如何从0搭建自己的自动化测试体系
Posted 自动化测试馆长
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何从0搭建自己的自动化测试体系相关的知识,希望对你有一定的参考价值。
1. 需求和目标
在我开展自动化测试之前,其实该项目以前的测试人员也已经写了很多的接口测试用例,但是大多数用例处于“半瘫痪”状态,在CI上无人维护(听说起初是有人维护的,但是后来用例多了,维护的人每次花很长时间去定位问题,结果却发现大部分的问题都是环境问题导致,花了半天时间定位却没什么收益,久而久之便不想去维护)。看起来,自动化似乎并没有什么收益,反而维护用例会造成额外的工作负担。
我觉得,其实自动化测试跟其它任何一种测试类型(比如异常测试、稳定性测试、性能测试等)都是类似的,它也是一种测试类型而已。在开展测试之前,我们首先必须要明确自动化测试的需求是什么,要解决什么样的问题。
1.1 让“自动化”代替“手动”
在我看来,初期的自动化测试,我的目标很明确,我就是要让“自动化”代替“手动”,让自动化真正地跑起来,凡是“自动化”跑过的内容,我绝不再去手工重复执行一遍。这样至少我有一个很明确的收益:每完成一条自动化用例,我减少了一条手工用例的执行时间。
必须要提醒的是,让“自动化”完全替代“手动”,其实对自动化用例的稳定性、容错都有一定的要求。你要花一定时间去思考用例执行过程中的异常场景,是否足以充分替代手工测试。因此,我在增加用例的时候都会非常谨慎,确保用例集是稳定100%通过的前提下才会增加新的用例。
对于正常情况下(排除环境、开发代码的问题)有时100%通过,有时90%通过的自动化用例集,我觉得它的作用和参考价值为0。正常的用例集就应该是100%通过的。
1.2 让“回归”自动化
上面说了让“自动化”替代“手动”,每完成一条自动化用例都是有明显收益的。那如何让收益最大化呢,当然是让每次回归或上线验证“不得不”执行的用例优先自动化。如果完成了回归用例集的全部自动化,那我就可以用它来替代我的日常回归,和上线回归工作,极大地释放我的手工验证时间。
这里必须要指出的是,我跟的项目其实是一个对系统稳定性的要求要高于新功能的引入的一个后台项目,所以它的核心功能是比较固定的,其实大多数后台项目也是类似的,核心功能聚合、对系统的稳定性要求高。这就需要保障系统的核心功能完善。所以我们可以先将“核心功能”的验证完成自动化。
1.3 不要让环境成为瓶颈
前面说了,旧的用例集在维护的过程中给测试人员增加了很多额外的负担,到最后发现很多都是环境的问题。当时的情形就是专门搭建了另一套测试环境专门用于自动化测试,而大数据的后台环境搭建和维护非常的复杂,如果同时维护多套环境,难免会在一些组件升级的过程中出现遗漏,导致环境不同步。因此,我们的自动化测试用例前期完全可以直接在功能测试环境执行,因为功能测试环境肯定是会一直随着版本的迭代向前不断更新的。
2. 技术选型
在明确了目标后,要开始技术选型。常见的自动化测试类型,包括
接口自动化
UI自动化
基于shell交互命令执行的自动化
此外,不属于测试范畴,但是也可以实现自动化、释放手工时间的还有
数据准备自动化
环境编译、部署、打包自动化
稳定性测试/性能测试结果指标获取、校验自动化
机器资源监控、报警自动化
其它所有手工重复执行的操作
在开始自动化之前,首先要分析项目的架构和状况。对于一个后端的服务,它如果是纯粹以接口的形式提供给其它组件去调用,那可以采取“接口自动化”;对于一个Web产品,如果前后端都在测试的保障范围,而且前端页面相对比较稳定,可以考虑采用“UI自动化”(此时接口自动化其实已经不足以保障产品的端到端功能);对于更后端的组件,如果想测试组件自身的基础核心功能,可以采用“基于shell交互命令执行的自动化”,通过自动化脚本的方式封装shell命令的调用。
此外,有些人可能还会执着于编程语言的选择,是用Java还是Python还是Shell,或者其它语言等等。这个我觉得其实没有定论,可以根据自己对语言的偏好和熟练程度,但是必须要考虑团队成员的普遍技术栈,因为后期可能其他人来接手这个项目时需要代替你去维护测试工程。通常来说,测试框架的选择(不管是接口自动化、UI自动化)推荐使用Java的TestNG框架;对于简单的基于命令行执行的自动化脚本的编写推荐使用Shell(Shell非常地强大);对于稍复杂的一些自动化的脚本的编写,推荐使用Python,在Python中可以非常方便地封装Shell命令,同时Python区别于Shell的一个特性就是它支持面向对象的封装,可以将一些对象封装在特定的类中,增加程序的可读性和健壮性。
这里再插一段题外话:有些人可能会疑惑,现在其实有很多接口测试平台,测试人员可以直接在平台上完成接口测试,在选型时怎么抉择?——这里我不评价哪种方式更好,只想说下自己的看法:我觉得两种其实各有各的好处:
编写代码的方式:
优点:提升自己的编码能力,问题定位能力,具备更高的灵活性和可操作性。缺点:结果展示不直观,不易于协作。其他人维护代码困难,难以推动开发执行。
接口平台的方式:
优点:简便,上手容易,可以在项目组间很好的协作和维护,测试记录和结果一目了然。缺点:离开了平台,可能又要回归手动。
对于测试人员而言,如果有精力和时间的话,我建议是两种都要掌握,甚至是自己去开发接口测试平台的能力。
3. 自动化实施过程
目前我跟的项目里已经实现自动化的内容包括:基于接口的场景回归自动化测试、编译部署过程自动化、Jacoco覆盖率统计并接入CR平台(代码变更分析平台)的自动化、对外/上线打包发布的自动化、稳定性测试结果校验的自动化。
下面着重介绍下项目的接口自动化框架的搭建和设计过程。
3.1 准备工作
老生常谈,开始自动化前,我仍然想再次强调一定要明确自己的需求是什么。在我的项目里,我的需求主要有以下几点:
同一份代码可以在多个集群执行
各个集群的测试数据相互独立,不会互相影响
可以方便地与数据库进行交互
当用例执行出错时,有详细的日志帮助定位
较好的可维护性和集群扩展性。
3.2 框架搭建
3.2.1 环境搭建
环境搭建时,主要用了以下工具:
Git:管理代码工程
TestNG:作为测试框架
Maven:管理依赖包
Log4j:管理日志
Hibernate:实现数据库交互
HttpClient:实现请求发送
之所以没有用MyBatis,觉得相对来说,MyBatis是一个半ORM的框架,它需要自己额外维护一份sql映射文件,而Hibernate是全ORM的,可以省去这一步。关于它俩的比较,大家可以参考下知乎的一篇文章:MyBatis和Hibernate的对比。对于JDBC的方式,当然它也可以访问数据库,只不过相对来说,使用ORM框架可以更贴近面向对象的编程方式。
3.2.2 不同集群配置管理
在实现过程中,因为不同的集群会有不同的配置,比如webserver host、登陆后台webserver的用户名/密码、公共账号信息、数据库信息等等。为了让一份代码可以在不同集群去共用,就必须把这些配置信息从代码中剥离出来。可以用配置文件的形式来统一管理集群的配置信息,如图所示:
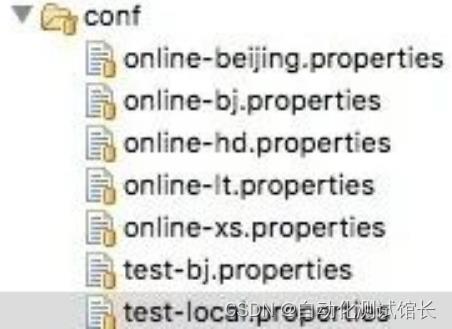
每个文件代表一个集群的配置。在代码中可以通过java.util.Properties类读取配置文件的方式载入各项配置信息:
/**
* 根据指定的配置文件名,初始化配置
* @param configFile
* @throws IOException
*/
public PropertiesUtil(String configFile) throws IOException
this.configFile =DEFAUL_CONFIG_FILE_DIRECTORY + configFile;
InputStream fis = new FileInputStream(this.configFile);
props = new Properties();
props.load(fis);
//关闭资源
fis.close();
/**
* 根据key值读取配置的值
* @param key key值
* @return key 键对应的值
* @throws IOException
*/
public String readValue(String key)
return props.getProperty(key);
/**
* 读取properties的全部信息
* @throws FileNotFoundException 配置文件没有找到
* @throws IOException 关闭资源文件,或者加载配置文件错误
*
*/
public Map<String,String> readAllProperties()
//保存所有的键值
Map<String,String> map=new HashMap<String,String>();
Enumeration<?> en = props.propertyNames();
while (en.hasMoreElements())
String key = (String) en.nextElement();
String property = props.getProperty(key);
map.put(key, property);
return map;
到这里,解决了配置读取的问题,还需要解决代码运行时如何让它自己去选择正确的集群配置文件的问题。我是将选择配置文件的逻辑全部封装到了一个工厂类BaseConfigFactory.java中,在实际测试使用时,我只需要通过工厂类的静态方法BaseConfigFactory.getInstance()去获取想要的配置信息,而不需要关心它到底是如何去选择正确的配置文件的。工厂类的实现可以参考:
public class BaseConfigFactory
private static final String testEnv= System.getenv("TEST_ENV") == null ? "null" : System.getenv("TEST_ENV");
private static Logger logger = Logger.getLogger(BaseConfigFactory.class);
private static BaseConfig baseConfig;
private static HashMap<String, String> clusterConfigMap;
public static synchronized BaseConfig getInstance()
if (null == baseConfig)
PropertyConfigurator.configure("log4j.properties");
initMap();
setupConfig();
return baseConfig;
public static void initMap()
clusterConfigMap = new HashMap<>();
clusterConfigMap.put("TEST-BJ", "test-bj.properties");
clusterConfigMap.put("ONLINE-BJ", "online-bj.properties");
clusterConfigMap.put("ONLINE-XS", "online-xs.properties");
clusterConfigMap.put("ONLINE-LT", "online-lt.properties");
clusterConfigMap.put("ONLINE-BEIJING", "online-beijing.properties");
clusterConfigMap.put("ONLINE-HD", "online-hd.properties");
clusterConfigMap.put("null", "test-local.properties");
public static void setupConfig()
logger.info("TEST ENV: " + testEnv);
String propertyFile = clusterConfigMap.get(testEnv);
logger.info("Using '" + propertyFile + "' as property file.");
baseConfig = new BaseConfig(propertyFile);
即,将所有的集群的配置放入到一个Map中,然后通过读取环境变量TEST_ENV的值来选取具体的集群配置文件clusterConfigMap.get(testEnv)。
3.2.3 log4j日志管理
良好的日志输出是帮助定位问题的关键环节,尤其是定位服务器上执行时出现的问题。这边贴一个log4j的配置:
### set log levels ###
log4j.rootLogger = debug, stdout, D, E
### 输出到控制台 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%dyyyy/MM/dd HH:mm:ss.SSS Z %p [%c1] [Thread-%t] %m%n
### 输出到日志文件 ###
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = logs/console.log
log4j.appender.D.Append = true
##输出Debug级别以上的日志##
log4j.appender.D.Threshold = INFO
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern=%dyyyy/MM/dd HH:mm:ss.SSS Z %p [%c1] [Thread-%t] %m%n
### 保存异常信息到单独文件 ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
##异常日志文件名##
log4j.appender.E.File = logs/error.log
log4j.appender.E.Append = true
##只输出ERROR级别以上的日志##
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern=%dyyyy/MM/dd HH:mm:ss.SSS Z %p [%c1] [Thread-%t] %m%n
##Hibernate日志级别设置
log4j.logger.org.hibernate.ps.PreparedStatementCache=WARN
log4j.logger.org.hibernate=ERROR
# Changing the log level to DEBUG will result in Hibernate generated
# SQL to be logged.
log4j.logger.org.hibernate.SQL=ERROR
# Changing the log level to DEBUG will result in the PreparedStatement
# bound variable values to be logged.
log4j.logger.org.hibernate.type=ERROR
该配置将INFO级别和ERROR级别的日志分别定位输出到不同的文件,且日志文件会按照日期进行自动归档,输出的格式包含了日志的日期、级别、类信息、线程信息、日志内容等。
一般情况下,对于接口测试,当接口测试用例失败时,我们要打印的日志包括:请求的url、参数、方法、实际响应、期望响应等等。
3.3 分层设计、解耦
首先看一下项目的工程目录:
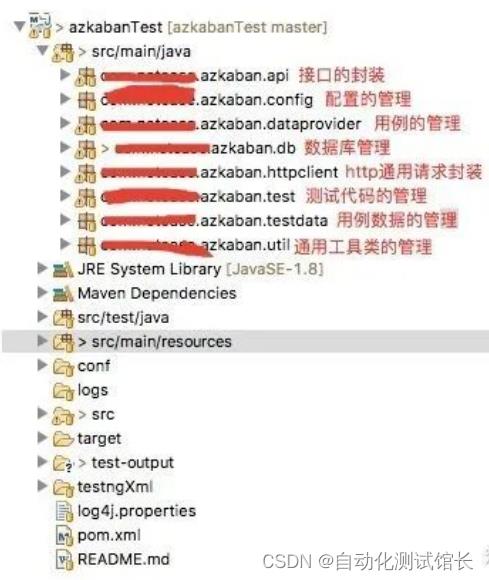
可以看到,项目中包含了多个package,各个package的作用已经在图片中标示了。以前好多测试人员的习惯是将api代码的调用、测试方法的编写、data Provider的编写、测试数据的构造全部写在一个类文件中,这样做其实会有几个问题:
可读性差
代码复用性低
维护性差
难以调试
耦合带来的其它各类问题
此外,如果不同集群的测试数据不同,会有大量的if判断,结果是灾难性的。
下面以一个用例为例,展示代码的结构:
测试api:
public class ScheduleApi extends BaseAzkabanApi
...
...
/**
* 使用默认公共账号、email、失败策略、sla报警邮箱新增正常调度。
* @param projectName
* @param flow
* @param projectId
* @param scheduleTime
* @param scheduleDate
* @param period
* @return
*/
public ResponseCode addNormSched(String projectName, String flow, String projectId, String scheduleTime, String scheduleDate,String period)
return scheduleFlow(projectName, flow, projectId, scheduleTime, scheduleDate, defaultProxyUser, defaultProxyEmail, period, defaultSlaEmail);
...
...
测试代码test:
@Test(singleThreaded=true)
public class ScheduleTest
...
...
/**
* 新增正常调度
* @param projectName
* @param flow
*/
@Test(priority=1, dataProvider="addNormSched", dataProviderClass=ScheduleDataProvider.class, testName="1410356")
public void addNormSched(String projectName, String flow, String expectedStatus, String hasScheduleId, String message)
ResponseCode rc= scheduleApi.addNormSched(projectName, flow);
Assert.assertEquals(rc.getStatus(), expectedStatus, message+rc.getDebugInfo("返回结果中的状态status对应值"));
Assert.assertEquals(rc.hasProperty("scheduleId"), Boolean.parseBoolean(hasScheduleId), message+rc.getDebugInfo("返回结果中是否包含scheduleId"));
...
...
测试用例dataProvider:
public class ScheduleDataProvider
@DataProvider(name = "addNormSched", parallel=true)
public static Object [][] addNormSched()
return new Object[][]
ScheduleTestData.validNormSchedule,
ScheduleTestData.notExistedProject,
ScheduleTestData.notExistedFlow
;
...
...
测试数据testdata:
public class ScheduleTestData extends BaseTestData
...
...
//Testdata for addNormSched
public static Object[] validNormSchedule=VALID_PROJECT_NAME, VALID_NORMAL_SCHEDULE_FLOW, "success", "true", "设置有效的正常调度";
public static Object[] notExistedProject=NOT_EXIST_PROJECT_NAME, VALID_NORMAL_SCHEDULE_FLOW, "error", "false", "不存在的project";
public static Object[] notExistedFlow=VALID_PROJECT_NAME, NOT_EXIST_FLOW_NAME, "error", "fasle", "不存在的flow";
...
...
可以看到,用例的测试代码test类是非常简洁的,只要调用api类封装的接口,然后进行assert判断即可。
关于测试数据,将dataprovider与testdata进行分离,也是为了后续可能会灵活地调整下架用例,只需要去除dataprovider类中的用例行即可,而testdata中的数据仍然可以留着复用。
另外,前面提到了不同集群测试数据的管理。再介绍下我这边的实现方式:
不同测试类使用的公共数据,存放于BaseTestData基类中,让其它testdata类继承于基类
不同集群可以共用的数据,尽量共用,以常量的方式存储于testdata类中
不同集群无法共用的数据,统一存放于特定的json文件管理
关于json文件管理数据,其实跟配置文件的管理类似,如下图所示:
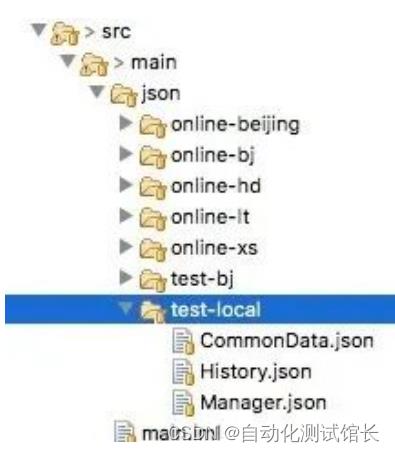
History.json:
"validTotalFetch":
"key":"",
"beginTime":"2017-06-30%2015:30",
"endTime":"2017-06-30%2015:50",
"expectedTotal":"7"
,
"validImmediatelyFetch":
"key":"instant_execute_job",
"beginTime":"2017-06-30%2013:30",
"endTime":"2017-06-30%2013:40",
"expectedTotal":"1"
,
"validScheduledFetch":
"key":"online_schedule_job",
"beginTime":"2017-06-30%2014:30",
"endTime":"2017-06-30%2014:40",
"expectedTotal":"2"
3.4 改进与提升
在自动化的实施过程中,还遇到了一些问题可能对其它项目也会有一定的借鉴意义。这边罗列下几个我觉得比较有意思的问题。
3.4.1 webserver高可用的支持
我们的后台webserver是支持高可用的,所以每次运维上线后webserver的host可能会发生变化,以及在服务运行过程中也可能会发生webserver切换。如果每次去手动调整自动化用例的配置信息,是一件非常麻烦的事情。
解决的方式就是在配置文件中,将主从webserver的host都填写进去,在测试过程中,如果发生请求失败,则允许切换一次host。
3.4.2 用例并发执行
由于我们的一部分用例是异步的场景用例,需要执行一个数据开发的任务,然后等待其执行完成。这些用例的执行比较费时,如果顺序执行的话会消耗非常多的时间。因此可以通过并发执行测试的方式,解决用例耗时的问题。关于TestNG的并发可以参考这篇文章:《简单聊聊TestNG中的并发》
3.4.3 单例模式解决session问题和host重复切换问题
问题1: Azkaban的每个接口,都需要一个必传参数seesion。这个session可以通过/login接口获取。如果每个接口在执行的时候都去调用一次/login接口重新获取session,就会显得很冗余,也可能导致旧的session失效。
问题2: 上述提到的对webserver高可用的支持,当多条用例并行执行时如果同时去切换host,可能会造成host切换回原来的不可用host。
对于问题1,可以将session作为单例的方式进行存储。
对于问题2,可以借鉴单例模式的“双重检查”思想,对切换host的代码进行部分同步,在防止host重复切换的同时,不会降低httpclient请求的并发性。关于单例模式的应用可以参考这篇KS文章:《“单例模式”学习及其在优化接口自动化测试代码中的实践》
3.4.4 “变”与“不变”
其实这也是所有设计模式的基本思想,即区分自动化测试中的“可变因素”和“不变因素”。我觉得ycwdaaaa大神(飞哥)有两句话是非常棒的:
封装"一切"可能的可控的变化因素
为了稳定使尽"一切"手段
4. 结合研发过程的应用
上面介绍了一些自动化的实施过程,这边再介绍下实施之后在项目研发过程中的应用。
目前在项目中,主要有以下几方面的应用。
(1)提测后的自动化回归验收
下图是项目的一条持续集成pipeline。在开发提测后,我会自动化地完成以下事情:
编译代码
将服务部署到各个机器,并完成Jacocod Agent的部署
执行静态代码检查
执行接口测试
完成覆盖率统计
将覆盖率统计数据接入到CR平台
当自动化用例全部执行通过时,说明系统的核心功能回归没有问题,然后开始版本的细粒度功能的测试。
(2)Bug修复后的回归验收
在测试过程中,开发肯定会经常修复bug重新提交代码,每次有代码重新提交时,我都可以一键完成部署、测试、覆盖率统计。
(3)上线后的回归验证
目前,项目的上线验证已经完全由自动化验证来替代。
(4)作为开发冒烟的一部分(未完成)
目前已经跟开发达成一致,开发非常欢迎将自动化用例接入到开发环境,用于他们每次变更时的环境正确性验证,可以尽早帮助他们发现研发过程中出现的问题。并且在提测前,只有100%通过自动化测试才可以进行提测。
(5)线上监控
目前各个线上集群,都部署了自动化测试用例,这部分用例会每隔4小时执行一次。用于确保线上环境的稳定性。从效果上来看,线上监控的成效是非常明显的,提前发现了很多集群的延迟问题,环境问题等,让开发可以及时地收到报警,了解线上集群的情况。
(6)关于持续集成
可能有人会发现,上述的执行过程其实不是真正意义上的持续集成,真正意义上的持续集成应该是:每次开发提交代码,自动触发构建。
必须要承认的是,确实是如此。但是不管怎么样,我觉得可以先从优化测试工作量的角度慢慢去推开整个流程,其实业界目前也并没有确切的定论说只有持续集成才是最佳的实践。相反,一味地持续集成可能会增加我们的维护成本。只要我们能切实提升自己的工作效率,达到目的就可以了。
5. 成效
当自动化做的比较完善后,你真的会发现:生活原来可以变得如此简单美好。
自动编译部署:测试过程中开发修复bug提交代码是非常频繁的,每次的手动编译部署可能都会耗费十几分钟,并且测试人员的关注点还不能离开。
自动打包发布:从这个版本开始,所有集群的上线都会统一使用QA发布的包。这样减少了以前每次上线时,开发运维人员要花费大量的时间逐一去拉取各个集群的代码再进行编译、部署。一键的打包发布,可以在上线前就提前准备好各个集群的上线包,开发只需调用部署脚本去获取这些包,然后替换就可以完成上线。此外,自动打包发布的方式极大减少了运维上线时漏操作的风险。
自动化回归测试:以前一次回归测试,需要QA持续地投入超过30分钟。现在通过一键执行,程序会自动地执行,时间控制在5分钟以内。且QA可以将注意力放到其它事情上。
自动化完成稳定性测试结果的校验:从前执行完稳定性测试,需要对着数据库的一大片数据进行人肉地校验。会耗费一个下午大半天的时间,甚至还是有遗漏。通过脚本自动校验,1分钟内就可以出结果报告。
这里再提一下UI自动化。很多人会对UI自动化有看法,觉得投入产出比不明显、维护成本高。我认为UI自动化跟接口自动化其实没有区别,都是功能回归的一种形式而已,选择哪种自动化的类型应该取决于项目的实际情况需要。另外,UI自动化的维护成本目前一个季度做下来看,真的没有比接口自动化要高,关键还在于自动化的设计上是不是做的易于维护。
6. 展望
可以看到以上的自动化都是基于环境的稳定可用为前提的。之所以没有独立分配一套环境用于自动化测试,也是因为环境维护的成本较高。但是,基于测试人员的增加,测试类型的丰富(异常、性能),在一套环境上执行所有测试显然会出现相互影响的问题。因此,如果能将测试环境搭建docker化,通过维护docker镜像的方式,自动化地使用docker镜像快捷地部署一套新的完整测试环境可以极大地提高我们的测试效率。
以上是关于如何从0搭建自己的自动化测试体系的主要内容,如果未能解决你的问题,请参考以下文章