论文翻译:搜索人脸活体检测的中心差异卷积网络及实现代码
Posted 青云遮夜雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文翻译:搜索人脸活体检测的中心差异卷积网络及实现代码相关的知识,希望对你有一定的参考价值。
搜索人脸活体检测的中心差异卷积网络
文章原文和模型源码:https://github.com/ZitongYu/CDCN
摘要
人脸活体检测(FAS)在人脸识别系统中起着至关重要的作用。大部分最先进的FAS技术。1)依赖于堆叠卷积层和专业设计的网络,这些网络在描述详细的细粒度信息方面较弱,并且当环境变化时容易失效(例如,在不同的照明条件下)。2)更倾向使用长序列作为输出来提取动态特征,这使得它们难以部署到需要快速响应的场景中。本文提出一种基于中心差分卷积(CDC)的帧级FAS方法,该方法可以通过聚合强度和梯度信息来捕获内在的详细模型。使用CDC构建的网络称为中心差分卷积网络(CDCN),能够提供比其使用普通卷积构建的对应网络更强大的建模能力。此外,在特定设计的CDC搜索空间上,利用神经结构搜索(NAS)发现了一个更强大的网络结构(CDCN ++),可以与多尺度注意力融合模块(MAFM)组合以进一步提高性能。在六个基准数据集上进行了全面的实验,结果显示:1)所提出的方法不仅在内部数据集测试中取得了优越的性能(尤其是在OULU-NPU数据集的Protocol-1中的0.2% ACER);2)在跨数据集测试中也具有很好的泛化性能(特别是从CASIA-MFSD到Replay-Attack数据集的6.5% HTER)。代码可在https://github.com/ZitongYu/CDCN上获取。
1. 绪论
人脸识别因其便利性已经被广泛应用在许多交互式的人工智能系统中。然而,易受攻击展示攻击(PA)的漏洞限制了它的可靠部署。仅仅向生物识别传感器呈现打印出的照片或者视频就可以欺骗人脸识别系统。展示攻击的典型例子时打印照片,视频回放和3D面具。为了保证人脸识别系统的可靠性,人脸活体检测(FAS)方法是检测这类展示攻击的重要方法。

注释:
VanillaConv是一种基本的卷积神经网络,它只包含卷积层和池化层,没有任何正则化或其他技巧。
图一:普通卷积(VanillaConv)和中心差分卷积(CDC)对于在不同偏移域(照明和输入相机)中欺骗面部的特征响应。普通卷积未能捕捉到一致的欺骗模式,而CDC能够提取不变的详细欺骗特征,例如晶格伪影。
近年来,一些基于[7,8,15,29,45,44]和基于深度学习的[49,64,36,26,62,4,19,20]方法被提出用于表示攻击检测(PAD)。一方面,经典的手工描述符(例如,局部二元模式(LBP)[7])利用邻居之间的局部关系作为鉴别特征,这对于描述生命面孔和欺骗面孔之间的详细不变信息(例如,颜色纹理、莫尔模式和噪声伪影)具有鲁棒性。另一方面,由于具有非线性激活的堆叠卷积操作,卷积神经网络(CNN)具有很强的表示能力来区分真实的和PA。“然而,基于CNN的方法专注于更深层次的语义特征,这些特征在描述生活和欺骗面部之间的详细细粒度信息方面较弱,并且在环境变化(例如,不同的光照)时很容易失效。如何将局部描述符与卷积运算相结合以实现鲁棒的特征表示是一个值得研究的问题。
最近的基于深度学习的FAS方法通常建立在基于图像分类任务的骨干 ·[61,62,20]上,如VGG [54]、ResNet [22]和DenseNet [23]。网络通常由二进制交叉熵损失监督,这很容易学习不重要的信息,如屏幕边框,而不是欺骗模式的本质。为了解决这一问题,我们开发了几种利用伪深度图标签作为辅助监督信号的深度监督FAS方法[4,36]。因此,应考虑通过辅助深度监督来自动发现最适合FAS任务的网络。
“大多数现有的最先进的FAS方法[36、56、62、32]需要多个帧作为输入,以提取动态的时空特征(例如,motion[36、56]和rPPG[62、32])用于PAD。然而,长视频序列可能不适用于需要快速做出决策的特定部署条件。因此,尽管与视频级方法相比性能较差,但基于帧级别的PAD方法从可用性角度来看具有优势。设计高性能的帧级方法对于实际FAS应用至关重要。”
基于上述讨论,我们提出了一种新的卷积算子,称为中心差分卷积(CDC),它很擅长描述细粒度不变信息。如图1所示,在不同的环境中,CDC比普通的卷积更有可能提取内在的欺骗模式(例如,晶格伪影)。此外,在一个专门设计的CDC搜索空间上,利用神经结构搜索(NAS)来发现优秀的帧级网络,用于深度监督的人脸反欺骗任务。我们的贡献包括:
- 我们设计了一种新的卷积算子,称为中心差分卷积(CDC),由于其在不同环境中对不变细粒度特征的显著表示能力,适用于FAS任务。在不引入任何额外参数的情况下,CDC可以取代现有神经网络中普通的普通卷积和即插即用,形成具有更鲁棒建模能力的中心差分卷积网络(CDCN)。
- 我们提出了CDCN++,CDCN的一个扩展版本,由搜索的主干网络和多尺度注意融合模块(MAFM)组成,可以有效地聚合多级CDC特征。
- 据我们所知,这是第一个搜索FAS任务的神经结构的方法。与之前基于softmax损失监督的NAS分类任务不同,我们在一个专门设计的CDC搜索空间上搜索非常适合的帧级网络的深度监督FAS任务。
- 我们提出的方法在所有6个基准数据集上通过内部和跨数据集测试实现了最先进的性能。
2. 相关工作
人脸活体检测
传统的人脸反欺骗方法通常从面部图像中提取手工制作的特征来捕捉欺骗模式。一些经典的局部描述符,如LBP [7,15]、SIFT [44]、SURF [9]、HOG [29]和DoG [45]被用来提取帧级特征,而视频级方法通常捕获动态线索,如动态纹理[28]、微运动[53]和眼睛闪烁[41]。最近,人们提出了一些基于深度学习的帧级和视频级人脸反欺骗的方法。相比之下,引入辅助深度监督FAS方法[4,36]来有效地学习更详细的信息。另一方面,提出了几种视频级CNN方法来利用PAD的动态时空[56,62,33]或rPPG [31,36,32]特征。尽管实现了最先进的性能,基于视频级深度学习的方法需要长序列作为输入。此外,与传统的描述符相比,CNN容易过度拟合,很难在看不见的场景上很好地概括。
卷积运算符
卷积算子是在深度学习框架中提取基本视觉特征的常用方法。最近,有人提出了对普通卷积算子的扩展。在一个方向上,经典的局部描述符(例如,LBP [2]和Gabor滤波器[25])被考虑到卷积设计中。具有代表性的工作包括局部二元卷积[27]和Gabor卷积[38],这分别是为了节省计算成本和提高抗空间变化的能力而提出的。另一个方向是修改聚合的空间范围。两个相关的工作是拨号卷积[63]和可变形卷积[14]。然而,由于对不变细粒度特征的表示能力有限,这些卷积算符可能不适用于FAS任务。
神经架构搜索
我们的工作是受最近对NAS [11,17,35,47,68,69,60]的研究的激励,同时我们专注于寻找一个高性能的深度监督模型,而不是一个人脸反欺骗任务的二元分类模型。现有的NAS方法主要有三类: 1)基于强化学习的[68,69],2)基于[51,52]的进化算法,3)基于梯度的[35,60,12]。大多数NAS方法在一个小的代理任务上搜索网络,并将找到的架构转移到另一个大型目标任务上。从计算机视觉应用的角度来看,NAS已经被开发用于人脸识别[67]、动作识别[46]、人ReID [50]、目标检测[21]和分割[65]任务。据我们所知,目前还没有基于NAS的方法用于人脸反欺骗任务。为了克服上述缺陷,填补空白,我们在一个专门设计的卷积算子上搜索深度监督FAS任务。
3. 方法论
在本节中,我们将首先在3.1节中介绍中心差分卷积,然后在3.2节中介绍用于面反欺骗的中心差分卷积网络(CDCN),最后在3.3节中介绍具有注意机制的搜索网络(CDCN++)。
3.1 中心差分卷积
在现代深度学习框架中,特征映射和卷积以三维形状(二维空间域和额外通道维度)表示。由于卷积操作在整个通道维度上保持相同,为了简单起见,在本小节中,卷积在二维中描述,而扩展到3D是直接的。
基本卷积
由于二维空间卷积是CNN中用于视觉任务的基本操作,这里我们将其表示为普通卷积,并首先对其进行回顾。二维卷积有两个主要步骤:
1)在输入特征图x上采样局部感受域区域R;
2)通过加权求和对采样值进行聚合。因此,输出特征映射y可以表示为
y
(
p
0
)
=
∑
p
n
∈
R
w
(
p
n
)
x
(
p
0
+
p
n
)
(
1
)
y(p_0)=\\sum_p_n\\in Rw(p_n) x(p_0+p_n)\\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ (1)
y(p0)=pn∈R∑w(pn)x(p0+pn) (1)
其中p0表示输入和输出特征图上的当前位置,而pn枚举R中的位置。例如,3×3核的局部接受域区域1是R=(−1、−1),(−1、0)、···、(0、1)、(1、1)。
基本卷积结合中心差分操作
受著名的局部二元模式(LBP)[7]的启发,它以二元中心差的方式描述局部关系,我们也在基本卷积中引入中心差分操作,以增强其表示和泛化能力。
同样,中心差分卷积也包括两个步骤,即采样和聚合。采样步长与基本卷积相似,但聚合步骤不同:如图2所示,中心差分卷积更倾向于聚合采样值的中心向梯度。(1)式变为:
y
(
p
0
)
=
∑
p
n
∈
R
w
(
p
n
)
(
x
(
p
0
+
p
n
)
−
x
(
p
0
)
)
(
2
)
y(p_0)=\\sum_p_n\\in Rw(p_n)(x(p_0+p_n)-x(p_0))\\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ (2)
y(p0)=pn∈R∑w(pn)(x(p0+pn)−x(p0)) (2)
当
p
n
=
(
0
,
0
)
p_n =(0,0)
pn=(0,0)时,相对于中心位置
p
0
p_0
p0本身,梯度值始终等于零。
图二如下: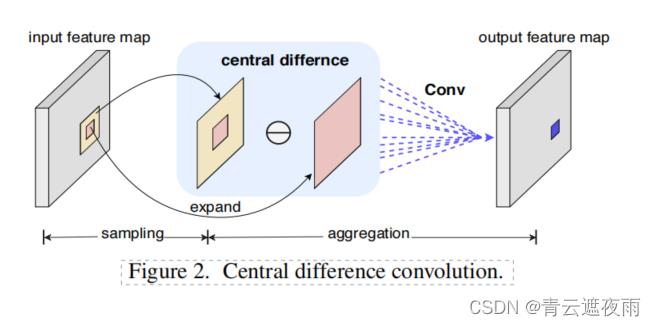
中心差分
在卷积神经网络中,中心差分操作可以通过在卷积核中引入差分核来实现。具体来说,可以在卷积核的中心位置添加一个差分核,用它来计算中心像素点与相邻像素点之间的差分值,然后将这个值加入到原始卷积核的权重中,以达到更好地捕捉图像像素点变化趋势的效果。
以一阶差分为例,假设卷积核的大小为 3 × 3 3\\times 3 3×3,则差分核的大小也为 3 × 3 3\\times 3 3×3,中心像素的权重为 0 0 0,其余像素的权重为 − 1 -1 −1 或 1 1 1,具体如下所示:
[ − 1 0 1 − 1 0 1 − 1 0 1 ] \\beginbmatrix -1 & 0 & 1 \\\\ -1 & 0 & 1 \\\\ -1 & 0 & 1 \\endbmatrix −1−1−1000111
在进行卷积运算时,可以将差分核与卷积核按照一定的方式进行叠加,然后再对图像进行卷积运算。具体来说,假设卷积核权重矩阵为 W W W,则卷积运算的输出可以表示为:
y ( p 0 ) = ∑ p n ∈ R ( ∑ i , j W ( i , j ) K ( p n + i , p n + j ) ) x ( p 0 + p n ) y(p_0)=\\sum_p_n\\in R\\left(\\sum_i,jW(i,j)K(p_n+i,p_n+j)\\right)x(p_0+p_n) y(p0)=pn∈R∑(i,j∑W(i,j)K(pn+i,pn+j))x(p0+pn)
其中 K K K 表示差分核, W ( i , j ) W(i,j) W(i,j) 表示卷积核的权重值, x ( p 0 + p n ) x(p_0+p_n) x(p0+pn) 表示输入图像中坐标为 p 0 + p n p_0+p_n p0+pn 的像素值, y ( p 0 ) y(p_0) y(p0) 表示卷积运算的输出。
对于人脸活体检测任务而言,无论是强度级别的语义信息还是梯度级别的细节信息,都对区分真实人脸和欺诈人脸具有关键作用,这表明将普通卷积和中心差分卷积相结合可能是提供更强建模能力的可行方式。因此,我们将中心差分卷积推广为:
y
(
p
0
)
=
θ
∑
p
n
∈
R
w
(
p
n
)
(
x
(
p
0
+
p
n
)
−
x
(
p
0
)
)
+
(
1
−
θ
)
∑
p
n
∈
R
w
(
p
n
)
x
(
p
0
+
p
n
)
(
3
)
y(p_0)=\\theta \\sum_p_n\\in Rw(p_n)(x(p_0+p_n)-x(p_0))\\\\+(1-\\theta)\\sum_p_n\\in Rw(p_n)x(p_0+p_n) \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ \\ (3)
y(p0)=θpn∈R∑w(pn)(x(p0+pn)−x(p0))