ORACLE数据库数据泵的导入导出
Posted lichuanjai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ORACLE数据库数据泵的导入导出相关的知识,希望对你有一定的参考价值。
一,数据泵的导入导出
数据泵的简介
数据泵中牵扯到一个逻辑概念:路径名称(DIRECTORY),它在物理上对应一个实际路径,当使用数据泵时,路径名称用于指明导出文件所在路径。
--先要准备
--1.创建一个路径指向一个主机上存在的文件夹的路径
CREATE OR REPLACE DIRECTORY DIR_1 AS 'D:\\dir1'; --D:\\dir1为实际路径
SELECT * FROM DBA_DIRECTORIES; --查看所有路径
--2.将存放路径的读写权限赋给某用户(以管理员身份赋权)
GRANT READ,WRITE ON DIRECTORY DIR_1 TO SCOTT;
--3.最好再将DBA权限给该用户,或exp_full_database和imp_full_database权限
GRANT DBA TO SCOTT;
--开始导出数据(导出表:emp表)
--命令 expdp user_name/pwd directory=dump_dir dumpfile=dump.dmp logfile=dump.log tables=tb_name1[,tb_name2]
--开始导出数据(expdp)
EXPDP SCOTT/scott DIRECTORY=DIR_1 DUMPFILE=EMP.DMP LOGFILE=EMP.LOG TABLES=EMP
--EXPDP 参数介绍
directory --导出路径,该名称指向字典DBA_DIRECTORIES中该名称对应的路径
dumpfile --导出文件的名称,后缀为.dmp
logfile --记录导出过程日志,后缀为.log
tables|schemas|tablespaces|full --分别表示导出表、模式(用户)、表空间、全库
content=all|data_only|metadata_only --分别表示导出数据及定义、仅导出数据、仅导出定义
query=[tb_name:] query_condition --导出表时使用,指定where子句以进行筛选,不能与content连用
将此命令放在命令行窗口运行(cmd打开命令行窗口)
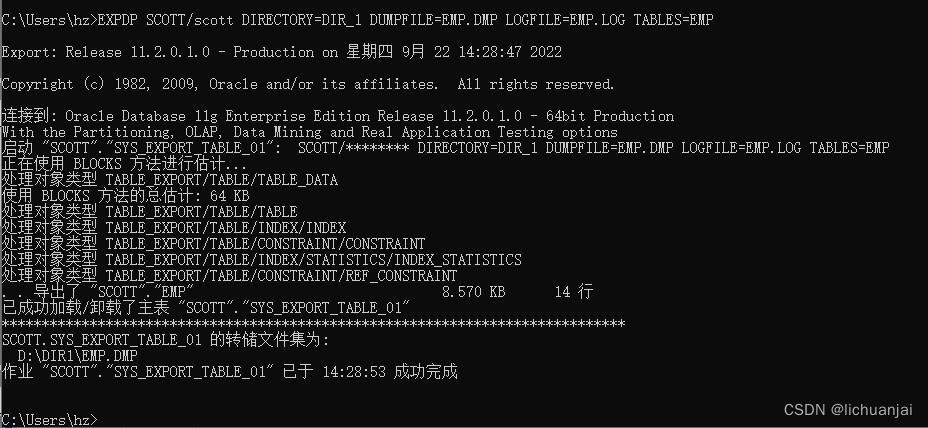
导出成功了,我们可以去对应路径查看一下我们导出的数据

我们可以发现,导出了两个文件,EMP.DMP和EMP.LOG
我们先来看一下EMP.DMP文件

是一堆乱码,但没关系,因为就是我们导出的表的数据,一会导入还需要这个文件作为导入数据
再来看看日志表EMP.LOG

里面就是你刚刚在命令行窗口执行时报出来的信息;这就数据导出成功了。接下来我们导入数据;
--开始导入数据(导入刚刚导出的表的数据)(impdp)
--命令 impdp user_name/pwd directory=dump_dir dumpfile=dump.dmp logfile=dump.log tables=tb_name1[,tb_name2]
DROP TABLE EMP; --为了方便验证,我们将emp表删除
SELECT * FROM EMP; --查一下emp表,看看还存不存在
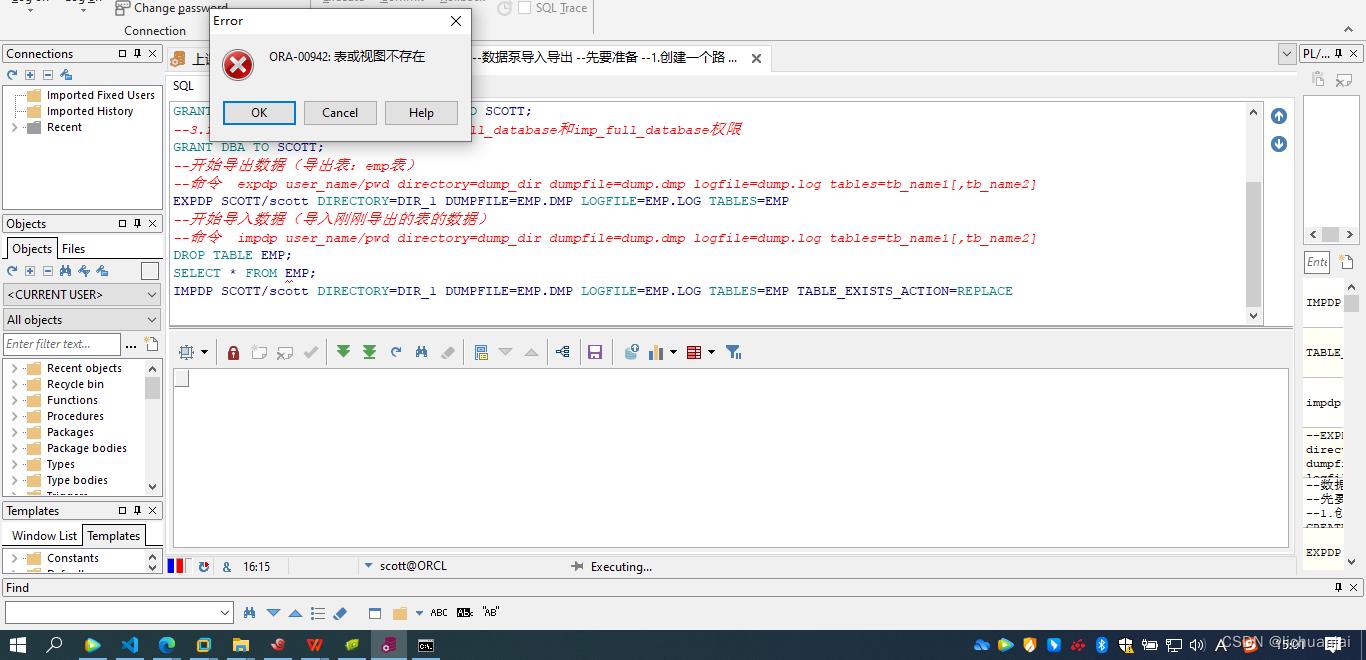
以上就是查不到emp表了
--导入数据(在命令行执行)
IMPDP SCOTT/scott DIRECTORY=DIR_1 DUMPFILE=EMP.DMP LOGFILE=EMP.LOG TABLES=EMP TABLE_EXISTS_ACTION=REPLACE
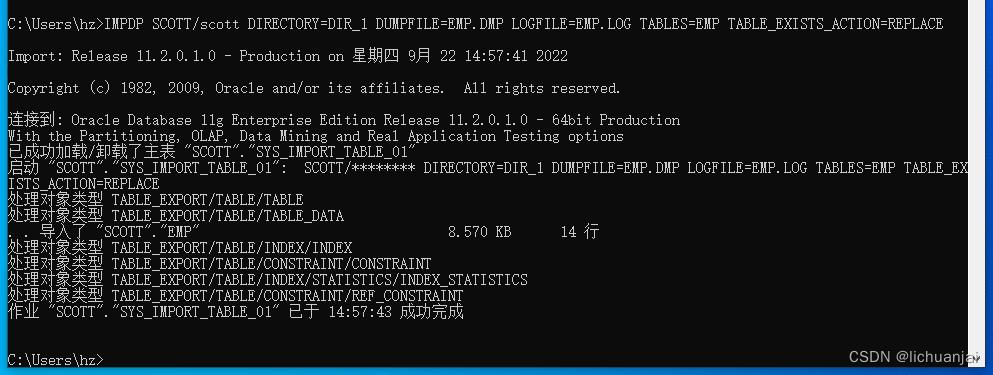
以上就是导入成功了
可以再查一下emp表,看有没有这个表
SELECT * FROM EMP;
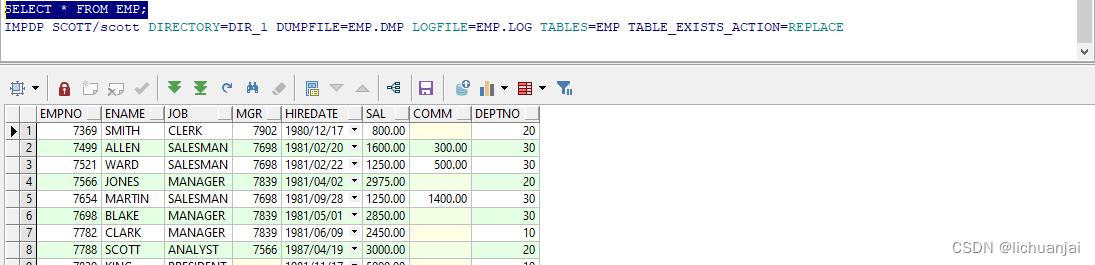
这就是导入成功了。
--IMPDP-参数介绍:
directory --导出路径,该名称指向字典DBA_DIRECTORIES中该名称对应的路径
dumpfile --导出文件的名称,后缀为.dmp
logfile --记录导出过程日志,后缀为.log
tables|schemas|tablespaces|full --分别表示导出表、模式(用户)、表空间、全库
remap_schema=from_schema:to_schema --改变用户所属 从哪个用户来,要到哪个用户去
IMPDP SCOTT/scott DIRECTORY=DIR_87 DUMPFILE=EMP.DMP LOGFILE=EMP.LOG TABLES=EMP,DEPT REMAP_SCHEMA=SCOTT:LICHUANJIA --从scott来,到LICHUANJIA去
remap_tablespace=from_tbs:to_tbs --改变表空间
table_exists_action=skip|append|replace|truncate --表存在时的处理:跳过、补充、替换、清空
SKIP:当表存在时,什么操作都不做,直接跳过
APPEND:当表存在时,在现有数据的基础之上补充数据
REPLACE:当表存在时,替换表结构和数据,相当于删除表后又重建插数据
TRUNCATE:当表存在时,清空表,再插入数据
工作中用的比较多的是 append/truncate
扩展:
导出:(导出用户,表空间,数据库)
用户:
expdp user_name/pwd directory=dump_dir dumpfile=dump.dmp logfile=dump.log schemas=user_name1[,user_name2]
EXPDP SCOTT/scott DIRECTORY=DIR_87 DUMPFILE=LI.DMP LOGFILE=LI.LOG SCHEMAS=LICHUANJIA --导出用户
表空间:
expdp user_name/pwd directory=dump_dir dumpfile=dump.dmp logfile=dump.log tablespaces=tbs_name1[,tbs_name2] -- 不用
数据库:
expdp user_name/pwd directory=dump_dir dumpfile=dump.dmp logfile=dump.log full=y
导入:(导入用户,表空间,数据库)
用户:
impdp user_name/pwd directory=dump_dir dumpfile=dump.dmp logfile=dump.log schemas=user_name1[,user_name2]
IMPDP SCOTT/scott DIRECTORY=DIR_87 DUMPFILE=LI.DMP LOGFILE=LI.LOG SCHEMAS=LICHUANJIA --导入用户
表空间:
impdp user_name/pwd directory=dump_dir dumpfile=dump.dmp logfile=dump.log tablespaces=tbs_name1[,tbs_name2]
数据库:
impdp user_name/pwd directory=dump_dir dumpfile=dump.dmp logfile=dump.log full=y
注:感兴趣的可以都试试。
以上是关于ORACLE数据库数据泵的导入导出的主要内容,如果未能解决你的问题,请参考以下文章