Lasso_ElasticNet_PolynomialFeatures算法介绍---人工智能工作笔记0032
Posted 脑瓜凉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lasso_ElasticNet_PolynomialFeatures算法介绍---人工智能工作笔记0032相关的知识,希望对你有一定的参考价值。

然后我们再来看这个ridge回归,可以看到这里的这个岭回归,可以看到
他的损失函数,其实就是添加了一个使用L2的正则化的,惩罚项对吧,目的是为了增强,损失函数的泛化能力,这里的alpha,实际上作用是为了,调整,这个损失函数的,正确率多一点还是泛化能力强一点.

可以看到他的使用函数的方式,这个是在sklearn的官网都有的.
可以看到首先获得Ridge的实例,指定了alpha的值对吧,其实alpha他也有默认值,然后
再进行.fit进行数据训练,然后就可以拿训练以后的实例,来进行预测了,可以看到
reg.intercept_是获取截距也就是w0,然后reg.coef_是获取w1到wn的值,然后
reg.predict是预测某个x值对应的y值对吧.

然后我们再来看看这个Lasso回归,我们知道回归可以用来解决一些,连续的问题,比如药物预测,股票预测等..这个lasso回归,可以看到,他的损失函数,其实就是,也是后面添加了惩罚项对吧,他也有个alpha用来条件,损失函数的,正确率,还有泛化能力.
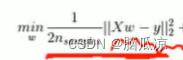
然后不同的是可以看到他用的是L1正则,L2正则是,所有w的平方和相加,而L1正则是,所有的w的绝对值的相加.对吧,并且前面,他还有个 1/2nsamples 这个其实就是1/2 参数的个数对吧,这样用来做,
防止来回震荡的,防止步子太大对吧.应该梯度越下降,随着迭代应该变小用的.
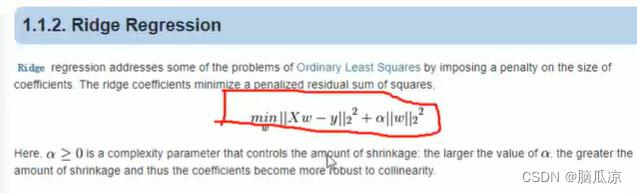
然后我们看ridge regression这里前面1/w对吧,所以ridge regression和lasso regression其实很像,但是他们的损失函数不一样对吧.

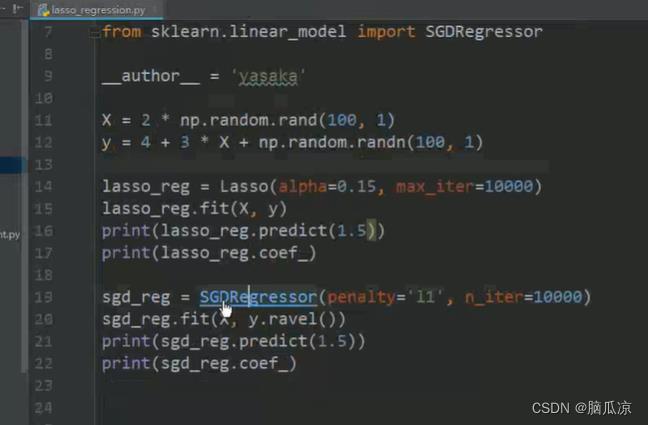
而使用的时候,我们可以看到,其实有两种方法,这里lasso,是导入这个算法
首先也是得到这个lasso实例,然后fit训练,然后就可以用训练后的,lasso_reg.predict预测等对吧
可以看到同时可以使用SGDRegressor这个随机梯度下降来,代替Lasso对吧,因为我们说,
SGDRegressor是一个通用的回归器,可以看到当我们指定penalty= 这个惩罚项我们指定使用l1的时候,其实就是等于lasso算法对吧.
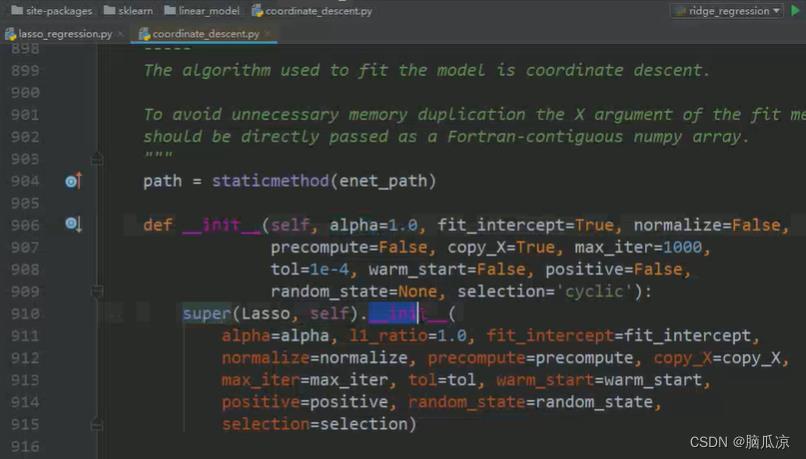
我们可以看一下lasso的初始化定义的函数,可以看到super继承了他的父类对吧

然后可以看到lasso的父类是elasticNet对吧
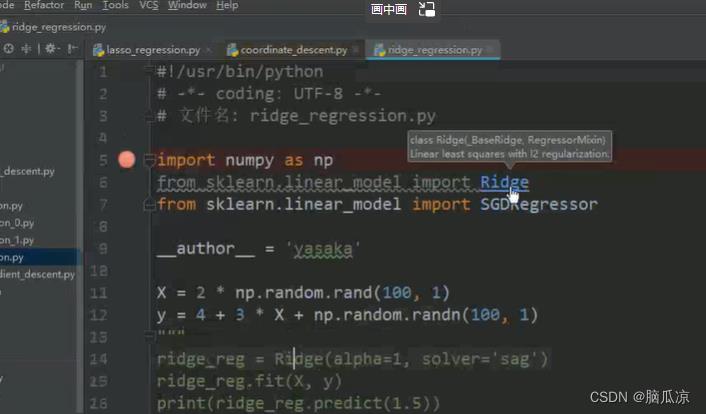
然后我们再来看这里
可以看到Ridge这里,我们看一下ridge他的父类

可以看到他继承了两个一个是_BASERidge,一个是RegressorMixin对吧.
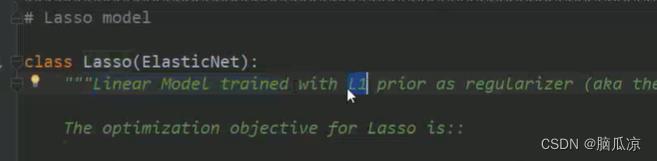
然后可以看到lasso注释写了,他说用l1正则化来进行回归的

然后我们这里对于lasso,对于SGDRegressor,这里没有max_iter,应该叫n_iter

我们先删除,然后执行一下看看

我们看一下这个l1_ratio这个,l1的alpha的值默认是0.15对吧,这个是SGDRegressor中的,然后
上面lasso的我们指定的也是0.15是一样的对吧

然后我们还可以指定一下最大迭代次数,这里SGDRegressor是10000次迭代,然后Lasso是也是我们指定10000次迭代对吧,然后

然后我们再来看这个elasticnet这个回归,可以看到,这里,这个回归其实,他包含了,L1正则化和L2正则化都包含,因为,对于L1正则化它有个特点就是,他可以让,维度对应的w,有些趋近于0,有些趋近于1,
这样的话,我们通过L1正则,就可以找到我们输入的维度数据,哪些是权重比较大的,哪些是权重比较小的对于权重趋近于0的,说明他对结果的影响不大,可以忽略掉这种数据,这样我们就实现了对数据维度的,降维对吧.
然后对于L2正则化来说,他可以实现,整体上可以保持w比较小,我们之前说过了,w越小越少越好对吧,
这里L2正则化就可以让w整体越小对吧,他的意思是,比如w原来是,0.5 ,0.3 0.1 经过L2正则化以后,这个w权重会变成,比如0.005 0.003 0.001对吧会这样
这里还要注意,一般情况我们都会使用L2正则化,因为对于数据特征的提取,还有数据的降维等操作,一般我们都会在数据的预处理阶段已经做了,所以说,我这里,就一般会直接使用L2正则化
这里我们一般都是使用Ridge回归,其次再去使用ElasticSearchNet回归,然后再去使用lasso回归,实际上来说,我们一般都不会去使用线性回归损失函数了,都是用这个封装好的了.
当我们不知道我们该用L1正则,还是用L2正则的时候,实际上我们可以使用ElasticSearchNet回归对吧.
原生的不加正则化的损失函数我们基本上不会使用了.
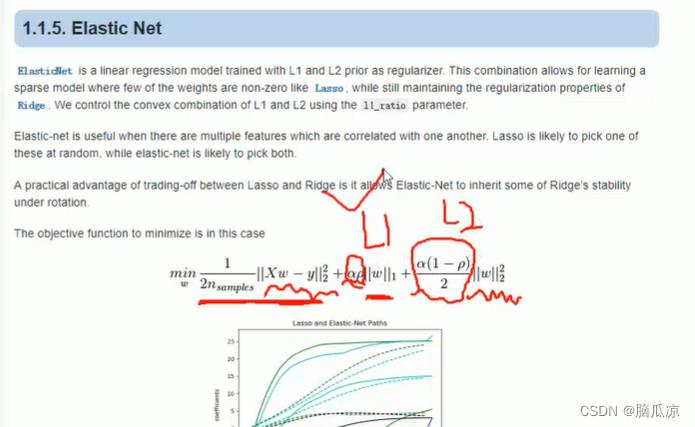
然后我们继续来看一下这个ElasticNet这个回归,可以看到,这里的损失函数,包含了L1正则,同时包含了L2正则对吧,可以看到,这里面,有个
 这部分可以看到就是lasso回归的损失函数,然后这里的
这部分可以看到就是lasso回归的损失函数,然后这里的
其实就是第一个部分加的惩罚项,就是加的L1的正则化,然后后面
就是加的L2的惩罚项,然后再来看
这里的:这个alpha 和 p这里,这两个数是用来,设置L1 和L2权重的,也就是说,让我的结果
损失函数的结果,是偏重L1一点,还是更偏重L2一点对吧,因为L1是可以让w,趋近于1或者0,而L2的结果可以使得整体的w,越小对吧.
而这里你alpha p 是L1的权重,然后 alph (1-p) /2 是L2的权重

然后我们还可以看一下这个elasticNet的使用案例对吧

然后我们去看一下代码也能反映出,可以看到这个lasso的源码

可以看到这个lasso的源码继承了父类对吧

而lasso的父类就是elasticNet对吧

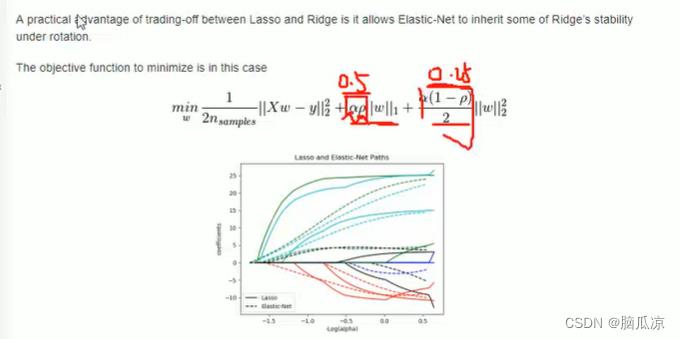
然后看一下他的这个alpha其实就是1.0对吧,而l1的权重就是0.5对吧,我们可以把
这两个权重可以看到,带入到,刚才看的那个公式算一下

这里alpha是1 p是0.5那么,这里的L1正则就是:alpha * p = 0.5对吧
然后L2的正则就是:alpha(1-p) /2 = 0.25对吧

可以看到这个就是默认的,在elasticNet回归中的,L1, 和L2的权重值对吧.
带入就可以计算出来
然后我们可以来看一下其实,SGDRegressor

里面当我们指定需要用penalty惩罚项是L1的时候,实际上这个时候用的权重,alpha是 l1_radio对吧
用的是这个
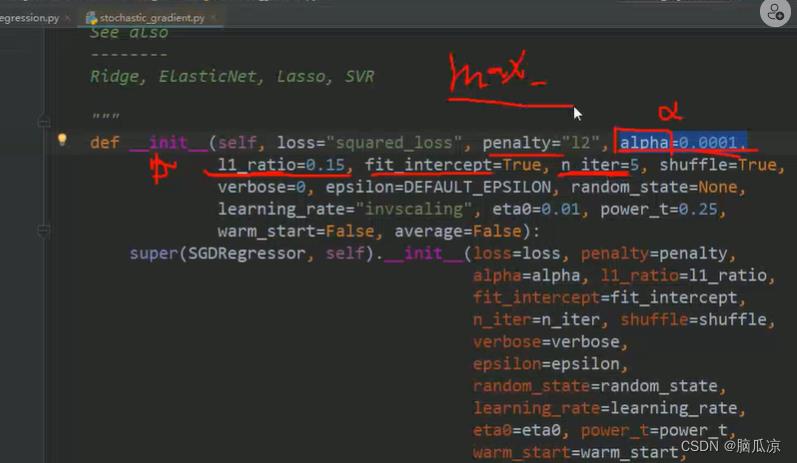
然后这里的可以看到SGDRegressor默认的penalty=l2惩罚项是l2,然后
对应的l1的惩罚项是0.15,然后那个截距,可以看到
fit_intercept=true会自动补齐w0对吧,然后n_iter=5 这个,是迭代次数是5对吧,这个和m_iter的区别是,
m_iter是指的最大执行5次,这个n_iter是,执行5次就结束对吧.

然后我们看看elasticNet怎么使用,可以看到,指定了alpha=0.0001,然后l1_ratio是0.15对吧
然后同样也是.fit以后,然后训练以后就可以进行.predict(1.5)预测了对吧
可以看到实际上他就相当于SGDRegressor当penalty惩罚项是elasticnet的时候对吧.
是等同的.执行一下可以看到结果也都是没问题的.
以上是关于Lasso_ElasticNet_PolynomialFeatures算法介绍---人工智能工作笔记0032的主要内容,如果未能解决你的问题,请参考以下文章