CSAPP Malloc Lab
Posted joker D888
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CSAPP Malloc Lab相关的知识,希望对你有一定的参考价值。
CSAPP Malloc Lab
在这个实验室中,您将为C程序编写一个动态存储分配器,即您自己版本的malloc、free和realloc例程,实现一个正确,高效和快速的分配器。本实验性能指标有两个方面,内存利用率和吞吐量,这两个方面都是动态存储分配器优秀与否的重要衡量指标,我们的分配器需要在吞吐量和内存利用率直接取得平衡以获取更高的分数。
若从官网中下载的实验文件,缺少测试文件,可从这里下载。
本实验的代码中使用了大量的宏和指针,需要特别小心。此外,为方便调试程序以及便利地对比各个版本的差异,使用了宏进行条件编译。
完成实验的方法有多种,下面主要根据书中介绍的分配器进行编码。
隐式空闲链表
隐式空闲链表:空闲块通过头部中的大小字段隐含地连接着的,分配器可以通过遍历堆中所有的块,从而间接地遍历整个空闲块的集合。
/*
* mm-naive.c - The fastest, least memory-efficient malloc package.
*
* In this naive approach, a block is allocated by simply incrementing
* the brk pointer. A block is pure payload. There are no headers or
* footers. Blocks are never coalesced or reused. Realloc is
* implemented directly using mm_malloc and mm_free.
*
* NOTE TO STUDENTS: Replace this header comment with your own header
* comment that gives a high level description of your solution.
*/
#include "mm.h"
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include "memlib.h"
/*********************************************************
* NOTE TO STUDENTS: Before you do anything else, please
* provide your team information in the following struct.
********************************************************/
team_t team =
/* Team name */
"ateam",
/* First member's full name */
"MingHui Lv",
/* First member's email address */
"joker868@126.com",
/* Second member's full name (leave blank if none) */
"",
/* Second member's email address (leave blank if none) */
"";
/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
#define IMPLICIT
// 隐式空闲链表--------------------------------
// 分配策略:默认是首次分配,通过定义以下宏,可以选择其他策略
// 下一次适配
// #define NEXT_FIT
// 最佳适配
// #define BEST_FIT
// 常数及宏 begin-----------------------------------------
#ifdef IMPLICIT
#define WSIZE 4 // 字和头部/脚部的大小(bytes)
#define DSIZE 8 // 双字
#define CHUNKSIZE (1 << 12) // 按照CHUNKSIZE大小(bytes)扩展堆
#define MAX(x, y) ((x) > (y) ? (x) : (y))
#define PACK(size, alloc) ((size) | (alloc))
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
#define HDRP(bp) ((char *)(bp)-WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp)-WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-DSIZE)))
// 常数及宏 end-----------------------------------------
// 私有全局变量即函数
#ifdef NEXT_FIT
static char *prev_bp = NULL;
#endif
static char *heap_listp;
static void *extend_heap(size_t words);
static void *coalesce(void *bp);
static void *find_fit(size_t asize);
static void place(void *bp, size_t asize);
static void *extend_heap(size_t words)
char *bp;
size_t size;
// 为对齐,分配偶数个字
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if ((long)(bp = mem_sbrk(size)) == -1) return NULL;
// 初始化空闲块头部脚部以及结尾块
PUT(HDRP(bp), PACK(size, 0)); // 空闲块头部
PUT(FTRP(bp), PACK(size, 0)); // 空闲块脚部
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); // 新的结尾块
// 合并空闲块
return coalesce(bp);
static void *coalesce(void *bp)
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp))); // 通过前一个块的脚部获取分配状态
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp))); // 通过后一个块的头部获取分配状态
size_t size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc)
return bp;
else if (prev_alloc && !next_alloc) // 下一个块为空闲
size += GET_SIZE(HDRP(NEXT_BLKP(bp))); // 加上下一个块的size
PUT(HDRP(bp), PACK(size, 0)); // 修改bp块的头部
PUT(FTRP(bp), PACK(size, 0)); // 修改“下一块”的脚部
// 需要注意的是:FTRP是通过HDRP运作的,所以要注意两者的先后关系
else if (!prev_alloc && next_alloc) // 上一个块为空闲
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
else // 上下两个块皆为空闲
size += GET_SIZE(HDRP(PREV_BLKP(bp))) + GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
// else 都已分配
#ifdef NEXT_FIT
prev_bp = bp;
#endif
return bp;
static void *find_fit(size_t asize)
#ifdef NEXT_FIT
int size = 0;
for (; (size = GET_SIZE(HDRP(prev_bp))) > 0; prev_bp = NEXT_BLKP(prev_bp))
if (!GET_ALLOC(HDRP(prev_bp)) && (asize <= GET_SIZE(HDRP(prev_bp))))
return prev_bp;
return NULL;
#elif defined(BEST_FIT)
void *best_bp = NULL;
void *bp;
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp))))
if (best_bp == NULL) best_bp = bp;
if (GET_SIZE(HDRP(best_bp)) > GET_SIZE(HDRP(bp))) best_bp = bp;
if (GET_SIZE(HDRP(best_bp)) == asize) break;
return best_bp;
#else
// 首次适配算法,从头开始搜索,选择第一个合适的空闲块
void *bp;
for (bp = heap_listp; GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
if (!GET_ALLOC(HDRP(bp)) && (asize <= GET_SIZE(HDRP(bp)))) return bp;
return NULL;
#endif
static void place(void *bp, size_t asize)
size_t csize = GET_SIZE(HDRP(bp));
// 当分割剩下的块大小 >= 最小块大小(2*DSIZE)时才进程分割
if ((csize - asize) >= (2 * DSIZE))
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1)); // 需要注意的是:FTRP是通过HDRP运作的,所有要注意两者的先后关系
bp = NEXT_BLKP(bp);
PUT(HDRP(bp), PACK(csize - asize, 0));
PUT(FTRP(bp), PACK(csize - asize, 0));
else
PUT(HDRP(bp), PACK(csize, 1));
PUT(FTRP(bp), PACK(csize, 1));
/*
* mm_init - initialize the malloc package.
*/
int mm_init(void)
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1) return -1;
PUT(heap_listp, 0); // 第一个字是双字边界对齐的不使用填充字
// 序言块是一个8字节的已分配块,只由一个头部和脚部组成,序言块和结尾块允许我们忽略潜在的麻烦边界问题
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); // 序言块
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); // 序言块
PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); // 结尾块
heap_listp += (2 * WSIZE); // 指向序言快的下一个字节
#ifdef NEXT_FIT
prev_bp = heap_listp;
#endif
// 以空闲块扩展空堆
if (extend_heap(CHUNKSIZE / WSIZE) == NULL) return -1;
return 0;
/*
* mm_malloc - Allocate a block by incrementing the brk pointer.
* Always allocate a block whose size is a multiple of the alignment.
*/
// 返回有效载荷的开始处
void *mm_malloc(size_t size)
size_t asize; // 调整后的块的大小
size_t extendsize; // 扩展堆的大小
char *bp;
if (size == 0) return NULL;
// 调整块大小,包括头部和脚部的开销以及对齐要求
if (size <= DSIZE)
asize = 2 * DSIZE;
else // 向上取整到8的倍数,(DSIZE)是头部和脚部的开销
asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE);
// 如果找到了合适的空闲块,分配
if ((bp = find_fit(asize)) != NULL)
place(bp, asize);
return bp;
// 没找到,扩展堆,再分配
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL) return NULL;
place(bp, asize);
return bp;
/*
* mm_free - Freeing a block does nothing.
*/
void mm_free(void *bp)
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
/*
* mm_realloc - Implemented simply in terms of mm_malloc and mm_free
*/
void *mm_realloc(void *ptr, size_t size)
void *oldptr = ptr;
void *newptr;
size_t copySize;
newptr = mm_malloc(size);
if (newptr == NULL) return NULL;
size = GET_SIZE(HDRP(oldptr)); // 获取原块的大小
copySize = GET_SIZE(HDRP(newptr)); // 获取新块的大小
if (size < copySize) copySize = size; // 截断
memcpy(newptr, oldptr, copySize - DSIZE); //-DSIZE 是减去头部脚部的开销
mm_free(oldptr);
return newptr;
#endif
首次适配
- 首次适配:从头开始搜索空闲链表,选择第一个合适的空闲块。
优点:它趋向于将大的空闲块保留在链表的后面;缺点:它趋向于在靠近链表起始处留下空闲块的“碎片”,这就增大了对较大块的搜索时间。
使用首次适配,测试结果如下:
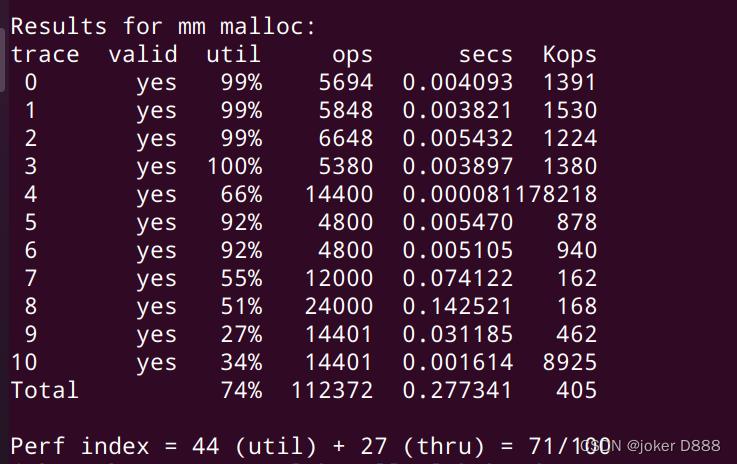
下一次适配
- 下一次适配:从上一次查询结束的地方开始进行搜索。
优点:下一次适配比首次适配运行起来明显要快一些,求其是当链表的前面布满了许多小的碎片时;缺点:然而下一次适配的内存利用率要比首次适配低得多。
需要注意的是需要在coalescs内也要相应修改,即在合并空闲块后,让prev_bp指向刚合并的空闲块,这样做不仅可以提高内存利用率也可以提高吞吐量,即使不谈这些好处,也必须在coalescs内对prev_bp相应修改。因为,当扩展块A合并上一个空闲块B后,A和B合为一大块空闲块,mm_malloc返回指针bp即
以上是关于CSAPP Malloc Lab的主要内容,如果未能解决你的问题,请参考以下文章