Core Java 经典笔试题总结(数据类型,表达式问题)
Posted dashuai的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Core Java 经典笔试题总结(数据类型,表达式问题)相关的知识,希望对你有一定的参考价值。
2016-10-18 整理
写一个程序判断整数的奇偶


public static boolean isOdd(int i){ return i % 2 == 1; } 百度百科定义:奇数(英文:odd)数学术语 ,口语中也称作单数, 整数中,能被2整除的数是偶数,不能被2整除的数是奇数,奇数个位为1,3,5,7,9。偶数可用2k表示,奇数可用2k+1表示,这里k就是整数。奇数可以分为: 正奇数:1、3、5、7、9、11、13、15、17、19、21、23、25、27、29、31、33......... 负奇数:-1、-3、-5、-7、-9、-11、-13、-15、-17、-19、-21、-23.-25、-27、-29、-31、-33......... 奇数可以被定义为被2 整除余数为1 的整数。但是在 int 数值中,有一半都是负数,而 isOdd 方法对于对所有负奇数的判断都会失败。在任何负整数上调用该方法都回返回false ,不管该整数是偶数还是奇数。正确写法: public static boolean isOdd(int i){ return i % 2 != 0; } 用位操作符AND(&)来替代对2的取余操作符会更好,注意优先级。 public static boolean isOdd(int i){ return (i & 1) != 0; }
在jdk1.5+的环境下,如下4条语句,讨论互相==比较的输出结果
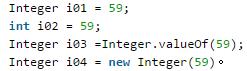
int i02=59; // 这是一个基本类型,存储在栈中。 Integer i01=59; // 调用 Integer 的 valueOf 方法,自动装箱。使用享元模式,看值是否在 [-128,127],且 IntegerCache 中是否存在此对象,如果存在,则直接返回引用,否则创建一个新的对象。因程序初次运行,没有 59 ,所以直接创建了一个新的对象 Integer i03 =Integer.valueOf(59); // 因为 IntegerCache 中已经存在此对象,所以,直接返回引用。 Integer i04 = new Integer(59) ; // 直接创建一个新的对象。 System. out .println(i01== i02); // i01 是 Integer 对象, i02 是 int ,这里比较的不是地址,而是值。 Integer 会自动拆箱成 int ,然后进行值的比较。所以为真。 System. out .println(i01== i03); // 因为 i03 返回的是 i01 的引用,所以,为真。 System. out .println(i03==i04); // 因为 i04 是重新创建的对象,所以 i03,i04 是指向不同的对象,因此比较结果为假。 System. out .println(i02== i04); // 因为 i02 是基本类型,所以此时 i04 会自动拆箱,进行值比较,所以,结果为真。
具体参考:
减小内存的占用问题——享元模式和单例模式的对比分析
用命令行: java xxx a b c 方式运行以下代码的结果是?

这里java xxx a b c 表示运行java字节码文件xxx,参数为 a b c,因为只输入了三个参数,且args是数组下标从0开始,而程序中使用到agrs[3]显然数组越界。抛出数组越界异常。
下面代码的输出结果是?

需要知道计算机用补码存储数值 10的原码:0000 0000 | 0000 0000 | 0000 0000 | 00001010 ~10: 1111111111111111,1111111111110101 变为负数,下面求该负数的补码: ~10反码:10000000000000000,0000000000001010 符号位不变,其余位取反 ~10补码:10000000000000000,0000000000001011,等于 -11 下面记住公式 -n=~n+1可推出 ~n = -n-1
下面代码的输出结果是?
System.out.println(2.00 - 1.10);
可能认为该程序打印0.90,但是编译器如何才能知道你想要打印小数点后两位小数呢? 实际它打印的是0.8999999999999999。问题在于1.1 这个数字不能被精确表示成为一个double,因此它被表示成为最接近它的double 值。该程序从2 中减去的就是这个值。更一般地说,问题在于并不是所有的小数都可以用二进制浮点数来精确表示的。如果你正在用的是JDK 5.0 或更新的版本,那么可以使用类似c的方式,Java的printf 工具来订正该程序: System.out.printf("%.2f%n",2.00 - 1.10); 这条语句打印的是正确的结果,但是这并不表示它就是对底层问题的通用解决方案:它使用的仍旧是二进制浮点数的double 运算。浮点运算在一个范围很广的值域上提供了很好的近似,但是它通常不能产生精确的结果。二进制浮点对于货币计算是非常不适合的,因为它不可能将0.1,或者10的其它任何次负幂精确表示为一个长度有限的二进制小数。 解决该问题的一种方式是使用某种整数类型,例如int 或long,并且以分为单位来执行计算。注意这样做请确保该整数类型大到足够表示在程序中你将要用到的所有值。对本题int 就足够了。下面是用int 以分为单位表示货币值后重写的println 语句: System.out.println((200 - 110) + "cents"); 解决该问题的另一种方式是使用执行精确小数运算的BigDecimal工具类。它还可以通过 JDBC 与 SQL DECIMAL 类型进行互操作。这里要注意: 一定要用 BigDecimal(String) 构造器,而不用BigDecimal(double)。后一个构造器将用它的参数的“精确”值来创建一个实例:new BigDecimal(.1)将返回一个表示0.100000000000000055511151231257827021181583404541015625 的BigDecimal。通过正确使用BigDecimal,程序就可以打印出我们所期望的结果0.90: import java.math.BigDecimal; public class Change1{ public static void main(String args[]){ System.out.println(new BigDecimal("2.00").subtract(new BigDecimal("1.10"))); } } 这个版本并不是十分地完美,因为Java 并没有为BigDecimal 提供任何语言上的支持。使用BigDecimal 的计算很有可能比那些使用原始类型的计算要慢一些,对某些大量使用小数计算的程序来说,这可能会成为问题。总之, 在需要精确答案的地方,要避免使用float 和double,对于货币计算,要使用int、long 或BigDecimal。
浮点数表示可以参考
从如何判断浮点数是否等于0说起——浮点数的机器级表示
下面代码的输出结果是?
final long MICROS_PER_DAY = 24 * 60 * 60 * 1000 * 1000; final long MILLIS_PER_DAY = 24 * 60 * 60 * 1000; System.out.println(MICROS_PER_DAY / MILLIS_PER_DAY);
除数和被除数都是long 类型的,long 类型大到了可以很容易地保存这两个乘积而不产生溢出。因此,看起来程序打印的必定是1000。 问题在于常数 MICROS_PER_DAY 的计算“确实”溢出了。尽管计算的结果能安全放入long 中,并且其空间还有富余,但是这个结果并不适合放入int 中。这个计算完全是以int 运算来执行的,并且只有在运算完成之后,其结果才被提升到long,而此时已经太迟了,计算已经溢出。 从int提升到long是一种拓宽原始类型转换(widening primitive conversion),它保留了(不正确的)数值。这个值之后被MILLIS_PER_DAY 整除,而MILLIS_PER_DAY 的计算是正确的,因为它适合int 运算。这样整除的结果就得到了5(前者返回的是一个小了200 倍的数值)。 那么为什么计算会是以int运算来执行的呢? 因为所有乘在一起的因子都是默认int数值。将两个int 数值相乘时,将得到另一个int 数值,这是Java 的语言特性,通过使用long 常量来替代int 常量作为每一个乘积的第一个因子,我们就可以修改这个程序。这样做可以强制表达式中所有的后续计算都用long 来完成。尽管这么做只在MICROS_PER_DAY 表达式中是必需的,但是在两个乘积中都这么做是一种很好的方式。相似地使用long 作为乘积的“第一个”数值也并不总是必需的,但是这么做也是一种很好的形式。在两个计算中都以long数值开始可以很清楚地表明它们都不会溢出。下面的程序将打印1000: final long MICROS_PER_DAY = 24L * 60 * 60 * 1000 * 1000; final long MILLIS_PER_DAY = 24L * 60 * 60 * 1000; System.out.println(MICROS_PER_DAY/MILLIS_PER_DAY); 小结:当操作很大的数字时,千万要提防溢出。即使用来保存结果的变量已显得足够大,也并不意味着要产生结果的计算具有正确的类型。当拿不准时,就使用long 运算来执行整个计算。
下面代码的输出结果是?
System.out.println(12345 + 5432l);
表面上看,这是一个很简单的题,打印66666。 实际上,当运行该程序时,它打印的是17777。仔细看 + 操作符的两个操作数,我们是将一个int 类型的12345 加到了 long 类型的5432l 上。请注意左操作数开头的数字1 和右操作数结尾的小写字母l 之间的细微差异。数字1 的水平笔划 和 垂直笔划 之间是一个锐角,而与此相对照的是,小写字母 l 是一个直角。 这个写法确实已经引起了混乱,这里有一个教训:在 long 型字面常量中,一定要用大写的L,千万不要用小写的l。这样就可以完全避免混乱。 System.out.println(12345 + 5432L); 类似的,要避免使用单独的一个 l 字母作为变量名。因为很难通过观察来判断它到底是 l 还是数字 1。属于编程不规范。 System.out.println(1); 总之,小写字母 l 和数字1 在大多数字体中几乎是一样的。为避免程序的读者对二者产生混淆,千万不要使用小写的 l 来作为 long 型字面常量的结尾或是作为变量名。Java 从C 编程语言中继承良多,包括long 型字面常量的语法。也许当初允许用小写的 l 来编写long 型字面常量本身就是一个错误。
下面代码的输出结果是?
System.out.println(Long.toHexString(0x100000000L + 0xcafebabe));
看起来应该打印1cafebabe。毕竟这是十六进制数字10000000016 与cafebabe16 的和。该程序使用的是long 型运算,它可以支持16位十六进制数,因此运算溢出是不可能的。 然而,运行该程序,发现它打印出来的是cafebabe,并没有任何前导的1。这个输出表示的是正确结果的低32 位,但是不知何故,第33 位丢失了。看起来程序好像执行的是int 型运算而不是long 型运算。 注意:十进制字面常量具有一个很好的属性,即所有的十进制字面常量都是正的,而十六进制或是八进制字面常量并不具备这个属性。要想书写一个负的十进制常量,可以使用一元取反操作符(-减号)连接一个十进制字面常量。以这种方式,十进制书写任何int 或long 型的数值,不管它是正的还是负的,并且负的十进制常数可以很明确地用一个减号符号来标识。 十六进制和八进制字面常量并不是这么回事,它们可以具有正的以及负的数值。如果十六进制和八进制字面常量的最高位被置位了,那么它们就是负数。在这个程序中,数字0xcafebabe是一个int 常量,它的最高位被置位了,所以它是一个负数。它等于十进制数值-889275714。 该程序执行的这个加法是一种“混合类型的计算(mixed-type computation):左操作数是long 类型的,而右操作数是int 类型的。为了执行该计算,Java 将int 类型的数值用拓宽原始类型转换提升为一个long 类型,然后对两个long 类型数值相加。因为int 是一个有符号的整数类型,所以它将负的int 类型的数值提升为一个在数值上相等的long 类型数值。这个加法的右操作数0xcafebabe 被提升为了long 类型的数值0xffffffffcafebabeL。这个数值之后被加到了左操作数0x100000000L 上。当作为int 类型来被审视时,经过符号扩展之后的右操作数的高32 位是-1,而左操作数的高32 位是1,将这两个数值相加就得到了0,这也就解释了为什么在程序输出中前导1 丢失了。下面所示是用手写的加法实现。(在加法上面的数字是进位) 1111111 0xf f f f f f f f c a f e b a b eL + 0x00000001 0 0 00 0 0 0 0L ---------------------------------- 0x00000000 c a f e b a b eL 修改需用一个long 十六进制字面常量来表示右操作数即可。这就可以避免具有破坏力的符号扩展,并且程序也就可以打印出我们所期望的结果1cafebabe: public class JoyOfHex{ public static void main(String[] args){ System.out.println(Long.toHexString(0x100000000L + 0xcafebabeL)); } } 本题给我们的教训是:混合类型的计算可能会产生混淆,尤其是十六进制和八进制字面常量无需显式的减号符号就可以表示负的数值。最好是避免混合类型的计算。
Math.round(11.5)等于多少? Math.round(-11.5)等于多少?
Java的Math类中提供了三个与取整有关的方法:ceil、floor、round,这些方法的作用与它们的英文名称的含义相对应, floor:向下取整数。返回double类型-----n. 地板,地面 例如:Math.floor(-4.2) = -5.0 ----------------------------------------------------------- ceil: 向上取整数。返回double类型-----vt. 装天花板; 例如:Math.ceil(5.6) = 6.0 ----------------------------------------------------------- 最不舒服的是round方法,算法为Math.floor(x+0.5),即将原数加0.5再向下取整,所以,Math.round(11.5)的结果为12.0,Math.round(-11.5)的结果为-11.0。
下面代码的输出结果是?

这里主要是有一点: ceil 方法上有这么一段注释:如果参数小于0且大于-1.0,结果为 -0 其实ceil 和 floor 方法 上注释都有:如果参数是 NaN、无穷、正 0、负 0,那么结果与参数相同,如果是 -0.0,那么其结果是 -0.0 答案是 -0.0 和 -1.0
下面代码的输出结果是?
int a = 0; int b = 1; System.out.println(b / a);
没什么好说的吧,抛出除数为0的算术异常
Exception in thread "main" java.lang.ArithmeticException: / by zero
下面代码的输出结果是?
double a = 0; int b = 1; System.out.println(b / a);
Infinity
浮点数除以0之所以不会抛出异常的一个最重要的原因是浮点数0不同于整数0,是不能准确表示的。实际上浮点数0指的是一个无限趋近于0的数,一个正数除以一个无限趋近于0的数结果就是无限趋近于正无穷大,也就是infinity。
infinity通常也称之为非数(NaN,not a number),是浮点数的一种特殊形态。
经过强制类型转换以后,变量a,b的值分别为多少?

short类型,a的二进制是:0000 0000 1000 0000,强制转换截后8位,正数用源码表示,负数用补码表示,第一位是符号。因此a截取后8位的二进制是:1000 0000,第一位是1,表示是一个负数,二进制的值是128,所以结果是 b = -128,a还是128。
下面代码的输出结果是?

这里涉及java的自动装包/自动拆包(AutoBoxing/UnBoxing), Byte的首字母为大写,是类,在add函数内实现++操作,会自动拆包成byte类型,所以add函数还是不能实现自增功能。也就是说add函数只是个摆设,没有任何作用。
Byte类型值大小为-128~127之间。 add(++a);这里++a会越界,a的值变为-128 。add(b); 前面说了,add不起任何作用,b还是127。
下面代码的输出结果是?

被final修饰的变量是常量,这里的b6=b4+b5可以看成是b6=10;在编译时就已经变为b6=10了,而b1和b2是byte类型,java中进行计算时候将他们提升为int类型再进行计算,b1+b2计算后已经是int类型,赋值给b3,b3是byte类型,类型不匹配,编译不会通过,需要进行强制转换。 记住:Java中的byte,short,char变量进行计算时都会提升为int类型。
下面代码的输出结果是?

Byte是byte的包装类型,自动初始化为null而不是0,答案为: null 42 42
下面代码的输出结果是?
1 Integer integer = 42; 2 Long long1 = 42L; 3 Double double1 = 42.0; 4 5 System.out.println(integer == long1); 6 System.out.println(integer == double1); 7 System.out.println(long1 == double1); 8 System.out.println(integer.equals(double1)); 9 System.out.println(double1.equals(long1)); 10 System.out.println(integer.equals(long1)); 11 System.out.println(long1.equals(42)); 12 System.out.println(long1.equals(42L)); 13 System.out.println(integer.equals(new Integer(42)));
5,6,7编译错误,包装类的“==”运算在不遇到算术运算的情况下,两边都是包装类那么不会自动拆箱(只要有一个是基本类型,就会自动拆箱),不能直接比较不同类型的变量,必须强制转化。 下面看包装类Integer的equals方法源码,其它包装类也重写了equals方法:先判断是不是属于一个类型,然后拆箱比较数值大小。 public boolean equals(Object obj) { if (obj instanceof Integer) { return value == ((Integer)obj).intValue(); } return false; } 8行输出false,不是一个类型 9行输出false 10行输出false 11行输出false,42默认是int类型 12行true 13行true 补充下,看String的equals方法源码:先比较是不是一个对象,如不是,同样的思路,先使用instanceof判断是不是一个类型的,如果是才判断字符串内容。 public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }
下面代码的输出结果是?
Map<String, Boolean> map = new HashMap<>(); System.out.println((map != null ? map.get("test") : false));
报异常:Exception in thread "main" java.lang.NullPointerException 回忆:基本数据类型的自动装箱(autoboxing)、拆箱(unboxing)是自J2SE 5.0开始提供的功能。 一般我们要创建一个类的对象实例的时候,我们会这样: Class a = new Class(parameters); 当我们创建一个Integer对象时,却可以这样: Integer i = 100; 注意和 int i = 100; 是有区别的,实际上,执行上面那句代码的时候,系统为我们执行了: Integer i = Integer.valueOf(100); 这里暂且不讨论这个原理是怎么实现的(何时拆箱、何时装箱),也略过普通数据类型和对象类型的区别。我们可以理解为,当我们自己写的代码符合装(拆)箱规范的时候,编译器就会自动帮我们拆(装)箱。那么这种不被程序员控制的自动拆(装)箱一定格外小心,可能存在问题。 注意:三目运算符的语法规范,当第二,第三位操作数分别为基本类型和对象时,其中的对象就会拆箱为基本类型进行操作。所以,结果就是由于使用了三目运算符,并且第二、第三位操作数分别是基本类型和对象。由于该对象为null,所以在拆箱过程中调用null.booleanValue()的时候就报了空指针异常。 如果代码这么写,就不会报错: Map<String, Boolean> map = new HashMap<>(); System.out.println((map != null ? map.get("test") : Boolean.FALSE)); 保证了三目运算符的第二第三位操作数都为对象类型。
下面代码的输出结果是?
char x = \'X\'; int i = 0; System.out.println(true ? x : 0); System.out.println(false ? i : x);
打印 X88。第一个print 语句打印的是X,而第二个打印的却是88。 请注意在这两个表达式中,每一个表达式的第二个和第三个操作数的类型都不相同:x 是char 类型的,而0 和i 都是int 类型的。而混合类型的计算会引起混乱,条件表达式结果类型的规则过于冗长和复杂,其核心就是4点: 如果第二个和第三个操作数具有相同的类型,那么它就是条件表达式的类型。 如果一个操作数的类型是T,T 表示byte、short 或char,而另一个操作数是一个int 类型的常量表达式,它的值是可以用类型T 表示的,那么条件表达式的类型就是T。 否则,将对操作数类型运用二进制数字提升,而条件表达式的类型就是第二个和第三个操作数被提升之后的类型。 如果第二,三个操作数有一个是基本类型,另一个是对象类型,那么对象类型会进行自动拆箱。 程序的两个条件表达式中,一个操作数的类型是char,另一个的类型是int。在两个表达式中,int 操作数都是0,它可以被表示成一个char。然而,只有第一个表达式中的int 操作数是常量(0),而第二个表达式中的int 操作数是变量(i)。因此,第2 点被应用到了第一个表达式上,它返回的类型是char,而第3 点被应用到了第二个表达式上,其返回的类型是对int 和char 运用了二进制数字提升之后的类型,即int。 条件表达式的类型将确定哪一个重载的print 方法将被调用。对第一个表达式来说,PrintStream.print(char)将被调用,而对第二个表达式来说,PrintStream.print(int)将被调用。前一个重载方法将变量x 的值作为Unicode字符(X)来打印,而后一个重载方法将其作为一个十进制整数(88)来打印。 总之,最好是在条件表达式中使用类型相同的第二和第三操作数。
下面代码的输出结果是?

张飞算计魏延,关羽,或者调戏妇女。 == 优先级高于 三目运算符,先判断 true == true,此时返回为 true, boolean b=true ? false : true == true ? false : true;转化为 true ? false : (true == true) ? false : true; true ? false : ((true == true) ? false : true); false,后面不会执行了。
参考文章:Java也适用。
c/c++系列的运算符优先级总结
下面代码的输出结果是?

JVM 加载 class 文件时,就会执行静态代码块,静态代码块中初始化了一个变量x并初始化为5,由于该变量是个局部变量,静态代码快执行完后变被释放。 接着两个静态成员变量x,y,并没有赋初值,会有默认值,int类型为0 main方法里执行x--操作,变量单独进行自增或自减操作x--和--x的效果一样,此时x变为了-1。 调用MyMethod()方法,在该方法中对x和y进行计算,由于x和y都是静态成员变量,所以在整个类的生命周期内的x和y都是同一个。y=x++ + ++x可以看成是y=(x++)+(++x),当++或者--和其它变量进行运算时,x++表示先运算,再自增,++x表示先自增再参与运算,所以x为-1参与运算,然后自增,x此时为0,++x后x为1,然后参与运算,那么y=-1+1就为0,此时x为1 执行并打印x+y + ++x运算方式和前面相同,最后计算结果就为3
类Demo中存在方法func0、func1、func2、func3和func4,请问该方法中,哪些是不合法的定义?

数据类型的转换,分为自动转换和强制转换。自动转换是程序在执行过程中 “ 悄然 ” 进行的转换,不需要用户提前声明,一般是从位数低的类型向位数高的类型转换;强制类型转换则必须在代码中声明,转换顺序不受限制。 自动数据类型转换 自动转换按从低到高的顺序转换。不同类型数据间的优先关系如下: 低 ---------------------------------------------> 高 byte,short,char-> int -> long -> float -> double 强制数据类型转换 强制转换的格式是在需要转型的数据前加上 “( )” ,然后在括号内加入需要转化的数据类型。有的数据经过转型运算后,精度会丢失,而有的会更加精确 答案: 1没有返回值,4也不对。
下面代码的输出结果是?
short s1 = 1; s1 = s1 + 1; s1 += 1; System.out.println(s1);
s1 = s1 + 1; 由于s1+1运算时会自动提升表达式的类型,所以结果是int型,再赋值给short类型s1时,编译器将报告需要强制转换类型的错误。 s1 += 1; 由于 +=是java语言规定的运算符,java编译器会对它进行特殊处理,且效率高,因此可以正确编译。当使用+=、-=、*=、/=、%= 运算符对基本类型进行运算时,遵循规则:运算符右边的数值将首先被强制转换成与运算符左边数值相同的类型,然后再执行运算,且运算结果与运算符左边数值类型相同。
下面代码的输出结果是?
System.out.println((int) (char) (byte) -1);
以int 数值-1 开始,然后从int转型为byte,之后转型为char,最后转型回int。第一个转型将数值从32 位窄化到了8 位,第二个转型将数值从8 位拓宽到了16 位,最后一个转型又将数值从16 位拓宽回了32 位。 运行该程序,打印65535。 因为Java 使用了基于2 的补码的二进制运算,因此int 类型的数值-1 的所有32 位都是置位的,补码表示就是全f的16进制。从int 到byte 的转型是很简单的,它执行了一个窄化原始类型转化(narrowing primitiveconversion),直接将除低8 位之外的所有位全部砍掉。这样做留下的是一个8位都被置位了的byte,它仍旧表示-1。 从byte 到char 的转型稍微麻烦一点,因为byte 是一个有符号类型,而char是一个无符号类型。在将一个整数类型转换成另一个宽度更宽的整数类型时,通常是可以保持其数值的,但是却不可能将一个负的byte 数值表示成一个char。因此,从byte 到char 的转换有些复杂。 有一条很简单的规则能够描述从较窄的整型转换成较宽的整型时的符号扩展行为: 如果最初的数值类型是有符号的,那么就执行符号扩展; 如果它是char,那么不管它将要被转换成什么类型,都执行零扩展。 了解这条规则可以使我们很容易地解决这个题。因为byte 是一个有符号的类型,所以在将byte 数值-1 转换成char 时,会发生符号扩展。作为结果的char 数值的16 个位就都被置位了,因此它等于2^16-1,即65535。从char 到int 的转型也是一个拓宽原始类型转换,它将执行零扩展而不是符号扩展。作为结果的int 数值也就成了65535。 尽管这条简单的规则描述了在有符号和无符号整型之间进行拓宽原始类型时的符号扩展行为,但是最好还是不要编写出依赖于它的程序。最好将你的意图明确地表达出来。 如果在将一个char 数值 c 转型为一个宽度更宽的类型,并且不希望有符号扩展,那么为清晰表达意图,可以考虑使用一个位掩码,即使它并不是必需的: int i = c & 0xffff; 或者,书写一句注释来描述转换的行为: int i = c; //不会执行符号扩展 如果在将一个char 数值c 转型为一个宽度更宽的整型,并且希望有符号扩展,那么就先将char 转型为一个short,它与char 具有同样的宽度,但是它是有符号的。在给出了这种细微的代码之后,应也为它书写一句注释: int i = (short) c; //转型将引起符号扩展 如果在将一个byte 数值b 转型为一个char,并且不希望有符号扩展,那么必须使用一个位掩码来限制它。这是一种通用做法,所以不需要任何注释: char c = (char) (b & 0xff);
下面代码的输出结果是?
int x = 1984; // (0x7c0) int y = 2001; // (0x7d1) x ^= y ^= x ^= y; System.out.println("x= " + x + "; y= " + y);
乍一看,会认为程序应该交换变量x 和y 的值。 实际上运行却打印 x = 0; y = 1984。出错了。关于亦或交换算法,很久以前,当中央处理器只有少数寄存器时,人们发现可以通过利用异或操作符(^)的属性(x ^ y ^ x) == y 来避免使用临时变量: x = x ^ y; y = y ^ x; x = y ^ x; 这个惯用法曾经在C 语言中被广泛使用过,并进一步被构建到了C++ 中,但是它并不保证在二者中都可以正确运行。有一点是肯定的,那就是它在Java 中肯定是不能正确运行的。 Java 语言规范描述到:操作符的操作数是从左向右求值。为了求表达式 x ^= expr 的值,x 的值是在计算expr 之前被提取的,并且这两个值的异或结果被赋给变量x。在程序中,变量x 的值被提取了两次——每次在表达式中出现时都提取一次——但是两次提取都发生在所有的赋值操作之前。 // Java 中x^= y^= x^= y 的实际行为 int tmp1 = x ; // x 在表达式中第一次出现 int tmp2 = y ; // y 的第一次出现 int tmp3 = x ^ y ; // 计算x ^ y x = tmp3 ; // 最后一个赋值:存储x ^ y 到 x y = tmp2 ^ tmp3 ; // 第二个赋值:存储最初的x 值到y 中 x = tmp1 ^ y ; // 第一个赋值:存储0 到x 中 在C 和C++中,并没有指定表达式的计算顺序。当编译表达式x ^= expr 时,许多C 和C++编译器都是在计算expr 之后才提取x 的值的,这就使得上述的惯用法可以正常运转。尽管它可以正常运转,但是它仍然违背了C/C++有关不能在两个连续的序列点之间重复修改变量的规则。因此,这个惯用法的行为在C 和C++中也没有明确定义。为了看重其价值,我们还是可以写出不用临时变量就可以互换两个变量内容的Java 表达式的。但是它同样是丑陋而无用的: // 杀鸡用牛刀的做法,千万不要这么做! y = (x^= (y^= x))^ y ; 在单个的表达式中不要对相同的变量赋值两次。表达式如果包含对相同变量的多次赋值,就会引起混乱,并且很少能够执行你希望的操作。即使对多个变量进行赋值也很容易出错。更一般地讲,要避免所谓聪明的编程技巧。它们都是易于产生bug 的,很难以维护,并且运行速度经常是比它们所替代掉的简单直观的代码要慢。 修改: int x = 1984; // (0x7c0) int y = 2001; // (0x7d1) x = x ^ y; y = y ^ x; x = y ^ x; System.out.println("x= " + x + "; y= " + y); 另外,用异或交换变量既不会加快运行速度(反而更慢,六读三写加三次异或),也不会节省空间(中间变量tmp 通常会用寄存器,而不是内存空间存储)。
详细参考理论:
一道面试题:用多种方法实现两个数的交换
下面代码的输出结果是?

首先,我们要知道,静态的方法也是可以通过对象来访问的,这一点很奇怪,但是确实是可以。其次,null可以被强制类型转换成任意类型的对象,于是可以通过它来执行静态方法。输出testMethod
在JAVA中如何跳出当前的多重嵌套循环?写一段代码示意。
break语句可以强迫程序中断循环,当程序执行到break语句时,即会离开循环,继续执行循环外的下一个语句,如果Break语句出现在嵌套循环中的内层循环,则break语句只会跳出当前层的循环,如果跳出多重以上是关于Core Java 经典笔试题总结(数据类型,表达式问题)的主要内容,如果未能解决你的问题,请参考以下文章