Redis热点数据处理
Posted xixingzhe2
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis热点数据处理相关的知识,希望对你有一定的参考价值。
1、概念
热点数据就是访问量特别大的数据。
2、热点数据引起的问题
流量集中,达到物理网卡上限。
请求过多,缓存分片服务被打垮。redis作为一个单线程的结构,所有的请求到来后都会去排队,当请求量远大于自身处理能力时,后面的请求会陷入等待、超时。根本原因在于读,不在写。
redis崩溃或热点数据过期,会有大量数据访问DB,造成DB崩溃,引起业务雪崩。
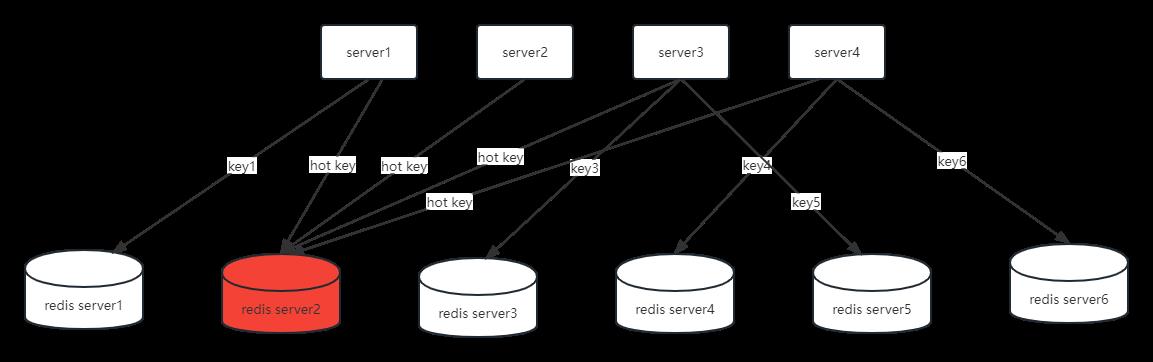
如上图,hot key即为热点数据,hot key的访问频次远大于其他key的使用。
3、如何排查热点key
3.1 排查标准
以redis访问key为例,我们可以很容易的计算出性能指标,譬如有1000台服务器,某key所在的redis集群能支撑20万/s的访问,那么平均每台机器每秒大概能访问该key200次,超过的部分就会进入等待。由于redis的瓶颈,将极大地限制server的性能。
而如果该key是在本地内存中,读取一个内存中的值,每秒多少个万次都是很正常的,不存在任何数据层的瓶颈。当然,如果通过增加redis集群规模的形式,也能提升数据的访问上限,但问题是事先不知道热key在哪里,而全量增加redis的规模,带来的成本提升又不可接受。
3.2 排查方法
3.2.1 凭借业务经验,进行预估哪些是热key
其实这个方法还是挺有可行性的。比如某商品在做秒杀,那这个商品的key就可以判断出是热key。缺点很明显,并非所有业务都能预估出哪些key是热key。
3.2.2 在客户端进行收集
这个方式就是在操作redis之前,加入一行代码进行数据统计。那么这个数据统计的方式有很多种,也可以是给外部的通讯系统发送一个通知信息。缺点就是对客户端代码造成入侵。
3.2.3 在Proxy层做收集
有些集群架构是下面这样的,Proxy可以是Twemproxy,是统一的入口。可以在Proxy层做收集上报,但是缺点很明显,并非所有的redis集群架构都有proxy。
3.2.4 用redis自带命令
(1)monitor命令,该命令可以实时抓取出redis服务器接收到的命令,然后写代码统计出热key是啥。当然,也有现成的分析工具可以给你使用,比如redis-faina。但是该命令在高并发的条件下,有内存增暴增的隐患,还会降低redis的性能。
(2)hotkeys参数,redis 4.0.3提供了redis-cli的热点key发现功能,执行redis-cli时加上–hotkeys选项即可。但是该参数在执行的时候,如果key比较多,执行起来比较慢。
3.2.5自己抓包评估
Redis客户端使用TCP协议与服务端进行交互,通信协议采用的是RESP。自己写程序监听端口,按照RESP协议规则解析数据,进行分析。缺点就是开发成本高,维护困难,有丢包可能性。
3.3 排查工具
可以使用京东的开源工具hotkey:https://gitee.com/jd-platform-opensource/hotkey
4、解决方案
4.1 二级缓存
利用ehcache或者HashMap或者guava cache都可以。在你发现热key以后,把热key加载到系统的JVM中。
针对这种热key请求,会直接从jvm中取,而不会走到redis层。假设此时有十万个针对同一个key的请求过来,如果没有本地缓存,这十万个请求就直接怼到同一台redis上了。
现在假设,你的应用层有50台机器,OK,你也有jvm缓存了。这十万个请求平均分散开来,每个机器有2000个请求,会从JVM中取到value值,然后返回数据。避免了十万个请求怼到同一台redis上的情形。
优点
读取速度快。
只需要改读取逻辑,不需要改写逻辑。
缺点
需要提前获知热点
缓存容量有限
不一致性时间增长
热点 Key 遗漏
4.2 增加数据副本
既然热点问题是因为某个key被大量访问导致的,那我们将这个Key的请求做下拆分不就行了。
假如hotkey的缓存是一个高频访问的数据,那么大量请求访问这个key时,就会出现压力都有redis server2这个节点来承担,这样redis server2节点就有可能会扛不住压力而罢工了。那么应该怎么解决这个问题呢?
不妨在缓存数据的时候,将这个数据在每个redis节点都缓存一份。而在缓存的时候,将key在程序层面进行加工,如变成hotkey#redis server1、hotkey#redis server2...hotkey#redis server6这样的6个key。此处我们假如这样的6个key会根据crc16算法,将这个6个key分别落在这6个节点之上。那么这样在访问的时候,我们就可以依然遵循这个规则获得一个key,这样一来,获取数据的时候,压力就被分散到不同的redis节点上了。
优点
可扩展,最高访问量和副本成正比。
缺点
每增加一个redis节点都会增加成本。
写入增加逻辑,读也要增加逻辑。
以上是关于Redis热点数据处理的主要内容,如果未能解决你的问题,请参考以下文章