MySQL深入浅出主从复制数据同步原理
Posted 小颜-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL深入浅出主从复制数据同步原理相关的知识,希望对你有一定的参考价值。
【mysql】深入浅出主从复制数据同步原理
参考资料:
文章目录
一、主从复制架构概述
不论任何技术栈,但凡一提高可用、高性能、高稳定这些词汇,必然会牵扯到集群、主从架构的概念,如MQ、Redis、ES、MongoDB、Zookeeper.....任何技术栈中都会有,而MySQL中同样不例外,官方也提供了主从架构的支持,通过调整多个MySQL节点的配置信息,即可将一个节点的数据同步给另一个或多个节点,但这种方式同步的是所有数据!
主从架构中必须有一个主节点,以及一个或多个从节点,所有的数据都会先写入到主,接着其他从节点会复制主节点上的增量数据,从而保证数据的最终一致性,使用主从复制方案,可以进一步提升数据库的可用性和性能:
- ①在主节点宕机或故障的情况下,从节点能自动切换成主节点的身份,从而继续对外提供服务。
- ②提供数据备份的功能,当主节点的数据发生损坏时,从节点中依旧保存着完整数据。
- ③可以基于主从实现读写分离,主节点负责处理写请求,从节点处理读请求,进一步提升性能。
但无论任何技术栈的主从架构,都会存在致命硬伤,同时也会存在些许问题需要解决:
- ①硬伤:木桶效应,一个主从集群中所有节点的容量,受限于存储容量最低的哪台服务器。
- ②数据一致性问题:由于同步复制数据的过程是基于网络传输完成的,所以存储延迟性。
- ③脑裂问题:从节点会通过心跳机制,发送网络包来判断主机是否存活,网络故障情况下会产生多主。
上述提到的三个问题中,第一个问题只能靠加大服务器的硬件配置解决,第二个问题相对来说已经有了很好的解决方案(后续讲解),第三个问题则是部署方式决定的,如果将所有节点都部署在同一网段,基本上不会出现集群脑裂问题。
上面简单了解了主从复制架构的一些基本概念后,接着来聊一聊MySQL中的主从复制。
二、MySQL中的主从复制技术
MySQL数据同步的原理
MySQL是基于它自身的Bin-log日志来完成数据的异步复制,因为Bin-log日志中会记录所有对数据库产生变更的语句,包括DML数据变更和DDL结构变更语句,数据的同步过程如下:
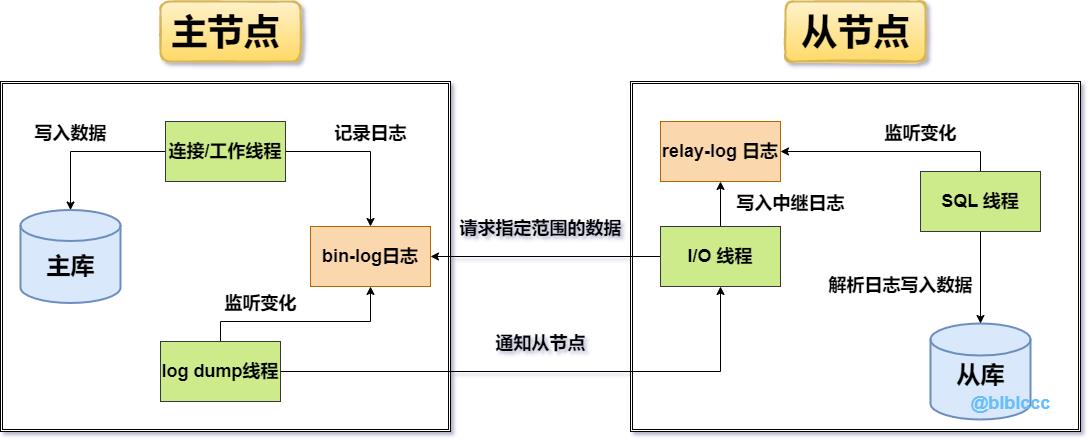
上述即是主从同步数据的原理图,但在讲解之前先来了解一下两种数据同步的方式:
- 主节点推送:当主节点出现数据变更时,主动向自身注册的所有从节点推送新数据写入。
- 从节点拉取:从节点定期去询问一次主节点是否有数据更新,有则拉取新数据写入。
那MySQL究竟采用的是什么方式呢?其实是「从拉」的方案,但对其稍微做了一些优化,传统的「从拉」方案是需要从节点一直与主节点保持长连接,从节点定时或持续性的对主节点做轮询,查看主机的数据是否发生了变更,而MySQL的数据同步原理如下:
- ①客户端将写入数据的需求交给主节点,主节点先向自身写入数据。
- ②数据写入完成后,紧接着会再去记录一份
Bin-log二进制日志。 - ③配置主从架构后,主节点上会创建一条专门监听
Bin-log日志的log dump线程。 - ④当
log dump线程监听到日志发生变更时,会通知从节点来拉取数据。 - ⑤从节点会有专门的
I/O线程用于等待主节点的通知,当收到通知时会去请求一定范围的数据。 - ⑥当从节点在主节点上请求到一定数据后,接着会将得到的数据写入到
relay-log中继日志。 - ⑦从节点上也会有专门负责监听
relay-log变更的SQL线程,当日志出现变更时会开始工作。 - ⑧中继日志出现变更后,接着会从中读取日志记录,然后解析日志并将数据写入到自身磁盘中。
阅读上述流程后,相信大家能感受出MySQL主从复制时做的优化,在主从数据同步的过程中,从节点并不会无限制的询问主机,这样实在太影响效率了,在MySQL中引入了惰性的思想,只有当主节点真正出现数据变更时,才会通知从节点拉取数据!
从节点拉取的数据到底是什么格式?
前面从整体角度出发,简单讲述了主从同步数据的过程,但从节点复制的数据到底是什么格式的呢?这里要根据主节点的Bin-log日志格式来决定,它会有三种格式,如下:
Statment:记录每一条会对数据库产生变更操作的SQL语句(默认格式)。Row:记录具体出现变更的数据(也会包含数据所在的分区以及所位于的数据页)。Mxed:Statment、Row的结合版,可复制的记录SQL语句,不可复制的记录具体数据。
一般在搭建主从架构时,最好将
Bin-log日志调整为Mixed格式,因为这种方式绝对不会出现数据不一致性,毕竟默认的Statment格式会导致主从节点间的数据出现不一致,例如:
-
insert into `zz_users` values(11,"blblccc","男","3333",now());当主节点插入数据时,使用了
sysdate()、now()....这类函数时,主节点会取自身的系统时间插入数据,而当从节点拉取SQL执行时,则会获取从节点的系统时间插入数据,因为主/从节点执行SQL语句绝对不可能发生在同一时间,因此就会导致主/从节点中,同一条数据的时间不一致。 -
有一个数据库表t1,表中有如下两条记录:
CREATE TABLE t1 ( a int(11) DEFAULT NULL, b int(11) DEFAULT NULL, KEY a (a) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; insert into t1 values(10,2),(20,1);接着开始执行两个事务的写操作:

以上两个事务执行之后,数据库里面的记录会变成(11,2)和(20,2),这个发上在主库的数据变更大家都能理解。
假如事务的隔离级别是read committed,所以,事务1在更新时,只会对b=2这行加上行级锁,不会影响到事务2对b=1这行的写操作。
以上两个事务执行之后,会在bin log中记录两条记录,因为事务2先提交,所以
UPDATE t1 SET b=2 where b=1;会被优先记录,然后再记录UPDATE t1 SET a=11 where b=2;(再次提醒:statement格式的bin log记录的是SQL语句的原文)这样bin log同步到备库之后,SQL语句回放时,会先执行
UPDATE t1 SET b=2 where b=1;,再执行UPDATE t1 SET a=11 where b=2;。这时候,数据库中的数据就会变成(11,2)和(11,2)。这就导致主库和备库的数据不一致了!!!
而将Bin-log日志调整为Mixed格式后,就不会再出现这样的问题,因为对于这种不可复制的记录,会直接选择记录具体变更过的数据到日志中,当从节点读取数据写入时,则可以直接将数据放到磁盘对应的位置中即可。
那为什么不选择
Row格式来作为数据同步时的格式呢?
这种方式同步数据不需要经过SQL解析过程,只需直接将数据放到磁盘的具体位置即可,但这种方式会让主节点的I/O负载直线拉高,在传输时也会大量占用网络带宽,因此一般都不会选择Row作为同步复制时的格式。
三、基于主从模型的不同架构
前面将最基本的主从复制原理和细节讲清楚了,虽然MySQL官方只提供了最基本的主从复制技术的支持,但这并不妨碍咱们将其玩出花来,目前业内可以基于主从机制实现:一主一从/多从、双主/多主、多主一从、级联复制四种架构,下面详细聊一聊每种架构。
一主一从/多从架构
一主一从或一主多从,这是传统的主从复制模型,也就是多个主从节点组成的集群中,只有一个主节点,剩余的所有节点都为其附属关系,大致如下:
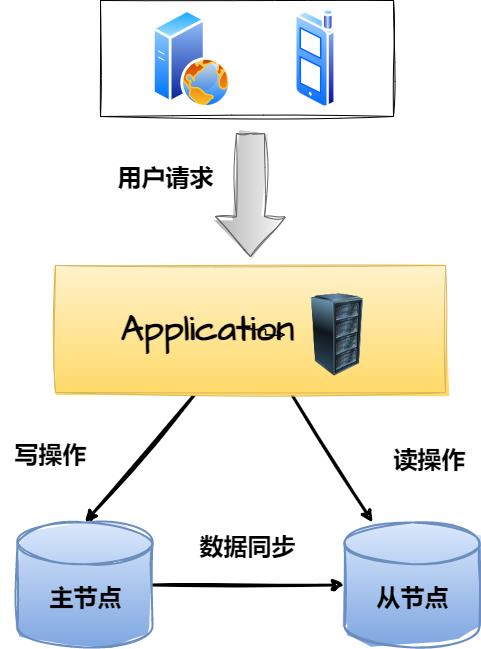
这种架构中,从节点的所有数据都源自于主节点,如上图所示,为了充分的利用好这种架构,一般都会基于它实现读写分离,也就是将客户端的写请求发给主节点处理,将客户端的读请求发给从节点处理。这种模式下,相较于单机节点而言,能够在性能上进一步提升,因为读写请求都被分发到了不同的节点处理,所以吞吐量至少会提升50%以上。
双主/多主架构
上述的一主一从/多从架构,更加适用于一些读大于写的场景,因为这类项目中,读请求的数量远超出写请求,因此将读操作分发到从库上,能够大大降低主库的访问压力,但如若你的项目中读写请求的比例对半开,同时整体的并发量也不算低,至少超出了单库的承载阈值,这时就可以选用双主/多主架构,如下:
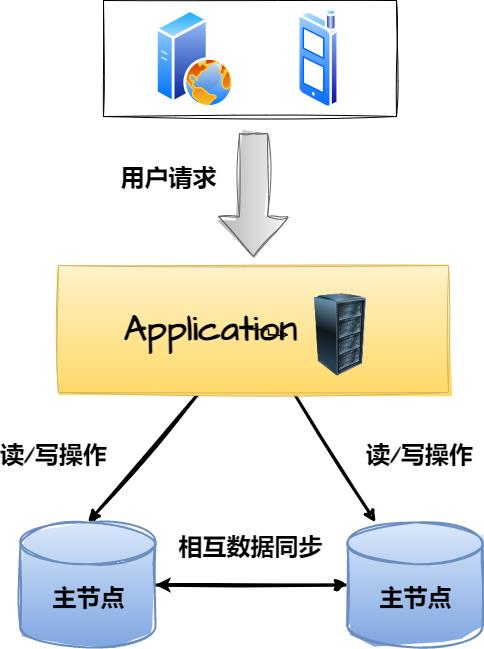
上图是一个典型的双主架构,这里有两个MySQL节点,它们都是主库,也都属于对方的从库,也就是两者之间会相互同步数据,这时为了防止主键出现冲突,一般都会通过设置数据库自增步长的方式来防重,通常会将两个节点的自增步长设为2,然后为两个节点分配自增初始值1、2,最终会出现如下效果:
DB1:1、3、5、7、9、11、13、15、17.......DB2:2、4、6、8、10、12、14、16、18......
在两个库上插入数据时,各自会以上述序列进行主键的递增,接着两个节点会各自同步对方的数据,这也就意味着双方都具备完整的数据,因此无论是:简单读、简单写、批量写、多表查…等任何类型的操作,都可以随便分发到任意节点上处理。
多主一从架构
除开上述两种主从架构的基本玩法外,面对于不同场景时也会有一些新奇玩法,比如面对于一些写大于读的场景,不管是一主多从、还是多主的方式,似乎都无法很好的解决这个问题,因此要处理这类问题时,可以选用多主一从架构,啥意思呢?如下图:
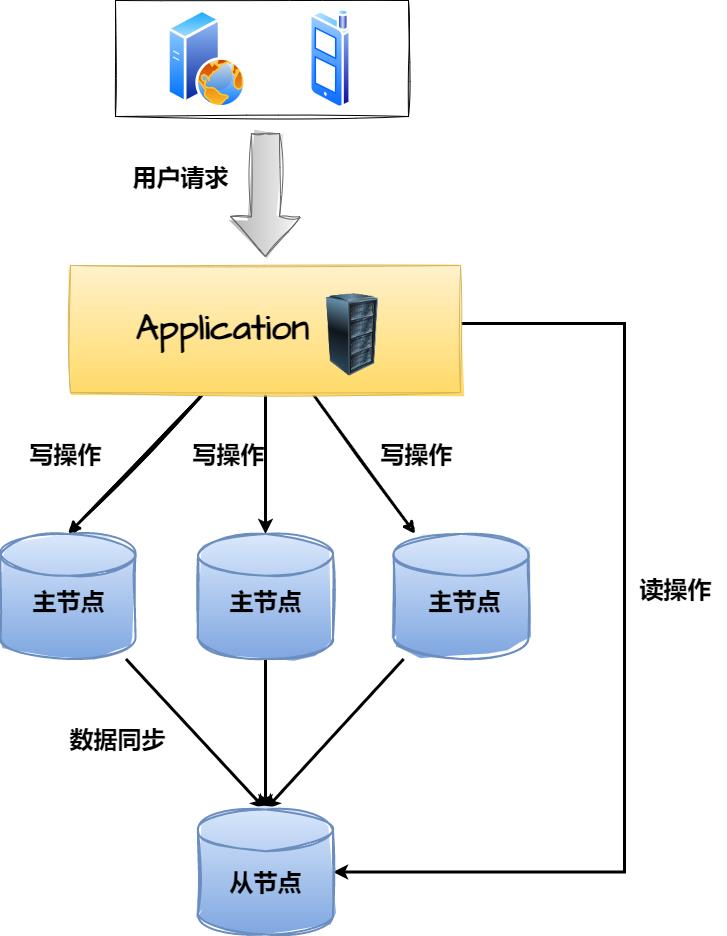
因为这种架构要解决写大于读造成的性能瓶颈,所以这里会采用多主来承载客户端的写请求,同时为了做好主键防重,也需要设置数据库自增步长和初始值,这里有三个主节点,因此自增步长为三,初始值分别为1、2、3,最终三个主节点中的数据如下:
DB1:1、4、7、10、13、16.....DB2:2、5、8、11、14、17.....DB3:3、6、9、12、15、18.....
而这三个主节点都会具备一个相同的从节点,也就是只有一个从库,它会负责同步所有主库的数据,这也就意味着从库中会具备三个主库的完整数据,这样做有什么好处呢?通过多个主节点解决了写请求导致压力过大的问题,同时从库中还有完整数据,因此也不会由于拆分了主库而影响读操作。
主从架构小结
下面做个简单的小总结:
- 一主多从架构:适用于读大于写的场景,采用多个从库来分担数据库系统的读压力。
- 多主架构:适用于读写参半的场景,采用多个主库来承载数据库系统整体的读写压力。
- 多主一从架构:适用于写大于读的场景,采用多个主库分担写压力,单个从库承载读压力。
四、主从数据一致性的解决方案
到这里为止,对于主从复制架构中绝大多数知识点和细节技术,都已经做了全面概述,最后再来重点叙说一个点,则是主从节点之间的数据一致性问题。通常情况下,对MySQL搭建了主从集群,往往从节点不会只充当备库的角色,为了充分利用已有的资源,都会在主从热备的基础上,采用读写分离方案,将写请求分发给主库、读请求分发给从库处理。
这样的确能够充分发挥从库所在机器的性能,但随之而来的还有一些问题,由于从库需要处理读取数据的请求,但主从节点之间的数据绝对会有一定延时,那对于一些关键性的数据,在主库上修改之后,再去从库上读取,这时就很有可能读取到的是旧数据,即修改前的原数据。
但这种情况对于用户而言显然是无法接受的,比如一个用户将个人信息修改后,然后再次查看时,发现个人信息依旧是修改之前的原数据,这时用户就有可能再次修改,经过反反复复多次修改后,用户发现依旧未生效,大多数情况下都会心里骂一句:“去你*的,乐色系统”!
想要解决上述这种读写分离导致的数据不一致性,主要有四种解决方案:
- 业务逻辑做改变
- 复制方式做更改
- 数据库架构做调整
- 引入第三方中间件
改变业务逻辑
改变业务逻辑的潜在含义是:对业务做一定更改,比如当用户立即修改数据后,因为在从库读不到数据,所以先显示一个审核状态,这样能够给出用户的反馈,从而避免用户再次重复操作,如:
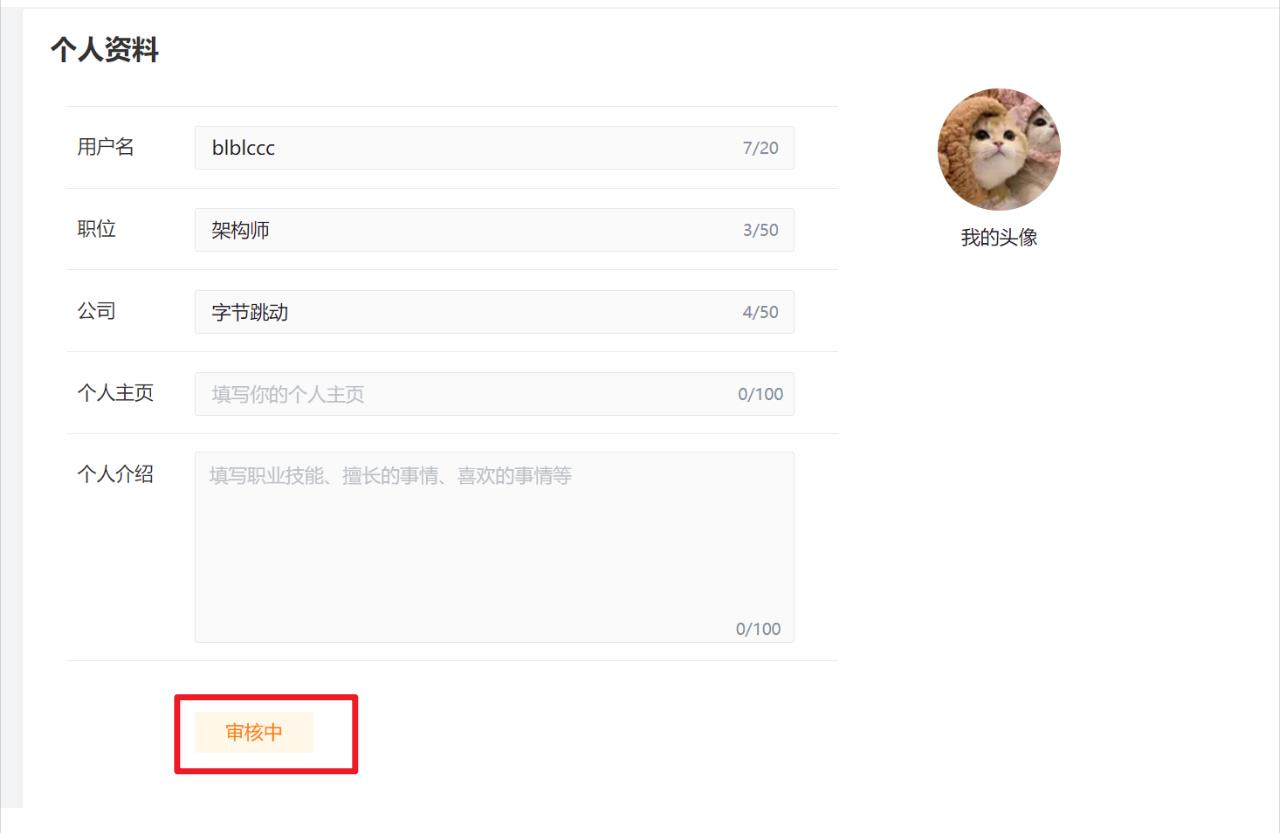
上述是掘金的个人资料,当用户手动更改后,会先显示一个「审核中」的状态,这种方式属于和数据不一致妥协的方案,接受一定的数据延迟,不过这种方式并不适用于一些对数据实时性要求较高的场景。
更改复制方式
在之前曾聊过MySQL四种数据同步复制的方式,即全同步、异步、半同步与无损复制,MySQL默认会是异步复制模式,即主节点写入数据后会立即返回成功的状态给客户端,这样能够确保性能达到最佳,但如果对实时性要求较高,可以将其改为全同步或半同步模式。
改成全同步的模式能够确保数据
100%不会存在延迟,但性能会因此严重下降,因此半同步是个不错的选择,但如果数据库仅仅是一主一从的架构,那么半同步模式和全同步模式没有任何区别,因为半同步是至少要求一个从库返回ACK,才向客户端返回写入成功,而一主一从架构中只有一个从节点~
不过就算是半同步(无损)复制模式,对比异步复制而言,依旧会导致性能下降较为严重。
调整数据库架构
如果无法接受主从架构带来的短期数据不一致,那可以升级服务器硬件,并将架构恢复成单库架构,所有读写操作都走单库完成,这就自然不会出现数据不一致问题。但如果升级硬件配置后,无法承载客户端的访问压力时,可将整体架构升级到分库分表架构,制定好合适的分片策略和路由键,每次读写数据都根据业务不同,操作不同的库。
引入第三方中间件
前面聊到的三种方案,多多少少都存在一些局限性,因为要么接受数据不一致、要么损失性能、要么使用更高规模的架构处理,但这些方案似乎都存在令人不能接受的后患,那有没有一种万全之策来解决这个问题呢?答案是有的,就是引入Canal中间件来监控主节点的Bin-log日志。
在之前讲主从同步数据原理时,曾讲到过,主节点上存在一个
log dump线程会监听Bin-log日志,当日志出现变更时会通知从节点来拉取数据,而Canal的思想也是一样的,会监控主节点的Bin-log日志,当发生变更时,就直接去拉取数据,然后直接推送给从节点写入。
Canal在主从集群的身份就类似于一个中间商,对于主节点而言,它是一个从库,因为Canal会去主库上拉取新增数据。而对于集群中真正的从节点而言,它是一个主库,因为Canal会给其他真正的从节点推送数据。但这种方式也无法做到真正的数据实时性,毕竟Canal监听变更、拉取数据、推送数据都需要时间,这部分的时间开销必然存在,只是它会比从库去主库上拉取,速度会更快一些罢了。
一般企业内部都会引入
Canal来解决数据不一致问题,因为它不仅仅只能解决主从延迟问题,还能解决MySQL-ES、MySQL-Redis.....等多种数据不一致的场景,Canal是由阿里巴巴开源的一项技术,也包括在阿里内部应用也较为广泛。
当然,也可以制定某些敏感数据走主库查询,这样能够确保数据的实时性,但容易模糊读写分离的界限,不过因为不需要引入额外的技术,所以在某些情况下也是个不错的方案。
以上是关于MySQL深入浅出主从复制数据同步原理的主要内容,如果未能解决你的问题,请参考以下文章