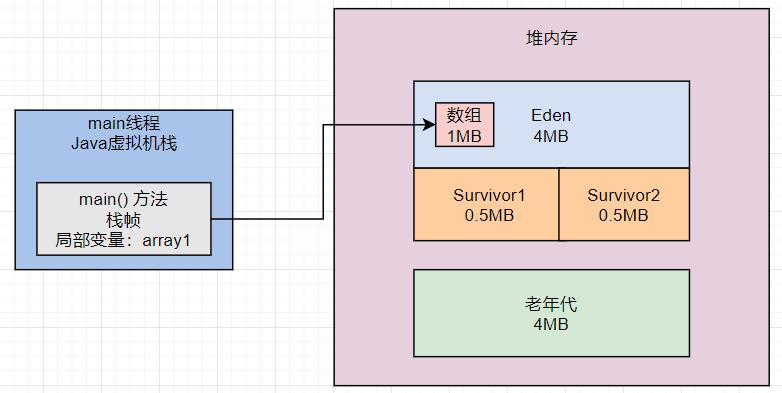
首先看第一行代码: byte[] array1 = new byte[1024 * 1024]; 。
这行代码一旦运行,就会在JVM的Eden区内放入一个1MB的对象,同时在main线程的虚拟机栈中会压入一个 main() 方法的栈帧,在 main() 方法的栈帧内部,会有一个“array1” 变量,这个变量是指向堆内存 Eden 区的那个1MB的数组,如下图。
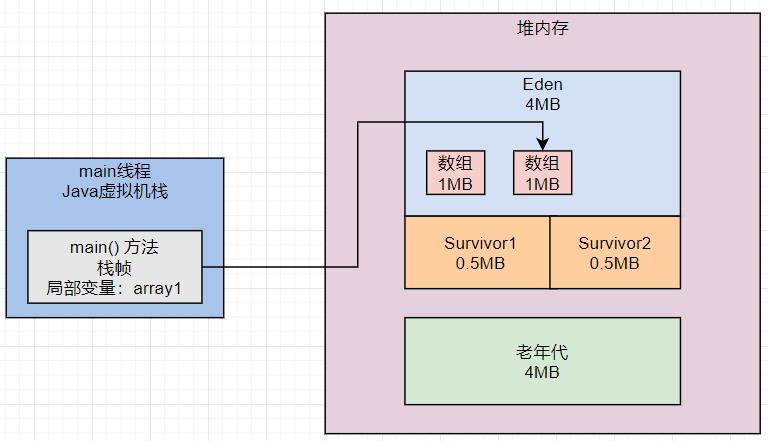
接着看第二行代码: array1 = new byte[1024 *1024];。
此时会在堆内存的Eden区中创建第二个数组,并且让局部变量指向第二个数组,然后第一个数组就没人引用了,此时第一个数组就成了没人引用的 “垃圾对象”了,如下图所示。
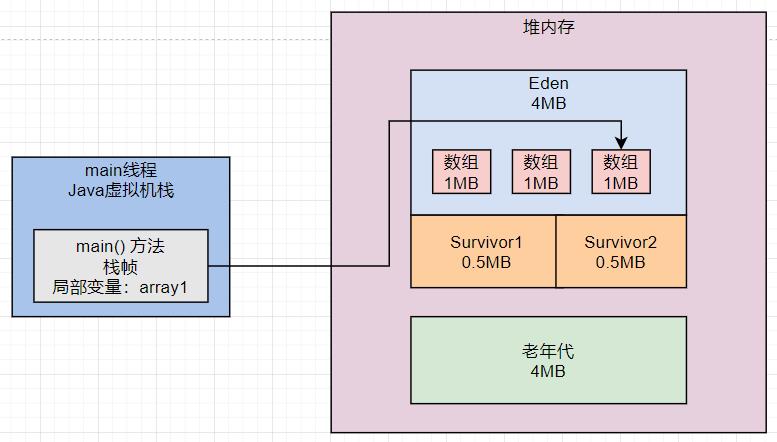
然后看第三行代码: byte[] array1 = new byte[1024 * 1024];。
这行代码在堆内存的Eden区内创建了第三个数组,同时让 array1 变量指向了第三个数组,此时前面两个数组都没有人引用了,就都成了垃圾对象,如下所示:
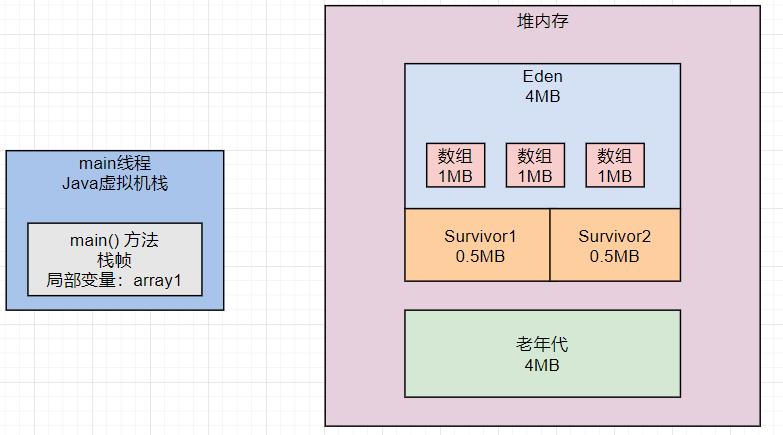
接着我们来看第四行代码: array1 = null;。
这行代码一致性,就让 array1 这个变量什么都不指向了,此时会导致之前创建的3个数组全部变成垃圾对象,如下图:
最后看第五行代码: byte[] array2 = new byte[2 * 1024 *1024];。
此时会分配一个2MB大小的数组,尝试放入Eden区中。
而这个时候 Eden 区明显是放不下的,因为Eden区总共就 4MB大小,而且里面已经放入了 3个 1MB的数组了,所以剩余空间只有 1MB了,此时你放一个 2MB的数组是放不下的。
所以这个时候就会触发年轻代的 Young GC。
5. 采用指定 JVM 参数运行程序
在 Eclipse等开发工具里如何以指定 JVM 参数运行程序,就是对你的程序右键,然后选择 “Run As -> Run Configurations” ,接着在下图中填入对应的JVM参数:
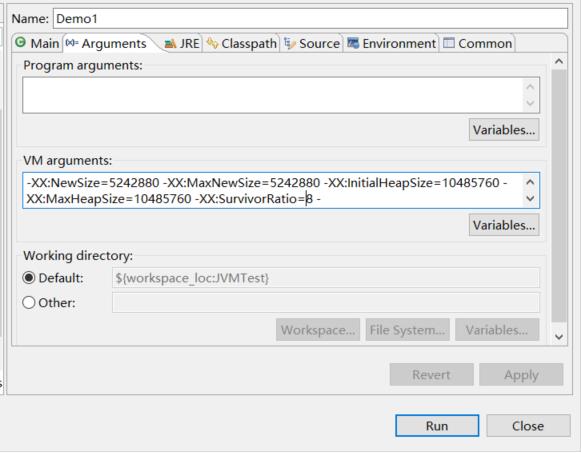
然后运行即可,此时运行完毕后,会在下述工程目录中出现一个 gc.log 文件,里面就是本次程序运行的 gc 日志,如下图所示:
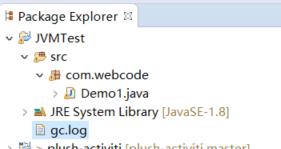
打开gc.log文件,就会看到如下所示的gc日志:
Java HotSpot(TM) 64-Bit Server VM (25.111-b14) for windows-amd64 JRE (1.8.0_111-b14), built on Sep 22 2016 19:24:05 by "java_re" with MS VC++ 10.0 (VS2010)
Memory: 4k page, physical 16192480k(8225436k free), swap 24925816k(12234880k free)
CommandLine flags: -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:MaxNewSize=5242880 -XX:NewSize=5242880 -XX:OldPLABSize=16 -XX:PretenureSizeThreshold=10485760 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:SurvivorRatio=8 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:-UseLargePagesIndividualAllocation -XX:+UseParNewGC
0.112: [GC (Allocation Failure) 0.112: [ParNew: 3930K->512K(4608K), 0.0016424 secs] 3930K->551K(9728K), 0.0018267 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
par new generation total 4608K, used 2601K [0x00000000ff600000, 0x00000000ffb00000, 0x00000000ffb00000)
eden space 4096K, 51% used [0x00000000ff600000, 0x00000000ff80a558, 0x00000000ffa00000)
from space 512K, 100% used [0x00000000ffa80000, 0x00000000ffb00000, 0x00000000ffb00000)
to space 512K, 0% used [0x00000000ffa00000, 0x00000000ffa00000, 0x00000000ffa80000)
concurrent mark-sweep generation total 5120K, used 39K [0x00000000ffb00000, 0x0000000100000000, 0x0000000100000000)
Metaspace used 2651K, capacity 4486K, committed 4864K, reserved 1056768K
class space used 286K, capacity 386K, committed 512K, reserved 1048576K
初步分析日志结果:
- 老年代5MB空间大于3MB,可以直接Young GC,3M垃圾直接回收,Eden区清空,S1、S2也清空。但根据日志,实际上from space是占满了。这里很疑惑
- 根据日志,发现确实进行了一次Young GC。具体日志:0.112: [GC (Allocation Failure) 0.112: [ParNew: 3930K->512K(4608K), 0.0016424 secs] 3930K->551K(9728K), 0.0018267 secs] [Times: user=0.00 sys=0.00, real=0.00 secs] 日中Allocation Failure表明了GC的原因(连续内存空间不足,内存空间分配失败),和具体的回收情况,可以看到内存空间被释放出来了,但却不是全部释放(可以看到原本的空间是 3930K,而不是三个数组的3072)
- 从第二点可以看出,第一次Young GC只有,有512k的存活,这0.5M的未被回收的内存正好对上了 from space 占满的0.5MB。
以上是关于Young GC过于频繁的主要内容,如果未能解决你的问题,请参考以下文章