Java内存模型JMM简单分析
Posted 白日梦想家12138
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java内存模型JMM简单分析相关的知识,希望对你有一定的参考价值。
参考博文:http://blog.csdn.net/suifeng3051/article/details/52611310
http://www.cnblogs.com/nexiyi/p/java_memory_model_and_thread.html
http://www.cnblogs.com/dolphin0520/p/3613043.html
一、Java内存区域的划分
由于Java程序是交给JVM执行的,所以我们在谈Java内存区域分析的时候事实上是指JVM内存区域划分。
根据《Java虚拟机规范》的规定,运行时数据区通常包括这几个部分:程序计数器(Program Counter Register)、Java栈(VM Stack)、本地方法栈(Native Method Stack)、方法区(Method Area)、堆(Heap)。
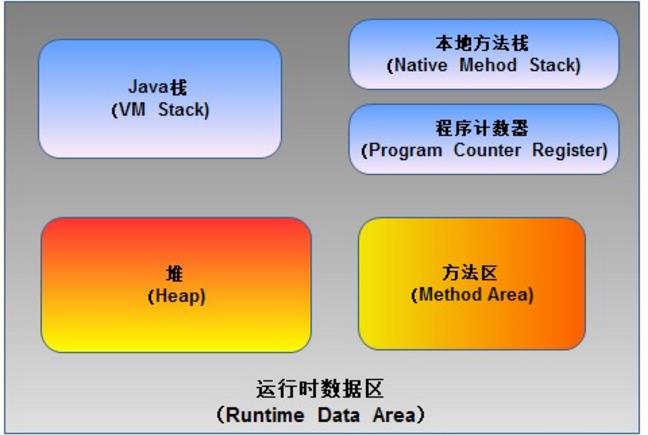
如上图所示,JVM中的运行时数据区应该包括这些部分。在JVM规范中虽然规定了程序在执行期间运行时数据区应该包括这几部分,但是至于具体如何实现并没有做出规定,不同的虚拟机厂商可以有不同的实现方式。
1.程序计数器:用来指示执行哪条命令
由于在JVM中,多线程是通过线程轮流切换来获得CPU执行时间的,因此,在任一具体时刻,一个CPU内核只会执行一条线程中的指令
因此,为了能够使得每个线程都在线程切换后能够恢复在切换之前的程序执行位置,每个线程都需要有自己独立的程序计数器,并且不能互相被干扰,否则就会影响到程序的正常执行次序,
因此可以这么说,程序计数器是每个线程所私有的
2.Java栈:Java栈是Java方法执行的内存模型
Java栈中包含:
1.局部变量表(方法中局部变量) 2.操作数栈(程序中的所有计算过程都是在借助于操作数栈来完成的)
3.指向运行时常量池的引用(引用指向运行时常量) 4.方法返回地址(当一个方法执行完毕,要返回之前调用它的地方) 5.附加信息
由于每个线程正在执行的方法可能不同,因此每个线程都会有一个自己的Java栈,互不干扰
3.本地方法栈(为执行本地方法服务的)
本地方法栈与Java栈类似,区别只不过是Java栈是为执行Java方法服务器的,而本地方法栈则是为执行本地方法(Native Method)服务的
在HotSopt虚拟机中,直接就把本地方法栈和Java栈合二为一
4.堆
Java中的堆是用来存储对象本身的以及数组(当然,数组引用是存放在Java栈中的)。另外,堆是被所有线程共享的,在JVM中只有一个堆
堆内存包含三块:年轻代(年轻代分三个区。一个Eden区,两个 Survivor区(一般而言))、年老代、永久代(jdk1.8之前)
5.方法区
方法区与堆一样,是被线程共享的区域。在方法区中,存储了每个类的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译后的代码等
根据以上,网上有很多种说法没有说清楚:
我们说,创建一个线程时,会创建一个线程自己的工作内存,用于操作从主存拷贝过来的变量
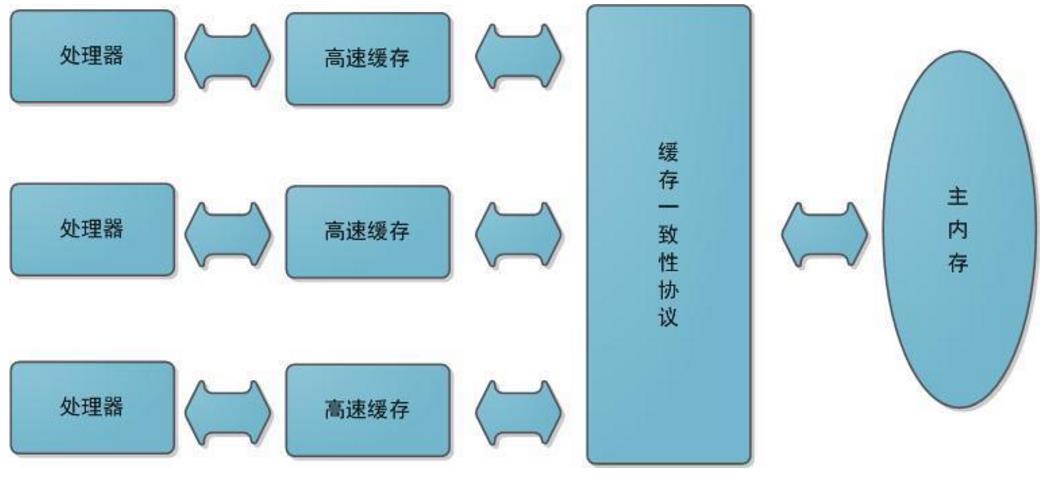
所谓的线程的 工作内存 实际上 是对 CPU寄存器和高速缓存的抽象描述,(实际上是不存在的,只是为了帮助我们理解,而提出这个概念)
现在的计算机,cpu在计算的时候,并不总是从内存读取数据,它的数据读取顺序优先级 是:寄存器-高速缓存-内存。线程耗费的是CPU,线程计算的时候,原始的数据来自内存,在计算过程中,有些数据可能被频繁读取,这些数据被存储在寄存器 和高速缓存中,当线程计算完后,这些缓存的数据在适当的时候应该写回内存。当个多个线程同时读写某个内存数据时,就会产生多线程并发问题
实际上,线程创建的时候,只会为这个线程分配一个线程栈(当然,没有每个线程都有的程序计数器),后面我们提到的关于主存变量的拷贝,线程在工作内存去操作,都是基于寄存器和高速缓存抽象出来的
我们可以这样理解:
创建线程,一个线程会有一个线程栈,线程的工作内存就在这个栈中,一个方法调用就是一个栈帧。一个栈帧:局部变量区、操作数栈和帧数据区。
工作内存为局部变量区中的数据,这样理解实际上是错误的,原因我们上面说到了,但是找不到更好的类比方式了,
总:在线程中创建一个变量,是直接创建在主存上的
在线程中操作变量,是在寄存器和高速缓存中去操作,然后从缓存中刷新回主存的
拷贝的过程有没有呢?也是没有的,线程要操作主存中的变量,先看缓存中有没有,如果缓存中有,就在缓存中操作,如果缓存中没有,就去主存中操作
二、Java内存模型
||
抽象出
||
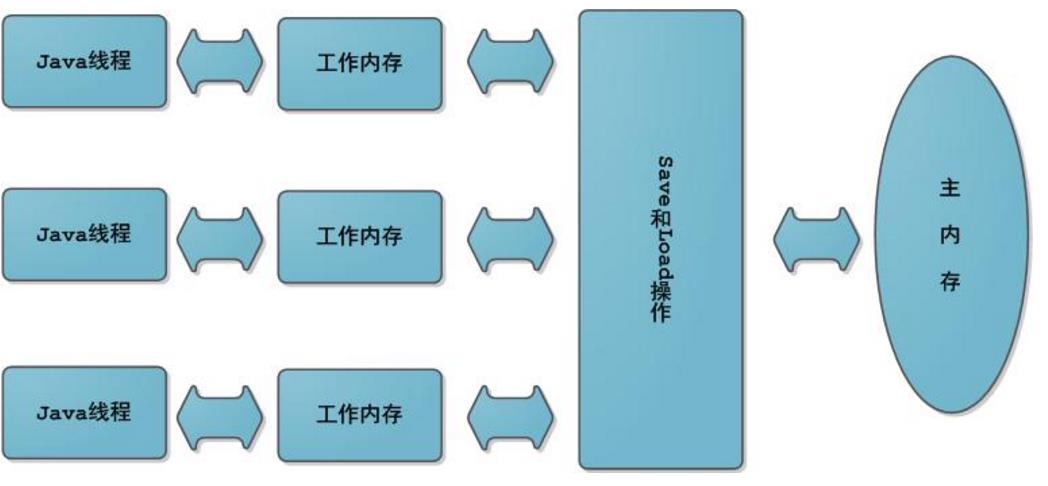
Java内存模型中规定了所有的变量都存储在主存中,每条线程还有自己的工作内存,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量,不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要在主内存来完成
注:线程之间的通信
线程的通信是指线程之间以何种机制来交换信息。在命令式编程中,线程之间的通信机制有两种 共享内存和消息传递
消息传递:在java中典型的消息传递方式就是 wait() 和 notify()
共享内存:通过共享对象进行通信
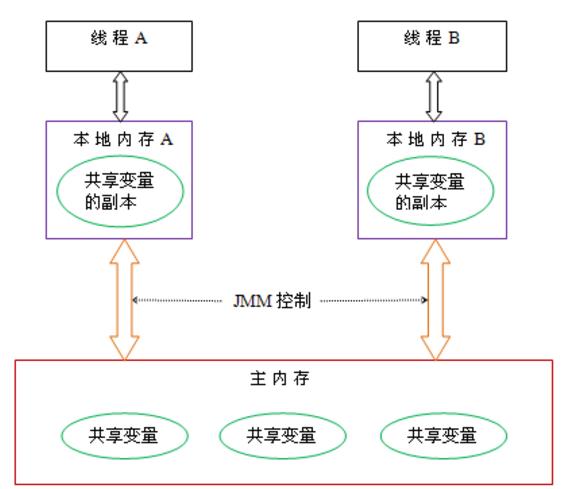
从上图来看,线程A与线程B之间如要通信的话,必须要经历下面2个步骤:
1.首先,线程A把本地内存A中更新过的共享变量刷新到主内存中去。
2. 然后,线程B到主内存中去读取线程A之前已更新过的共享变量。
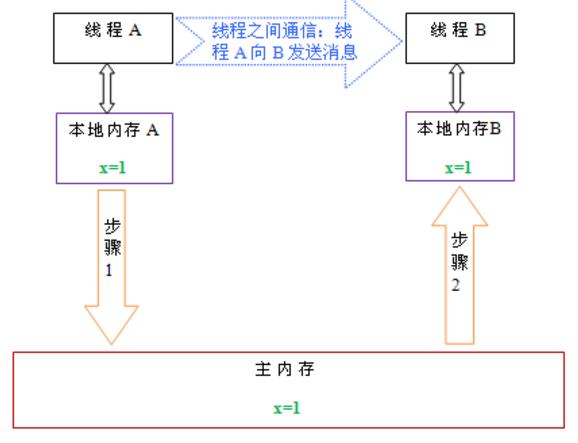
从整体来看,这两个步骤实质上是线程A在向线程B发送消息,而且这个通信过程必须要经过主内存。
(注:以下都是建立在Java内存模型的基础之上,抽象出现的,便于理解)
默认情况下,线程之间的工作内存是不可共享的,即A线程是看不到B线程的工作内存的,B线程从主存中copy了一份变量x,然后对这个变量进行操作
A是看不到B对x做了什么操作的,必须要等B将x的值刷新回内存,线程A才知道
在使用volatile关键字修饰变量x之后呢,volatile保存可见性的原理是在每次访问变量时都会进行一次刷新,因此每次访问都是主存中最新的版本
线程B从主存中copy了一份变量x,此时B对i进行操作后,会立即将更新后x的刷新回主存,A线程读取x的值时,刷新主存,得到的是x的最新值
最后可以理解为,线程是在主存上操作对象x(实际上不是,还是必须要在线程自己的工作空间上操作,只是有这个效果),线程之间 对于x对象都是可见的,
做一些补充:从上面我们知道 \'工作内存并不是在内存中分配一块空间给线程,而是cache 和寄存器的一个抽象\'
但是, 为了加速对象的分配,JVM确实会为每个线程分配一块内存, 这块内存称为TLAB
TLAB(Thread-local allocation buffer) 即线程本地分配缓存, TLAB是线程专用的内存分配区域, 目的是加速对象的分配
由于对象一般会分配在堆上, 而堆是全局共享的。在同一时间, 可能会有多个线程在堆上申请空间。 因此, 每一次对象分配都必须进行同步操作,
而在竞争激烈的场合分配的效率又会进一步下降。 为了优化这种情况, 诞生了TLAB
TLAB本身占用的是 eden 区的空间,在TLAB启用的情况下, 虚拟机会为每一个Java线程分配一块TLAB区域 默认设定为占用Eden Space的1%
在Java程序中很多对象都是小对象且用过即丢,它们不存在线程共享也适合被快速GC,所以对于小对象通常JVM会优先分配在TLAB上,并且TLAB上的分配由于是线程私有所以没有锁开销。因此在实践中分配多个小对象的效率通常比分配一个大对象的效率要高。
也就是说,Java中每个线程都会有自己的缓冲区称作TLAB(Thread-local allocation buffer),每个TLAB都只有一个线程可以操作,TLAB结合bump-the-pointer技术可以实现快速的对象分配,而不需要任何的锁进行同步,也就是说,在对象分配的时候不用锁住整个堆,而只需要在自己的缓冲区分配即可。
附一下对象的大致分配流程:
尝试栈上分配 --Y--> 栈上分配
| 失败
尝试TLAB分配 --Y--> TLAB分配
| 失败
是否满足直接进入老年代 --Y--> 老年代分配
| 否
进入Eden区
以上是关于Java内存模型JMM简单分析的主要内容,如果未能解决你的问题,请参考以下文章